kettle分页抽取数据
2024-01-08 20:33:50
背景
kettle抽取数据大家还是比较熟悉的,kettle在抽取数据的时候会开启很多通道,同时抽取,但是我现在遇到一个场景:
从一个mysql数据库里获取“已办”状态的数据id,然后拿这些id去一个oracle数据库里查询,这些id在oracle数据中的状态是不是正确的,oracle数据库设置了in条件最多能in1000个值,并且oracle数据库是和核心生产库,我不能去创建表之类的进行关联,只有查询权限。
基于以上场景,通过java代码实现其实相当简单,做一个mysql分页,1000条匹配一次,但是用kettle还从来没做过分页,于是乎开始百度,但是大部分博主给的是错的,主要在变量部分,同一个转换中,“设置变量”后再通过${xx}获取变量值是获取不到的,必须跨转换才行,真的是比较奇怪。
下面就把完整的kettle过程贴出来:
总作业(workflow_oa_check.kjb)

- 给mysql数据库创建一个可以保存结果数据的表

- ?获取分页页数,为了方便,其实输出的是页数*1000
- 循环页数匹配逻辑作业,注意,必须勾选“执行每一个输入行”,这样就会有循环的效果
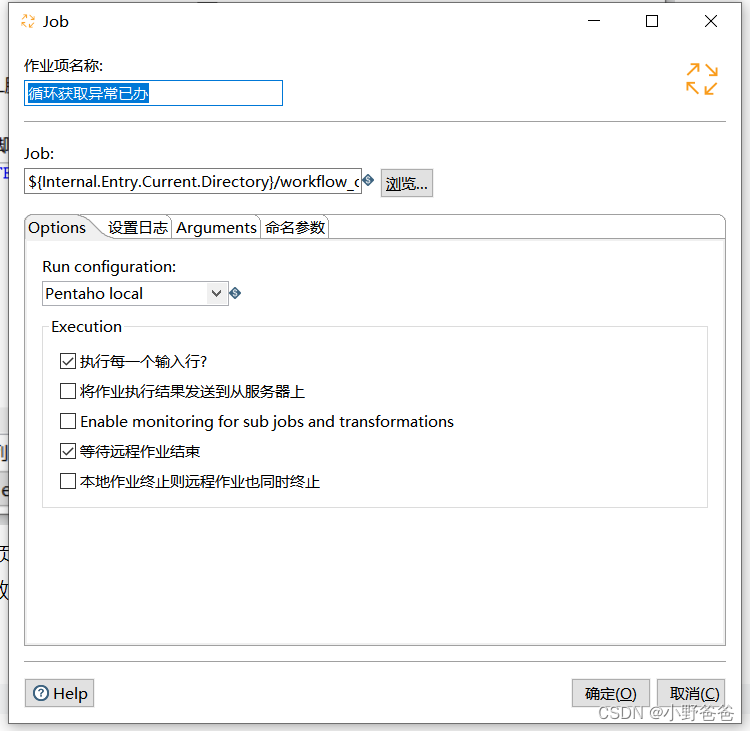
?获取页数(workflow_oa_done_num.ktr)
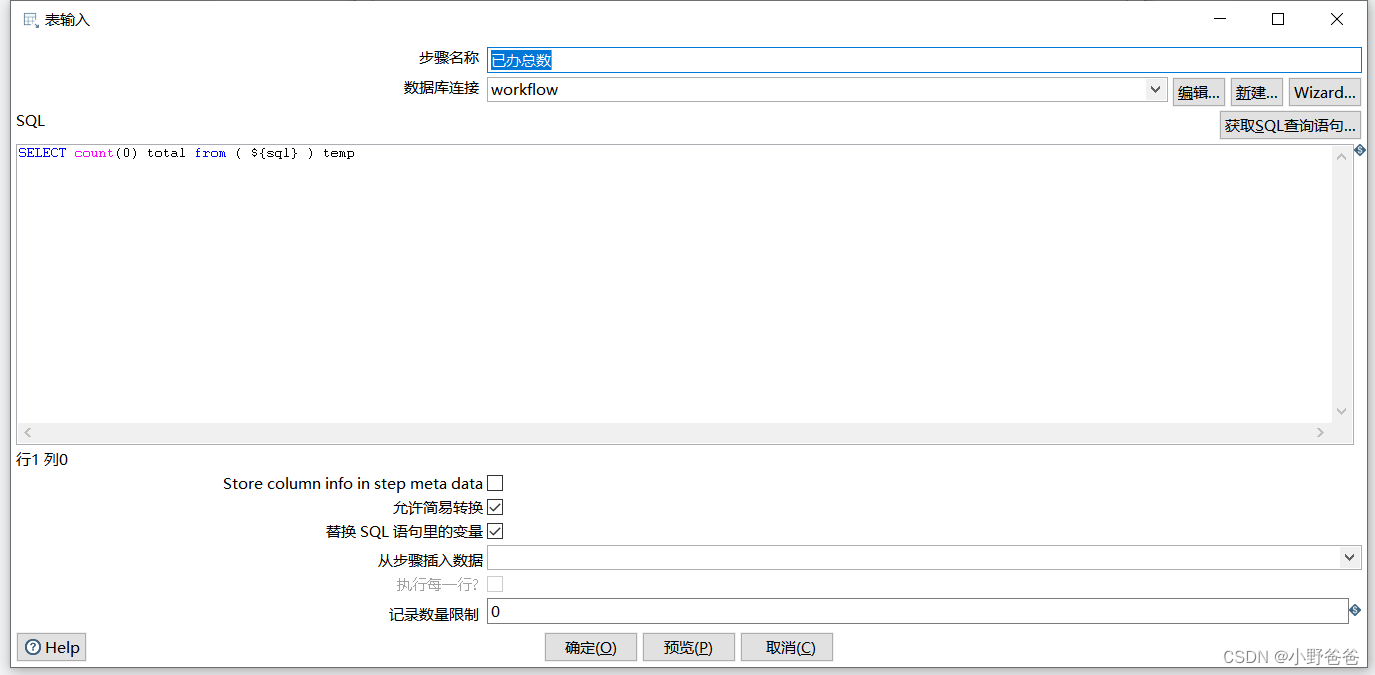
- 已办总数,表输入,?SELECT count(0) total from ( ${sql} ) temp? ?,其中,具体sql是个变量,可以在job执行的时候自行复制,例如可以是select * from act_hi_taskins
 ? ? ??
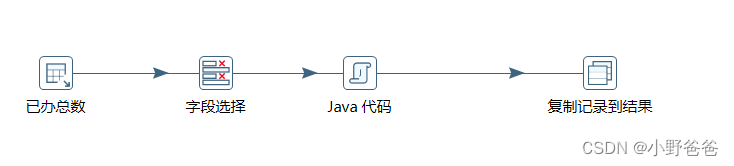
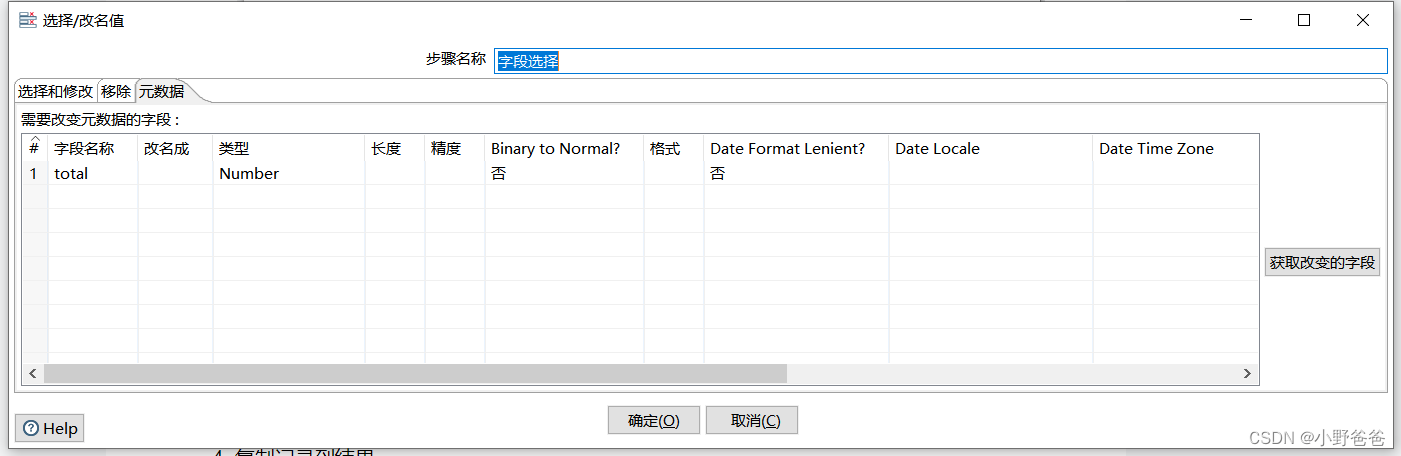
? ? ?? - 字段选择,将上一步的表输入字段选择
- java代码,根据总页数/每页的数量循环
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException { if (first) { first = false; } Object[] r = getRow(); if (r == null) { setOutputDone(); return false; } //此处创建 r,是为了获取输入参数TOTAL_SRC的值 r = createOutputRow(r, data.outputRowMeta.size()); double num = get(Fields.In, "total").getNumber(r); int pageNum = 1000; int pages = (int)num/pageNum +1; //计算总页数 System.out.println("=====================总页数"+pages); //生成页码,并输出 for(int i=0;i<pages;i++){ r = createOutputRow(r, data.outputRowMeta.size()); get(Fields.Out, "PAGE").setValue(r, (i)*pageNum); //将页码*pageNum 赋值给PAGE; putRow(data.outputRowMeta, r); } return true; }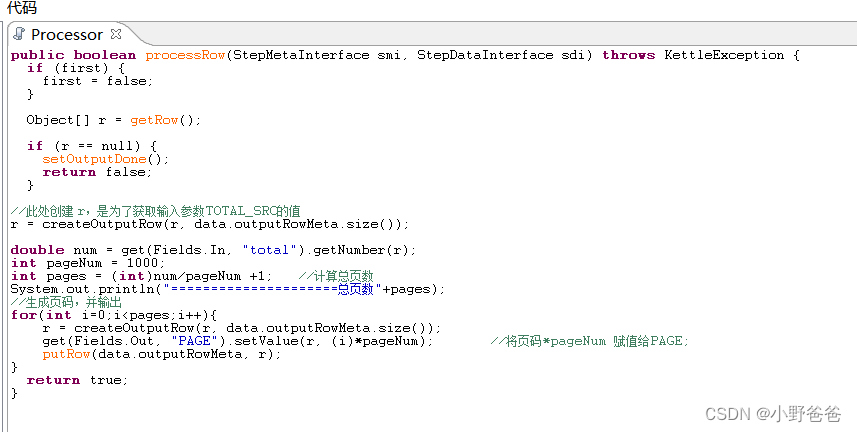
- 复制记录到结果?
循环获取异常已办(workflow_oa_check_loop.kjb)
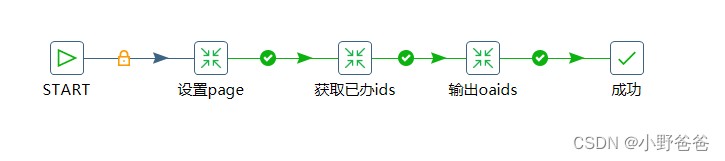
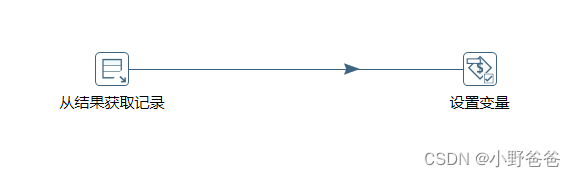
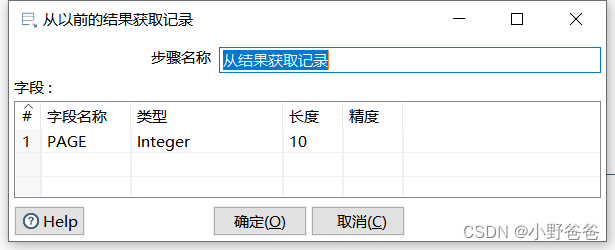
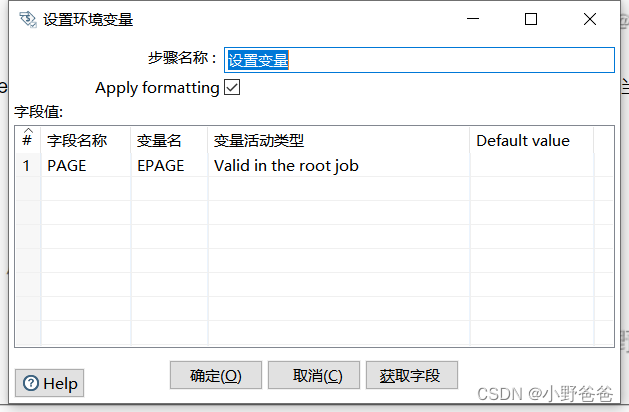
- 设置page,目的是从上一步的结果中获取页数*1000这个值,然后把这个值放到当前变量中
? ? ? ? ? ?
?
? ? ? ? ?
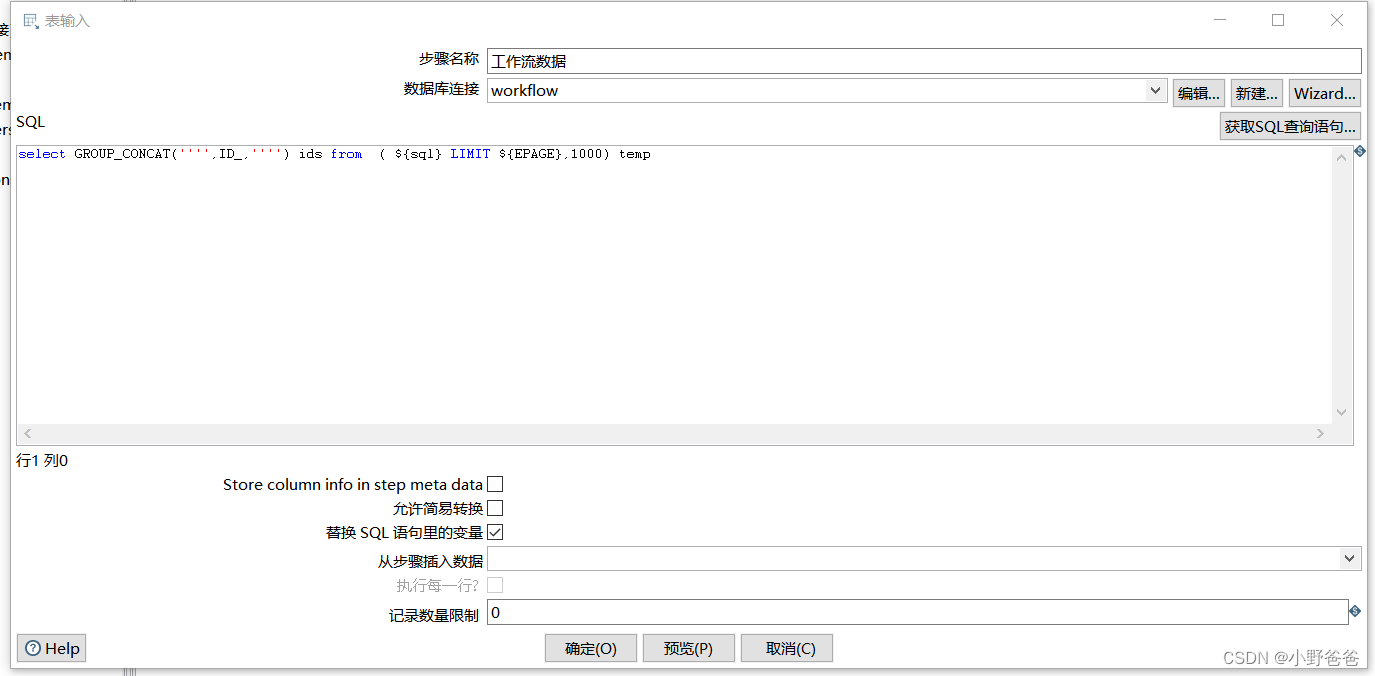
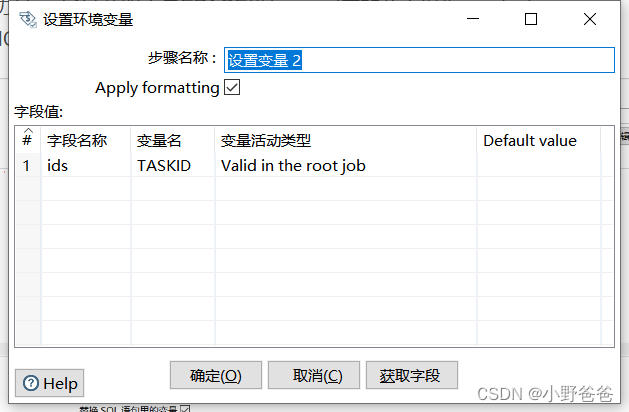
? ? ? ?2. 获取已办ids,通过获取变量EPAGE进行mysql库的分页操作,把获取的id集合放入变量中,select GROUP_CONCAT('''',ID_,'''') ids from ?( ${sql} LIMIT ${EPAGE},1000) temp
? ? ??
? ? ??
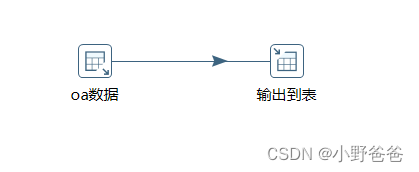
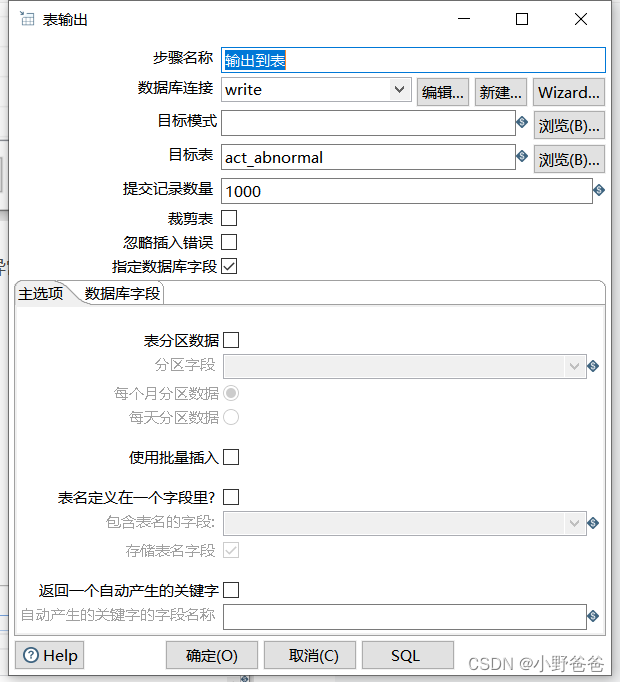
? ? ?3.输出oaids,根据上一步的ids,查询oracle库的异常数据,并将异常数据输出到最开始建的表中
? ? ?

文章来源:https://blog.csdn.net/lihongjing/article/details/135416400
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!