Java / Scala - Trie 树简介与应用实现

目录
一.引言
Trie 树即字典树,又称为单词查找树或键树,是一种树形结构,常用于统计,排序和保存大量的字符串,所以经常被搜索引擎系统用于文本词频统计。
◆ 优点 -?利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
◆ 思想?- 其核心思想是空间换时间,通过拆分字符串并存储换取查询的高效率
二.Tire 树简介
1.树 Tree
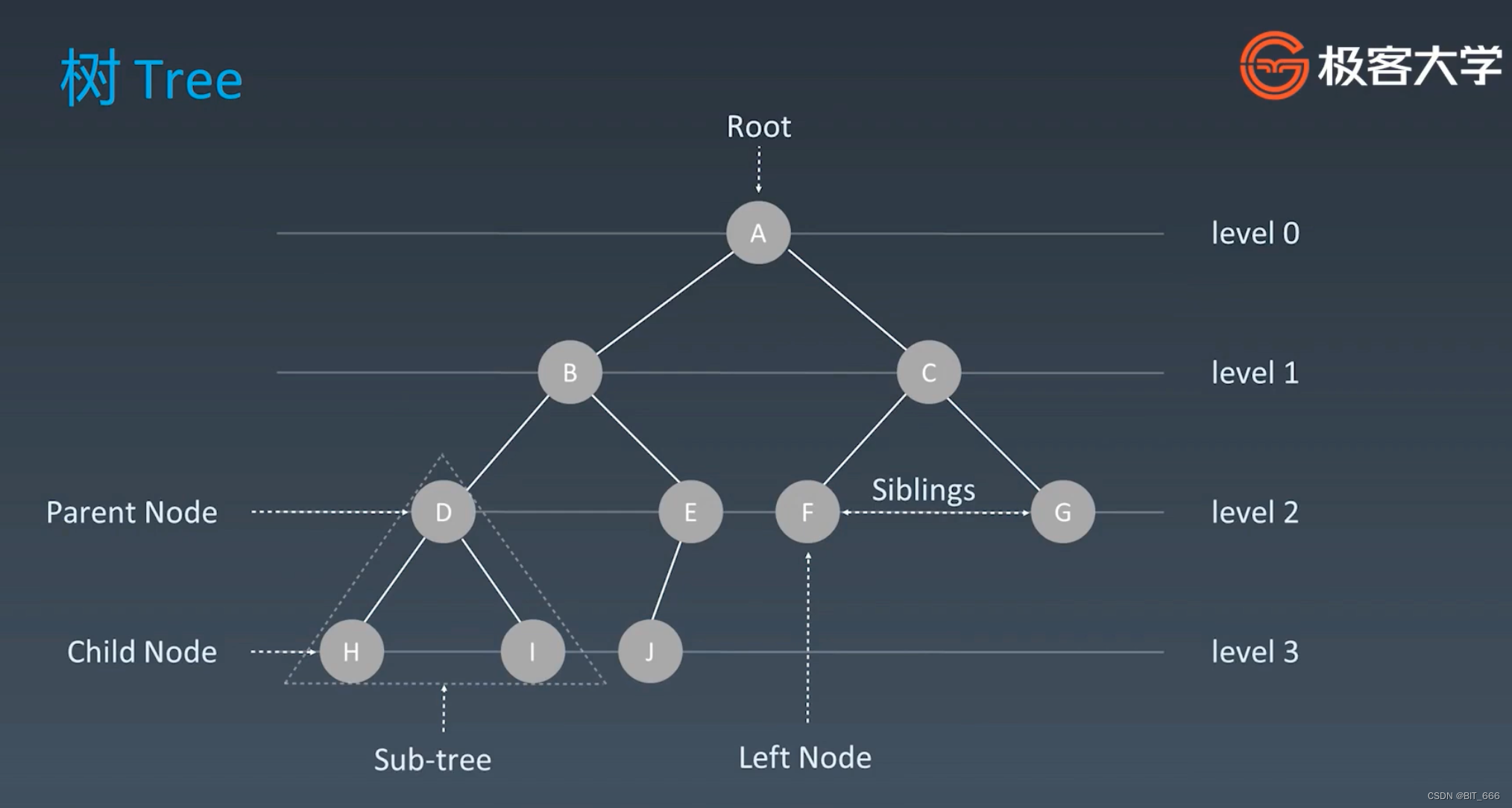
上面是最常见的树的形态,其拥有根节点 root,有左右的 sub-tree 子树,每个父结点 Parent Node 可能拥有子节点 Child Node,也有可能没有子节点,此时为 None。Siblings 代表同级的兄弟姐妹节点,Level 代表树的深度即层数。
2.二叉搜索树 Binary Search Tree
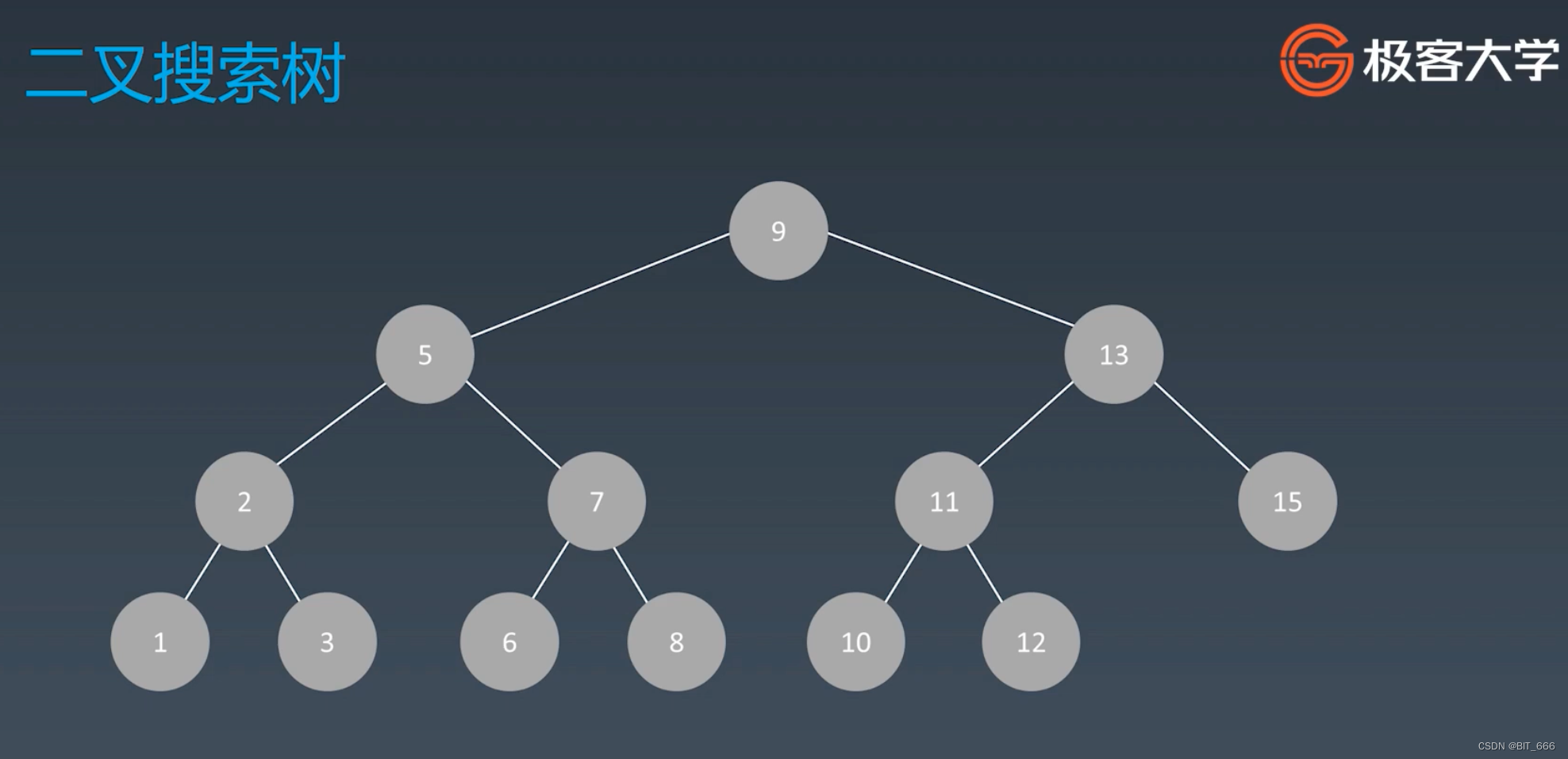
二叉搜索树(Binary Search Tree,简称 BST),又被称为二叉查找树、排序二叉树,是指一个空树或者具备下列性质的二叉树:
◆?若任意节点的左子树不为空,则左子树上所有节点的值都小于它的根节点的值。
◆?若任意节点的右子树不为空,则右子树上所有节点的值都大于它的根节点的值。 ?
◆?任意节点的左、右子树也分别为二叉搜索树。 ?
◆?没有键值相等的节点(即相同的元素只能出现一次)。
其具备以下特性:
◆?中序遍历 - 对 BST 进行中序遍历会得到一个有序的序列。这是因为在中序遍历的过程中,先访问左子节点(较小),再访问当前节点,最后访问右子节点(较大)。
◆?查找效率 - 在 BST 中查找一个元素的平均时间复杂度和树的深度有关,理想情况下,即 BST 是平衡的时候,时间复杂度是 O(log n),其中 n 是树中节点的数量。但是在最坏情况下,如树完全不平衡(退化成链表),查找时间复杂度退化为O(n)。
◆?插入和删除操作 - 插入和删除也有可能改变树的结构。BST 的插入操作是指在满足上述性质的情况下,将一个新节点插入到树中。删除操作则可能涉及到重新调整树的结构,以保持二叉搜索树的性质。
3.字典树 Trie Tree
3.1 基本概念
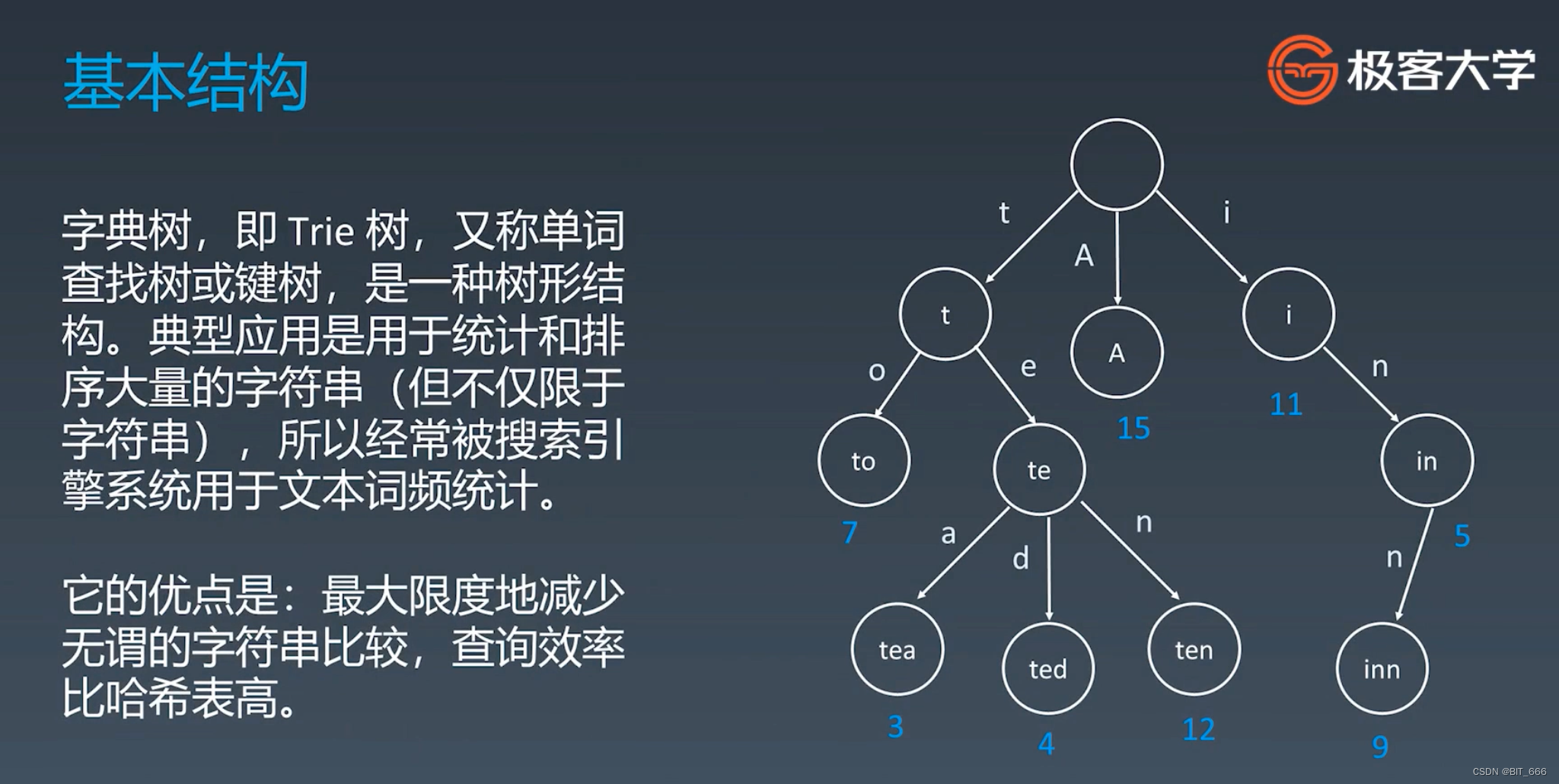
注意这里 Trie 树不是二叉树,而是一颗多叉树,具体分多少叉要根据我们的实际场景来定。例如我们 Trie 树要存储所有英文单词,那理论上每一个父结点 Parent Node 要分 26 个子节点 Child Node,因为英文有 26 个英文字母。Trie 树具备如下基本性质:
◆ 结构本身不存储完整单词,而是存储每个细粒度的拆分项,例如单词搜索则存储字母
◆ 结从根结点到某一结点,将路径上的字符相连,为该结点对应的字符串
◆ 每个结点的所有子结点路径代表的字符都不相同,这里其实代表没有重复字符串结点
3.2 额外信息
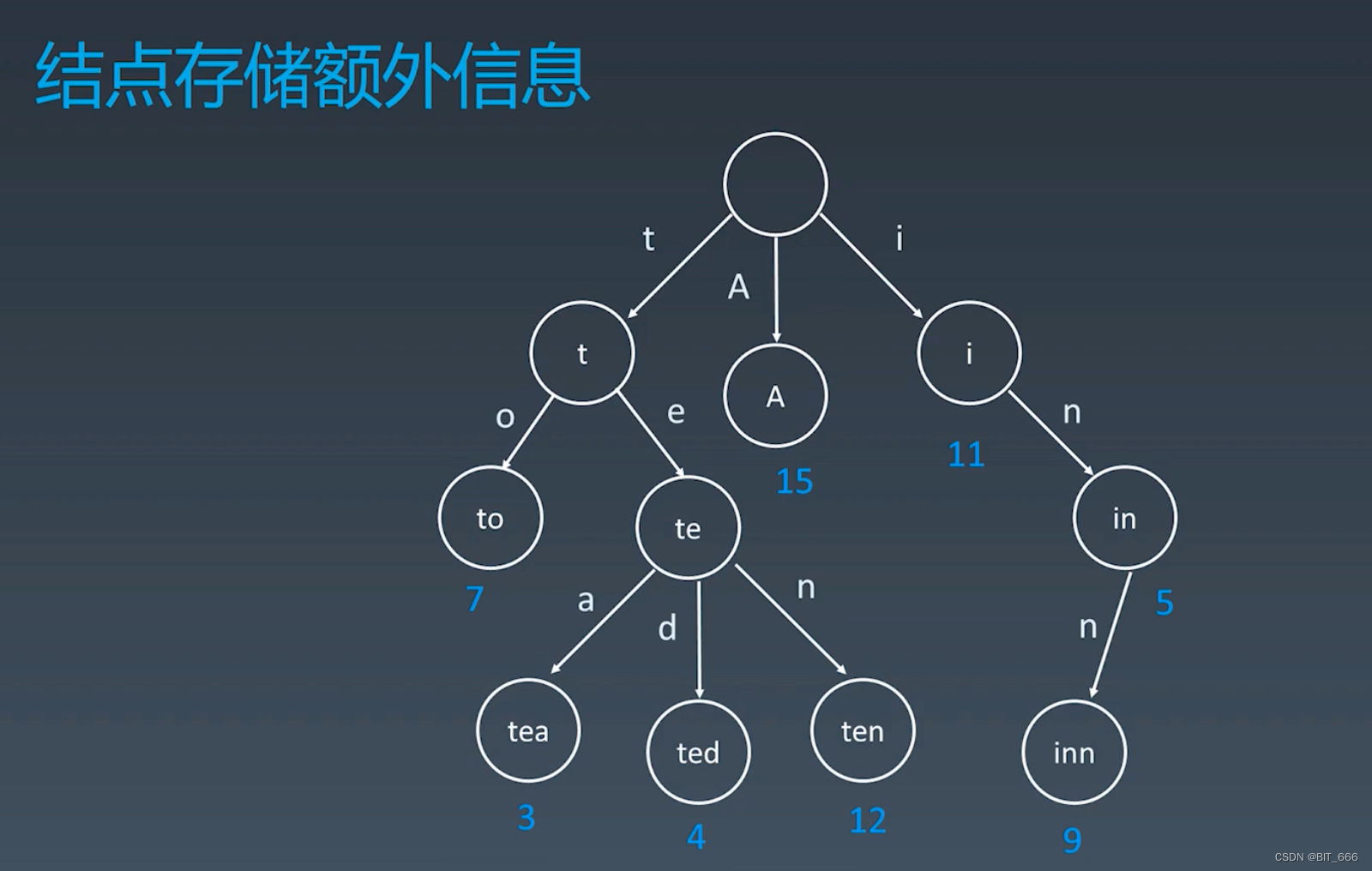
每个 Node 结点除了存储对应的字符外,其还可以具备其自己的属性,最简单的,上面的示例中给出了对应字符串的出现频次,这可以作为搜索推荐的参考依据,如果是代码,其额外信息可以作为一个 Class 存在,内部包含该节点多个属性,例如字符串对应的领域、频率、长度、适用范围等等。?说到词频,也让我们想起来 Word2vec 里用到的霍夫曼树,其在构造编码时也考虑了词频的因素,使得词频高的词可以尽可能快的找到。
3.3?结点实现

这里对于每个 Node 而言,结点就不存在 Left 和 Right 的概念了,而是直接对应下一个可能的字符串,选定哪个字符串,就到下一个字符串对应的 Node 上。如果我们认为是简单单词且不区分大小写,我们可以认为每个 Node 最多有 26 个分叉结点,但如果有更多字符或特殊符号的加入,那么多叉树会有更多的分叉。如果一个结点指向 null 代表其没有儿子结点,此时连接其路径上的字符即可得到该结点对应的字符串表示。
3.4 查找与存储
◆ 存储
假设是上面提到的英文单词查找,且不区分大小写,此时最坏的情况为 26 叉树,每分叉一次,一个结点就多 26 个叉,这样的指数分叉对于存储空间还是有很大的消耗。
◆ 查找
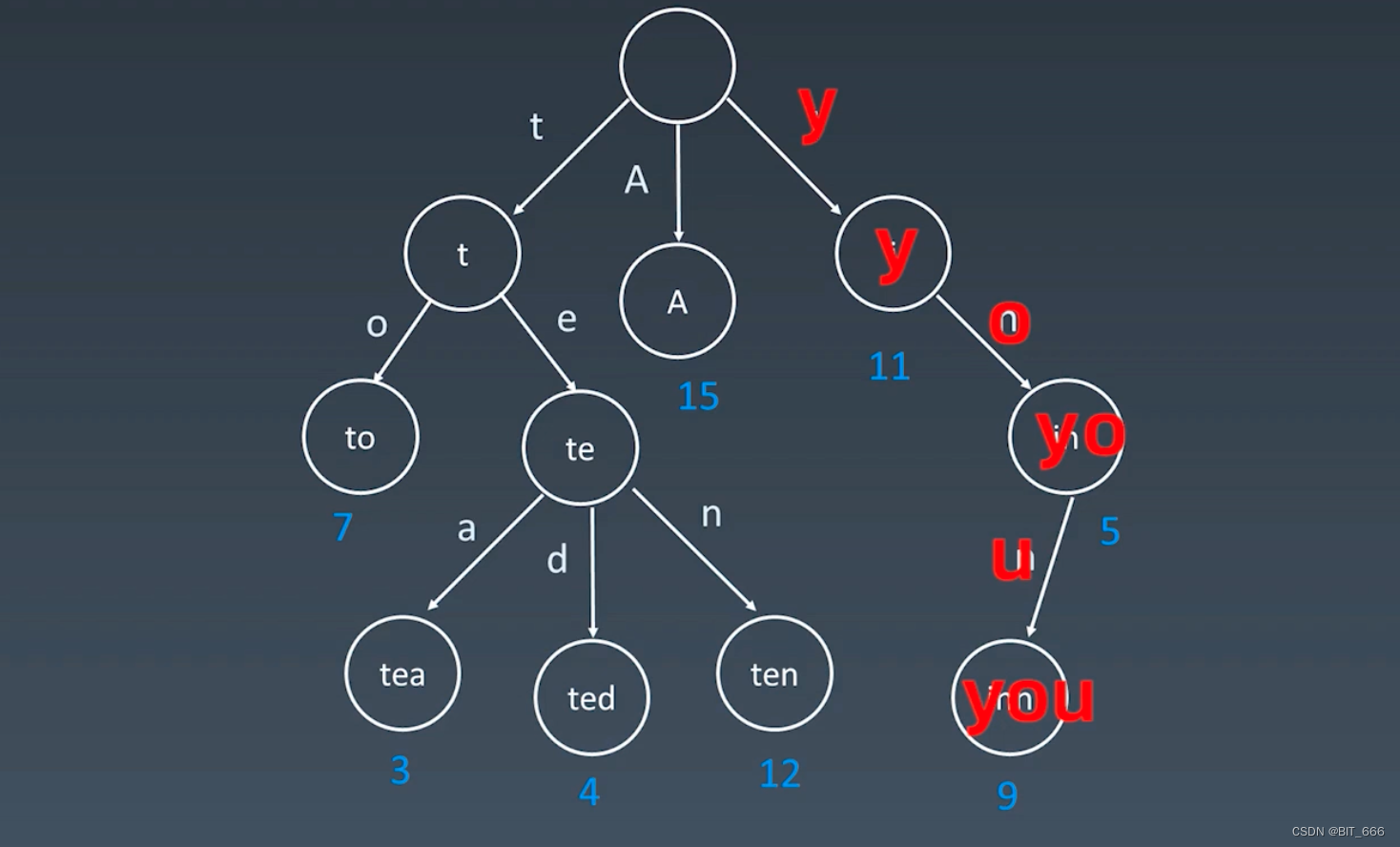
相比于存储的消耗,查找的速度会快很多,因为查找的次数是和单词的字符量匹配的,常见的英文单词字符量在 10 左右,那我们只需要 10 次的常数时间就可以查到,以 you 为例,只需要 3 步就可以找到。但如果是用二分查找等方法,由于整个字典集的数量 n 特别大,即使排好序也是 Log(n) 的查找效率,会比 Trie 树查找次数多很多。这也体现了我们开头说的 Trie 树的核心思想: 空间换时间。其实这个概念不光是 Trie 树,很多算法都会用到这个思想,将时间复杂度降低,空见复杂度提升。
三.Trie 树应用
1.应用场景
因为 Trie 树公共前缀的使用, 所以它十分适合搜索与输入法拓展等领域,当我们输入了前面的公共前缀,其可以根据词频很容易的给出后面的候选。?实际场景中应用较多的是 Aho-Corasick 算法,其适用于确定性的、完全匹配的字符串搜索场景,它能够高效地检测出预定义的关键词是否在给定文本中出现。针对每一次输入,算法都能找出所有存在的关键词匹配。
2.Java / Scala 实现
2.1?Pom 依赖
<!-- https://mvnrepository.com/artifact/org.ahocorasick/ahocorasick -->
<dependency>
<groupId>org.ahocorasick</groupId>
<artifactId>ahocorasick</artifactId>
<version>0.6.3</version>
</dependency>2.2?关键词匹配
import org.ahocorasick.trie.{Emit, Token, Trie}
// 初始化并构建Trie
val trie = Trie.builder()
.addKeyword("hers")
.addKeyword("his")
.addKeyword("she")
.addKeyword("he")
.build()
// 搜索文本
val text = "she sells sea shells by the sea shore"
// 执行搜索
val tokens: java.util.Collection[Token] = trie.tokenize(text)
// 注意这里使用Java转Scala的集合转换
import scala.collection.JavaConverters._
for (token <- tokens.asScala) {
if (token.isMatch) {
// 打印匹配的词条和位置
println(s"Found match: ${token.getFragment} at position ${token.getEmit.getStart}")
}
}- addKeyword 用于添加关键词到 Trie 树中
- text 为代分析的文本
- tokenize 方法分析文本进行关键词匹配
- isMatch getFragment 获取命中的关键词,getEmit.getStart 与 getEnd 用于获取 Fragment 片段在 text 中的起始位置
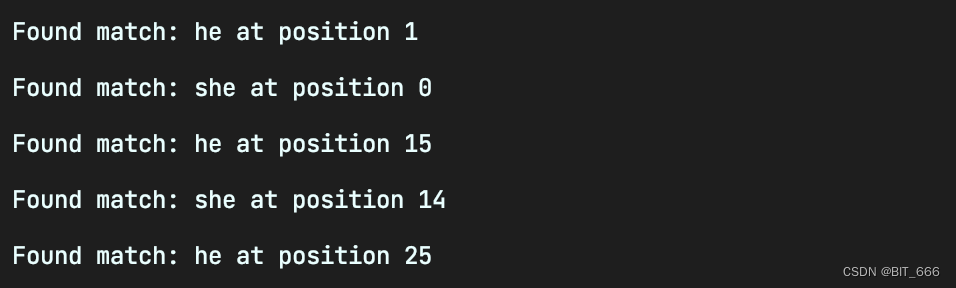
实战场景下,Builder 过程中会添加一个很大的字典内容构造 Trie 树,随后应用 Trie 树进行文本的关键词匹配,判断目标文本是否命中字典中给定的关键字。
四.总结
上面就是 Trie 树的简单介绍与应用。如果想要开发类似 Google 的关键词搜索推荐系统要比使用简单的 Aho-Corasick 算法要复杂得多,并且可能需要依赖机器学习和大数据处理技术。 如果你只是想实现一个简单版本的搜索推荐系统,可以考虑一些基础的模糊匹配算法或使用现有的搜索引擎库,比如 Elasticsearch,它内置了自动补全和模糊匹配的功能,同时 Elasticsearch 也能够通过集群分布式架构来处理大规模数据集,非常适用于构建搜索推荐系统。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!