Java 并发编程中的线程池
7 并发编程中的线程池
自定义线程池
package com.rainsun.d7_thread_pool;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayDeque;
import java.util.Deque;
import java.util.HashSet;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
@Slf4j(topic = "c.d1_mypool")
public class d1_mypool {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(
1,
1000, TimeUnit.MILLISECONDS,
1,
(queue, task) -> {
// 1. 一直等待
// queue.put(task);
// 2. 带超时等待
// queue.offer(task, 500, TimeUnit.MILLISECONDS);
// 3. 放弃执行
// log.debug("放弃 {}", task);
// 4. 抛出异常,与放弃执行的区别是后面的任务不会被执行
// throw new RuntimeException("任务执行失败" + task);
// 5. 调用这自己执行任务
task.run();
});
for(int i = 0; i < 3; ++ i){
int j = i;
threadPool.execute(()->{
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("{}", j);
});
}
}
}
// 拒绝策略
@FunctionalInterface
interface RejectPolicy<T>{
void reject(BlockQueue<T> queue, T task);
}
@Slf4j(topic = "c.ThreadPool")
class ThreadPool{
// 任务队列
private BlockQueue<Runnable> taskQueue;
// 线程集合
private HashSet<Worker> workers = new HashSet<>();
// 核心线程数
private int coreSize;
// 获取任务的超时时间
private long timeout;
private TimeUnit timeUnit;
// 拒绝策略
private RejectPolicy<Runnable> rejectPolicy;
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueCapacity, RejectPolicy<Runnable> rejectPolicy) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockQueue<>(queueCapacity);
this.rejectPolicy = rejectPolicy;
}
// 执行任务
public void execute(Runnable task){
// 任务数没有超过 coreSize 时,直接交给 worker 对象执行
// 如果任务数超过 coreSize 时,加入任务队列 taskQueue 暂存
synchronized (workers){
if(workers.size() < coreSize){
Worker worker = new Worker(task);
log.debug("新增 worker{}, task{}", worker, task);
workers.add(worker);
worker.start();
}else{
// taskQueue.put(task);
/**
* 拒绝策略:
* 1. 一直等待
* 2. 带超时的等待
* 3. 放弃任务执行
* 4. 抛出异常
* 5. 调用者自己执行任务
*/
taskQueue.tryPut(rejectPolicy, task);
}
}
}
class Worker extends Thread{
private Runnable task;
public Worker(Runnable task){
this.task = task;
}
@Override
public void run(){
// 执行任务
// 1. task不为空,执行任务
// 2. task 为空,则接着从任务队列获取新任务再执行任务
while(task != null || (task = taskQueue.poll(timeout, timeUnit)) != null){
try {
log.debug("正在执行任务...{}", task);
task.run();
}catch (Exception e){
e.printStackTrace();
}finally {
task = null;
}
}
synchronized(workers){
log.debug("worker 被移除 {}", this);
workers.remove(this);
}
}
}
}
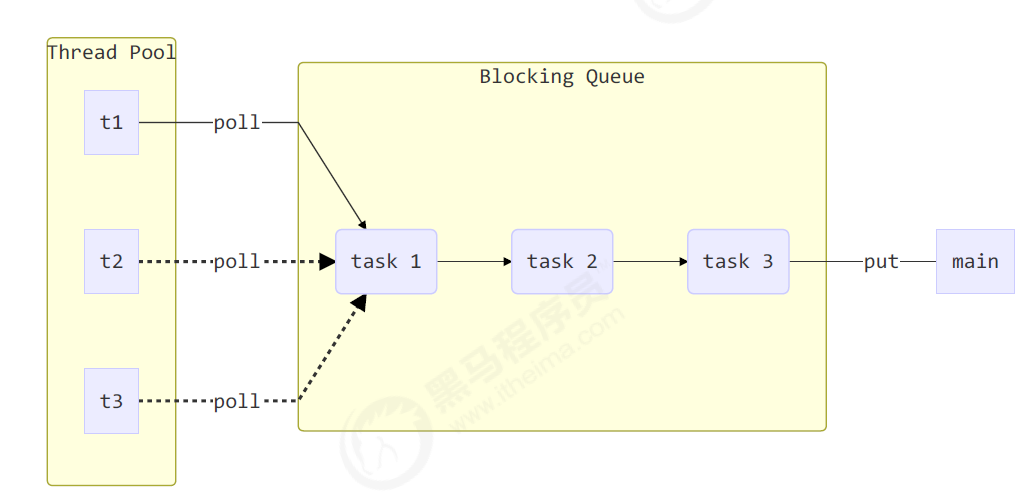
/* 消费者生产者模型 */
@Slf4j(topic = "c.BlockQueue")
class BlockQueue<T>{
// 1. 任务队列
private Deque<T> queue = new ArrayDeque<>();
// 2. 锁
private ReentrantLock lock = new ReentrantLock();
// 3. 生产者条件变量
private Condition fullWaitSet = lock.newCondition();
// 4. 消费者条件变量,获取 task 任务
private Condition emptyWaitSet = lock.newCondition();
// 5. 容量
private int capacity;
public BlockQueue(int capacity) {
this.capacity = capacity;
}
// 带超时的阻塞获取
public T poll(long timeout, TimeUnit unit){
lock.lock();
try {
// 将 timeout 时间统一转换为 纳秒
long nanos = unit.toNanos(timeout);
while(queue.isEmpty()){
try{
if(nanos <= 0){
return null;
}
// 返回剩余等待时间
nanos = emptyWaitSet.awaitNanos(nanos);
}catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal();
return t;
} finally {
lock.unlock();
}
}
// 获取任务
public T take(){
lock.lock();
try {
while(queue.isEmpty()){
try{
emptyWaitSet.await();
}catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal();
return t;
} finally {
lock.unlock();
}
}
// 添加任务
public void put(T task){
lock.lock();
try {
while(queue.size() == capacity){
try{
log.debug("等待加入任务队列 {}", task);
fullWaitSet.await();
}catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("加入任务队列 {}", task);
queue.addLast(task);
emptyWaitSet.signal();
}finally {
lock.unlock();
}
}
// 具有超时时间的阻塞添加
public boolean offer(T task, long timeout, TimeUnit timeUnit){
lock.lock();
try {
long nanos = timeUnit.toNanos(timeout);
while(queue.size() == capacity){
try{
if(nanos <= 0){
return false;
}
log.debug("等待加入任务队列 {}", task);
nanos = fullWaitSet.awaitNanos(nanos);
}catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("加入任务队列 {}", task);
queue.addLast(task);
emptyWaitSet.signal();
return true;
}finally {
lock.unlock();
}
}
public int getSize(){
lock.lock();;
try {
return queue.size();
}finally {
lock.unlock();
}
}
// 带有 用户自定义拒绝策略 的任务添加
public void tryPut(RejectPolicy<T> rejectPolicy, T task){
lock.lock();;
try {
if(queue.size() == capacity){
rejectPolicy.reject(this, task);
}else{
log.debug("加入任务队列 {}", task);
queue.addLast(task);
emptyWaitSet.signal();
}
}finally {
lock.unlock();
}
}
}
ThreadPoolExecutor
线程池状态
ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量
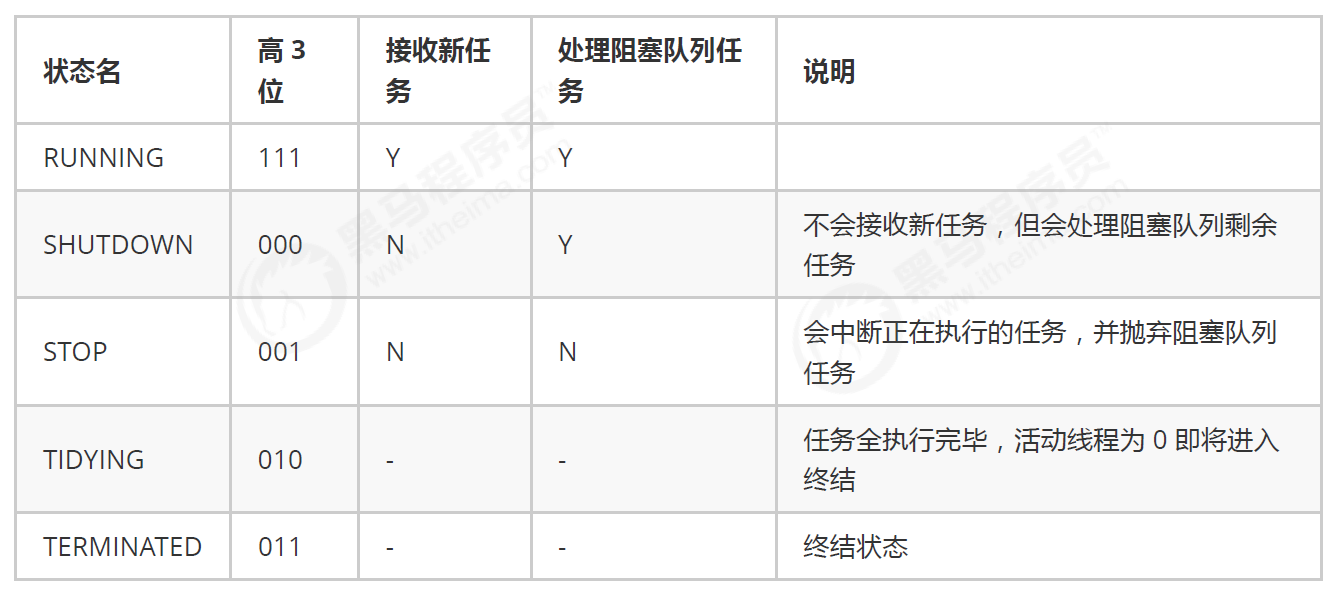
从数字上比较,TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING
这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 cas 原子操作进行赋值
// c 为旧值, ctlOf 返回结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// rs 为高 3 位代表线程池状态, wc 为低 29 位代表线程个数,ctl 是合并它们
private static int ctlOf(int rs, int wc) { return rs | wc; }
构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize 核心线程数目 (最多保留的线程数)
- maximumPoolSize 最大线程数目
- keepAliveTime 生存时间 - 针对救急线程
- unit 时间单位 - 针对救急线程
- workQueue 阻塞队列
- threadFactory 线程工厂 - 可以为线程创建时起个好名字
- handler 拒绝策略
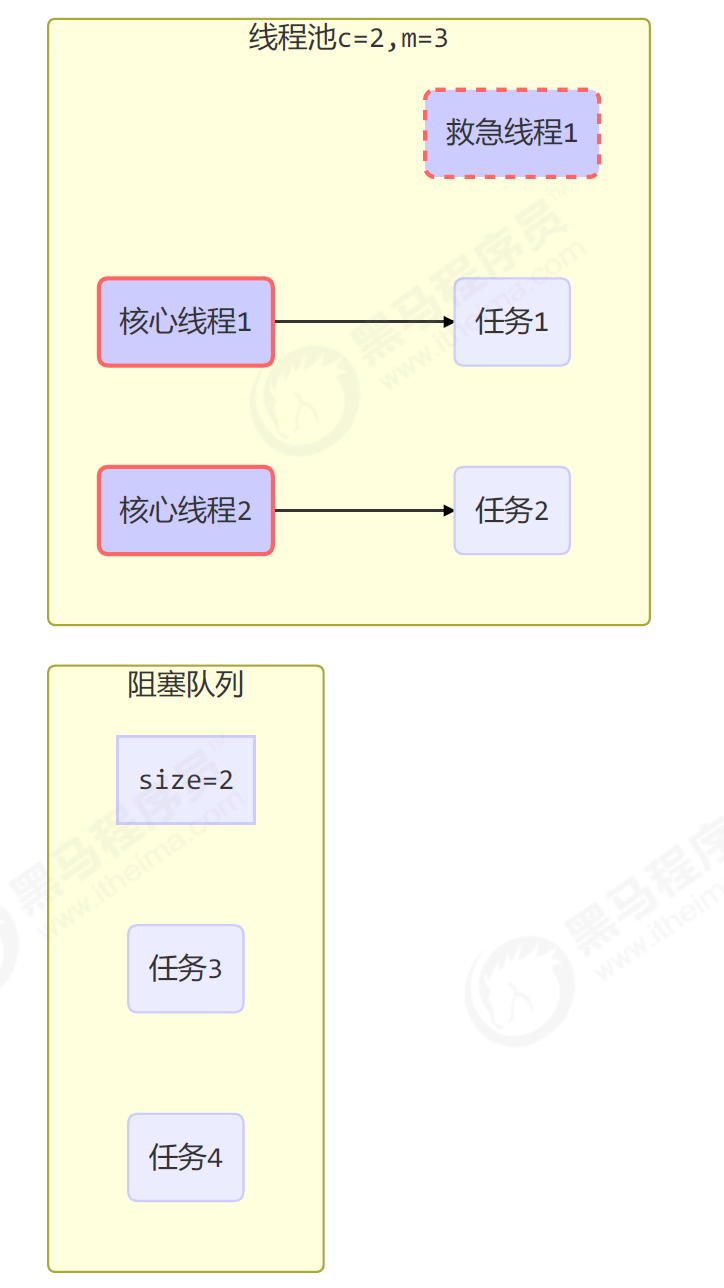
工作方式:
线程池中分核心线程核救急线程,任务首先会交给核心线程运行。
如果核心线程满了,就会在阻塞队列中等待。
如果阻塞队列也满了,就会交给救急线程运行,当救急线程运行完了就会结束,但是核心线程会一直执行,不会结束(即使没有任务)。
当救急线程也满了,新任务就会执行拒绝策略
-
线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
-
当线程数达到 corePoolSize 并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue 队列排队,直到有空闲的线程。
-
如果队列选择了有界队列,那么任务超过了队列大小时,会创建maximumPoolSize - corePoolSize 数目的线程来救急。
-
如果线程到达 maximumPoolSize 仍然有新任务这时会执行拒绝策略。拒绝策略 jdk 提供了 4 种实现,其它著名框架也提供了实现
-
AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略
-
CallerRunsPolicy 让调用者运行任务
-
DiscardPolicy 放弃本次任务
-
DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之
-
Dubbo 的实现,在抛出
RejectedExecutionException 异常之前会记录日志,并 dump 线程栈信息,方便定位问题
Netty 的实现,是创建一个新线程来执行任务
ActiveMQ 的实现,带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略
PinPoint 的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略
-
-
当高峰过去后,超过corePoolSize 的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由keepAliveTime 和 unit 来控制。

根据这个构造方法,JDK Executors 类中提供了众多工厂方法来创建各种用途的线程池
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
特点
- 核心线程数 == 最大线程数(没有救急线程被创建),因此也无需超时时间
- 阻塞队列是无界的,可以放任意数量的任务
- 评价 适用于任务量已知,相对耗时的任务
newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
特点
- 核心线程数是 0, 最大线程数是 Integer.MAX_VALUE,救急线程的空闲生存时间是 60s,意味着
- 全部都是救急线程(60s 后可以回收)
- 救急线程可以无限创建
- 队列采用了 SynchronousQueue 实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货)
SynchronousQueue<Integer> integers = new SynchronousQueue<>();
new Thread(() -> {
try {
log.debug("putting {} ", 1);
integers.put(1);
log.debug("{} putted...", 1);
log.debug("putting...{} ", 2);
integers.put(2);
log.debug("{} putted...", 2);
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t1").start();
sleep(1);
new Thread(() -> {
try {
log.debug("taking {}", 1);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t2").start();
sleep(1);
new Thread(() -> {
try {
log.debug("taking {}", 2);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t3").start();
只有 take 了,才能 put 进去:
11:48:15.500 c.TestSynchronousQueue [t1] - putting 1
11:48:16.500 c.TestSynchronousQueue [t2] - taking 1
11:48:16.500 c.TestSynchronousQueue [t1] - 1 putted...
11:48:16.500 c.TestSynchronousQueue [t1] - putting...2
11:48:17.502 c.TestSynchronousQueue [t3] - taking 2
11:48:17.503 c.TestSynchronousQueue [t1] - 2 putted...
适用情况:整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲 1分钟后释放线程。 适合任务数比较密集,但每个任务执行时间较短的情况
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
使用场景:
希望多个任务排队执行。线程数固定为 1,任务数多于 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放。
区别:
-
自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一个线程,保证池的正常工作
-
Executors.newSingleThreadExecutor() 线程个数始终为1,不能修改
- FinalizableDelegatedExecutorService 应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法
-
Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改
- 对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用setCorePoolSize 等方法进行修改
提交任务
// 执行任务
void execute(Runnable command);
// 提交任务 task,用返回值 Future 获得任务执行结果
<T> Future<T> submit(Callable<T> task);
// 提交 tasks 中所有任务
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
// 提交 tasks 中所有任务,带超时时间
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long t imeout, TimeUnit unit)throws InterruptedException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消,带超时时间
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
关闭线程池
shutdown
线程池状态变为 SHUTDOWN
- 不会接收新任务
- 但已提交任务会执行完
- 此方法不会阻塞调用线程的执行
void shutdown();
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改线程池状态
advanceRunState(SHUTDOWN);
// 仅会打断空闲线程
interruptIdleWorkers();
onShutdown(); // 扩展点 ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
// 尝试终结(没有运行的线程可以立刻终结,如果还有运行的线程也不会等)
tryTerminate();
}
shutdownNow
/*
线程池状态变为 STOP
- 不会接收新任务
- 会将队列中的任务返回
- 并用 interrupt 的方式中断正在执行的任务
*/
List<Runnable> shutdownNow();
public List<Runnable> shutdownNow() {
Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改线程池状态
advanceRunState(STOP);
// 打断所有线程
interruptWorkers();
// 获取队列中剩余任务
tasks = drainQueue();
} finally {
mainLock.unlock();
}
// 尝试终结
tryTerminate();
return tasks;
}
其他方法:
// 不在 RUNNING 状态的线程池,此方法就返回 true
boolean isShutdown();
// 线程池状态是否是 TERMINATED
boolean isTerminated();
// 调用 shutdown 后,由于调用线程并不会等待所有任务运行结束,因此如果它想在线程池 TERMINATED 后做些事
情,可以利用此方法等待
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
任务调度线程池
指定一段时间后运行线程
在『任务调度线程池』功能加入之前,可以使用 java.util.Timer 来实现定时功能,Timer 的优点在于简单易用,但由于所有任务都是由同一个线程来调度,因此所有任务都是串行执行的,同一时间只能有一个任务在执行,前一个任务的延迟或异常都将会影响到之后的任务。
ScheduledExecutorService
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
// 添加两个任务,希望它们都在 1s 后执行
executor.schedule(() -> {
System.out.println("任务1,执行时间:" + new Date());
try { Thread.sleep(2000); } catch (InterruptedException e) { }
}, 1000, TimeUnit.MILLISECONDS);
executor.schedule(() -> {
System.out.println("任务2,执行时间:" + new Date());
}, 1000, TimeUnit.MILLISECONDS);
scheduleAtFixedRate 例子:
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleAtFixedRate(() -> {
log.debug("running...");
}, 1, 1, TimeUnit.SECONDS);
scheduleAtFixedRate 例子(任务执行时间超过了间隔时间):
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleAtFixedRate(() -> {
log.debug("running...");
sleep(2);
}, 1, 1, TimeUnit.SECONDS);
输出分析:一开始,延时 1s,接下来,由于任务执行时间 > 间隔时间,间隔被『撑』到了 2s
scheduleWithFixedDelay 例子:(与上面AtFixedRate 是设置的线程结束后的延时时间)
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleWithFixedDelay(()-> {
log.debug("running...");
sleep(2);
}, 1, 1, TimeUnit.SECONDS);
输出分析:一开始,延时 1s,scheduleWithFixedDelay 的间隔是 上一个任务结束 <-> 延时 <-> 下一个任务开始 所以间隔都是 3s
正确处理执行任务异常
方法1:主动捉异常(任务自己处理异常)
ExecutorService pool = Executors.newFixedThreadPool(1);
pool.submit(() -> {
try {
log.debug("task1");
int i = 1 / 0;
} catch (Exception e) {
log.error("error:", e);
}
});
方法2:使用 Future
ExecutorService pool = Executors.newFixedThreadPool(1);
Future<Boolean> f = pool.submit(() -> {
log.debug("task1");
int i = 1 / 0;
return true;
});
log.debug("result:{}", f.get()); // get 中封装了异常信息
Tomcat 线程池
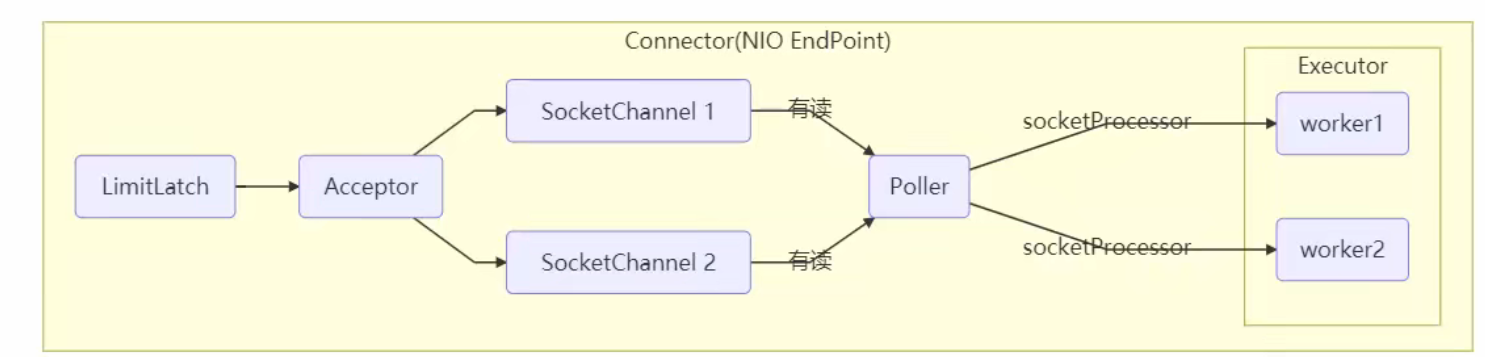
- LimitLatch 用来限流,可以控制最大连接个数,类似 J.U.C 中的 Semaphore
- Acceptor 只负责【接收新的 socket 连接】
- Poller 只负责监听 socket channel 是否有【可读的 I/O 事件】
- 一旦可读,封装一个任务对象(socketProcessor),提交给 Executor 线程池处理
- Executor 线程池中的工作线程最终负责【处理请求】
Tomcat 线程池扩展了 ThreadPoolExecutor,行为稍有不同
- 如果总线程数达到 maximumPoolSize
- 这时不会立刻抛 RejectedExecutionException 异常
- 而是再次尝试将任务放入队列,如果还失败,才抛出 RejectedExecutionException 异常
Fork/Join
概念:
Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型运算
所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解
Fork/Join 在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运算效率
Fork/Join 默认会创建与 cpu 核心数大小相同的线程池
使用:
提交给 Fork/Join 线程池的任务需要继承 RecursiveTask(有返回值)或 RecursiveAction(没有返回值),例如下面定义了一个对 1~n 之间的整数求和的任务
@Slf4j(topic = "c.d2_fork_join")
public class d2_fork_join {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new MyTask((5))));
}
}
class MyTask extends RecursiveTask<Integer>{
private int n;
public MyTask(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if(n == 1) return 1;
MyTask t1 = new MyTask(n-1);
t1.fork(); // fork 让 pool 中的一个线程执行 t1 任务,也就是执行t1中的compute方法
int result = n + t1.join(); // join 获取任务结果
return result;
}
}
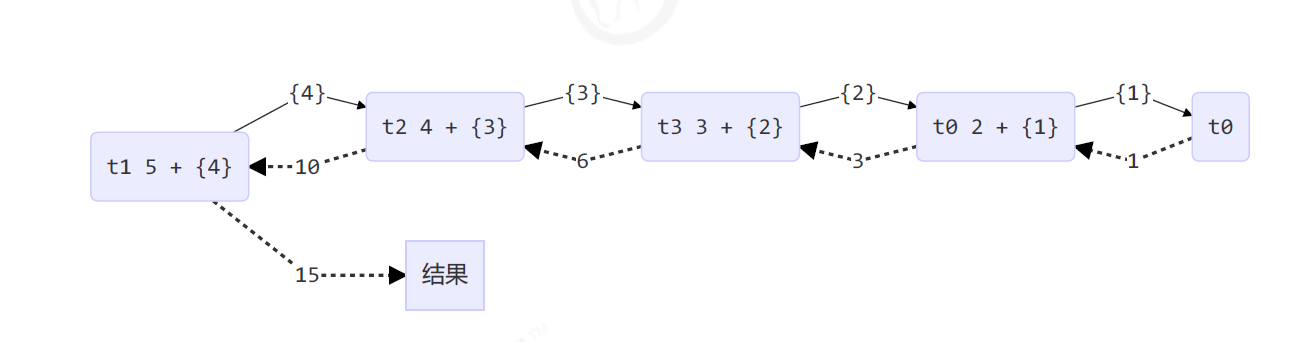
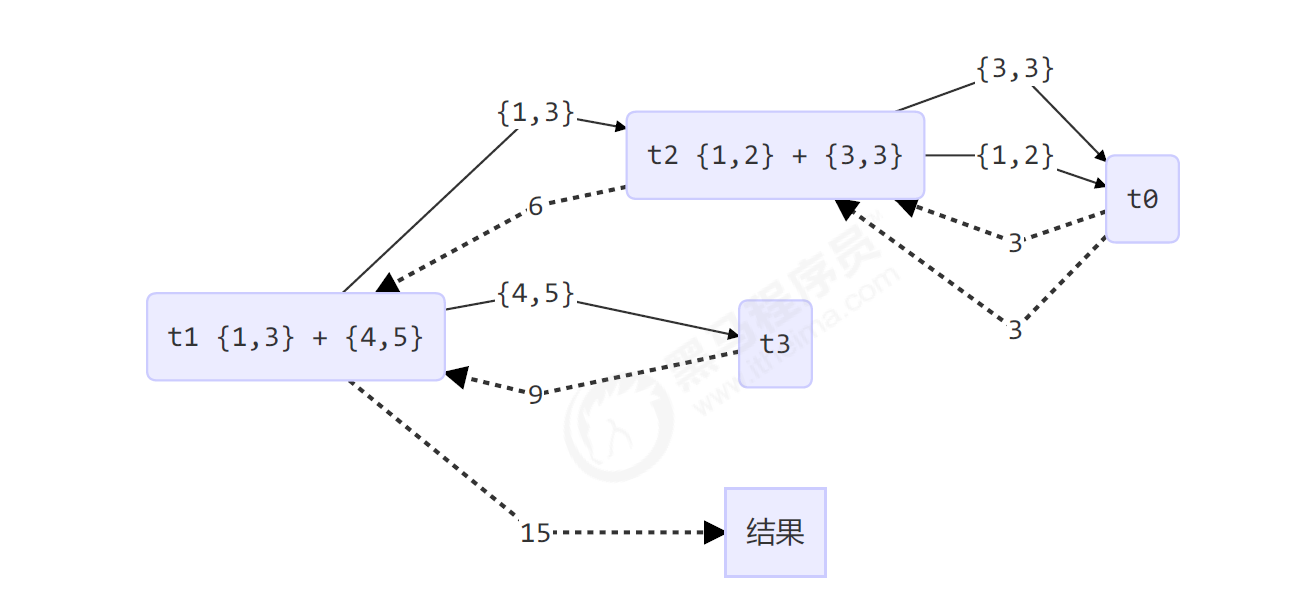
改进:
task(5)等待task(4),任务之间具有依赖关系
合理的拆分可以减少依赖关系,增大并行度
@Slf4j(topic = "c.d2_fork_join")
public class d2_fork_join {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new AddTask(0, 5)));
}
}
class AddTask extends RecursiveTask<Integer>{
private int begin;
private int end;
public AddTask(int begin, int end) {
this.begin = begin;
this.end = end;
}
@Override
protected Integer compute() {
if(begin == end) return begin;
if(end - begin == 1) return end + begin;
int mid = (end+begin) / 2;
AddTask t1 = new AddTask(begin, mid);
AddTask t2 = new AddTask(mid + 1, end);
t1.fork();
t2.fork();
return t1.join() + t2.join();
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!