【学习笔记】Java函数式编程02——Stream流
三、Stream流
3.1 概述
Stream流是JDK8提供的新特性。使用的是函数式编程的模式。
它可以被用来对集合或数组进行链状流式的操作。
和之前的IO流进行区分,IO流是针对文件和数据操作
可以更方便的对集合和数据进行操作。
3.2 快速入门
3.2.1 数据准备
依赖准备:lombok+hutool工具包即可
package com.zhc.demo02.entity;
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.lang.UUID;
import cn.hutool.core.util.RandomUtil;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.NoArgsConstructor;
import java.util.ArrayList;
import java.util.List;
/**
* @Author zhuhuacong
* @Date: 2023/12/12/ 10:40
* @description 作者
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@EqualsAndHashCode
public class Author {
private Long id;
private String name;
private Integer age;
private String intro;
private List<Book> books;
public static List<Author> getAuthor(){
List<Author> authors = new ArrayList<>();
Snowflake snowflake = new Snowflake();
for (int i = 0; i < 10; i++) {
Author author = new Author();
List<Book> books = new ArrayList<>();
books.add(getBook(snowflake));
books.add(getBook(snowflake));
books.add(getBook(snowflake));
books.add(getBook(snowflake));
books.add(getBook(snowflake));
author.setAge(RandomUtil.randomInt(20,60));
author.setId(RandomUtil.randomLong());
author.setName(RandomUtil.randomString(5));
author.setIntro(RandomUtil.randomString(100));
author.setBooks(books);
authors.add(author);
}
return authors;
}
public static Book getBook(Snowflake snowflake ){
return new Book(snowflake.nextId(), RandomUtil.randomString(5), RandomUtil.randomString(100), RandomUtil.randomInt(50, 100));
}
}
package com.zhc.demo02.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.NoArgsConstructor;
/**
* @Author zhuhuacong
* @Date: 2023/12/12/ 10:41
* @description 书
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@EqualsAndHashCode
public class Book {
private Long id;
private String name;
private String category;
private Integer score;
}
3.2.2 场景练习
3.2.2.1 场景一、遍历所有作家并打印
方法一、按照原本是方法遍历对象并打印
(略)
方法二、使用stream()流
??使用stream()流的forEach方法
需要注意:
-
java所有的集合类都带有这个stream方法
default Stream<E> stream() { return StreamSupport.stream(spliterator(), false); } -
forEach方法需要传入我们前面学到的
Consumer(消费者)的实现类void forEach(Consumer<? super T> action);
以此记得得出写法如下
List<Author> authors = Author.getAuthor();
authors.stream() // 集合对象的stream方法
.forEach(new Consumer<Author>() {
@Override
public void accept(Author author) {
System.out.println(author + "\n");
}
});
使用省略规则简化后,得到的写法是
authors.stream()
.forEach(author -> System.out.println(author + "\n"));
- 不难发现,使用lambda简化后,代码简介了非常多
3.2.2.2 场景二、打印所以年龄小于18的作家名字,并且注意去重
为了更好的模拟场景。可以将名字和年龄的生成逻辑进行修改。使用如下的方法。
// 类似 author.setName(RandomUtil.randomString("张王李",2));同时难度加大
方法一、传统遍历代码
使用传统方法处理逻辑应该是这样的:
- 遍历集合先找出符合年龄的作家
- 再遍历一次符合条件的作家列表,判断名字是否重复
- 最终打印输出作家对象
方法二、使用stream()流
??distinct()方法
使用这个方法可以对元素进行去重处理。需要注意:
- 该方法的去重逻辑是调用
Object.equals(Object)进行判断,所以在判断POJO实体类时,是需要重写equals和hashCode代码的 - 对于有序流,这个方法是稳定的。如果是无序流,建议先执行
sequential()方法后再进行去重
??filter()方法
过滤器,完整方法如下
Stream<T> filter(Predicate<? super T> predicate);
看到了前一章学习的熟悉的方法Predicate(断言,实现这个函数式接口可以判断是否筛选过滤出该对象
代码如下:(最终优化
// 打印所以年龄小于18的作家名字,并且注意去重
List<Author> authors = Author.getAuthor();
authors.stream()
.distinct()
.filter(author -> author.getAge() < 18)
.forEach( a -> System.out.println(a.getName()+"\t"+a.getAge()));
- 代码非常简介
- 验证结果——正确
3.2.2.3 场景三、基于题目2,注意实现根据作家名称去重
查看打印的结果可以发现,由于stream的distinct()方法是调用equals进行去重的
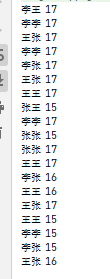
其实结合实际生产中,往往需要根据作家名称去重
代码如下,使用到的map()方法,后续会进行研究
authors.stream()
.filter(a -> a.getAge() < 18)
.map(Author::getName)
.distinct()
.forEach(System.out::println);
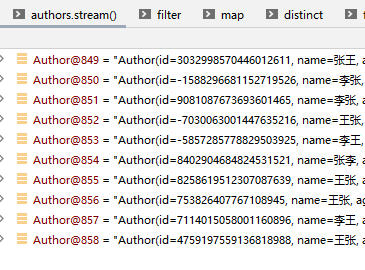
3.2.3 IDEA的stream流调试功能
以场景3为例,我们调用了4个不同的stream流方法,打断点进入调试模式后就可以找到对应的“流调试”按钮

进入该模式后就可以看到我们的刚才的操作了
1、转换为stream
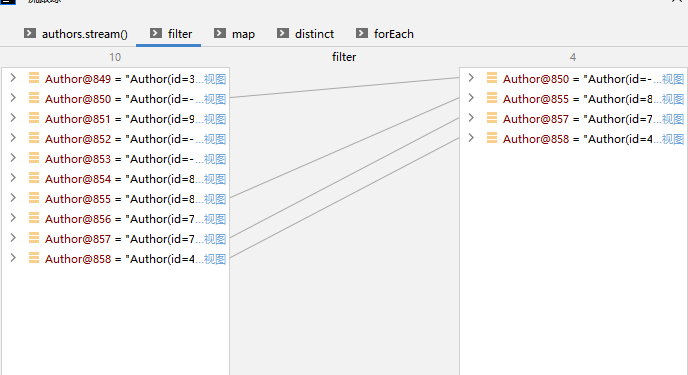
2、过滤
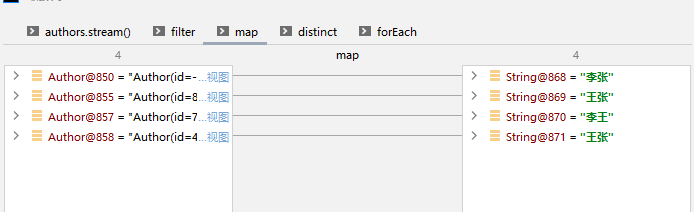
3、提取元素
4、去重
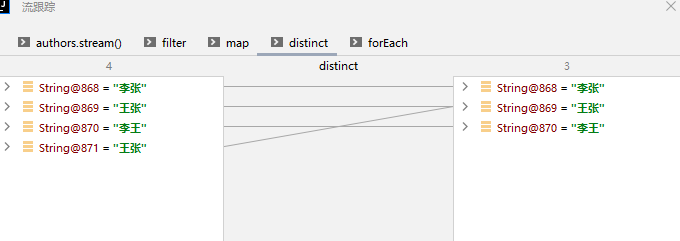
5、遍历
这个就不用看了
3.3 常用操作
流在创建好之后,就需要一些中间操作对集合进行修改
操作完成后,需要结束这一次Stream流,必须要有终结操作,前面的代码才能生效
3.3.1 创建流
创建流的核心思想:将集合转换为流
3.3.1.1 单列集合
像列表、链表、Set就是单列集合
语法:集合对象.stream()(在父类collection已经新增了stream这个方法,可以直接转换
3.3.1.2 数组
语法:Arrays.stream(数组)——使用到了数组的工具类Arrays进行转换操作
或者Stream.of()也可以转换数组——注意这个方法的参数是一个【可变参数列表】,在java的低层,可变参就是一个数组。
3.3.1.3 双列集合
Map本身是无法直接转换为Stream流的,需要转换成单列集合后再转换为stream流
map.entrySet().stream()
3.3.2 中间操作
3.3.2.1 filter
可以对流中的元素进行条件过滤,**符合过滤条件(Predicate返回结果为true)**的才能继续留在流中。
前面已经接触过了,就不做赘述
3.3.2.2 ??map
可以对流中的元素进行计算或者转换。
查看map源码,可以发现,maper传入的是一个Function接口,相当于取定义了一个复杂的类型转换(前一章学到的)
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
做个小练习:将集合中每一个author对象转换为JSON字符串
List<Author> authors = Author.getAuthor();
// 匿名内部类式编程
authors.stream()
.map(new Function<Author, String>() {
@Override
public String apply(Author author) {
return JSON.toJSONString(author);
}
})
.forEach(System.out::println);
// lambda
authors.stream()
.map(author -> JSON.toJSONString(author))
.forEach(System.out::println);
// 跟进一步简写(IDEA提供
authors.stream()
.map(JSON::toJSONString)
.forEach(System.out::println);
通过这个案例可以发现:
- 遵循“省略原则”的返回类型是可推导的,那么匿名内部类就可以进行简写
- IDEA提供的简写方式,进一步简写了传入的参数对象
3.3.2.3 distinct
去除流中的重复元素。
注意:distinct方法是依赖Obiect的equals方法来判断是否是相同对象的。所以需要注意重写equals方法。(前面??distinct()方法提到了,不进行赘述了
3.3.2.4 ??sorted
可以对集合进行排序。
查看源码可以发现sorted方法其实有两种重载的方式:一种是无参,一种是带有函数式接口参数Comparator(比较器)。
关于:无参sorted()
查看源码可知,要求排序的对象去实现Comparable接口,才能进行排序。
如果直接调用,则会抛出异常ClassCastException
举个例子:按作家的年龄进行排序,先使作家类实现Comparable接口,然后添加如下代码
/**
* 比较
*
* @param o o
* @return int -1、0或1,相当于对象小于、等于或大于指定对象。
*/
@Override
public int compareTo(Object o) {
if (o instanceof Author){
Author author = (Author) o;
return this.age.compareTo(author.getAge());
}
return 0;
}
运行验证,通过
authors.stream()
.sorted()
.forEach(System.out::println);
关于顺序,其实不需要特意去记忆,只需要进行一次可测试即可。
关于:有参sorted(Comparator)
源码方法Stream<T> sorted(Comparator<? super T> comparator);
从匿名内部类开始简化
authors.stream()
.sorted(new Comparator<Author>() {
@Override
public int compare(Author o1, Author o2) {
return o1.getAge().compareTo(o2.getAge());
}
})
.forEach(System.out::println);
// lambda简化
authors.stream()
.sorted((o1, o2) -> o1.getAge().compareTo(o2.getAge()))
.forEach(System.out::println);
// idea提供简化
authors.stream()
.sorted(Comparator.comparing(Author::getAge))
.forEach(System.out::println);
值得一提是idea提供的快捷简写方法。(不一定要会写,但是要懂得看)
3.3.2.5 limit
设置流的最大长度,超出的部分将会被抛弃。
- 如果超过最大长度,则不会发生截取
专项练习
:对流中的元素按照年龄进行降序排序,并且要求不能有重复的元素,然后打印其中年龄最大的两个作家的姓名。
补充一下题意,为了体现去重的效果,选择补充根据名字+年龄的字段进行去重
// 匿名内部类写法
authors.stream()
.sorted(new Comparator<Author>() {
@Override
public int compare(Author o1, Author o2) {
return o2.getAge()-o1.getAge();
}
})
.map(new Function<Author, String>() {
@Override
public String apply(Author author) {
return author.getName()+author.getAge();
}
})
.distinct()
.limit(2)
.forEach(System.out::println);
// 简化后写法
authors.stream()
.sorted((o1, o2) -> o2.getAge()-o1.getAge())
.map(author -> author.getName()+author.getAge())
.distinct()
.limit(2)
.forEach(System.out::println);
3.3.2.6 skip
跳过前面的n个元素,返回剩下的元素。
(顾名思义,不做赘述
3.3.2.7 ??flatMap
flatMap的效果和map类似但也有所不同
- map只能将一个对象转换为另一个对象后,作为流中的元素
- 而flatMap可以把一个对象转换成多个对象,作为流中的元素
**如何理解?**比如一个作者拥有多部作品,如果需要从“作家流”取出所有作品book,作为“作品流”,这个时候就可以用到flatMap了。
阅读源码也不难发现,flatMap要求传入的函数式接口Function中唯一的方法,已经定义好的返回的类型Stream
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
举个例子
// 匿名内部类写法
authors.stream()
.flatMap(new Function<Author, Stream<Book>>() {
@Override
public Stream<Book> apply(Author author) {
return author.getBooks().stream();
}
})
.forEach(new Consumer<Book>() {
@Override
public void accept(Book book) {
System.out.println(book);
}
});
匿名内部类在flatMap中是比较繁琐的,因为需要指定 Stream<?>的类型才能保证forEach正常介绍到对象类型
// 简化后
authors.stream()
.flatMap(author -> author.getBooks().stream())
.forEach(System.out::println);
3.3.3 终结操作 to be continued…
终结操作另起一文!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!