MAP: Multimodal Uncertainty-Aware Vision-Language Pre-training Model
问题
多模态语义理解通常需要处理不确定性,这意味着获得的消息往往涉及多个目标。这种不确定性对我们的解释来说是有问题的,包括模式间和模式内的不确定性。人们很少研究这种不确定性的建模,特别是在未标记数据集的预训练和特定任务下游数据集的微调方面。
贡献
- 我们专注于多模态理解的语义不确定性,并提出了一个称为概率分布编码器的新模块,将多模态表示中的不确定性框架为高斯分布。
- 我们开发了三个不确定性感知预训练任务来处理大规模未标记数据集,包括 D-VLC、D-MLM 和 D-ITM 任务。据我们所知,这是利用 VLP 中表示的概率分布的首次尝试。
- 我们将所提出的预训练任务包装到端到端多模态不确定性感知视觉语言预训练模型(称为 MAP)中,用于下游任务。实验表明 MAP 获得了最先进的 (SoTA) 性能。
结构和方法
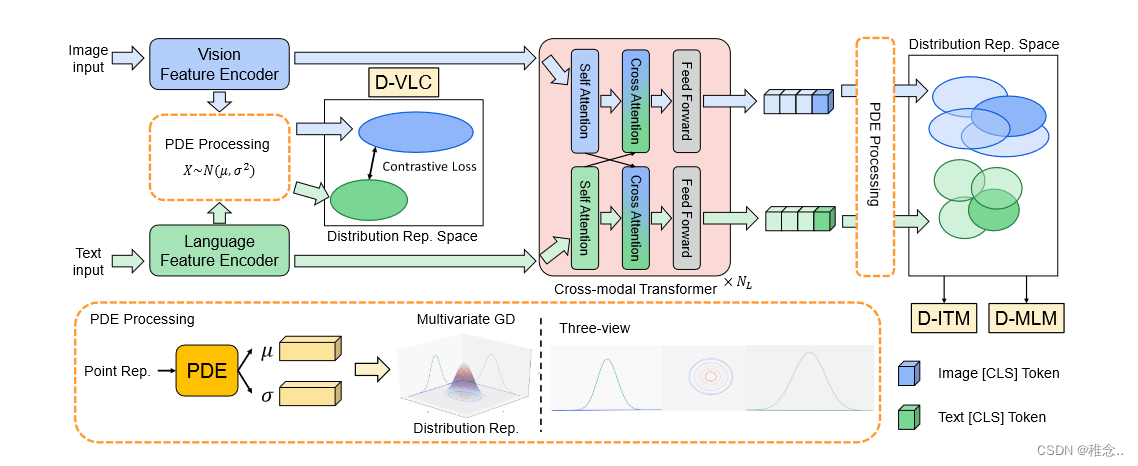
为了提取特征,我们利用图像编码器和语言编码器。具体来说,我们采用 CLIP-ViT 作为图像编码器,采用 RoBERTa-Base 作为语言编码器。
在我们的方法中,图像块序列比文本序列长得多,使得视觉特征的权重太大而无法一起计算注意力分数。为了解决这个问题,我们选择具有两个变压器分支的双流模块,其中自注意力分数是单独计算的。
主要结构有NL层跨模态编码器。每个编码器主要由两个自注意(SA)块和两个交叉注意(CA)块组成。在每种模态的 SA 块中,查询、键和值向量都是从视觉或语言特征线性投影的。在第 i 层的视觉到语言交叉注意力块中,查询向量表示自注意力块之后的语言特征 T ′ i ,键/值向量表示视觉特征 I′ i 。通过采用多头注意力(MHA)操作,CA 块使语言特征能够跨模态学习视觉信息。语言到视觉的 CA 块与视觉到语言的 CA 块类似。带SA和CA的第i层编码器的工作流程如下:
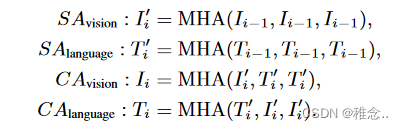
然后利用D-VLC D-MLM D-ITM三个任务来进行模型的训练
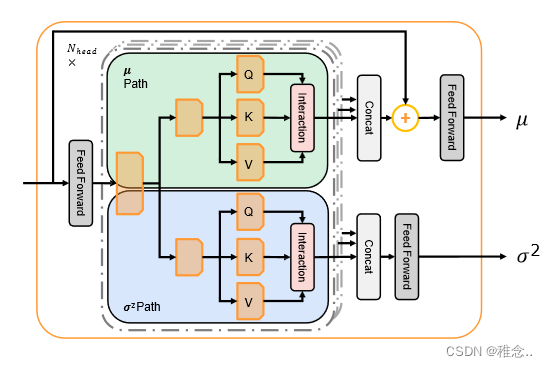
PDE的输入特征来自不同模态的点表示空间。为了对多模态不确定性进行建模,我们进一步将输入特征构建为多元高斯分布。具体来说,PDE 预测每个输入特征的均值向量 (μ) 和方差向量 (σ2)。均值向量表示分布在概率空间中的中心位置,方差向量表示分布在每个维度上的范围。
PDF(概率分布器)考虑到均值和方差向量建模需要特征级和序列级交互。具体来说,前特征级和序列级交互。馈层用于特征级交互,多头(MH)操作负责序列级交互。
我们提出了一种概率分布编码器(PDE),同时考虑到对均值和方差向量进行建模需要特征级和序列级交互。具体来说,前馈层用于特征级交互,多头(MH)操作负责序列级交互。通过应用 MH 操作,输入隐藏状态 H ∈ RT ×D 被分成 k 个头,其中 T 是序列长度,D 是隐藏大小。在每个头中,我们分割特征并将它们发送到两条路径(μ,σ2)。在每条路径中,输入隐藏状态 H(i) ∈ RT ×D/2k 被投影到第 i 个头中的 Q(i)、K(i)、V(i)。举例来说,μ路径中的操作为:
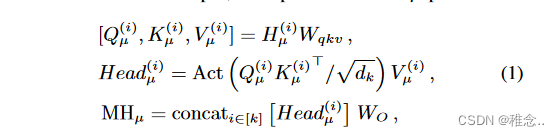
其中 dk 设置为 D/(2k)。权重Wqkv ∈ Rdk×3dk 是将输入投影到每个头的子空间中。权重 WO ∈ Rkdk×D 将 k 个头结果的串联投影到输出空间。 aActo 包括用于考虑序列级交互的激活函数和归一化函数。 σ2 路径与μ 路径类似。由于输入点表示与均值向量相关,因此采用加法运算来学习均值向量。
总结
在这项工作中,我们通过将其建模到概率分布来关注现实世界对象中的多模态不确定性。通过考虑序列级和特征级交互,我们提出了概率分布编码器(PDE)来获得不同模态的分布表示。我们的实验表明,分布表示对于 VL 下游任务是有益的。此外,不确定性建模有助于多样化的预测。为了学习大规模数据中的多模态不确定性,我们设计了三个新的预训练任务(D-MLM、DITM 和 D-VLC)。此外,我们提出了一种端到端多模态不确定性感知视觉语言预训练模型(MAP)来获得通用分布表示。我们凭经验证明了所提出的 MAP 在几个 VL 下游任务上的有效性。未来,我们将探索更多的分布子空间并在更大的数据集上进行实验。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!