一文掌握文本语义分割:从朴素切分、Cross-Segment到阿里SeqModel
前言
之所以写本文,源于以下两点
- 在此文《基于LangChain+LLM的本地知识库问答:从企业单文档问答到批量文档问答》的3.5节中,我们曾分析过langchain-chatchat项目中文本分割相关的代码,当时曾提到该项目中的文档语义分割模型为达摩院开源的:nlp_bert_document-segmentation_chinese-base?(这是其论文)
- 在此文《知识库问答LangChain+LLM的二次开发:商用时的典型问题及其改进方案》中,我们再次提到,langchain-chatchat的默认分块大小是chunk_size:250 (详见configs/model_config.py,但该系统也有个可选项,可以选择达摩院开源的语义分割模型:nlp_bert_document-segmentation_chinese-base)
考虑到在RAG中,embedding和文档语义分割、段落分割都是绕不开的关键点,故本文重点梳理下各类典型的语义分割模型
- 一方面,更好的促进我司第三项目组知识库问答项目的进度
- 二方面,把我司在这个方向上的探索、经验一定程度的通过博客分享给大家(更多深入细节则见我司的大模型项目开发线上营)
第一部分?基于Cross Segment Attention的文本分割
RAG场景下,目前比较常用的文本切块方法还都是基于策略的,例如大模型应用开发框架提供的RecursiveCharacterTextSplitter方法,定义多级分割符,用上一级切割符分割后的文本块如果还是超过最大长度限制,再用第二级切割符进一步切割
Lukasik等人在论文《Text Segmentation by Cross Segment Attention》提出了三种基于transformer的分割模型架构。其中一种仅利用每个候选断点(candidate break)周围的局部上下文,而另外两种则利用来自输入的完整上下文(所谓候选断点指任何潜在的段边界,即any potential segment boundary)
1.1?Cross-segment BERT:确定某个句子是否作为下一个段落的开头
分割模型旨在完成文档分割任务,以预测每个句子是否是文本分段的边界

- 在?Cross-segment BERT模型中,我们将围绕潜在段落断点的局部上下文输入到模型中:左边k个标记和右边k个标记
- 其中与[CLS]对应的输出隐状态被传递给softmax分类器,以便对候选断点进行分段决策
1.2?BERT+Bi-LSTM
在BERT+Bi-LSTM模型中,我们首先使用BERT对每个句子进行编码,然后将句子表示输入到Bi-LSTM中,具体而言

- 当用BERT编码每个句子时,所有序列都以[CLS]标记开始
? 如果分割决定是在句子级别sentence level做出的(例如,文档分割document segmentation),我们使用[CLS]token作为LSTM的输入
需要注意的是,在话语分割(discourse segmentation)任务中,由于上下文较短,可以仅使用一次BERT进行完全编码(Note that,due to the context being short for the discourse seg-mentation task, it is fully encoded in a single passusing BERT.?);
或者可以独立地对每个单词进行编码。考虑到许多单词由single word-piece组成,使用深度transformer编码器来对它们进行编码可能会比较费计算资源,毕竟transformer的计算成本(特别是自注意力)随着输入长度呈二次增长
故在使用这个模型的时候,一般将BERT的输入减少到最大句子大小为64个token,以减少训练和推理时间 - 然后,LSTM负责处理具有线性计算复杂度的多样化和潜在的大型句子序列(Then, the LSTM isresponsible for handling the diverse and potentiallylarge sequence of sentences with linear computa-tional complexity)。在实践中,我们将最大文档长度设定为128个句子,更长的文档会被分割成连续且非重叠的128个句子块,并作为独立的文档进行处理
// 待更
1.3?Hierarchical BERT
而在分层BERT模型中,我们首先使用BERT对每个句子进行编码,然后将输出的句子表示输入到基于Transformer的另一个模型中

第二部分 阿里语义分割模型SeqModel
2.1?SeqModel核心原理
回顾一下
- 上文的Cross-Segment提出了一个基于本地上下文的跨段BERT模型和一个分层BERT模型(Hier.BERT),以利用两个BERT模型对句子和文档进行编码,从而实现更长的上下文建模
proposed a cross-segment BERT model using local contextand a hierarchical BERT model (Hier.BERT) using two BERTmodels to encode sentence and document separately for ex-ploiting longer context - 2020年,此篇论文《Two-level transformer and auxiliary coherence modeling for improved text segmentation》还采用了两个分层连接的Transformer结构(uses two hierarchically con-nected transformers)。然而,由于分层模型计算成本高且推理速度较慢
2.1.1?SeqModel:将文档分割建模为句子级序列标记任务
为此,Zhang等人在论文《Sequence Model with Self-Adaptive Sliding Window for Efficient Spoken Document Segmentation》中提出了SeqModel
- SeqModel利用BERT对多个句子同时编码,建模了更长的上下文之间依赖关系之后再计算句向量,最后预测每个句子后边是否进行文本分割
- 此外,该模型还使用了自适应滑动窗口方法,在在不牺牲准确性的情况下进一步加快推理速度
如下图所示,SeqModel将文档分割建模为句子级序列标记任务(which models document segmentation as a sentence-level sequence label-ing task)
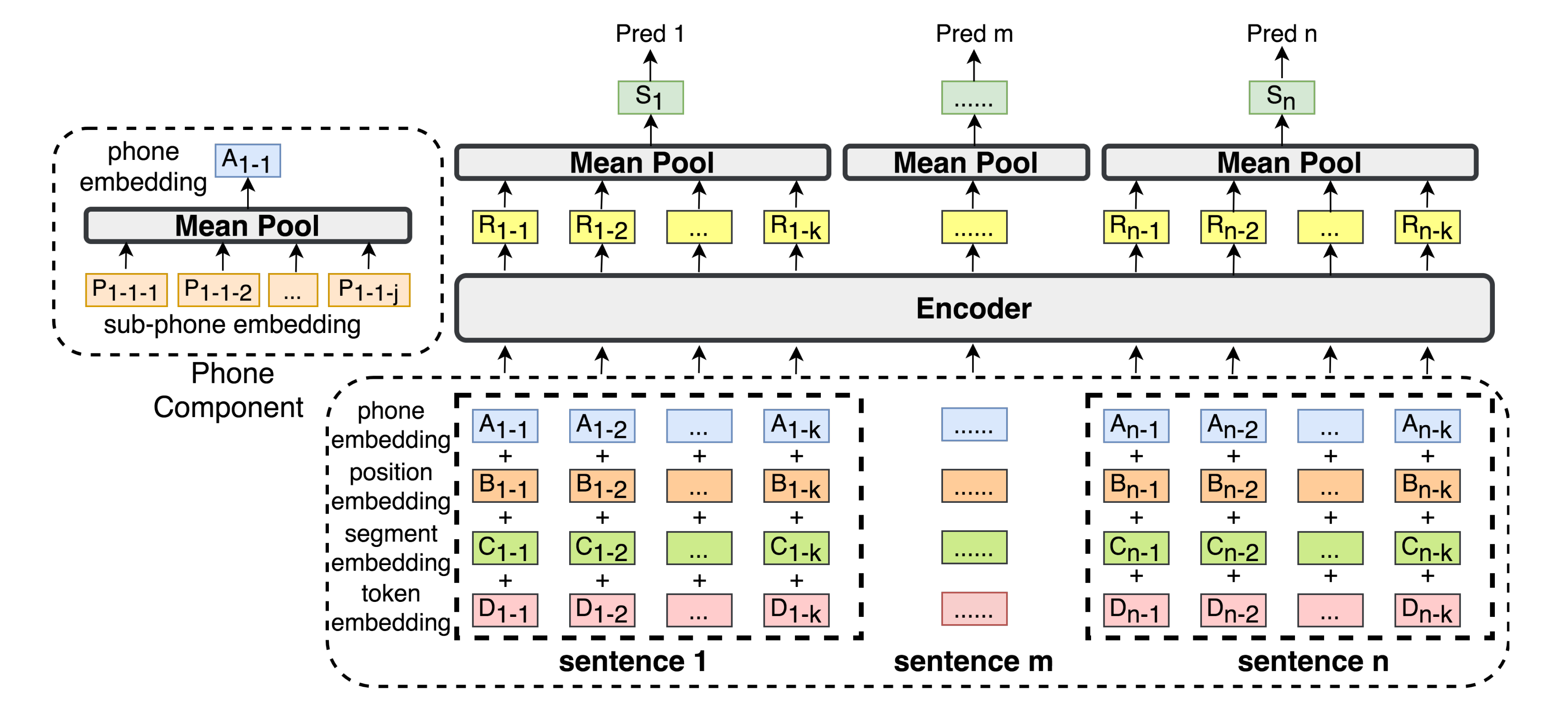
- 首先,文档中的每个句子经过WordPiece分词器进行分词[12]
- 然后,通过由“token嵌入、位置嵌入和段落嵌入”组成的输入表示层来对这些句子进行编码
This sequence is embedded through the input representation layer as the element-wise sum of token embedding, position embedding, and segment embedding. - 接下来,这些嵌入被送入Transformer编码器,输出与k个标记对应的隐状态
,并使用均值池化方法得到句子编码
These embedding sare then fed to a transformer encoder and the output hiddenstates corresponding to?k?tokens in sentence?sm, denoted by?{Rm?i?}ki=1, are mean-pooled to represent the sentenceencoding.? - 最后,将所有句子
的句子编码
输入softmax二元分类器以判断每个句子是否为段落边界,训练目标是最小化softmax交叉熵损失
The sentence encodings?{Sm}nm=1?for sentences{s}nm=1?are fed to a softmax binary classifier to classifywhether each sentence is a segment boundary.?The training objective is minimizing the softmax cross-entropy loss.
2.1.2?自适应滑动窗口(Self-adaptive Sliding Window)
我们还提出了一种自适应滑动窗口方法,在不牺牲准确性的情况下进一步加快推理速度(We also propose a self-adaptive sliding window approach tofurther speed up inference without sacrificing accuracy),如下图所示

- 传统的分割推理滑动窗口使用固定的前向步长。在我们提出的自适应滑动窗口方法中,在推理过程中,从前一个窗口中的最后一句话开始,模型在最大后向步长内 向后查看,以找到来自前一个推理步骤的积极分割决策(模型对分割预测概率>0.5)
Traditional sliding window for seg-mentation inference uses a fixed forward step size. In ourproposed self-adaptive sliding window approach, during in-ference, starting from the last sentence in the previous win-dow, the model looks backward within a maximum backward step size to find positive segmentation decisions (segmenta-tion prediction probability from the model > 0.5) from the previous inference step. - 当在这个跨度内有积极的决策时,下一个滑动窗口将自动调整为:从最近预测片段边界之后的下一个句子开始。否则,当在这个跨度内没有积极的决策时,下一个滑动窗口将从前一个窗口中的最后一句话开始
When there are positive decisions within this span, the next sliding window is automatically ad-justed to start from the next sentence after the most recent predicted segment boundary. Otherwise, when no positive de-cisions exist within this span, the next sliding window startsfrom the last sentence in the previous window. - 考虑到最后一段和历史对下一个分割决策影响已经降低,这种策略有助于丢弃滑动窗口内不相关的历史信息。因此,自适应滑动窗口既可以加快推理速度也可以提高分割准确性
Consideringthat the last paragraph and the history beyond have reducedimpact on the next segmentation decision, this strategy helpsdiscard irrelevant history within the sliding window. Hence,the self-adaptive sliding window may both speed up inferenceand improve segmentation accuracy.?
2.2 与cross-segment BERT、Hierarchical BERT的区别
2.2.1 与cross-segment BERT的区别
- 对于cross-segment BERT而言,其将文档分割作为每个候选断点的token级别的二分类任务。输入训练样本由一个领头的[CLS]标记和连接候选断点左右局部上下文的方式组成,并通过[SEP]标记进行分隔
该序列被送入BERT编码器,其中与[CLS]对应的输出隐状态被传递给softmax分类器,以便对候选断点进行分段决策
the cross-segment BERT model [10],treats document segmentation as a token-level binary classi-fication task for each candidate break (i.e., each token).?The input training sample is composed of a leading [CLS] token,and concatenation of the left and right local contexts for acandidate break, separated by the [SEP] token.
This sequenceis fed to a BERT-encoder and the output hidden state corre-sponding to [CLS] is fed to a softmax classifier for segmen-tation decision on the candidate break.? - 相比之下,我们的SeqModel同时编码一组句子
此外,我们的SeqModel同时对多个句子进行分类,在推理速度方面较跨段模型显著加快
In comparison, our SeqModel encodes a block of sentences?{sm}nm=1?simulta-neously, hence exploits longer context and inter-sentence de-pendencies through encoder self-attention.?Consequently, thecontextualized sentence encodings?{Sm}nm=1?for classifica-tion can potentially improve segmentation accuracy.
In ad-dition, our SeqModel classifies multiple sentences simultane-ously, hence significantly speeds up inference compared tothe cross-segment model.?
2.2.2 与Hierarchical BERT、直接BERT的区别
- 不同于Hierarchical BERT,SeqModel通过均值池生成上下文化的句子编码,而不是像Hierarchical BERT那样使用另一个Transformer编码器进行文档编码。因此,它显著降低了计算复杂度,并提高了推理效率(SeqModel generates contextualized?Hier.BERT, hence significantly reduces computational com-plexity and improves inference efficiency.)
- BERT[BERT: pre-training of deep bidirectional transformers for language understanding]采用下一句预测(NSP)任务作为句间目标,这是一个判别两个句子在原始来源中是否相邻的二值分类任务
BERT [13] employs the next sentence prediction (NSP) task as an inter-sentence objective, which is a binary classification task deciding whether two sentences are contiguous in the original source.啥意思呢,其实很简单
在预训练BERT模型过程中,为了让模型学到两个句子之间的关系,设计了一个二分类任务,即- 同时向BERT中输入两个句子,预测第二个句子是否是第一个句子的下一句。基于这个原理,我们可以设计一种最朴素的文本切分方法,其中最小的切分单位是句子?(下图:图源)
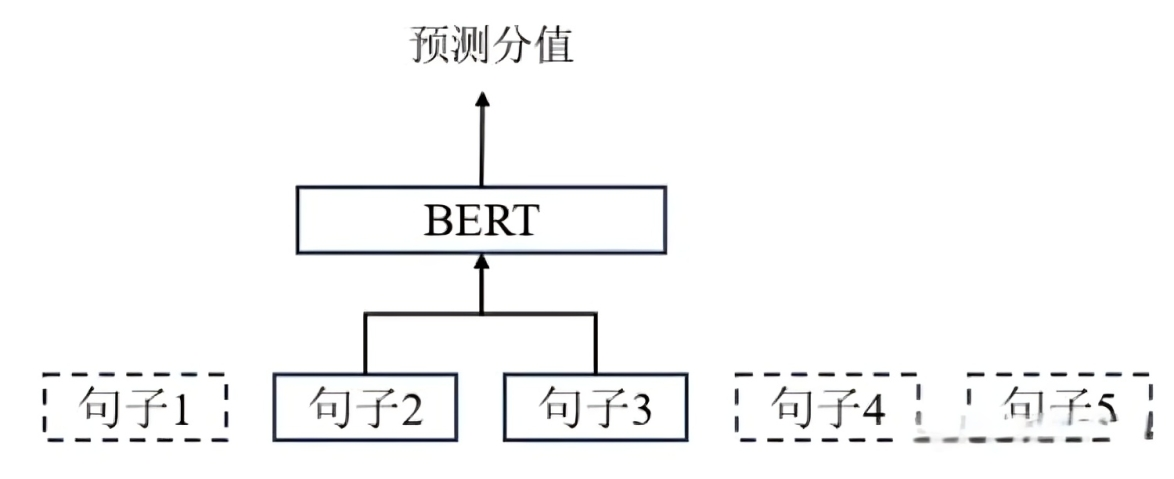
- 在完整的文本上,用滑动窗口的方式分别将相邻的两个句子输入到BERT模型中做二分类,如果预测分值较小,说明这两个句子之间的语义关系比较弱,可以作为一个段落切分点
- 然而,这种方法判断是否是文本切分点时只考虑了前后各一个句子,没有利用到距离更远位置的文本信息。此外,该方法的预测效率也相对较低
- 同时向BERT中输入两个句子,预测第二个句子是否是第一个句子的下一句。基于这个原理,我们可以设计一种最朴素的文本切分方法,其中最小的切分单位是句子?(下图:图源)
- RoBERTa[14]将NSP目标从预训练中移除,但也添加了其他训练优化
RoBERTa [14] removes the NSP objective from pre-training but also adds other training optimizations. - StructBERT[15]在BERT预训练目标的基础上增加了一个单词结构目标和一个句子结构目标。句子结构目标对两个句子(S1,S2)进行三元分类,以决定S1是在S2之前还是之后,或者两个句子是不连续的
StructBERT [15] augments BERT pre-training objectives with a word structural objective and a sentence structural objective. The sentence structural objective conducts a ternary classification on two sentences (S1, S2) to decide whether S1 precedes or follows S2 or the two sentences are noncontiguous. - CONPONO模型[16]利用了新的句子间目标,包括预测具有多个句子之间的连贯但非连续的跨度之间的排序。
The CONPONO model [16] exploits new inter-sentence objectives, including predicting ordering between coherent yet noncontiguous spans with multiple sentences in between. - ELECTRA[17]用一个更有效的替换token检测任务取代了BERT预训练中的屏蔽语言建模,该任务用生成器网络生成的可信替代(plausible alternatives)替代一些输入token,然后训练一个判别器来预测损坏输入中的每个token是否被生成的样本替换
ELECTRA [17] replaces masked language modeling in BERT pre-training with a more efficient replaced-token detection task, which replaces some input tokens with plausible alternatives generated by a generator network, then trains a discriminator to predict whether each token in the corrupted input is replaced by a generated sample or not.
2.3?SeqModel的应用
SeqModel模型权重已公开在魔搭社区上,支持中文,地址为:https://modelscope.cn/models/damo/nlp_bert_document-segmentation_chinese-base/summary,可通过如下代码使用:
from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
p = pipeline(
task=Tasks.document_segmentation,
model='damo/nlp_bert_document-segmentation_chinese-base')
result = p(documents='......')
print(result[OutputKeys.TEXT])这就是本文前言中所说的阿里开源的语义分割模型了呐
// 待更..
参考文献与推荐阅读
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!