Python生成圣诞节词云-代码案例剖析【第17篇—python圣诞节系列】
??Python制作圣诞树词云-中文
🐬展示效果
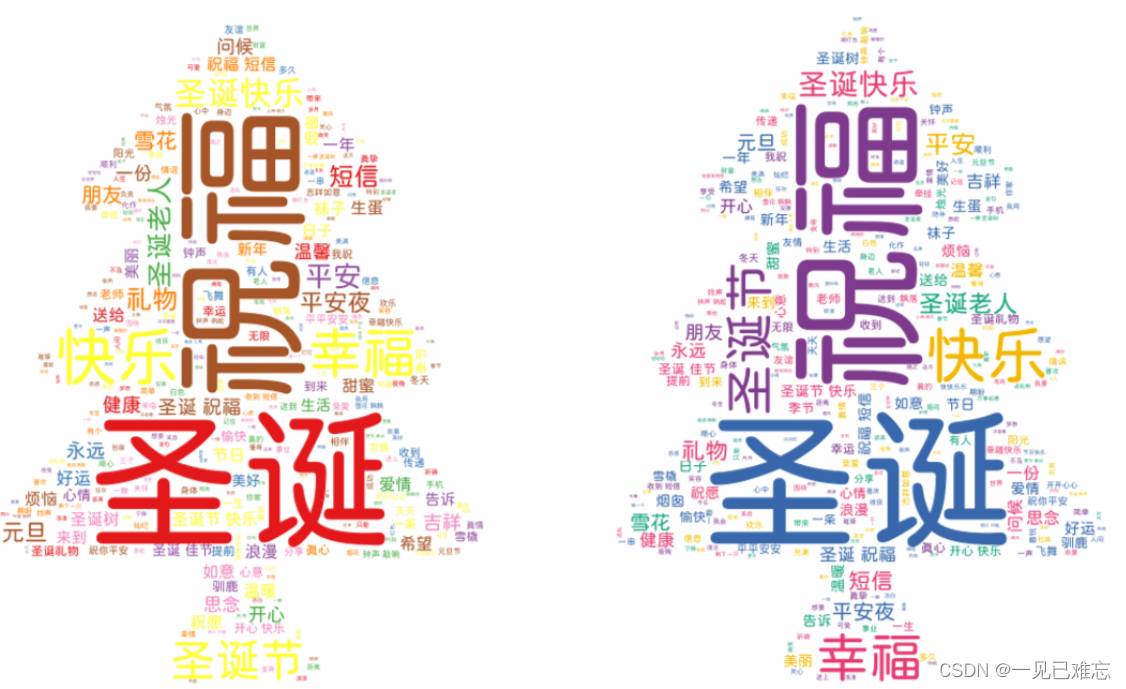
🌸代码
# -*- coding: UTF-8 -*-
import jieba
import re
from stylecloud import gen_stylecloud
from PIL import Image
import numpy as np
with open('./圣诞素材/Christmas.txt', encoding="utf-8") as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# 文本分词 精确模式
seg_list_exact = jieba.cut(new_data, cut_all=False)
# 加载停用词
with open('stop_words.txt', encoding='utf-8') as f:
# 获取每一行的停用词 添加进集合
con = f.read().split('\n')
stop_words = set()
for i in con:
stop_words.add(i)
# 列表解析式 去除停用词和单个词
result_list = [word for word in seg_list_exact if word not in stop_words and len(word) > 1]
print(result_list)
# 个人推荐使用的palette配色方案 效果挺好看 其他测试过 感觉一般~~
# colorbrewer.qualitative.Dark2_7
# cartocolors.qualitative.Bold_5
# colorbrewer.qualitative.Set1_8
gen_stylecloud(
text=' '.join(result_list), # 文本数据
size=600, # 词云图大小
font_path=r'./font/猫啃网糖圆体.ttf', # 中文词云 显示需要设置字体
icon_name = "fas fa-tree", # 图标
output_name='./results/圣诞树06.png', # 输出词云图名称
palette='cartocolors.qualitative.Bold_5', # 选取配色方案
)
🌴代码剖析
这段代码使用了jieba进行中文分词,结合stylecloud库生成了一个基于指定配色方案的圣诞主题词云图。以下是对代码的解释:
-
import jieba:导入中文分词库jieba。 -
import re:导入正则表达式库。 -
from stylecloud import gen_stylecloud:导入stylecloud库中的生成词云图的函数。 -
from PIL import Image:导入Python Imaging Library(PIL)中的Image类。 -
import numpy as np:导入numpy库并使用别名np。 -
with open('./圣诞素材/Christmas.txt', encoding="utf-8") as f::打开文件’Christmas.txt’,并使用utf-8编码读取。 -
data = f.read():将文件内容读取到变量data中。 -
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S):使用正则表达式提取data中的中文字符,放入new_data中。 -
new_data = "/".join(new_data):将提取的中文字符用’/'连接成字符串。 -
seg_list_exact = jieba.cut(new_data, cut_all=False):使用jieba库进行中文分词,采用精确模式。 -
with open('stop_words.txt', encoding='utf-8') as f::打开停用词文件’stop_words.txt’,并使用utf-8编码读取。 -
con = f.read().split('\n'):读取文件内容并按行分割,得到停用词列表。 -
stop_words = set(con):将停用词列表转换为集合,方便快速检查词是否在停用词中。 -
result_list = [word for word in seg_list_exact if word not in stop_words and len(word) > 1]:使用列表解析式过滤掉停用词和长度为1的词,得到最终的分词结果。 -
gen_stylecloud(text=' '.join(result_list), size=600, font_path=r'./font/猫啃网糖圆体.ttf', icon_name="fas fa-tree", output_name='./results/圣诞树06.png', palette='cartocolors.qualitative.Bold_5'):使用gen_stylecloud函数生成词云图。
text=' '.join(result_list):将分词结果连接成一个字符串。size=600:设置词云图大小为600。font_path=r'./font/猫啃网糖圆体.ttf':指定中文显示所需的字体文件路径。icon_name="fas fa-tree":指定词云图中的图标,这里使用了一个圣诞树图标。output_name='./results/圣诞树06.png':指定输出词云图的文件路径和名称。palette='cartocolors.qualitative.Bold_5':选择了一个配色方案。
注意:在运行之前,请确保已安装相应的库,可以使用以下命令进行安装:
pip install jieba stylecloud Pillow numpy
??Python制作圣诞树词云-英文
🐬展示效果
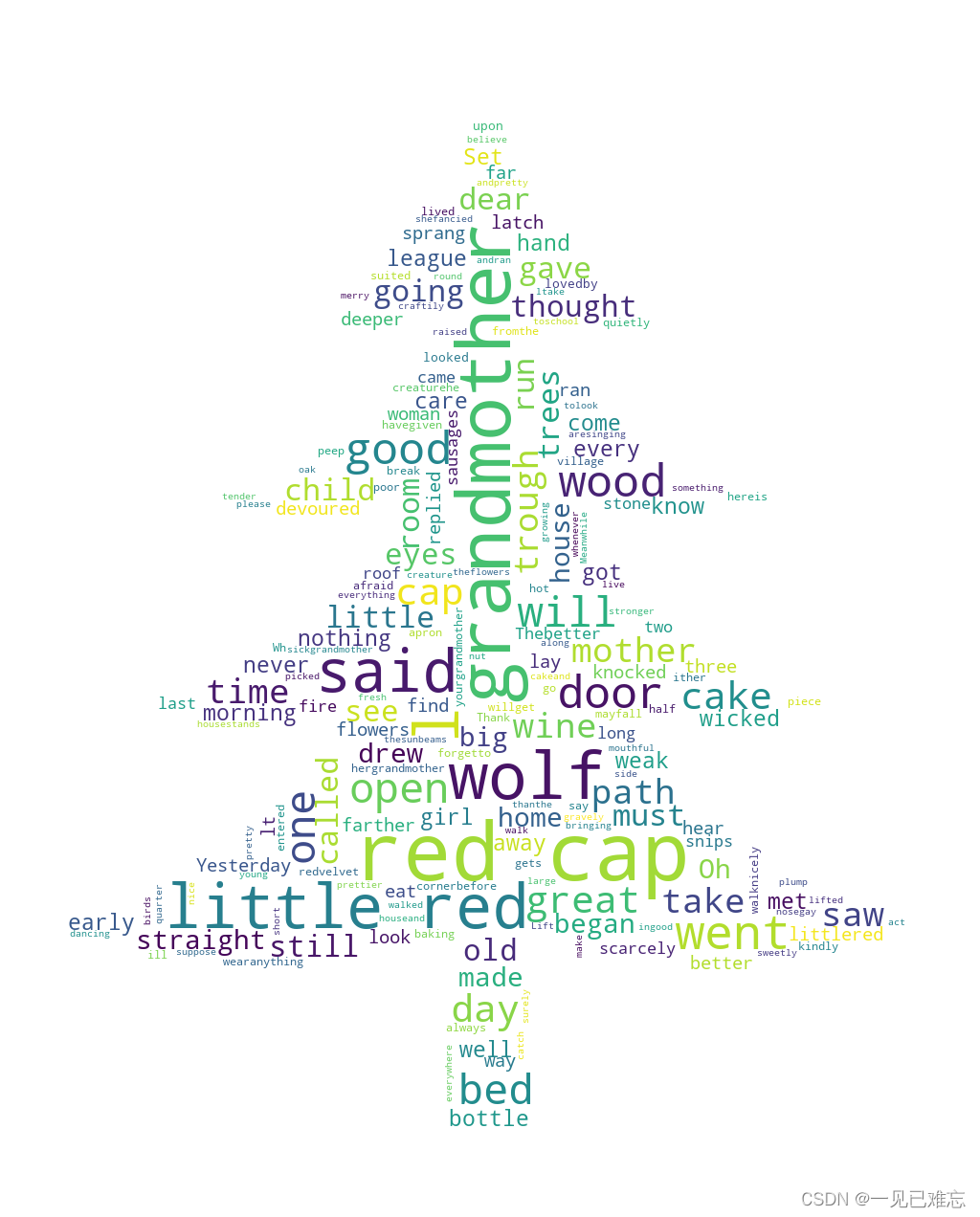
🌸代码
from wordcloud import WordCloud
import PIL.Image as image
import numpy as np
# 一些变量值,依据自己实际情况进行设置
edcoding_type = "utf-8" # 编码方式
background_color = "white" # 生成图片的背景颜色
txt_path = "little red-cap.txt" # 文本路径
mask_path = "mask.png" # 词云形状掩码路径
img_path = "red-cap_wordcloud.png" # 输出生成的词云图片路径
max_words = 200 # 最大显示词数量
# 读取文本内容
def get_txt(txtpath):
with open(txtpath, encoding = edcoding_type) as f:
text = f.read()
return text
# 生成词云
def generate_wordcloud(wordlist, maskpath, backgroundcolor, maxwords):
mask = np.array(image.open(maskpath)) # 设置图形掩码
wordcloud = WordCloud(
background_color = backgroundcolor, # 设置图片背景颜色
mask = mask, # 设置掩码
max_words = maxwords # 设置最大显示词数
).generate(wordlist)
return wordcloud
text = get_txt(txt_path) # 获取文本
word_cloud = generate_wordcloud(text, # 生成词云
mask_path,
background_color,
max_words)
image_file = word_cloud.to_image() # 生成图片
image_file.show() # 显示图片
word_cloud.to_file(img_path) # 保存生成的图片
🌴代码剖析
这段代码使用了WordCloud库生成了一个基于给定文本的词云图。以下是对代码的解释:
-
from wordcloud import WordCloud:导入WordCloud库,用于生成词云。 -
import PIL.Image as image:导入PIL库中的Image类,用于处理图像。 -
import numpy as np:导入NumPy库并使用别名np。 -
edcoding_type = "utf-8":设置文本的编码方式为UTF-8。 -
background_color = "white":设置生成图片的背景颜色为白色。 -
txt_path = "little red-cap.txt":设置文本文件的路径。 -
mask_path = "mask.png":设置词云形状的掩码文件路径。 -
img_path = "red-cap_wordcloud.png":设置输出生成的词云图片的路径。 -
max_words = 200:设置最大显示词数量为200。 -
def get_txt(txtpath)::定义函数get_txt,用于读取文本内容。
with open(txtpath, encoding=edcoding_type) as f::打开文本文件,并使用指定的编码方式读取文件内容。text = f.read():将文件内容读取到变量text中。return text:返回读取到的文本内容。
def generate_wordcloud(wordlist, maskpath, backgroundcolor, maxwords)::定义函数generate_wordcloud,用于生成词云图。
mask = np.array(image.open(maskpath)):将图形掩码加载为NumPy数组。WordCloud(...).generate(wordlist):使用WordCloud生成词云图,设置了背景颜色、掩码和最大显示词数。return wordcloud:返回生成的词云对象。
text = get_txt(txt_path):调用get_txt函数获取文本内容。word_cloud = generate_wordcloud(text, mask_path, background_color, max_words):调用generate_wordcloud函数生成词云图。image_file = word_cloud.to_image():将词云对象转换为图像对象。image_file.show():显示生成的词云图。word_cloud.to_file(img_path):将生成的词云图保存为图片文件。
🎅圣诞节快乐!
愿你的圣诞充满温馨和欢笑,家人团聚,友谊长存。在这个特别的时刻,愿你感受到爱的温暖,希望的明亮。愿你的心充满喜悦,新的一年里,幸福、健康、平安与你同行。圣诞快乐!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!