分布式(6)
目录
26.雪花算法如何实现的?
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将64位分隔成多个部分,每个部分代表不同的涵义。而Java中64位的整数是Long类型,所以在Java中SnowFlake算法生成的ID就是Long来存储的。
第1位占用1bit,其值始终是0,可看做事符号位不使用。
第2位开始的41位是时间戳,41bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可用的时间年限是69年的时间。
中间的10bit位可以表示机器数,即2^10=1024台机器,但是一般情况下我们不会部署这么多台机器。如果我们对IDC(互联网数据中心)有需求,还可以将10bit分5bit给IDC,分5bit给工作机器。这样子就可以表示32个IDC,每个IDC下可以有32台机器,具体的划分可以根据自身需求定义。
最后12bit位是自增序列,可表示2^1=4096个数。
这样的划分之后相当于在一毫秒一个数据中心的一台机器上课产生4096个有序的不重复的ID。但是我们IDC和机器数肯定不止一个,所以毫秒内能生成的有序ID数是翻倍的。

27.雪花算法有什么问题?有哪些解决思路?
有哪些问题?
时钟回拨问题;
趋势递增,而不是绝对递增;
不能在一台服务器上部署多个分布式ID服务;
如何解决时钟回拨?
以百度的UidGenerator为例,CachedUidGenerator方式主要采取如下一些措施和方案规避了时钟回拨问题和增强唯一性:
自增列:UidGenerator的workerId在实例每次重启时初始化,且就是数据库的自增ID,从而完美的实现每个实例获取到的workId不会有任何冲突。
RingBuffer:UidGenerator不再在每次取ID时都实时计算分布式ID,而是利用RingBuffer数据结构预先生成若干个分布式ID并保存。
时间递增:传统的雪花算法实现都是通过System.currentTimeMills()来获取时间并与上一次时间进行比较,这样的实现严重依赖服务器的时间。而UidGenerator的时间类型是AtomicLong,且通过incrementAndGet()方法获取下一次的时间,从而脱离了对服务器时间的依赖,也就不会有时钟回拨问题
(这种做法也有一个小问题,即分布式ID中的时间信息可能并不是这个ID真正产生的时间点,例如:获取的某分布式ID的值为3200169789968523265,他的反解析结果为{"timestamp":"2019 05 02 23:26:39";"workId":"21";"sequenece":"1"},但是这个ID可能并不是在“2019 05 02 23:26:39:这个时间产生的)。
28.有哪些方案实现分布式锁?
使用场景
需要保证一个方法在同一时间内只能被同一个线程执行
实现方式:
加锁和解锁
方案,考虑因素(性能,稳定,实现难度,死锁)
基于数据库做分布式锁? ?乐观锁(基于版本号)和悲观锁(基于排他锁)
基于Redis做分布式锁:setnx(key,当前时间+过期时间)和redlock机制;
基于zookeeper做分布式锁:临时有序节点来实现的分布式锁,Curator
基于Consul做分布式锁
29.基于数据库如何实现分布式锁?有什么缺陷?
基于数据库表(锁表,很少使用)
最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。当我们想要获得锁的时候,就可以在该表中增加一条记录,想要释放锁的时候就删除这条记录。为了更好的延时,我们先创建一张数据库表,参考如下:

当我们想要获得锁时,可以插入一条数据:

当需要释放锁时,可以删除这条数据:

基于悲观锁
悲观锁实现思路?
在对任意记录进行修改前,先尝试为该记录加上排他锁(exclusive? locking)。
如果加锁失败,说明该记录正在被修改,那么当前查询可能等待或者抛出异常。具体响应方式由开发者根据实际需要决定。
如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
其间如果有其他对该记录做修改或者加排他锁的操作,就会等待我们解锁或者直接抛出异常。
以MySQL? InnoDB中使用悲观锁为例?
要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交,set? ?autocommit=0;

上面的查询语句中,我们使用了select? ...? for? update的方式,这样就通过开启排他锁的方式实现了悲观锁。此时在t? goods表中,id为1的那条数据被我们锁定了,其他的事务必须等本次事务提交后才能执行。这样我们就可以保证当前的数据不会被其他事务修改。
上面我们提到,使用select ... for? update会把数据给锁住,不过我们需要注意一些锁的级别,MySQL? Innodb默认行级锁。行级锁是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁把整张表锁住,这点需要注意。
基于乐观锁
乐观并发控制(又名:乐观锁,缩写OCC)是一种并发控制的方法。他假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务辉县检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
以使用版本号实现乐观锁为例?
使用版本号时,可以在数据初始化时指定一个版本号,每次对数据的更新操作都对版本号执行+1操作。并判断当前版本号是不是该数据的最新的版本号。

需要注意的是,乐观锁机制往往基于系统中数据存储逻辑,因此也具备一定的局限性。由于乐观锁机制是在我们的系统中实现的,对于来自外部系统的用户数据更新操作不受我们系统控制,因此可能会造成脏数据被更新到数据库中。在系统设计阶段,我们应该宠妃考虑到这些情况,并进行相应的调整(如将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据更新途径,而不是将数据库表直接对外公开)。
缺陷
对数据库依赖,开销问题,行锁变表锁问题,无法解决数据库单点和可重入的问题。
30.基于Redis如何实现分布式锁?有什么缺陷?
最基本的Jedis方案
加锁:? set? NX PX+重试+重试间隔
向Redis发起如下命令:SET? ?productid:lock? 0xx9p03001? NX? PX? 30000其中,”productId"由自己定义,可以是与本次业务有关的Id,"0xx9p03001"是一串随机值,必须保证全局唯一(原因在后文中会提到),“NX“指的是当且仅当key(也就是案例中的”productid:lock")在Redis中不存在时,返回执行成功,否则执行失败。“PX 30000”指的是在30秒后,key被自动删除。执行命令后返回成功,表名服务成功的获得了锁。

解锁:采用lua脚本:在删除Key之前,一定要判断服务A持有的Value与Redis内存储的Value是否一致。如果贸然使用服务A持有的key来删除锁,则会误将服务B的锁释放掉。
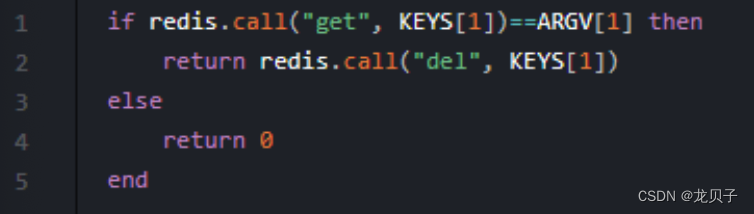
基于RedLock实现分布式锁
假设有两个服务A,B都希望获得锁,有一个包含了5个Redis Master的Redis Cluster,执行过程大致如下:
客户端获取当前时间戳,单位:毫秒
服务A轮询每个Master节点,尝试创建锁。(这里锁的过期时间比较短,一般就几十毫秒)RedLock算法会尝试在大多数节点上分别创建锁,假如节点总数为n,那么大多数节点指的是n/2+1。
客户端计算陈工建立完锁的时间,如果建锁时间小于超时时间,就可以判定锁创建成功。如果锁创建失败,则依次(遍历master节点)删除锁。
只要有其他服务创建过分布式锁,那么当前服务就必须轮询尝试获取锁。
基于Redisson实现分布式锁?
过程?
线程去获取锁,获得成功:执行lua脚本,保存数据到redis数据库。
线程去获取锁,获取失败:订阅了解锁消息,然后再尝试获取锁,获取成功后,执行Lua脚本,保存数据到redis数据库。
互斥?
如果这个时候客户端B来尝试加锁,执行了同样的一段Lua脚本。第一个if判断会执行“exists? ?myLock”,发现myLock这个锁key已经存在。接着第二个If判断,判断myLock锁key的hash数据结构中,是否包含客户端B的ID,但明显没有,那么客户端B会获取到pttl? myLock返回的一个数字,代表MyLock这个锁key的剩余生存时间。此时客户端B会进入一个while循环,不听的尝试加锁。
watch? dog 自动延时机制?
客户端A加锁的锁key默认生存时间只有30秒,如果超过了30秒,客户端A还想一直持有这把锁,怎么办?其实只要客户端A一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端A还持有锁Key,那么就会不断的延长锁key的生存时间。
可重入?
每次lock会调用incrby,每次unlock会减一。
方案比较
1.借助Redis实现分布式锁时,有一个共同的缺陷:当获取锁被拒绝后,需要不断地循环,重新发送获取锁(创建key)的请求,直到请求成功。这就造成空转,良妃宝贵的CPU资源。
2.RedLock算法本身有争议,并不能保证健壮性。
3.Redisson实现分布式锁时,除了将key新增到某个指定的Master节点外,还需要由master自动异步的将key和Value等数据同步至绑定的slave节点上。那么问题来了,如果master没来得及同步数据,突然发生宕机,那么通过故障转移和主备切换,slave节点被迅速升级为Master节点,新的客户端加锁成功,旧的客户端的watch dog发现key存在,误以为旧客户端仍然持有这把锁,这就导致同时存在多个客户端持有同名锁的问题了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!