强化学习第一课 Q-Learning
2023-12-29 18:44:18
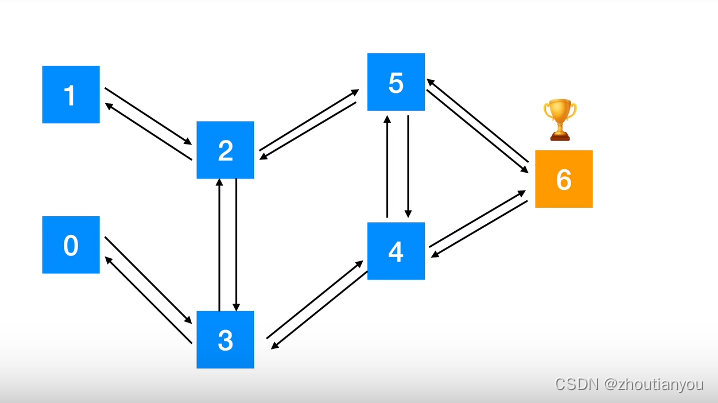
解决问题:从任何位置到6
视频课程地址:
强化学习算法系列教程及代码实现-Q-Learning_哔哩哔哩_bilibili
相应代码:
import numpy as np
import random
q = np.zeros((7, 7))
q = np.matrix(q)
r = np.array([[-1, -1, -1, 0, -1, -1, -1],
[-1, -1, 0, -1, -1, -1, -1],
[-1, 0, -1, 0, -1, 0, -1],
[0, -1, 0, -1, 0, -1, -1],
[-1, -1, -1, 0, -1, 0, 100],
[-1, -1, 0, -1, 0, -1, 100],
[-1, -1, -1, -1, 0, 0, 100]])
r = np.matrix(r)
gamma = 0.8
for i in range(1000):
state = random.randint(0, 6)
while state != 6:
r_pos_action = []
for action in range(7):
if r[state, action] >= 0:
r_pos_action.append(action)
next_state = r_pos_action[random.randint(0, len(r_pos_action) - 1)]
q[state, next_state] = r[state, next_state] + gamma * q[next_state].max()
state = next_state
print(q)
state = random.randint(0, 6)
print("机器人处于{}".format(state))
count = 0
while state != 6:
if count > 20:
print("fail")
break
q_max = q[state].max()
q_max_action = []
for action in range(7):
if q[state, action] == q_max:
q_max_action.append(action)
next_state = q_max_action[random.randint(0, len(q_max_action) - 1)]
print('机器人 goes to {} 。'.format(next_state))
state = next_state
count += 1
文章来源:https://blog.csdn.net/zhoutianyou/article/details/135291688
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!