LinkedHashMap详解
前言
HashMap是我们经常使用的存储对象,而LinkedHashMap却不常使用,以至于我们对这个类往往仅仅停留在知道:一个有序排列的键值对存储数据结构。本文就深入了解一下这个类。
用法
demo
public static void main(String[] args) {
System.out.println("-------HashMap--------");
m1(new HashMap<>());
System.out.println("-------LinkedHashMap--------");
m1(new LinkedHashMap<>());
}
public static void m1(Map<String, String> map) {
map.put("aaa", "1");
map.put("bbb", "2");
map.put("ccc", "3");
map.forEach((k, v) -> {
System.out.println(k + " - " + v);
});
}
输出
-------HashMap--------
aaa - 1
ccc - 3
bbb - 2
-------LinkedHashMap--------
aaa - 1
bbb - 2
ccc - 3
几种构造方法
//默认构造方法:无参
Map<String, String> map = new LinkedHashMap<>();
//传入初始容量
Map<String, String> map2 = new LinkedHashMap<>(100);
//传入初始容量,扩容因子,是否以访问顺序排序
Map<String, String> map3 = new LinkedHashMap<>(100, 0.75f, true);
解释:
LinkedHashMap作为Map的一个实现,可以像HashMap一样方便的使用多态机制。
后面会详细解释构造方法中的几个参数含义。
代码详解
继承关系
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
解释:
LinkedHashMap是HashMap的子类,实现了Map接口。
所以LinkedHashMap有着HashMap的key-value存储数据的特性。
关键成员变量
transient LinkedHashMap.Entry<K,V> head;//链表头节点引用(指针)
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;//链表尾节点引用(指针)
/**
* The iteration ordering method for this linked hash map: {@code true}
* for access-order, {@code false} for insertion-order.
*
* @serial
*/
final boolean accessOrder;//排序方式
解释:
相对于HashMap,这是三个成员变量是LinkedHashMap所特有的,他们是实现子类特殊特性的关键成员变量。
- head,tail 代表头和尾,类型是双向链表的节点(除了有next,还有before和after)(为什么有next了,还需要after?因为next是为了实现HashMap基础功能的,是为了实现HashMap中的链表或红黑树用的。二before和after是LinkedHashMap专门为了实现双向链表的。两者功能不同,无法共用)。表示存入map的数据,除了存在HashMap里,还在一个双向链表里存了一份。从而实现了顺序存取的效果。
- accessOrder:控制存储顺序。这个参数可能不太好理解。我们一般认为,既然是顺序存储,当然是像List那样按插入的顺序存储呀。需要规定什么顺序吗? 是的,这里规定了第二种存储顺序:按访问时间排序,哪个刚访问(包括新增),哪个就排在前面。那些很久之前插入,并且一直没被访问过的数据就排在后面。也就意味着,当使用这种排序模式时,链表会不断进行重新排序。
顺序遍历
前面的demo示例中,展示了LinkedHashMap的顺序遍历特性,并且我们知道了是链表实现的顺序存取,下面就是forEach的源码:
public void forEach(BiConsumer<? super K, ? super V> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.key, e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
解释:
顺着链表从head一直往后迭代:e = e.after,实现顺序遍历map的特性。
类似的,LinkedHashMap中实现的迭代器也是依赖链表。
afterNodeAccess
节点被访问之后:把被访问的节点移动到队列尾部(move node to last)
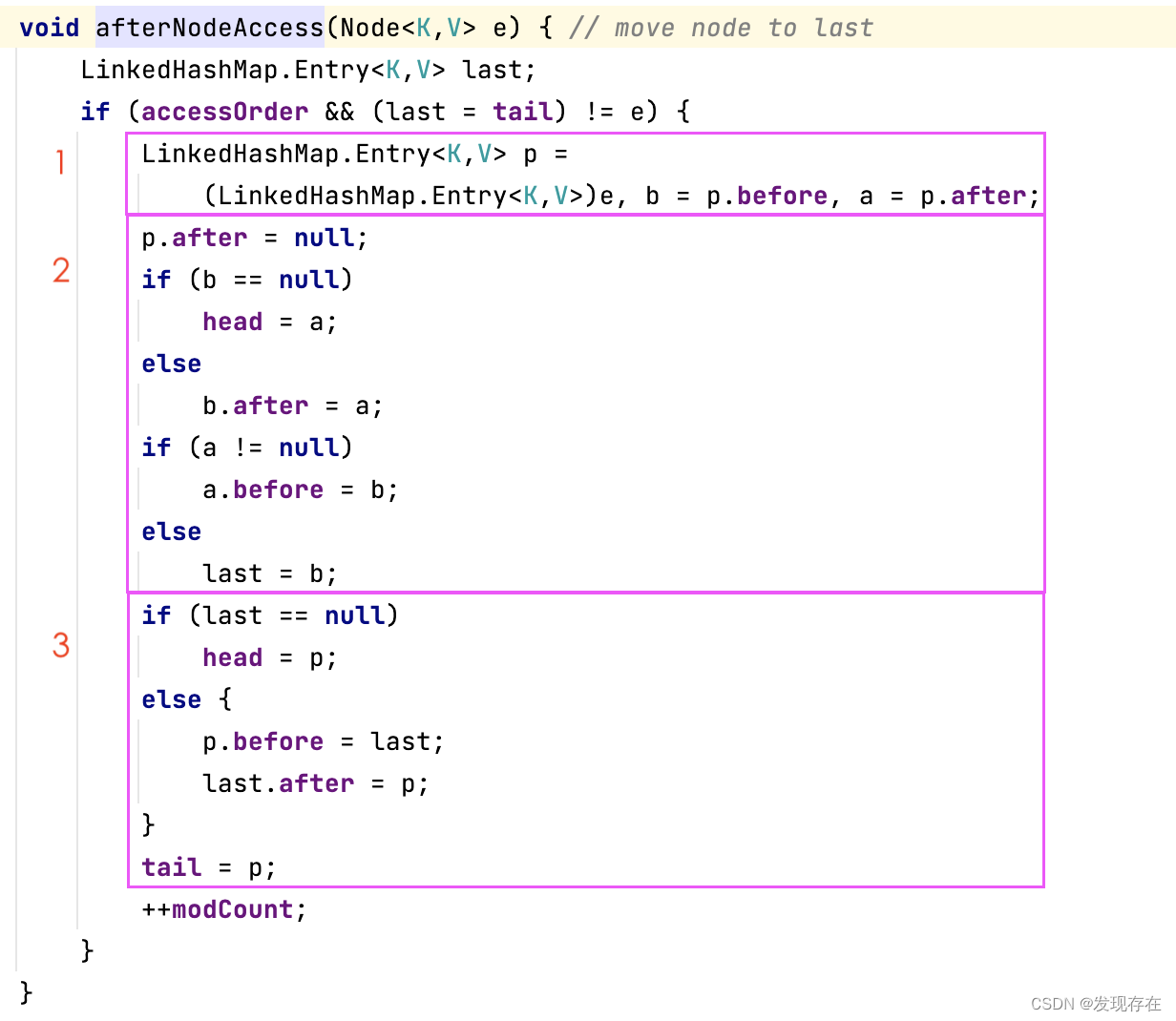
p在队列里的三种情况示意图:

解释:
- 1、创建p前后两个指针 b,a,为后面操作做准备
- 2、分三种情况(p在头,尾,中间),把p移出队列
- 3、分两种情况(经过前面处理后:队列为空,不为空),把p加入队列尾部
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
等效于:
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e;
LinkedHashMap.Entry<K,V> b = p.before;
LinkedHashMap.Entry<K,V> a = p.after;
afterNodeInsertion
插入节点之后:可能删除最老的节点
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
解释:
入参evict控制了是否执行这样的逻辑
if条件中的removeEldestEntry(first)是一个钩子方法,同样控制删除与否,用于给子类实现,默认是返回false
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
如果重写成
private static final int MAX_ENTRIES = 100;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
就表示当数量超过100时删除,删除最老的元素。
为什么第一个元素(head)就是最老的元素?
因为根据前面afterNodeAccess可知道:每次访问元素,都会把该元素挪到队尾。那么,相对应的队头就是最长时间没被访问过的元素。
这就是所谓的LRU(Last Recently Used 最近最少使用)缓存淘汰算法。
其原理是 :如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很低,当数据所占据的空间达到一定阈值时,这个最少被访问的数据将被淘汰掉。
afterNodeRemoval
删除节点之后
前面在执行removeNode(hash(key), key, null, false, true);之后,就会在该方法里执行afterNodeRemoval方法
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
解释:
和afterNodeAccess类似,同样是创建当前节点前后两个指针b,a。
把b指向a,就把p节点排除掉了(同时考虑p点所在的三种可能位置:头,中间,尾)
小结
通过前面几个方法,我们对LinkedHashMap就有了一个基本的了解:
- LinkedHashMap是在HashMap基础上增加了一个链表
- 实现机制上并没有增加一个所谓”链表“的数据结构,而是
继承并扩充了HashMap的Node节点,把HashMap的普通链表节点(HashMap为什么需要用链表节点来存储数据?),变成了双向链表节点(为什么要双向链表?),然后又增加了head,tail成员变量,一个”看不见的双向链表“就形成了。 - 为什么HashMap需要用链表节点来存储数据:因为HashMap在遇到Hash冲突时,需要用链表或红黑树来把冲突的数据”串起来“。
- 为什么LinkedHashMap需要双向链表:因为LinkedHashMap在实现顺序存储时,增加了”按最近访问时间“的机制来排序(accessOrder=true)。要实现这种特性,就需要在增加,访问节点时对节点进行重新排序(涉及到了删除节点),一旦涉及删除节点,就需要双向链表来快速(如果不是为了快速,单向链表也可以从头遍历找到节点)删除操作。
- HashMap实现了很多”钩子函数“,比如afterNodeAccess(访问节点之后的操作),afterNodeInsertion(插入新节点之后的操作)…。LinkedHashMap作为HashMap的子类,很好的利用了这些钩子函数。通过重写,改写成符合自己特性的方法。从而实现”扩充HashMap“的效果(HashMap中的方法都还正常使用,只不过效果略有不同,这也就是所谓的Java多态)
实现LRU缓存
通过前面的源码解析,我们知道LinkedHashMap有意让用户把LinkedHashMap实现为LRU缓存。只需要继承LinkedHashMap,重写唯一的一个protected方法即可。
demo
/**
* 实现一个LRU算法淘汰策略的缓存
*/
public class MyLruCache extends LinkedHashMap {
private int capacity;//缓存容量
public MyLruCache(int capacity) {
//缓存淘汰采用LRU算法策略
super(capacity, 0.75f, true);
this.capacity = capacity;
}
//重写protected方法,控制删除元素的条件
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > capacity;
}
public static void main(String[] args) {
MyLruCache mc = new MyLruCache(100);
mc.put("aa", "aa");
}
}
其中调用父类构造方法 super(capacity, 0.75f, true);
第一个参数是缓存容量
第二个参数,0.75f是HashMap的扩容因子默认值。具体原理请见【另一篇博客】
第三个参数accessOrder=true代表采用“访问顺序”排序,也就是LRU淘汰策略(见前面afterNodeAccess中的用法)
优化
既然作为缓存,一般情况下都是作为公共缓存,供多线程访问,保证并发安全是基本要求。
Map m = Collections.synchronizedMap(new MyLruCache(100));
通过Collections.synchronizedMap将Map转成线程安全的。
总结
- LinkedHashMap通过拓展HashMap的节点,构造出双向链表,从而实现出遍历性能还不错的链表结构。
- LinkedHashMap是建立在HashMap的良好设计模式基础上,通过重写一些钩子函数,方便的拓展了HashMap的功能
- LinkedHashMap可以方便的实现一个LRU(最近最少访问淘汰策略)的缓存。同时注意要把缓存转成线程安全的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!