ChatGPT 4 测试Algorithm co-pilot prompts
收到中科院课程网站的一份邮件
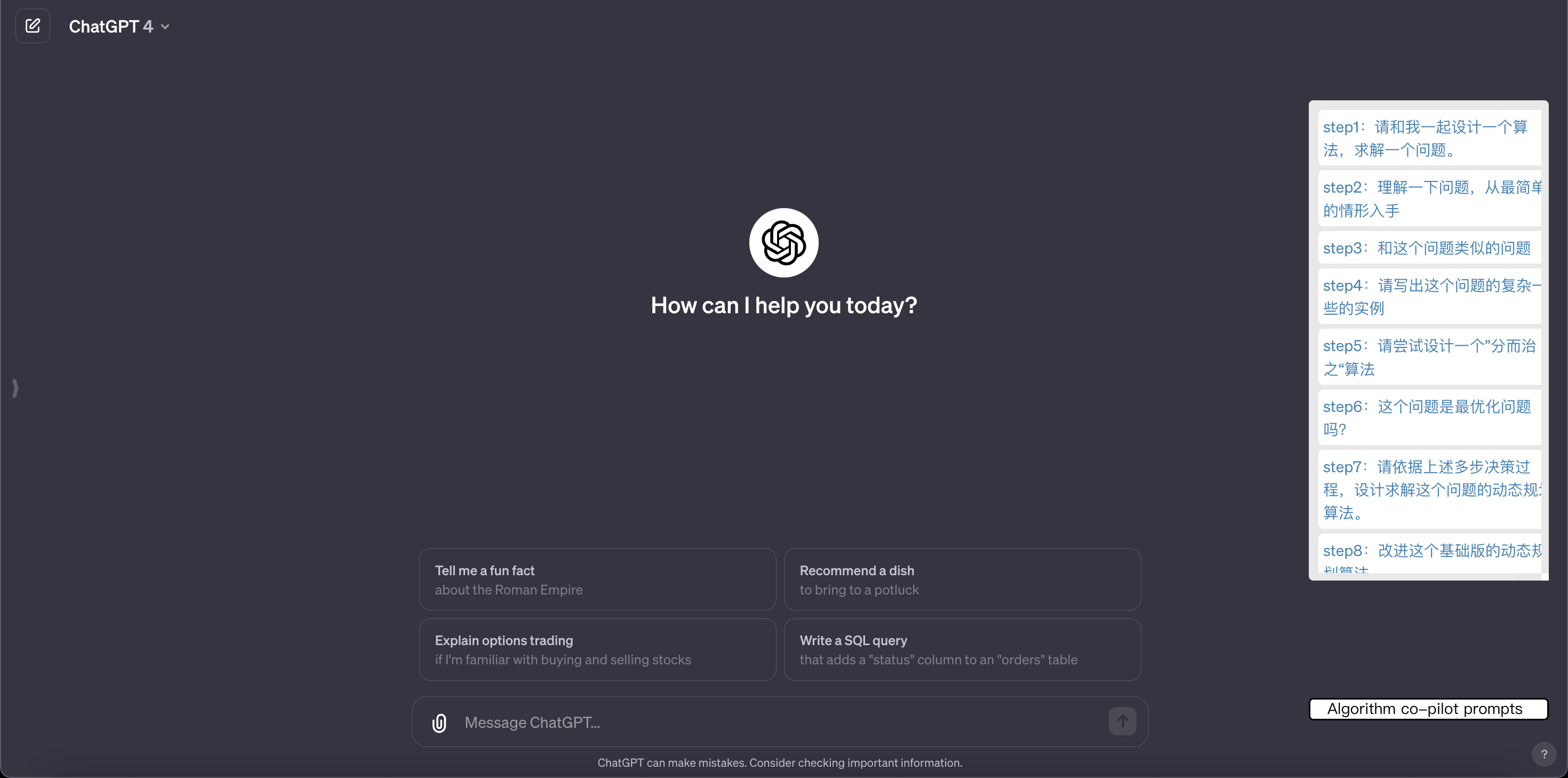
使用GPT4测试该插件的功能,仅供自己学习使用。
测试用例:Leetcode算法题 135. 分发糖果
困难
n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。
你需要按照以下要求,给这些孩子分发糖果:
- 每个孩子至少分配到
1个糖果。 - 相邻两个孩子评分更高的孩子会获得更多的糖果。
请你给每个孩子分发糖果,计算并返回需要准备的 最少糖果数目 。
示例 1:
输入:ratings = [1,0,2]
输出:5
解释:你可以分别给第一个、第二个、第三个孩子分发 2、1、2 颗糖果。
示例 2:
输入:ratings = [1,2,2]
输出:4
解释:你可以分别给第一个、第二个、第三个孩子分发 1、2、1 颗糖果。
第三个孩子只得到 1 颗糖果,这满足题面中的两个条件。
提示:
n == ratings.length1 <= n <= 2 * 1040 <= ratings[i] <= 2 * 104

这个问题可以通过一种双向遍历的算法来解决。我们可以分两个步骤来处理:
- 从左向右遍历:为每个孩子分配糖果,保证每个孩子至少有一颗糖果,并且如果一个孩子的评分比他左边的孩子高,那么他应该得到比左边孩子更多的糖果。
- 从右向左遍历:再次检查并调整糖果分配,以确保如果一个孩子的评分比他右边的孩子高,那么他应该得到比右边孩子更多的糖果。
在实现这个算法时,我们需要两个数组来分别记录从左到右和从右到左遍历时每个孩子应该得到的糖果数。最后,对于每个孩子,我们取两个方向计算出的糖果数的较大值,这样就能满足题目中的所有要求。
现在,我将编写这个算法的伪代码和Python实现代码。
伪代码
function minCandies(ratings):
n = length of ratings
if n == 0:
return 0
left_to_right = array of size n, initialized with 1
right_to_left = array of size n, initialized with 1
// 从左向右遍历
for i from 1 to n-1:
if ratings[i] > ratings[i-1]:
left_to_right[i] = left_to_right[i-1] + 1
// 从右向左遍历
for i from n-2 down to 0:
if ratings[i] > ratings[i+1]:
right_to_left[i] = right_to_left[i+1] + 1
// 统计总糖果数
total_candies = 0
for i from 0 to n-1:
total_candies += max(left_to_right[i], right_to_left[i])
return total_candies
Python实现代码
def minCandies(ratings):
n = len(ratings)
if n == 0:
return 0
left_to_right = [1] * n
right_to_left = [1] * n
for i in range(1, n):
if ratings[i] > ratings[i-1]:
left_to_right[i] = left_to_right[i-1] + 1
for i in range(n-2, -1, -1):
if ratings[i] > ratings[i+1]:
right_to_left[i] = right_to_left[i+1] + 1
total_candies = sum(max(left_to_right[i], right_to_left[i]) for i in range(n))
return total_candies
这个代码应该可以正确解决你描述的问题。你可以试着运行这个代码,看看是否得到了期望的结果。
测试通过


当然,对于这个问题,最简单的实例是只有一个孩子的情况。在这种情况下,问题的输入变得非常简单:
- 输入:
ratings = [x],其中x可以是任何非负整数,表示这个唯一孩子的评分。
根据题目要求,每个孩子至少要分配到1个糖果。因此,对于这个最简单的实例,不论孩子的评分是多少,我们都只需要分配1个糖果。
- 输出:
1
这是因为没有其他孩子与之比较,所以无论这个孩子的评分是什么,他都只会获得1颗糖果。这是符合题目要求的最少糖果数目。
我们可以通过直接观察来验证这个解的正确性。在只有一个孩子的情况下,由于没有相邻的孩子来进行比较,所以最少和最多的糖果数都是1。因此,这个解是正确的。

这个问题与“计算数组中递增子序列的长度”有相似之处。在递增子序列问题中,我们需要找到数组中最长的连续递增的部分。然而,尽管这两个问题看起来相似,它们在算法实现上有一些关键的不同点:
-
目标不同:递增子序列问题的目标是找到最长的连续递增序列,而糖果分配问题的目标是分配糖果,满足特定的分配规则。
-
单向与双向:递增子序列问题通常只需要单向遍历数组(例如,从左到右),而糖果分配问题需要两个方向的遍历。首先从左到右确保每个孩子至少有一个糖果,且评分更高的孩子比左侧的孩子得到更多的糖果;然后从右到左再次遍历以满足评分更高的孩子比右侧的孩子得到更多的糖果。
对于只有一个孩子的简单实例,递增子序列的算法实际上可以给出正确的结果,因为在这种情况下,这个孩子构成了一个长度为1的递增子序列。但是,当问题规模变大,即存在多个孩子时,这两个问题就不能用相同的算法来解决了。
为了改进算法以解决糖果分配问题,我们需要特别注意两方面:
- 两个方向的遍历:首先从左到右遍历以保证评分高的孩子比左边孩子得到更多的糖果,然后从右到左遍历以确保评分高的孩子比右边孩子得到更多的糖果。
- 取两个方向的最大值:对于每个孩子,取这两个方向计算出的糖果数的最大值,以满足题目的所有要求。
这种双向遍历的方法是解决这个特定问题的关键,它是递增子序列算法所不具备的。

让我们考虑一个复杂一些的实例。假设有5个孩子,他们的评分数组为 ratings = [1, 3, 2, 2, 1]。这个实例比单个孩子的情况要复杂,因为它涉及到多个孩子以及他们之间的评分比较。
能否分解成简单实例?
对于这个复杂实例,我们不能直接将其分解为单个孩子的简单实例。这是因为每个孩子获得的糖果数不仅取决于他们自己的评分,还取决于他们与相邻孩子的评分比较。因此,孩子之间的相对评分关系是关键,这意味着我们不能独立地考虑每个孩子。
数据结构的分解与组合
-
输入数据结构:输入是一个整数数组,代表每个孩子的评分。虽然我们可以将数组分解为较小的子数组,但由于孩子之间相对评分的重要性,这样的分解不会有助于我们找到问题的解决方案。
-
输出数据结构:输出是一个整数,表示总共需要的最少糖果数。这个输出是基于整个评分数组的,不能简单地由子数组的解组合而成,因为每个子数组中孩子的相对评分可能会影响到总体的糖果分配。
解决方案的实现
因此,要解决这个问题,我们需要对整个评分数组进行完整的分析,而不是仅仅依赖于其子部分。我们需要使用前面提到的双向遍历算法来确保正确的糖果分配。这种方法涉及到全局的视角,考虑到了孩子之间的相对评分,而不是单独考虑每个孩子。
在实际应用中,这意味着我们需要考虑整个评分数组,对其进行两次遍历(一次从左到右,一次从右到左),并在这两次遍历的基础上确定每个孩子应该获得的糖果数。最终的解决方案将是这两个遍历过程的综合结果。

尽管分而治之(Divide and Conquer)是一种强大的算法设计策略,但在这个特定的问题中,直接应用分而治之的方法并不完全适合。原因在于,每个孩子获得的糖果数量不仅取决于他们自己的评分,还取决于他们相对于邻近孩子的评分。这种相互依赖性使得将问题简单地分解成独立的子问题变得复杂。
然而,我们可以尝试一种类似分而治之的方法,这种方法基于将数组分割为具有明显峰谷结构的子段。这里的关键是识别出局部的最高点和最低点,因为在这些点处,糖果的分配可以独立于其余部分。以下是这种方法的大致步骤:
-
识别局部最低点和最高点:遍历评分数组,找出局部最低点(即评分低于相邻孩子的孩子)和局部最高点(即评分高于相邻孩子的孩子)。
-
处理局部段:对于每个局部段(从一个最低点到另一个最低点),单独处理糖果的分配。在每个局部段内,从最低点向两边扩展,保证相邻的孩子评分更高的获得更多的糖果。
-
组合结果:将这些局部段的糖果数目加总,得到总的糖果数目。
这种方法类似于分而治之,因为它将问题分解为多个较小的子问题(局部段),独立地解决这些子问题,然后将解组合起来。但这种方法的有效性依赖于能否准确地识别出局部的最高点和最低点,并正确地处理边界情况。
让我们通过一个例子来具体说明这个方法:假设 ratings = [1, 3, 2, 2, 1]。这个数组有两个局部最低点(第一个和最后一个元素)和一个局部最高点(第二个元素)。我们可以将数组分为两个部分:[1, 3, 2] 和 [2, 1],分别处理这两个部分,然后将结果相加。在处理每个部分时,我们从最低点开始向两边扩展,保证评分更高的孩子得到更多的糖果。
这种方法的挑战在于正确处理边界情况,尤其是当局部最高点在两个局部段的交界处时。此外,这种方法可能在效率上不如直接的双向遍历算法,因为它需要额外的逻辑来识别和处理局部段。

这个问题确实是一个最优化问题。我们的目标是最小化分发给孩子们的糖果总数,同时满足两个约束条件:每个孩子至少得到一个糖果,以及评分较高的孩子得到更多的糖果。下面我们将通过分析一个简单实例来更好地理解这个问题。
最简单的实例
考虑最简单的实例,即只有两个孩子,他们的评分分别为 [1, 2]。
所有可行解及其目标函数值
- 分发糖果
[1, 2]:总数为1 + 2 = 3 - 分发糖果
[1, 3]:总数为1 + 3 = 4 - 分发糖果
[2, 2]:总数为2 + 2 = 4 - 分发糖果
[2, 3]:总数为2 + 3 = 5 - 以此类推…
在这些可行解中,第一个方案 [1, 2] 是最优解,因为它满足了所有的条件,并且总糖果数最少。
问题的分解和多步决策过程
这个问题可以被描述成一个多步决策过程,其中每一步对应于决定某个孩子应该得到多少糖果。每一步的决策取决于当前孩子与他们左右邻居的相对评分。
最优子结构
这个问题确实具有“最优子结构”性质。我们可以通过以下递归关系来表达这个性质:
-
对于每个孩子
i,他们应该得到的糖果数量取决于他们与左右邻居的比较结果。具体来说,如果i的评分高于他的左邻居,他应该得到比左邻居更多的糖果;如果i的评分高于他的右邻居,他应该得到比右邻居更多的糖果。 -
因此,我们可以分别计算从左到右和从右到左的糖果分配,并取每个位置上这两个值的较大者作为最终的糖果数量。
子问题的独立性和重叠
子问题在这个问题中是重叠的。例如,在计算某个孩子应得的糖果数时,需要考虑他左右两边的孩子。因此,同一个子问题可能会在处理相邻孩子时被重复考虑。
为了避免重复求解,我们可以使用动态规划的方法,其中一个重要的技巧是“以存代算”。我们可以用一个数组来存储每个孩子应得的糖果数。当我们计算一个新的孩子的糖果数时,我们先检查这个数组,看看是否已经计算过。这样,我们就可以避免重复计算同一个子问题,提高算法的效率。
总的来说,这个问题的解决方案涉及到对整个评分数组的综合分析,并使用动态规划技术来优化重复子问题的处理。

要设计一个贪心算法来解决这个问题,我们首先需要明确问题的多步决策过程,并为每一步定义一个小目标。然后,我们可以尝试设计一个贪心规则来求解出每步的最优解。下面,我将按照这个思路来设计贪心算法。
第一种思路:直接设计贪心规则
多步决策过程
在这个问题中,每一步的决策涉及到决定一个孩子应该得到多少糖果。每个孩子得到的糖果数量应满足两个条件:每个孩子至少得到一个糖果,且评分更高的孩子比他们的邻居得到更多的糖果。
每步小目标
每一步的小目标是在满足上述条件的情况下,尽可能少地分配糖果给当前的孩子。
贪心规则
我们可以设计以下贪心规则:在遍历孩子时,如果一个孩子的评分高于他左边的孩子,那么他应该得到比左边孩子更多的糖果;否则,他只得到1颗糖果。
例子
考虑评分数组 ratings = [1, 2, 2]。根据贪心规则:
- 第一个孩子得到1颗糖果。
- 第二个孩子的评分高于第一个孩子,所以他得到2颗糖果。
- 第三个孩子的评分等于第二个孩子,所以他只得到1颗糖果。
这样分配糖果的总数是 1 + 2 + 1 = 4,这是最优解。
完整的贪心算法
def minCandies(ratings):
n = len(ratings)
candies = [1] * n
for i in range(1, n):
if ratings[i] > ratings[i - 1]:
candies[i] = candies[i - 1] + 1
for i in range(n - 2, -1, -1):
if ratings[i] > ratings[i + 1]:
candies[i] = max(candies[i], candies[i + 1] + 1)
return sum(candies)
第二种思路:从动态规划到贪心
动态规划算法
首先设计一个动态规划算法。这个算法基于两个数组,分别从左到右和从右到左记录每个孩子应得的糖果数。然后,对于每个孩子,取两个方向计算出的糖果数的较大值作为该孩子的最终糖果数。
观察最优决策规律
通过观察多步决策过程中的最优解,我们可以发现,最优解通常是在满足每个孩子至少一个糖果的基础上,只在必要时增加糖果数(即当一个孩子的评分比他的邻居高时)。
设计贪心规则
基于上述观察,我们可以总结出贪心规则:如果一个孩子的评分高于他的邻居,他应该得到比邻居更多的糖果;否则,他只得到1颗糖果。这实际上与第一种思路中的贪心规则相同。
因此,第二种思路最终导出的贪心算法与第一种思路是一致的。这个算法在实际应用中通常能得到正确的最优解。

设计一个“逐步改进”的算法来解决这个问题,我们首先需要确定如何获取一个初始的可行解,然后定义如何从一个可行解过渡到另一个更优的可行解。这个过程涉及到对当前解的持续调整,直到达到最优解或者一个足够好的解。下面是算法的具体步骤:
1. 获取初始可行解
初始的可行解可以是给每个孩子分配1颗糖果。这显然是一个可行解,因为它满足每个孩子至少得到一个糖果的要求。
2. 定义可行解之间的关系和变换
可行解之间的关系是基于给孩子们分配的糖果总数。一个可行解可以变换到另一个可行解,通过增加某些孩子的糖果数以满足评分比邻居高的孩子得到更多糖果的规则。
3. 计算新可行解的目标函数值
每次变换后,我们需要计算新的可行解的总糖果数。如果新的总数比原来的少,这个新的解就更优。
4. “逐步改进”算法
从初始解开始,逐步调整糖果分配:
- 从左到右遍历:检查每个孩子与他左边邻居的评分。如果一个孩子的评分高于他的左邻居,增加他的糖果数,使其比左邻居多1颗糖果。
- 从右到左遍历:再次检查每个孩子与他右边邻居的评分。如果一个孩子的评分高于他的右邻居,且他当前的糖果数不比右邻居多,那么增加他的糖果数,使其至少比右邻居多1颗糖果。
- 重复以上步骤,直到没有更多的改进可以被做出(即在一次完整的从左到右和从右到左的遍历中,没有糖果数的改变)。
这种方法逐步增加糖果的总数,直到找到最少的糖果数满足所有条件。这个算法是有效的,因为它在每一步都试图最小化总糖果数,同时确保高评分的孩子比他们的邻居得到更多的糖果。
def minCandies(ratings):
n = len(ratings)
candies = [1] * n
# 从左到右遍历
for i in range(1, n):
if ratings[i] > ratings[i - 1]:
candies[i] = candies[i - 1] + 1
# 从右到左遍历
for i in range(n - 2, -1, -1):
if ratings[i] > ratings[i + 1]:
candies[i] = max(candies[i], candies[i + 1] + 1)
return sum(candies)
这个算法确保了在每一步都试图找到一个更优的解,并且最终得到的解是满足题目要求的最优解。

这个问题的解不能简单地被表达成由 0 和 1 组成的向量 x = [x1, x2, ..., xn]。在这个问题中,解的形式是一个整数数组,其中每个元素表示对应孩子得到的糖果数,而这个数字可以是任何满足题目条件的正整数,而不仅仅是 0 或 1。
基础版的枚举算法
要设计一个基础版的枚举算法,我们需要枚举出所有可能的糖果分配方式,然后从中选择一个使得总糖果数最小的分配。由于每个孩子至少得到一颗糖果,且没有上限,这意味着理论上可能的分配方式是无限的。但在实际操作中,我们可以设定一个合理的上限,例如最多糖果数不超过孩子人数的两倍。
def enumerateCandies(ratings, max_candies):
n = len(ratings)
best_distribution = None
min_candies = float('inf')
def is_valid(distribution):
for i in range(n-1):
if (ratings[i] < ratings[i+1] and distribution[i] >= distribution[i+1]) or \
(ratings[i] > ratings[i+1] and distribution[i] <= distribution[i+1]):
return False
return True
def enumerate_distributions(index, current_distribution):
nonlocal best_distribution, min_candies
if index == n:
if is_valid(current_distribution):
total_candies = sum(current_distribution)
if total_candies < min_candies:
min_candies = total_candies
best_distribution = current_distribution[:]
return
for candies in range(1, max_candies + 1):
current_distribution[index] = candies
enumerate_distributions(index + 1, current_distribution)
enumerate_distributions(0, [0] * n)
return best_distribution
# Example
ratings = [1, 2, 2]
max_candies = 2 * len(ratings)
best_distribution = enumerateCandies(ratings, max_candies)
print("Best distribution:", best_distribution)
改进版枚举算法:剪枝
为了提高枚举算法的效率,我们可以引入剪枝策略,来避免探索那些无法产生最优解的部分解。在这个问题中,我们可以在每一步计算当前的部分解的最小可能总糖果数。如果这个数已经超过了当前的最小糖果数,我们就可以停止进一步探索这个分支。
在上述代码中加入剪枝的方法是在 enumerate_distributions 函数中检查当前分配的糖果数是否已经超过 min_candies。如果是,就返回而不再继续探索。
这种剪枝策略能显著减少搜索空间,从而提高算法的效率。不过,即使有了剪枝,枚举算法仍然可能在大型问题实例上变得非常慢,因为其时间复杂度是指数级的。在实际应用中,更高效的方法如动态规划或贪心算法通常是更好的选择。
总结:
自我感觉挺好用的,给一些关于算法问题的提示,可以辅助算法学习者更加深入全面的理解问题
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!