NLP论文阅读记录 - AAAI-23 | 01 Cogito Ergo Summ:通过语义解析图和一致性奖励对生物医学论文进行抽象总结
文章目录
前言

Cogito Ergo Summ: Abstractive Summarization of Biomedical Papers via Semantic Parsing Graphs and Consistency Rewards(23)
0、论文摘要
生物医学出版物的自动合成激发了因文献拥堵而引发的深刻研究兴趣。当前的序列到序列模型主要依赖于词汇表面,很少考虑源文档中提到的实体之间的深层语义互连。这种肤浅的内容转化为捏造的、信息贫乏、冗余且近乎摘录的摘要,严重限制了它们在生物医学中的实际应用,其中专业术语和复杂的事实进一步强调了任务的复杂性。
为了填补这一空白,我们认为摘要生成器应该获取对输入的语义解释,利用结构化和明确的表示来捕获和保存文本内容中最相关的部分。
本文提出了 COGITOERGOSUMM,这是第一个生物医学抽象概括框架,为大型预训练语言模型配备了丰富的语义图。准确地说,我们将两种具有不同目标和粒度的互补语义解析技术(事件提取和抽象含义表示)的图形融入其中,还设计了奖励信号,以通过强化学习最大限度地保留信息内容。
对 CDSR 数据集的广泛定量和定性评估表明,尽管使用的参数减少了 2.5 倍,但我们的解决方案根据多个指标实现了具有竞争力的性能。
结果和消融研究表明,我们的联合文本图模型生成了更具启发性、可读性和一致性的摘要。
一、Introduction
1.1目标问题
鉴于生物医学出版物数量庞大,临床医生、患者和研究人员需要先进的工具来有效浏览文献并掌握重要内容。因此,自动将日常科学发现或见解组织成自然、简洁和信息丰富的综合对于促进知识获取至关重要(Moradi 和 Ghadiri 2019)。为此,抽象文档摘要需要以创造性的方式重新措辞和压缩长且通常迷宫般的文本部分,丢弃冗余和不必要的属性。与开放领域相比,在生物医学中执行此任务会提高*所有作者的贡献相同。版权所有 ? 2023,人工智能促进协会 (www.aaai.org)。版权所有。巨大的挑战和限制(Karamanis 2007)。
事实上,
(i)医学术语和专业语言确实很难解释;
(ii) 科学文件传达精确的领域信息,允许狭窄的解释范围和不可容忍的事实错误;
(iii) 条款往往相互依存并表达复杂的相互作用;
(iv) 知识随着时间的推移而迅速发展。
1.2相关的尝试
尽管基于 Transformer 的预训练语言模型取得了前所未有的进步(Lin 和 Ng 2019),但当前的摘要者仍然面临简洁性、非重复性、流畅性、信息性和忠实性方面的问题(Maynez 等人,2020)。大多数先前的研究仅依赖于表面的文本组织,而忽略了更深层次的底层语义内容(Bender et al. 2021),缺乏结构化表示来封装所提到的实体(例如蛋白质、疾病、药物)之间复杂的远程关联。相反,我们认为这些联系对于文档理解至关重要,并且有利于知识选择。
1.3本文贡献
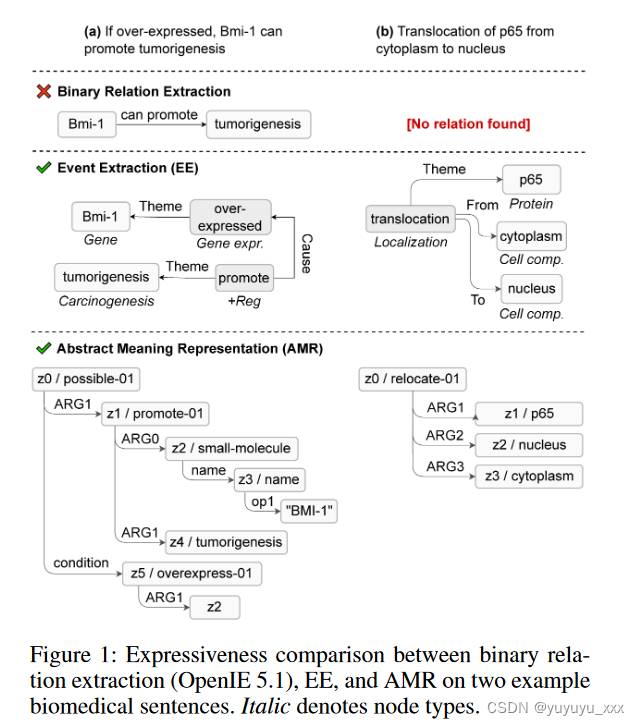
生物医学文献通常由一系列事件和事实证据组成;了解如何在生成模型中利用这些信息至关重要。值得注意的是,语义解析图通过提供能够将概念单元(说什么)与语言能力(如何说)解耦的形式意义表示来标准化许多词汇和句法变化。由于这些表示可以用具有不同目标和属性的各种形式来定义,因此我们强调桥接两个有影响力的语义解析任务的互补优势的重要性:闭域事件提取(EE)和抽象含义表示(AMR)。 EE 是任务驱动的,旨在派生具有特定语义角色的参与者之间的 n 元和潜在嵌套交互,其中事件模式(即目标事件、实体和角色类型)是预先建立的,符合参考本体;它的历史与健康信息学紧密相连(Frisoni、Moro 和 Carbonaro 2021)。 AMR 以语言为基础,旨在以图形方式捕获任何句子的一般含义,作为抽象概念之间的高级语义关系(Banarescu 等人,2013)。图1描述并比较了它们的表达能力。
越来越多的自然语言生成(NLG)研究呼吁关注将显式语义结构纳入摘要过程(Yu et al. 2020),
从而解锁比句子袋更高层次的抽象,以及更准确地模拟人类解释、重写和释义。然而,现有的图形增强方法至少具有以下弱点之一:(i)它们尚未针对生物医学领域进行设计或评估; (ii) 他们采用的图 LSTM 架构难以与 Transformer 竞争; (iii) 它们基于基于开放域三元组的提取,众所周知,这些提取不足以代表文档的完整生物学含义; (iv) 它们不包含确保文档摘要一致性的模块。
我们提出了 COGITOERGOSUMM1,这是第一个基于语义感知变压器的模型,用于生物医学领域的单文档抽象摘要。具体来说,我们使用多关系图神经网络(GNN)将源文档压缩成一组明确的 EE 和 AMR 图,在不强加线性化的情况下产生密集的嵌入。在此基础上,我们探索了一种微调方法,用于将预测的符号表示合并到预先训练的编码器-解码器语言模型中。具体来说,我们通过解码器中的 EE 和 AMR 特定注意机制集成语义解析图,从而帮助关键内容选择和语义理解。我们通过强化学习(RL)优化网络,根据从文档和生成的摘要中提取的含义表示集之间的软对齐来设计一致性引导的奖励信号。
自动和人工评估是在 CDSR(Guo et al. 2021)上进行的,CDSR 是一个流行的数据集,用于生成生物医学评论的外行语言摘要。我们的模型在符合多个质量标准方面进行了实质性改进,在使用的参数减少了 2.5 倍的同时实现了接近最先进 (SOTA) 的性能。实证结果证实了语义图在帮助模型保留基本全局上下文并保持最相关实体之间的事实联系方面的价值。
二.相关工作
2.1抽象概括
基于自监督预训练 Transformer 的序列到序列架构对隐式学习抽象概括程序(Zhang et al. 2020a)产生了强烈的推动作用,其中包括多文档(Moro et al. 2022)和低层次摘要程序(Moro et al. 2022)。资源设置(Moro 和 Ragazzi 2022;Moro 等人 2023)。然而,现代解决方案很容易产生幻觉内容(Cao 等人,2018 年;Maynez 等人,2020 年)或依赖提取(参见 Liu 和 Manning,2017 年)。获得对语义和上下文的理解正在成为一种特权,但纯粹根据形式训练的模型无法学习意义(Bender 和 Koller 2020)——即使有更多的数据和巨大的架构维度。
2.2图增强摘要
长期以来,人们一直在研究图结构来实现摘要子任务(即信息提取、内容选择、附加任务)。面实现),根据其成分记录不同的好处。早期的提取摘要技术构建了文档内(Mihalcea 和 Tarau 2004)和文档间(Wan 2008)余弦相似性连接网络来识别显着句子。后期的混合神经系统主要站在普通 GNN 的肩膀上(Wu 等人,2021a),利用基于图的注意力(Tan、Wan 和 Xiao,2017 年)和异构词/句子级节点(Wang 等人)等2020)。至于抽象概括,社区尝试了图形文档表示的混合,从依赖性(Wu et al. 2021b)、情感(Moro et al. 2018)和共指链接(Balachandran et al. 2021)到潜在共现(Frisoni 和 Moro 2020)、话语关系(Li et al. 2020;Chen 和 Yang 2021)和引文网络(An et al. 2021)。为了更好地思考实体交互,OpenIE 框架中的<主语、谓语、宾语> 三元组的组合(Angeli、Premkumar 和 Manning 2015)已??成为基石(Fan 等人,2019 年;Huang、Wu 和 Wang 2020 年;Ji和Zhao 2021;Zhu et al. 2021)。另一方面,开放域二元关系不足以用于生物医学,存在导出不正确或不完整事实的风险,这些事实难以与后处理进行比较和合并(Frisoni、Moro 和 Carbonaro 2021)。与我们的工作最相关的是通过 AMR 语义分析增强的摘要器(Dohare、Gupta 和 Karnick 2018;Hardy 和 Vlachos 2018;Lee 等人 2021),尽管在一般领域展示了卓越的生成可控性,但在生物信息学中尚未得到充分探索。弗里索尼。等人。 (2022)调查 EE 增强总结,观察到性能由于事件图数量的减少而受到阻碍。此外,现在几乎所有的解决方案都依赖于图 LSTM 架构——它很难与变压器或图到文本的语言转换器竞争——忽略源文本的贡献。据我们所知,我们是第一个将文本、EE 和 AMR 结合起来进行基于 Transformer 的抽象摘要,解决了它们的相互限制。另一个趋势是通过外部知识图进行上下文增强,例如医学的 UMLS(Gigioli 等人,2018)。然而,与灵活的含义表示不同,已知这些资源对现实世界实体的覆盖范围有限且静态。
2.3 抽象概括的强化学习
在传统的编码器-解码器架构中,网络经过训练以最小化下一个令牌预测的最大似然损失,但根据所需自动指标的不一定等效的优化进行评估。此外,解码器在训??练期间知道真实序列,但在测试时没有这样的监督,导致暴露偏差(Ranzato et al. 2016)。
最近,强化学习方法被提出通过直接解决不可微分的度量优化问题、不需要黄金摘要以及在每个时间步允许全局决策而不是局部(代币级)决策来减轻这些差异。克里斯辛斯基等人。 (2018); Paulus、Xiong 和 Socher (2018);夏尔马等人。
(2019)利用 ROUGE 分数来鼓励新颖性和相关性,忽略实体交互。夏洛姆等人。
(2019); Huang、Wu 和 Wang(2020)提出填空和三重重建问答奖励,需要临时模型来生成人工问题。相反,我们根据预测摘要与原始文档的关键内容一致性来奖励预测摘要,衡量其语义图之间的一致性。
三.本文方法COGITOERGOSUMM 框架
3.1 问题陈述
给定数据集 C=(d1, d2, . . . , dk),每个文档 di 由 n 个标记 d=(x1.x2, . . . , xn) 的序列组成。 di 的语义在文档级事件和 AMR 图(分别为 Ge 和 Ga)中得到压缩。形式上,目标是通过对条件分布 p(y1, y2, …, ym|x1, x2,…,xn,Ge,Ga),可概念化为神经符号任务。我们将Ge和Ga分开,让模型实现它们独特的特性。图2示出了具体示例。
3.2 图表构建
我们首先获得句子级的EE和AMR输出,即从两个角度表征每个句子核心概念的多关系有向无环图结构。然后,我们通过图融合来构建 Ge 和 Ga,确保最终得到单个明智互连的文档图,而不是两组小型不相交网络。
事件图
与 BioNLP-ST 竞赛一致,事件是从触发器(证明其发生的跨度,例如“交互”、“调节”)、一种类型(例如,“绑定”、“正则化”),以及一组被分类为实体或事件本身的参数——发挥一定的作用(例如,“主题”、“原因”)。预期寻求的交互的特殊性使得 EE 领域具有特定性。我们采用 DeepEventMine(Trieu 等人,2020),这是一个端到端框架,在七个生物医学基准上保持 SOTA。我们按照 Frisoni 等人的方法将输出对峙 .a* 注释文件转换为异构事件图。 (2022)。节点表示触发器或实体,而边用于实体-触发器或触发器-触发器关系,第二个边用于嵌套事件。与 AMR 不同,事件图并不适用于所有句子,而仅适用于表达模型已训练的所需交互的句子。
AMR 图
AMR 旨在产生一种语言中立的含义表示,从英语中抽象出来,并在有根图中提供从单词到概念(对象、属性等)的抽象层。它涵盖了约 100 个广泛使用的 PropBank 语义角色;作为 EE,注释包括实体/角色识别和类型。我们使用 SOTA 文本到文本 AMR 解析器(Bevilacqua、Blloshmi 和 Navigli 2021),在 AMR 3.0 (LDC2020T02) sembank 上的 Smatch 得分为 83.0。由于许多 EE 输出可能为空并损害模型的鲁棒性(Frisoni. et al. 2022),AMR 补充并不总是可利用的事件图。
图合并和重新连接
在 EE 和 AMR 形式体系中,实体、触发器或概念被规范化并由单个图片段表示,无论它在句子中重复出现多少次(语义完整性)。如果一个节点履行多个角色,AMR 涵盖句内共指边类型。在事件和编辑的 AMR 表示之上,我们单独操作图形重新布线以反映文档结构并增强信息流。从机制上讲,我们引入了人工句子节点,每个节点都连接到源自该提及的所有事件/AMR 顶点。句子节点按照位置顺序相互链接,并由主节点收集。由此产生的 Ge 和 Ga 图表述了句子内和句子间的信息,允许按叙述顺序、概念关联或邻近度进行文档遍历。
Model
受图赋能 LSTM 的局限性(Frisoni. et al. 2022)的启发,COGITOERGOSUMM 扩展了基于预训练的 BART 架构(Lewis et al. 2020),具有在解码期间处理语义解析图并保留最相关的灵活能力通过 RL 获取信息。图 3 描绘了整体架构,基于四个模块构建,即文本编码、图编码、语义驱动的多视图解码和一致性奖励。
文本编码器
我们通过可学习的 BART 编码通道将输入文档馈送到文本双向编码器 Et(·)。记录 di 的 l 个标记在其上下文隐藏表示中进行转换:
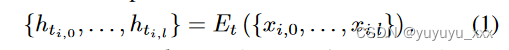
图编码器
节点初始化。由于所有节点都附有文本,因此我们使用预先训练的 BART 语言模型 En(·) 的嵌入来初始化它们的特征。
明确地,给定一个带有标记化文本属性 tokens(i) 的触发器/实体/概念节点 i,我们取其在长输入文档上下文中的每个标记嵌入的平均值,即 En([x1, x2, … , xn∥tokens(i)]),其中 [.∥.] 表示串联运算符。为了减少结构化预测噪声,我们将最大节点长度设置为 5 个标记。对于事件图,我们还添加了 DeepEventMine 学习到的实体和触发器类型。最后,对于句子和主节点,我们分别对句子跨度和整个文档的标记嵌入进行平均。
边缘感知图注意力网络。通过两个图编码器 EGe (·) 和 EGa (·),我们采用 Ge 和 Ga 建模的多视图语义来学习监督节点嵌入并挖掘隐式关系。我们的 GNN 模块依赖于图注意力基础(GAT)(Velickovic 等人,2018),它通过 L 层消息传递(共享参数)和多头注意力邻域聚合来诱导节点表示。由协作节点组成的图中的消息传递(Lodi、Moro 和 Sartori 2010;Cerroni 等人 2013)实际上是一种借鉴通信网络和分布式算法的既定工作模式。由于Ge和Ga是多关系图,我们扩展GAT以考虑连接两个节点
的边类型e。在第 l 层中,我们通过以下方式更新每个节点 i 的表示 ?h(l) i ∈RD:
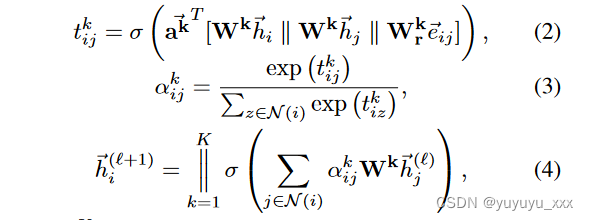
其中 ∥K k=1 表示 K 个注意力头的串联,αk ij 是由 k- 计算得到的归一化注意力权重
第一个注意力头,N(i)是包含i(包括i)的一阶邻居的集合,?eij是连接节点i和j的关系类型2的one-hot嵌入,Wk,Wk r和?ak是可训练参数,σ 是 LeakyReLU 非线性。
解码器
受 Chen 和 Yang (2021) 的启发,我们通过多粒度解码器 D(·) 聚合不同级别的编码表示,该解码器将第 l 个标记预测为:
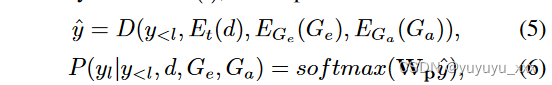
其中 Wp 代表可训练的线性投影。我们用两个额外的交叉注意力(事件注意力和 AMR 注意力)来补充 BART 变压器解码器,这两个交叉注意力是在 EGe 和 EGa 并行学习的节点表示上进行的。我们在原始文本交叉注意力之后将它们合并到每一层中。令牌、事件和 -AMR 参与向量(at、ae、aa)通过前馈网络组合成语义感知表示。为了加速新模块的训练并减轻早期随机初始化图编码器和交叉注意力的负面影响,我们在关注每个解码器层中的语义图后将 ReZero (Bachlechner et al. 2021) 应用于残差连接: as = at + αas,其中 α 是一个可学习参数,调节语义图上交叉注意力的更新。
培训目标和一致性奖励
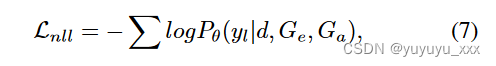
其中 θ 表示模型参数集。除了语法正确之外,我们还希望生成的摘要能够尽可能多地保留原始文档中的关键信息。从 PICO(DeYoung 等人,2021)的成功中汲取灵感,我们相信结构化语义表示不仅适用于改进文本生成,还适用于生物医学一致性评估。基于这种直觉,我们设计了一个轻量级的奖励函数 ψ 来最大化文档摘要含义重叠的不可微分程度,这可以通过第二阶段的 RL 训练来实现。我们参考了 Smatch(F-score)(Cai 和 Knight 2013),度量计算两个 AMR 图之间的匹配三元组,受益于与总结目标 ROUGE 更高的人类事实判断相关性(Ribeiro 等人 2022)。文档级一致性奖励通过平均池化获得;将预测摘要句子的每个 AMR 图与源句子的所有 AMR 图进行比较(一对多软对齐):
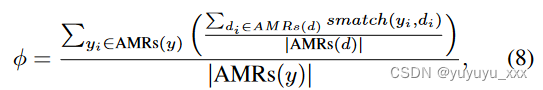
其中AM Rs(·)代表句子级AMR图。给定一个起始策略 π 对应于按照等式训练的模型。在图 7 中,我们将自回归预测的标记视为动作,并采用近端策略优化(Schulman et al. 2017)来最大化:
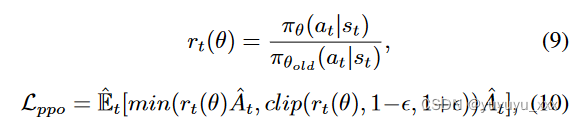
其中 rt(θ) 表示迭代 t 时策略下的操作(即,根据先前的 token st 有条件生成的标记 at)与先前策略下的操作之间的概率比。 ^ E[. 。 。 ] 表示有限批次样本的经验平均值; Clip 函数与 ε 超参数相结合,确保策略在迭代过程中不会发生太大变化; ^ A 是优势函数,是对当前状态下所选动作所获得的相对改进的估计。为了计算优势,我们使用广义优势估计公式(Schulman et al. 2016):
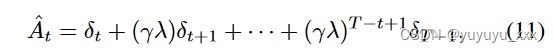
其中 δt = ψt + γV (st+1) ? V (st); λ 和 γ 是超参数,T 是生成文本的长度。价值函数 V 使用与主模型并行训练的第二个神经网络(Actor-Critic 范式)进行建模。正如(Ziegler et al. 2019)中提出的,我们在奖励函数中添加了一个惩罚项,通过减少预期的 KL? 散度来防止新策略与已经预训练的语言模型偏离太多:
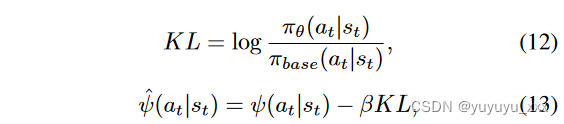
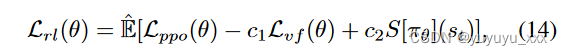
其中 Lvf 是负责更新批评网络的价值函数的均方误差; Sπθ是一个熵项,用于确保训练期间有足够的探索; c1 和 c2 是用于调整损失中每个分量的重要性的超参数。
四 实验效果
4.1数据集
我们在 CDSR 数据集(Guo et al. 2021)上训练和评估我们的模型,这是一个由广泛使用的 Cochrane 系统评论数据库获取的公开语料库3。 CDSR 旨在提高健康素养,评估自动生成的非专业语言摘要生物医学科学评论。据我们所知,它是唯一具有可管理大小和已知图形增强基线的生物医学总结基准。 CDSR 包含 6,677 个高质量对,其中源是专业语言的长摘要,目标是由综述作者或 Cochrane 工作人员编写的普通公众版本。除了创建准确和真实的摘要之外,这项任务还需要联合风格转换,设置术语解释和句子结构简化等障碍,为 COGITOERGOSUMM 勾勒出完美的测试平台。详细信息如表 1 所示。
4.2 对比模型
我们将 COGITOERGOSUMM 与代表性的提取和抽象摘要模型进行正面比较。 ? 甲骨文。它通过选择文档中与目标具有最高 ROUGE-2 分数(句法匹配上限)的句子来创建提取摘要。 ? BERT(Liu 和 Lapata 2019)。带有分类头的句子间编码器,由 Oracle extractive 监督。 ? 指针生成器(参见Liu 和Manning 2017)。 Seq2seq 模型经过训练可以从源中复制单词并从固定词汇表中生成新单词。 ? BART(Lewis 等人,2020)。我们考虑了在 PubMed 上预先训练的模型。 ? EASumm(Frisoni 等人,2022 年)。用于抽象概括的事件增强图 LSTM 架构。
4.3实施细节
我们扩展了 BART-base4 的 HuggingFace 实现,并从在 PubMed5 上预训练的模型初始化权重,留下 42 作为默认训练种子。我们截断输入文档并将最大输出长度设置为 1024。我们利用在 MLEE6 上预训练的 DeepEventMine 模型,MLEE6 是最符合 CDSR 的生物医学基准(Frisoni. et al. 2022)。平均而言,从源文档中提取所有句子级 AMR 和事件图分别需要 3 秒和 1.2 秒。我们使用 PyTorch Geometric 实现 GNN(Fey 和 Lenssen 2019)。在强化学习期间,我们冻结编码器参数并仅训练模型解码器;批评者网络是一个具有一个隐藏层(隐藏大小 256)的多层感知器。超参数列于附录 7 中。每个实验均在具有 Nvidia GeForce RTX3090 GPU、24GB 专用内存、64GB RAM 和 Intel? CoreTM i9-10900X1080 CPU @ 3.70GHz 的工作站上进行。训练我们最好的模型需要 20GB VRAM 和 32 小时(强化学习需要 19 小时); 3.18 kg CO2e 碳足迹,所需能源 9.83 kWh,平均碳水化合物 25.77 Ym(Moro、Ragazzi 和 Valgimigli 2023)。
4.4评估指标
根据常见实践,我们根据 ROUGE-1、ROUGE- 自动评估模型性能2、ROUGE-L F1 分数。这些基于召回的指标通过测量一元组、二元组和最长公共子序列重叠来评估信息量。标准 ROUGE 指标无法对其他重要维度(例如语义连贯性、抽象性和可理解性)提供有意义的说明,而这些维度是我们工作的重点。为了更好地衡量摘要质量,我们应用 BERTScore(Zhang 等人,2020b)、FactCC(Kryscinski 等人,2020),并报告 n-grams 新颖性8 与可读性指标,即 Flesch-Kincaid 年级水平(Flesch 1948)和Coleman-Liau(Coleman 和 Liau 1975)指数 9。我们对除 BERTScore 之外的所有指标都使用默认超参数,其中我们使用 IDF 权重并指定基线=True 的重新调整,以提高可解释性并避免小范围变化。为了定性分析我们生成的摘要,我们进行了深入的人类评估研究。我们随机选择 30 个 CDSR 测试集实例,并邀请 3 位注释者(具有生物医学能力的精通英语的人)来访问我们模型的输出,以及 BART-base 的输出(以随机顺序呈现),即忽略语义的骨架模型。阅读完文章后,每位评委根据四个独立的观点,按照李克特量表从 1(最差)到 5(最好)进行总结:(i)信息性,即传达显着内容; (ii) 事实性,即忠实于文章; (iii) 流利性,即流畅、符合语法且连贯; (iv) 简洁,即不包含冗余和不必要的信息。
4.5 实验结果
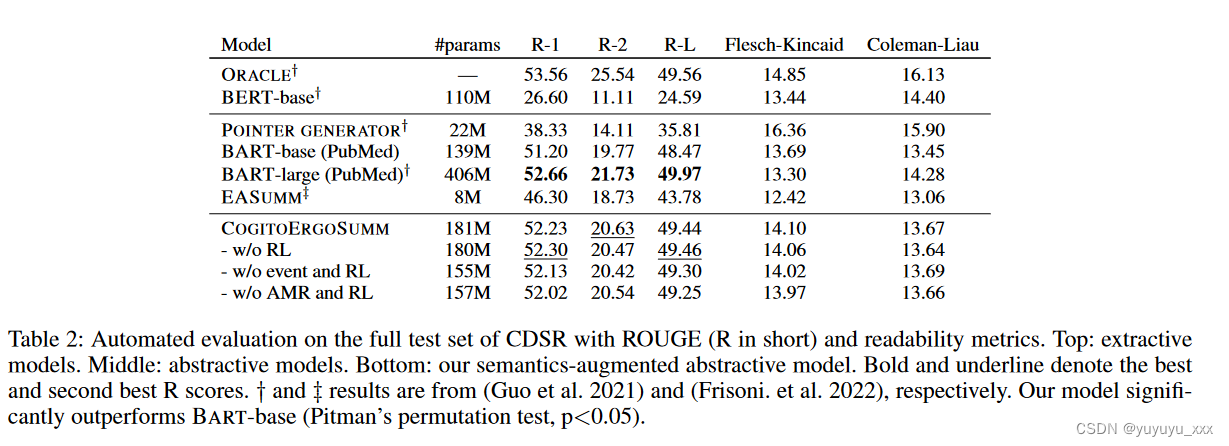
总体定量结果如表 2 所示。缩小范围后,我们发现结构化语义信息可以极大地帮助预训练的语言模型识别源文档中的显着部分。尽管我们的重点是提高语义一致性,但 COGITOERGOSUMM 获得的 ROUGE 分数明显高于以前的提取和抽象方法(BARTlarge 除外),尽管可训练参数减少了 2 倍以上,但我们的模型仍然具有竞争力。值得注意的是,我们以 6 个 R-1/-L 点击败了图 LSTM。每
删除图形编码器时,性能下降最多。即使 AMR 看起来比事件更有影响力,但最好的结果来自它们的混合,这表明这两种类型的语义图在生成更合理的摘要方面相互补充。 ROUGE 无法察觉 RL 效应,但通过更深入的分析却很显着。图 4 展示了同一样本的人工评估结果与自动指标的对比。所有评估者的评估者间一致性的平均肯德尔系数为 0.16。 COGITOERGOSUMM 在检查的每个质量维度上均排名较高,明显与 BART 存在差距(+12.46% 事实性,+6.69% 信息性),并重申了之前的推论。该图强调了 ROUGE 与所需输出属性之间的较差相关性。
我们验证了主要成分的相对影响(表 3)。首先,我们仔细研究不同的图编码器:(i)Levi 变换二分图上的 GAT,平等对待节点和边,以及(ii)边缘感知 GAT;我们发现(ii)带来了巨大的空间,可以确定关系类型在表示学习中的价值。其次,我们测试了结合事件和 AMR 交叉注意力的不同方法,并通过并行策略记录了稍微更好的分数。附录中公开了使用不同随机种子的测试和额外的定性案例研究。
五 总结
在本文中,我们介绍了一个用于注入特定领域和通用语义解析图的框架——事件和AMR——用于生物医学抽象总结的基于变压器的模型。我们提出了新的解码器交叉注意模块和奖励信号,以根据源文档及其正式的底层语义生成高质量的摘要。 CDSR 的实验和消融研究表明,我们的框架在信息性、真实性和可读性方面树立了新的标志,更好地选择和保存具有摘要价值的内容。定性评估表明,我们的模型在与人类判断相关的所有指标上都超越了当前的基线,同时在基于召回的分数(即 ROUGE)上仍然具有竞争力。我们的结果证实了这样的假设:通过图注入的语义感知为架构扩展绘制了一条补充路径。对于未来的工作,我们计划使用深度度量学习来进行高效的文本图检索(Moro、Salvatori 和 Frisoni 2023)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!