Mysql文件-笔记
? ? ?我们小组技术分享mysql,给我表这块,这个知识呀 只要你想学 源源不断 源源不断,我其实想把我们组的分享都弄出来,偷偷的 嘘~
? ? 表是特定实体的数据集合,关系型数据库模型核心,表逻辑存储和实现,物理存储特征:数据在表中是如何组织和存放的
字符集
? ? ?计算机只存储二进制数据,存储字符串需要建立之间的映射关系;
编码:把字符映射成二进制
解码:二进制映射到字符
比较大小:同一字符集多种比较规则
字符集:字符范围/编码规则不一样
? 对于不同字符,不同字符集有不同编码方式
? 我:utf8编码:111001101000100010010001 (3个字节,十六进制表示是:0xE68891)
我:gb2312编码:1100111011010010 (2个字节,十六进制表示是:0xCED2)- ASCII:128个字符,空格 标点符合 数字 大小写字母 不可见字符,可用1字节编码?https://en.wikipedia.org/wiki/ASCII?ASCII码一览表,ASCII码对照表
- ISO 8859-1/latin1 256字符,ascii基础上扩充128西欧常用字符(德法字母)?https://zh.wikipedia.org/wiki/ISO/IEC_8859-1
- GB2312 汉字6763个/拉丁字母/希腊字母/日文平假名/片假名字母/俄语西里尔字母,兼容ascii,如果ascii中1字节其他2字节?https://zh.wikipedia.org/wiki/GB_2312
- GBK 对GB2312扩充并兼容?https://zh.wikipedia.org/wiki/%E6%B1%89%E5%AD%97%E5%86%85%E7%A0%81%E6%89%A9%E5%B1%95%E8%A7%84%E8%8C%83
- utf8 所有字符不断扩充,兼容ascii,变长编码方式,1~4字节?https://en.wikipedia.org/wiki/UTF-8
mysql支持的
-
utf8/utf8mb3:阉割过的utf8字符集,只使用1~3个字节表示字符。 -
utf8mb4:正宗的utf8字符集,使用1~4个字节表示字符。
? ??SHOW CHARSET; #查看字符集
? ?SHOW COLLATION LIKE 'utf8\_%';#utf8下的比较规则
? ?知道列的字符集和比较规则,可用确定存储数据每列实际数据占用的存储空间大小
索引组织表:InnoDB
? ?据主键顺序组织存放
? ? ? ?无主键:首先使用非空唯一索引(多个选建表时第一个定义的非空唯一索引),否则自动建6字节的指针
InnoDB逻辑存储结构
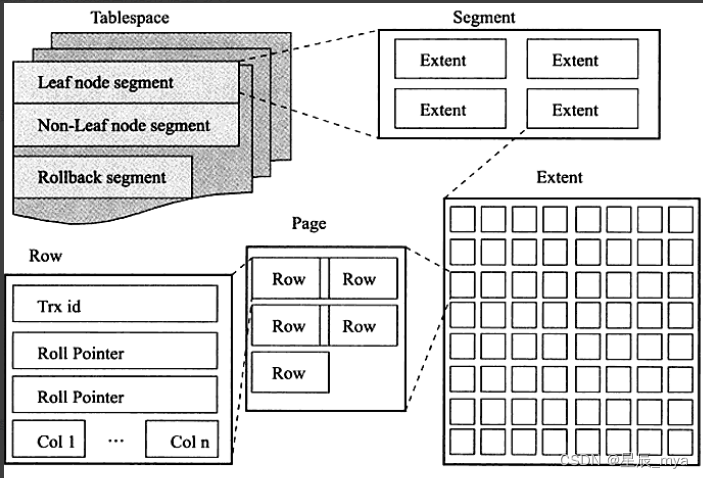
表空间
? 存储结构,含表/索引/大对象长型数据,将数据库中数据组织成 与数据在系统上存储位置相关的 逻辑存储器分组,本身存储在数据库分区组中,默认在共享表空间ibdata1

? 对于独立表空间来说则对应的文件系统中表名.ibd文件,多个页的组合,表空间由若干区组成,256区划成一组,每个区都有对应的XDES entry结构来组成链表,对区分门别类进行管理

?开启innodb_file_per_table后每张表(的数据 索引 插入缓冲Bitmap页)会单独放到一张表空间内,其他undo 事务 插入缓冲索引页 二次写缓冲等还是放到共享表空间
- ? 可恢复性,可通过单一命令备份/复原表空间中的(同一表空间的)对象
- 表空间存储表有限,超过了需要创建附加的表空间
- 可借助自动存储器表空间,由数据库管理器自动管理存储器(尝试平衡容器数据复合)
- (分配)缓冲池隔离数据,提供性能和内存利用率
?为了方便范围查询,对B+树的非叶子节点和叶子节点借助段进行区分,缩小查询范围
系统表空间
整个MySQL进程只有一个系统表空间,额外记录一些有关整个系统信息的页,所以会比独立表空间多出一些记录这些信息的页

区extent
??连续分配的空间,InnoDB引擎页16KB,一区有64个连续页 1M,当数据量特别大的时候为索引分配空间按区为单位分配,使得B+树物理位置相邻
? 1.0x引入压缩页:KEY_BLOCK_SIZE设置每页大小,对应的区被均分
? 1.2x支持innodb_page_size指定默认页大小
分类或状态:
? ?空闲的区free没有被使用的
? ?有剩余空间的碎片区free_frag
? ?没有剩余空间的碎片区full_frag,都被用上了
? ?附属于某个段的区fseg,每一索引可分为叶子节点段和非叶子节点段,InnoDB还另定义些特殊作用的段,这些段中的数据量很大时将使用区来作为基本的分配单位
?
?第一是固定的,本表空间本区的属性,第二个本区本区的页的属性,其中XDES entry(上)
段segment
? ? 逻辑上的概念,若干零散页和完整的区组成段,段组成表,段是数据库的分配单位(段以区为单位申请存储空间),不同类型数据库对象一不同段形式存在
? ? ? ? 创建表会创建表段,创建索引会创建索引段,段不要求区间相邻;InnoDB存储引擎表是索引组织的
? 为段分配存储空间策略:
? ? 开始向表插入数据,段从某个碎片区以单个页为单位分配存储空间
? ? 当段占用了32个碎片区页后,将以完整的区为单位分配存储空间
? ? ? ?碎片区:直属表空间,可用于不同目的(用于段123),不是所有页为了存储同一段而存在

?插入数据的过程:
? ?段比较少,查看表空间是否状态有free_frag的区,找到取零碎页记录,否则找free将其变为free_frag从该区取零碎页记录,循环直到该区full_frag
? ?32个页已经被占满,申请完整的区来插入数据,据segmentId建立链表,插入时先获取not_full链表头节点把数据插入对应的区中,该区用完将该节点移动到full链表中
? ?表中插入一条记录,本质上就是向该表的聚簇索引以及所有二级索引代表的B+树的节点中插入数据
?数据段
? ?B+树叶子节点
索引段
? ?B+树非索引节点

回滚段
? ?管理undolog,每个段记录1024个undo log segment,innoDB默认支持128个回滚段:show variables like 'innodb_undo_logs'
? ? ? ?能支持的max并发事务128*1024,开启事务需要写undo log先去段找空闲位置,有空位时申请undo页
? ? ? ? undolog在commit后将放入一个链表中,判断使用空间小于3/4可被重用,不回被回收,其他事务可记录在当前undolog后面;undolog的离散,清理效率不高
页page/块block
? innodb按页为单位读取,页是磁盘的最小管理单位,默认16KB,1.2x版本后innodb_page_size设置大小
?页类型
FSP_HDR表空间头部信息,存储表空间整体属性,第一个组256个区对应的XDES entry结构
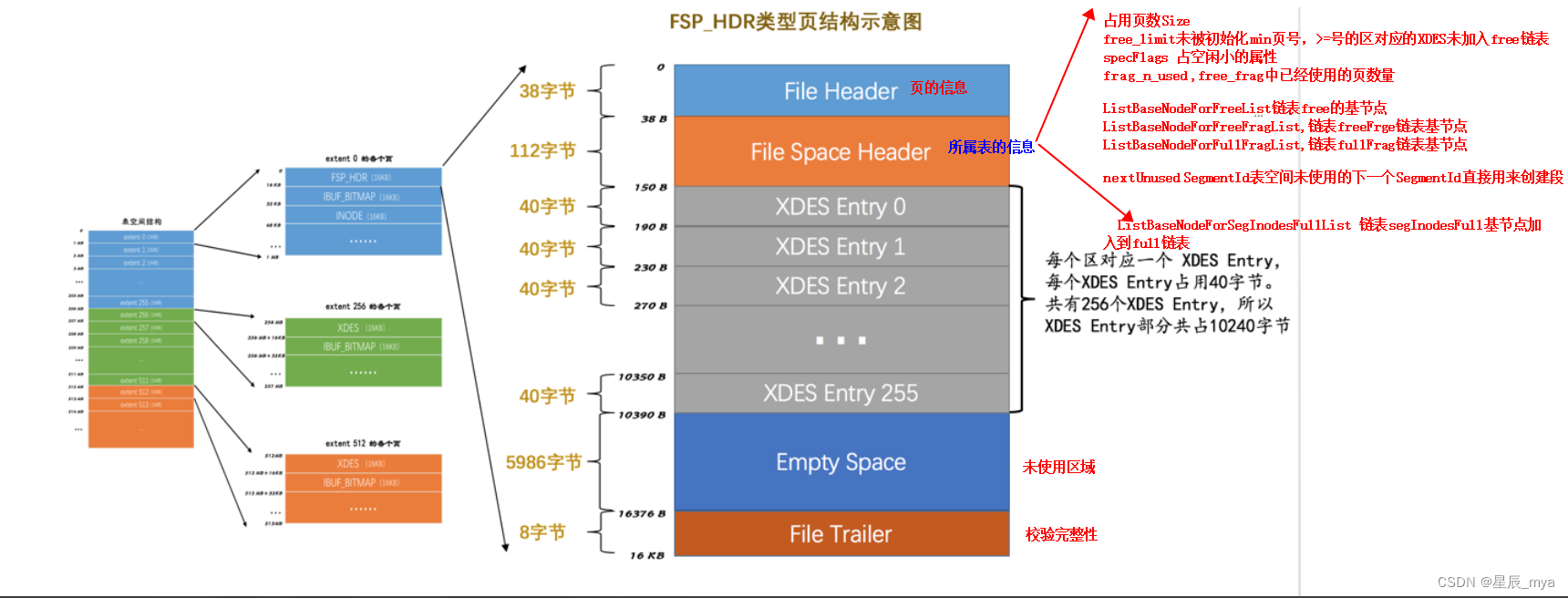
-
FREE Limit:什么时候加入到free链表:什么时候用到什么时候初始化,在该字段表示的页号之前的区都被初始化了,之后的区尚未被初始化 -
Next Unused Segment ID表索引都对应拥有唯一标识SegmentId的2个段,借助当前属性在创建新段时直接使用这个字段的值即可 - Space Flags表空间属性,是否自动把较长字段放到blob页,页大小,是否是共享表空间/临时表空间/是否加密等
XDES

INNODE
为了存储INODE Entry结构
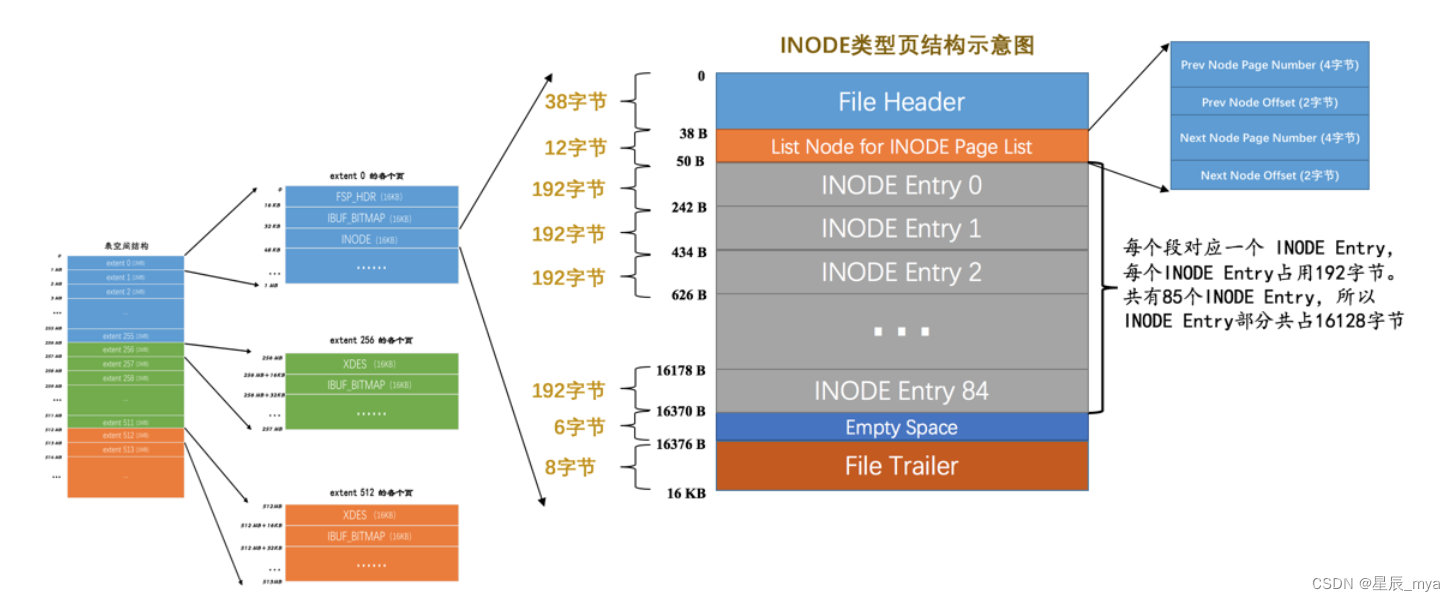
页结构示意图

文件头描述页信息,尾校验完整性,具体通过指针相当于双向链表连接上下(逻辑上)
数据插入记录:新的记录插入从空闲空间中分配空间
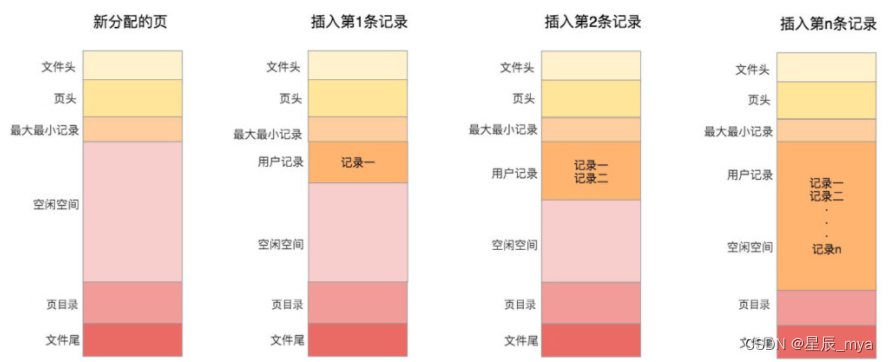
页目录存储每组最后一条记录地址偏移量(槽)每个槽相当于指针指向了不同组的最后一条记录
https://www.cnblogs.com/gered/p/13803642.html
行
? InnoDB按行存放,列式存储,每行最多存放16KB/2-200行记录(7992),? 默认当行最多存储65535byte数据,1byte字节=8bit? 1024byte=1k
? ? show create table 表名;?
? ? alter table 表名 character set utf8mb4;
预估数据占用存储,优化查询(条数/分页)

InnoDB行记录格式**
? ?行记录结构类型:show table status like 'table_name'; 字段row_format
Compact
mysql5.0 ,高效存储数据? ?页中行数据越多,性能越高
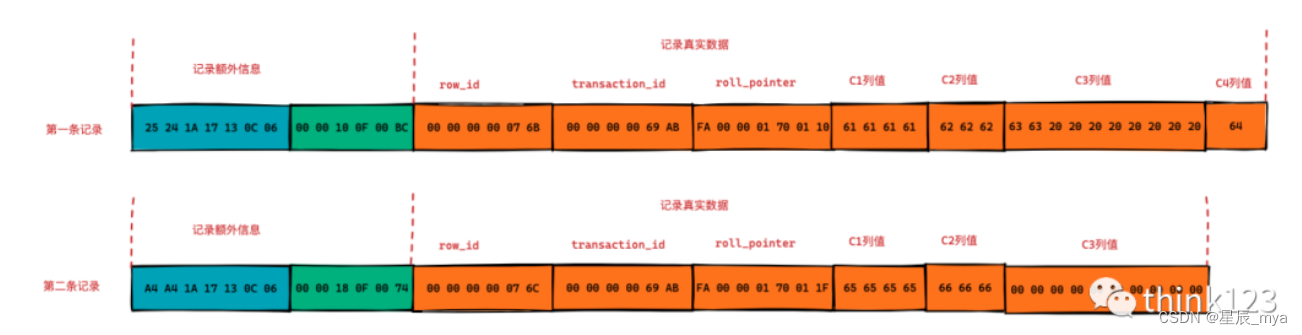
- 变长字段长度列表:非null,有可变列则按列顺序逆序放置,可变字段容许存储的max字节数超过255且真实存储字节数超过127字节使用2字节否则1字节
- NULL标志位:1标识该行数据容许存储null值,0无

- 标记头信息:固定5字节;起始两bit未知;n_owned当前记录有多少条记录

? ? ? ? ? ?delete_mask是否被删除,占用1进制位,0未被删除,1被删除打个删除标记节省移除后其他记录在磁盘上的重新排列的消耗,被删除记录组成垃圾链表占用的是可重用空间,新记录插入把这些被删除记录占用的空间覆盖掉
? ? ? ? ?min_rec_mask非叶子节点的最小记录
? ? ? ? ?heap_no当前记录在本页中的位置,InnoDB会自动给每页加两个记录(伪记录/虚拟记录)代表最小记录和最大记录,对于一个完整记录来说,通过比较主键来比较记录大小:?Infimum + Supremum
? ? ? ? ? ? ? ? ? ?Infimum下界值是010 supermum是011 1xx预留bit

? ? ? ??record_type 当前记录类型,0普通记录 1B+树非叶子节点 2 最小记录 3最大记录 ,上面也能看出来
? ? ? ??next_record页中下条记录的相对位置,真实数据的地址偏移量,链表结构按照主键值由小到大的顺序串连各行记录,Infimun的下一条是本页中最小的用户记录,本页主键值最大的用户记录下一条记录是supremum,所以supresum的next_record是0
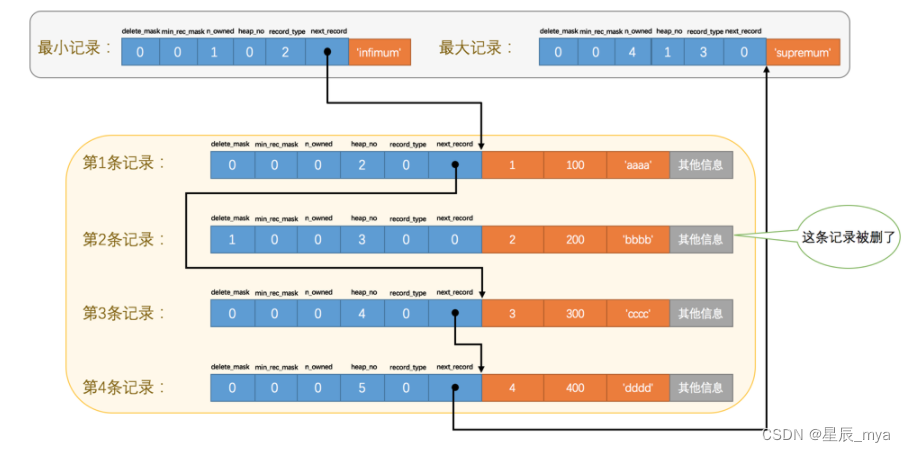
null?不占空间实际,另有两隐藏列:事务ID6字节和回滚指针列7字节,无主键还+rowid
?当列类型为varchar/varbinary/blob/text,列超过768byte的数被放到其他页中,行溢出

zlib算法压缩数据,大长度类型有效存储
CREATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名称
ALTER TABLE 表名 ROW_FORMAT=行格式名称redundant行记录格式
5.0前行记录存储方式

? ? 所有列长度信息逆序存储到字段长度偏移列表,字段长度偏移列表中各列对应的偏移量第一个比特位是否为null的依据,1是否非null
? ? ?字段长度偏移列表存储 每列中的值占用的空间 在记录真实数据结束处 的位置

不同字符集占用的空间不同,对null值的处理不同

1byte_offs_flag使用记录的真实数据的长度(上面说的偏移值)占用空间>127则2字节否则1字节,
行溢出数据
varchar :过大会被自动转成test类型
某列数据非常多,本记录的真实数据只会存储该列的前768字节数据和指向其他页的地址

innodb1.0x,zlib算法压缩行数据(高效存储),存放在BLOB的数据完全行溢出,数据页只存放20字节指针,实际数据在off page
char行结构存储
mysql4.1 char(n) n字符长度,不一定定长
? 不同的字符集在内部存储占用上有区别:多字节的字符编码不再定长 char(10) 10-30字节
InnoDB数据页结构
InnoDB管理存储空间的基本单位,大小16KB

当前页信息:
? ?文件头 file header 38byte,通用信息
? ? ? ? ?fil_page_offset:页偏移值,页号,4字节32bit,表空间最多2^32页,最多支持64TB的数据

? ?页头 page header 数据页专有的一些信息 各种状态,56byte
? ? ? ? 数据页状态信息,page_free可重用空间的首指针
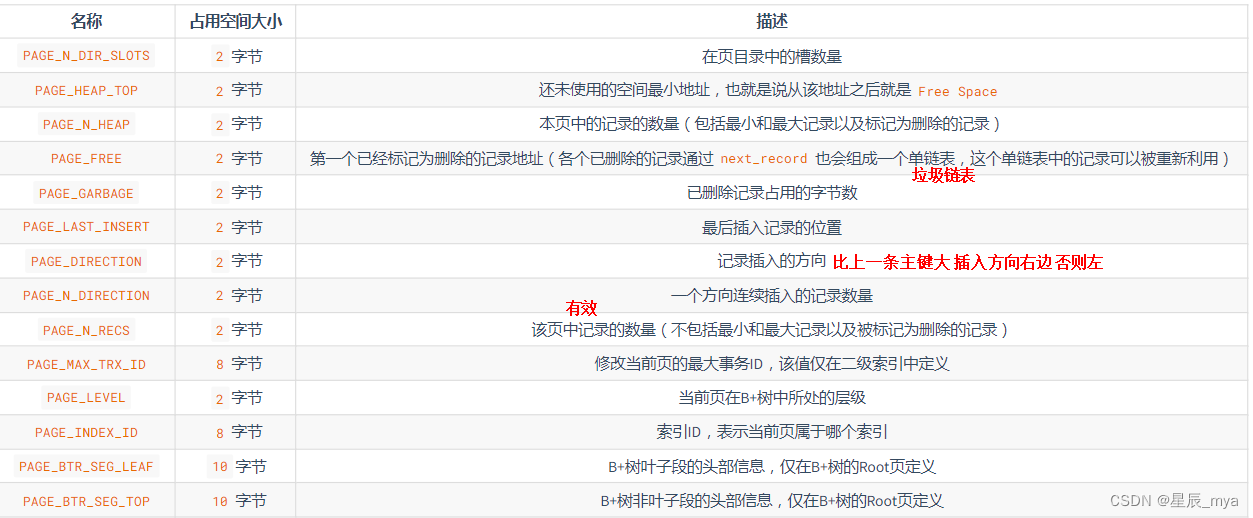
? ? ? ? ? ?将值与FileHeader的fil_page_space_or_chesum和fil_page_lsn比较保证页完整性
? ? ? ? ?
Infimum 和supremum records
? ? ?虚拟行记录,限定记录边界,infimum比该页主键值小,supremum可能大的值还要大的值,不能被删除
实际行记录存储空间:动态
? ?/user records 实际存储的行记录内容
 ? /free space 尚未使用的空间,每次新增记录从freeSpace中申请记录大小的空间划分到UserRecords,当使用完了还要新记录申请新的页
? /free space 尚未使用的空间,每次新增记录从freeSpace中申请记录大小的空间划分到UserRecords,当使用完了还要新记录申请新的页
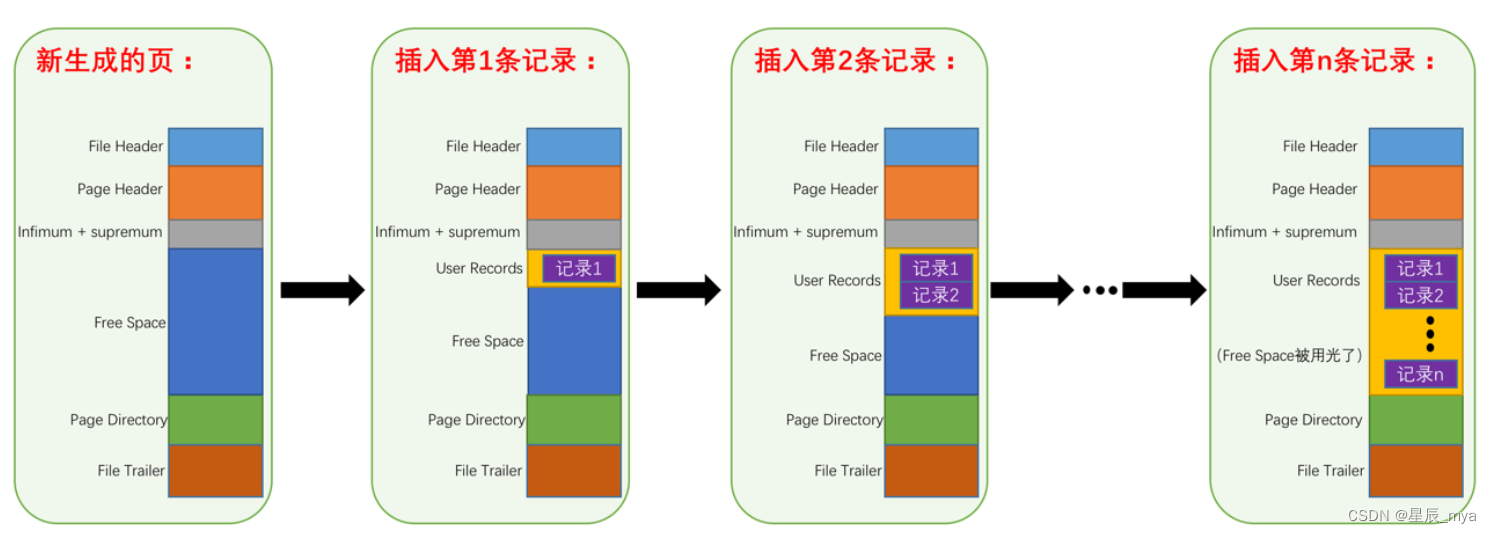
? /page directory页中某些记录的相对位置
? ? 记录的相对位置;槽slots稀疏目录可能含多个按索引键值顺序存放的记录,可利用二叉查找定位记录
b+树索引只能找到记录所在页,数据把页载入到内存,pageDirectory 二叉查找(时间复杂度低内存查找快)
查找数据过程:

约束
?数据的完整性:
? ? 实体完整性:primary key ,unique key,触发器保证
? ? 域完整性:每列值满足特定条件
? ? ? ? 合适数据类型,外键约束(MyISAM不),触发器,default
? ? ?触发器:在insert/delete/update前后自动调用sql命令/存储过程

索引:数据结构,有逻辑上概念还代表物理存储方式
set? sql_mode ='STRICT_TRANS_TABLES' 开启严格校验
外键:即时检查
? ?逻辑外键,业务上维护;
? ?被引用的表父表,引用的表子表
? ? ? ?子表操作cascade当父表delelte和update时子表数据也delete/update
? ? ? ? set null父表delete或update,子表对应更为null值
? ? ? ? not action父表delete/update抛错不被容许
? ? ? ? restrict父表delete/update抛错,默认设置
? ?oracle数据库 建立外键的列也要加个索引,innodb/MicrosoftSQLServer自动加了索引,避免外键无索引导致死锁
??
视图
sql查询定义当作表来使用,没有实际的物理存储,mysql5.0
- 简单:不需要关心对应的表结构/各种条件
- 安全,只能访问容许查询的结果集,对表的权限管理不需要限制到行和列
- 数据独立,视图结构确定,屏蔽表结构变化对用户影响
更新操作:视图定义来更新基本表
物化视图:oracle,根据基表实际存在的表,用于存储耗时较多的sql操作结果
? ? ? ? ? ? ? ? ? microsoft sql server 被称为索引视图
? ? ?查询重写,对基表查询,能否通物化视图直接得到结果
? ? ?刷新:基表DML后,视图何时采用哪种方式基表进行同步
? ? ? ? ? ?on demand需要时刷新,on commit基表DML提交时刷新
? ? ? ? ? ?刷新的方法:fast 增量,complete完全刷新,force可快速刷新则fast否complete,never不刷新;借助物化视图日志是实现
增加维护成本,不一致问题等隐患,良好的结构设计不需要视图;
建议:
? ? 统一前缀v/view,不要关联太多表 数据冗余,带条件查询,不要直接更新等等
分区表
? ? ? 数据库高可用性的管理,将一个表或索引分解为多个更小/可管理的部分;并不是所有引擎都支持分区,mysql5.1不支持垂直分区,一个分区中有数据和索引(局部分区)
- range 行数据基于给定连续区间的列值放入分区,mysql5.5,partition * values less then ();支持子分区
- list,和上类似,离散的值,mysql5.5;partition * values in (),插入多行遇到未定义,myIsam部分成功,mysql视为一个事务,全部失败;支持子分区
- hash,自定义的函数表达式返回值(不能为负)
- key,据数据库的函数
- columns,直接使用非整型数据进行分区,不支持blob/text
存在主键/唯一索引,分区列必须是唯一索引的组成部分,无主键唯一索引科指定任一列为分区列

null值:mysql数据库分区视null小于任何非null值
? range自动将该值放大最左分区
? list分区显式指出哪个分区放null
? hash和key:分区函数将null值返回0
OLTP在线事务处理,电子商务网络游戏,不一定合适分区,加大B+树查询次数
OLAP在线分析处理,数据仓库数据集市,分区提高查询性能
交换数据
alter table * exchange partition,分区数据可与非分区的表进行交换
? ?相同表结构,表数据符合分区定义,不能有外键,auto_increment被重置
? ??
? ? ??
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!