k8s实操
2023-12-17 18:41:35
问题一 开通了vpc 但是仍然无法ping 通
需要安全组放行icmp

问题二 实际安装过程中每个节点需要提前安装 conntrack socat

更新apt
apt-get update
安装需要的
apt install -y conntrack && apt install -y socat
一定要先删除失败的

出现这个问题有可能是没有删除之前失败的集群 以及ip 配置不正确 配置文件中均为内网ip 即可
我部署时的配置文件
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: sample
spec:
hosts:
- {name: node1, address: 192.168.0.196, internalAddress: 192.168.0.196, user: root, password: "jz125606."}
- {name: node2, address: 192.168.0.197, internalAddress: 192.168.0.197, user: root, password: "jz125606."}
- {name: node3, address: 192.168.0.198, internalAddress: 192.168.0.198, user: root, password: "jz125606."}
roleGroups:
etcd:
- node1
control-plane:
- node1
worker:
- node1
- node2
- node3
controlPlaneEndpoint:
## Internal loadbalancer for apiservers
internalLoadbalancer: haproxy
domain: lb.kubesphere.local
address: ""
port: 6443
kubernetes:
version: v1.23.8
clusterName: cluster.local
autoRenewCerts: true
containerManager: docker
etcd:
type: kubekey
network:
plugin: calico
kubePodsCIDR: 10.233.64.0/18
kubeServiceCIDR: 10.233.0.0/18
## multus support. https://github.com/k8snetworkplumbingwg/multus-cni
multusCNI:
enabled: false
registry:
privateRegistry: ""
namespaceOverride: ""
registryMirrors: []
insecureRegistries: []
addons: []
---
apiVersion: installer.kubesphere.io/v1alpha1
kind: ClusterConfiguration
metadata:
name: ks-installer
namespace: kubesphere-system
labels:
version: v3.2.0
spec:
persistence:
storageClass: ""
authentication:
jwtSecret: ""
zone: ""
local_registry: ""
# dev_tag: ""
etcd:
monitoring: false
endpointIps: localhost
port: 2379
tlsEnable: true
common:
core:
console:
enableMultiLogin: true
port: 30880
type: NodePort
# apiserver:
# resources: {}
# controllerManager:
# resources: {}
redis:
enabled: false
volumeSize: 2Gi
openldap:
enabled: false
volumeSize: 2Gi
minio:
volumeSize: 20Gi
monitoring:
# type: external
endpoint: http://prometheus-operated.kubesphere-monitoring-system.svc:9090
GPUMonitoring:
enabled: false
gpu:
kinds:
- resourceName: "nvidia.com/gpu"
resourceType: "GPU"
default: true
es:
# master:
# volumeSize: 4Gi
# replicas: 1
# resources: {}
# data:
# volumeSize: 20Gi
# replicas: 1
# resources: {}
logMaxAge: 7
elkPrefix: logstash
basicAuth:
enabled: false
username: ""
password: ""
externalElasticsearchUrl: ""
externalElasticsearchPort: ""
alerting:
enabled: false
# thanosruler:
# replicas: 1
# resources: {}
auditing:
enabled: false
# operator:
# resources: {}
# webhook:
# resources: {}
devops:
enabled: true
jenkinsMemoryLim: 2Gi
jenkinsMemoryReq: 1500Mi
jenkinsVolumeSize: 8Gi
jenkinsJavaOpts_Xms: 512m
jenkinsJavaOpts_Xmx: 512m
jenkinsJavaOpts_MaxRAM: 2g
events:
enabled: false
# operator:
# resources: {}
# exporter:
# resources: {}
# ruler:
# enabled: true
# replicas: 2
# resources: {}
logging:
enabled: false
containerruntime: docker
logsidecar:
enabled: true
replicas: 2
# resources: {}
metrics_server:
enabled: false
monitoring:
storageClass: ""
# kube_rbac_proxy:
# resources: {}
# kube_state_metrics:
# resources: {}
# prometheus:
# replicas: 1
# volumeSize: 20Gi
# resources: {}
# operator:
# resources: {}
# adapter:
# resources: {}
# node_exporter:
# resources: {}
# alertmanager:
# replicas: 1
# resources: {}
# notification_manager:
# resources: {}
# operator:
# resources: {}
# proxy:
# resources: {}
gpu:
nvidia_dcgm_exporter:
enabled: false
# resources: {}
multicluster:
clusterRole: none
network:
networkpolicy:
enabled: false
ippool:
type: none
topology:
type: none
openpitrix:
store:
enabled: false
servicemesh:
enabled: false
kubeedge:
enabled: false
cloudCore:
nodeSelector: {"node-role.kubernetes.io/worker": ""}
tolerations: []
cloudhubPort: "10000"
cloudhubQuicPort: "10001"
cloudhubHttpsPort: "10002"
cloudstreamPort: "10003"
tunnelPort: "10004"
cloudHub:
advertiseAddress:
- ""
nodeLimit: "100"
service:
cloudhubNodePort: "30000"
cloudhubQuicNodePort: "30001"
cloudhubHttpsNodePort: "30002"
cloudstreamNodePort: "30003"
tunnelNodePort: "30004"
edgeWatcher:
nodeSelector: {"node-role.kubernetes.io/worker": ""}
tolerations: []
edgeWatcherAgent:
nodeSelector: {"node-role.kubernetes.io/worker": ""}
tolerations: []
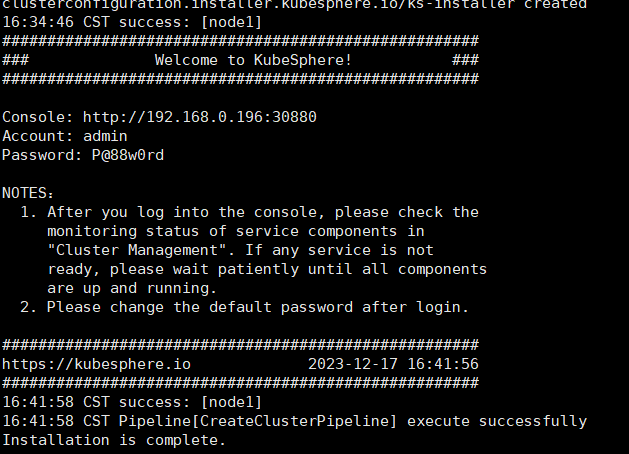
再次安装 一下等待即可

成功部署
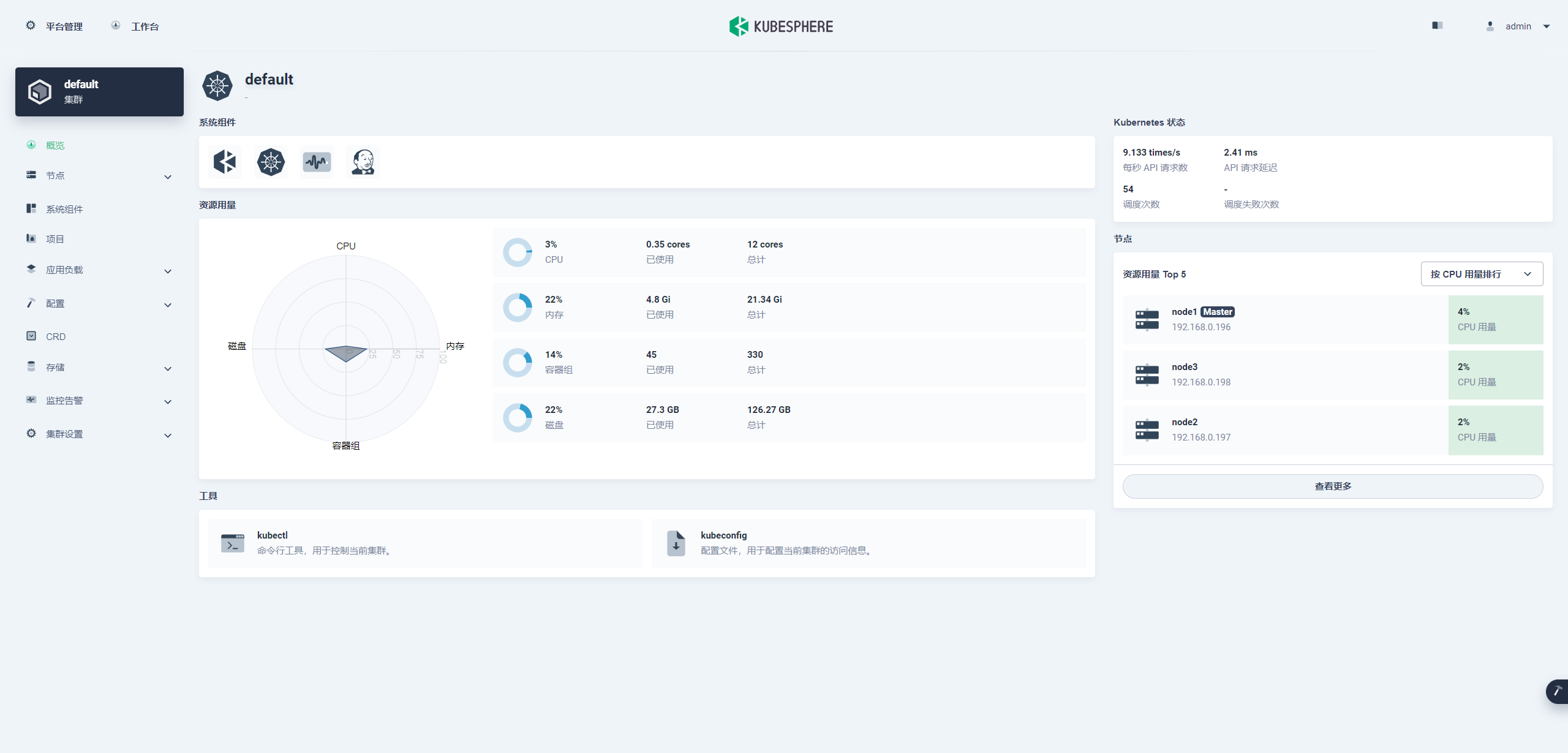
查看集群状态


由于我部署了 devops 所以也有jenkins

创建命名空间

创建nginx 工作负载 pod
创建服务 记得在阿里云端口放行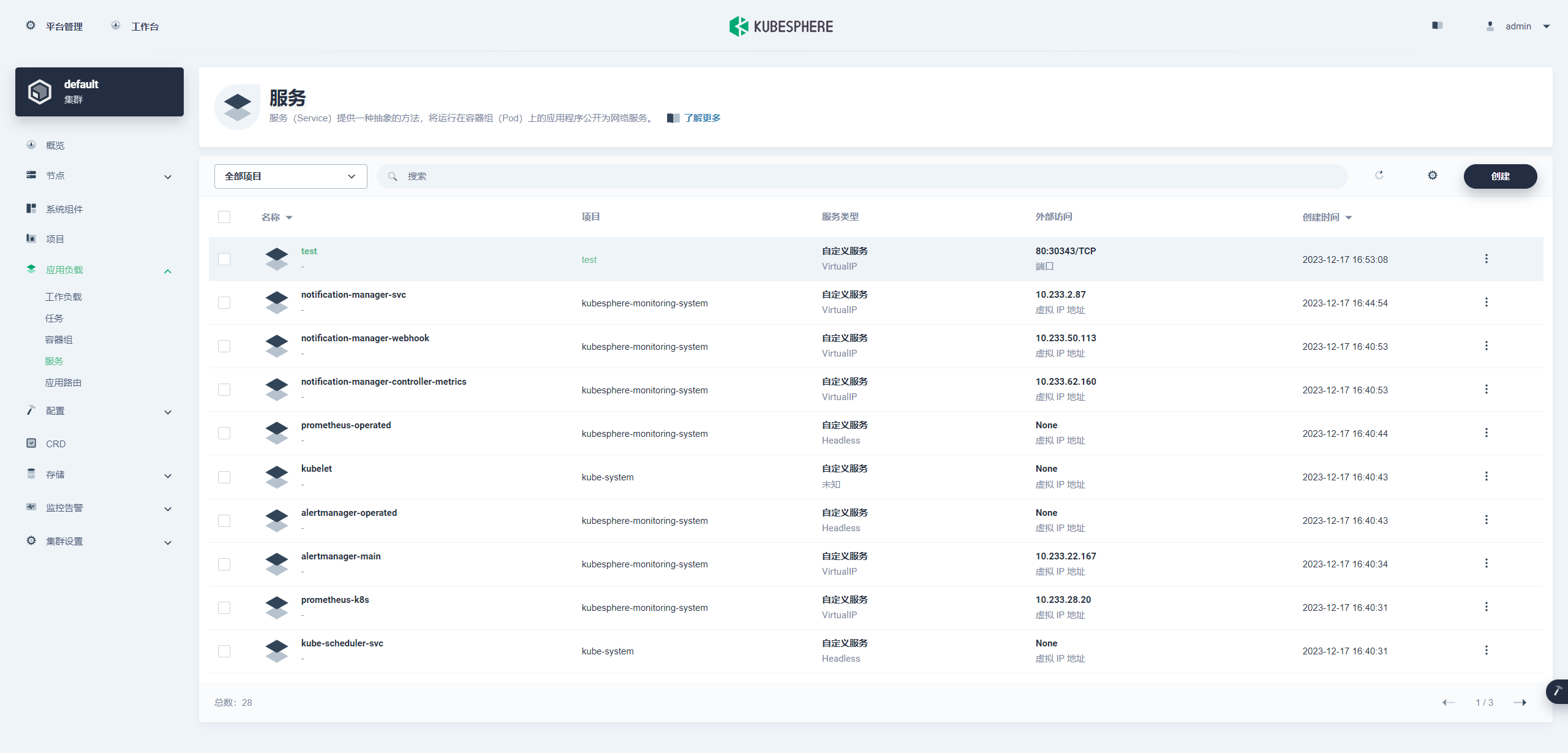
修改宿主机密码后
test.yaml 配置文件的对应节点密码修改即可 仍可使用
作者声明
如有问题,欢迎指正!
文章来源:https://blog.csdn.net/weixin_45247019/article/details/135045928
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!