一语道破爬虫,来揭开爬虫面纱
目录
一、爬虫(网络蜘蛛(Spider))
1.1、是什么:
网络蜘蛛:互联网是张网,可以在网上走来走去
网络爬虫就是自动的从网络上获取数据的程序【模拟客户端浏览器】
1.2、学习的原因
好吃:有数据才能进行数据分析【大数据分析】
能从网络上爬取什么:浏览网站时所能看见的数据都可以通过爬虫程序保存下来、文字、图片、视频/音频
1.3、用在地方:
数据展示----------将爬取的数据展示到网页或者APP上,比如:百度新闻、今日头条,
数据分析-----------从数据中寻找一些规律,比如:慢慢买(价格对比)、TIOBE排行等
1.4、是否合法:
网络爬虫的约束---------Robots协议、约束网络爬虫程序的速度(一秒发出一千个请求)
1.5、后果
要么封账号要么封ip(换ip----换电脑,网上有ip池,花钱买),严重的坐牢
案例:
爬虫禁区1:
为违法违规组织提供爬虫相关服务 (验证码识别服务贩卖SEO......)
- 知乎某极验破解者自述被抓?
- “快啊答题”AI破解验证码服务开发者被判刑
- 永嘉警方揪出“黑”百度黑客团伙 千扰搜索引擎牟利超七千万元
爬虫禁区2: 个人隐私数据抓取与贩卖
- 简历大数据公司“5达科技”被一锅端
- 社保掌上通被下架 用户的信息很容易泄露太不安全了
- 爬虫为何受关注? 业内: 大数据服务商或因合作方涉套路贷犯罪而被牵连
爬虫禁区3:利用无版权的商业数据获利
- “车来了”涉嫌偷数据被警方立案
- 裁判文书网数据竟被售卖: 爬虫程序抓取 或成侵权
二、应用领域
2.1、区分Python与爬虫
Python 不是爬虫,而是一种编程语言。然而,Python 在爬虫领域中有着广泛的应用。许多人选择使用 Python 来编写网络爬虫,因为它有许多强大的库和工具,如 Requests、Beautiful Soup、Scrapy 等,可以帮助开发者轻松地编写和管理爬虫程序。
因此,虽然 Python 本身不是爬虫,但它是一种非常适合用于编写爬虫的编程语言,可以帮助开发者快速、高效地创建各种类型的网络爬虫。
Python
是一种功能强大且灵活的编程语言,因此在各种领域都有广泛的应用。以下是 Python 的一些主要应用领域:
1. Web 开发:Python 可以用于开发 Web 应用程序和网站,常用的 Web 框架包括 Django 和 Flask。
2. 数据科学和机器学习:Python 在数据科学和机器学习领域非常流行,因为有许多强大的库和工具,如 NumPy、Pandas、SciPy、scikit-learn 和 TensorFlow。
3. 自动化和脚本编写:Python 可以用于编写自动化脚本,包括系统管理、文件操作、数据处理等。
4. 科学计算和工程:Python 在科学计算和工程领域有广泛的应用,因为它可以处理复杂的数学计算和科学建模。
5. 游戏开发:Python 可以用于开发游戏,有一些流行的游戏引擎如 Pygame 和 Panda3D。
6. 网络编程:Python 在网络编程方面有着良好的支持,可以用于开发网络应用和服务器端程序。
7. 数据库:Python 有许多库可以用于与各种数据库进行交互,如 MySQL、PostgreSQL 和 MongoDB。
8. GUI 应用程序:Python 可以用于开发图形用户界面(GUI)应用程序,如使用 Tkinter、PyQt 和 wxPython 等库。
总的来说,Python 在各种领域都有广泛的应用,因此是一种非常流行的编程语言。
爬虫:
1. 搜索引擎:爬虫被用于搜索引擎的抓取和索引网页内容,以便用户可以通过搜索引擎找到相关的信息。
2. 数据挖掘:爬虫可以用于从网页上抓取大量的数据,然后进行分析和挖掘,以发现有用的信息和趋势。
3. 价格比较和商品信息收集:爬虫可以用于抓取不同网站上的商品信息和价格,以便用户可以比较不同产品的价格和特性。
4. 网络安全:爬虫可以用于发现和分析网站上的安全漏洞和恶意软件,以帮助提升网络安全。
5. 社交媒体分析:爬虫可以用于抓取社交媒体上的信息和数据,以进行用户行为分析和趋势预测。
6. 舆情监控:爬虫可以用于监控新闻网站、论坛和社交媒体上的舆情信息,以帮助政府和企业了解公众舆论。
7. 金融市场分析:爬虫可以用于抓取金融市场上的数据和信息,以进行趋势分析和预测。
8. 学术研究:爬虫可以用于抓取学术文献和研究成果,以帮助研究人员进行文献综述和数据分析。
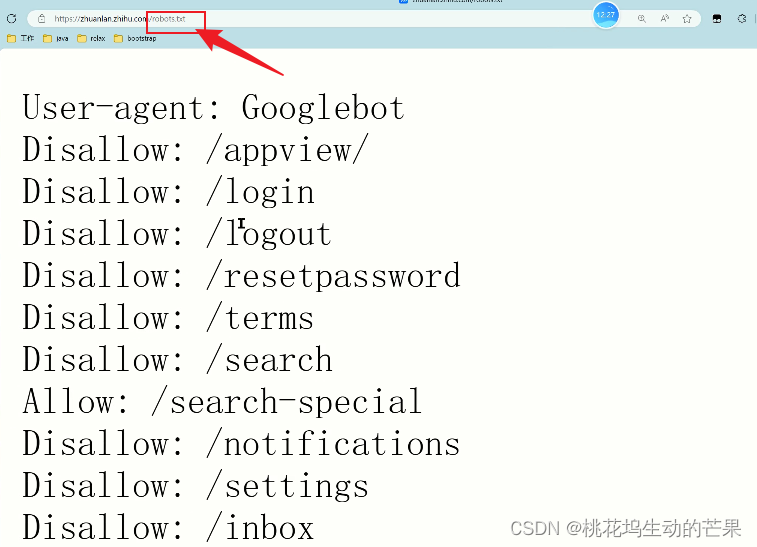
三、Robots协议
是网站管理和网络爬虫开发者之间的一种合作方式/君子协议(说白了就是给你看的,网站自己会做反爬手段),有效地管理网络爬虫对网站的访问,保护网站内容的安全性和合法性。
在网站后面加/robots.txt就可以看见那些可以爬那些不可以爬
Disallow:禁止爬
Allow:允许爬
四、抓包
抓包(Packet Capture)是指通过软件工具捕获和分析计算机网络中传输的数据包。抓包通常用于网络分析、安全审计、故障排除和网络性能优化等目的。
简单说明:电脑当前连了网,我们要和另外一台电脑通讯,通讯过程中发送的数据,是以包来发送的
4.1、浏览器抓包
右键---->检查(快捷键:F12)


4.2、抓包工具
可以截取经过计算机网络接口的数据包,并将其保存到文件中供后续分析。这些数据包可以包含从源到目的地的所有通信内容,包括通信双方的IP地址、端口号、协议类型、数据内容等信息。通过分析这些数据包,可以深入了解网络通信的细节,发现潜在的安全问题、网络瓶颈或者通信异常。
抓包工具通常可以在本地计算机上运行,也可以在网络设备上运行。
常见的抓包工具:
Wireshark、tcpdump、Fiddler、Charles等。这些工具提供了丰富的功能,可以对抓取到的数据包进行过滤、分析和可视化展示,帮助网络管理员和安全专家进行网络监控和问题排查。
伪基站就假的网络
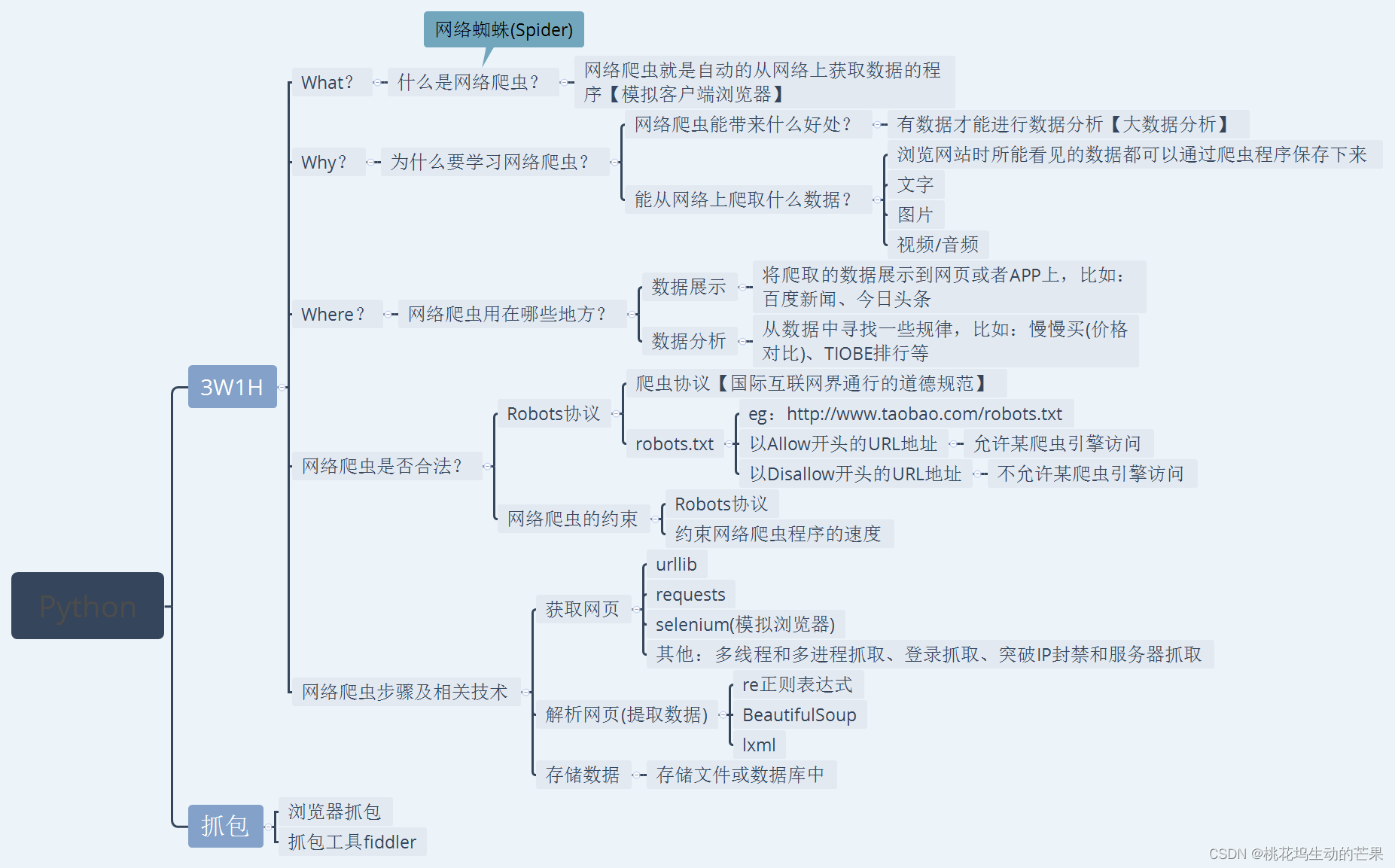
五、思维导图总结
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!