Text2SQL学习整理(三)SQLNet与TypeSQL模型
导语
上篇博客:Text2SQL学习整理(二):WikiSQL数据集介绍简要介绍了WikiSQL数据集的一些统计特性和数据集特点,同时简要概括了该数据集上一个baseline:seq2sql模型。本文将介绍seq2SQL模型后一个比较知名的模型SQLNet。
Sqlnet: Generating structured queries from natural language without reinforcement learning
SQLNet简介
SQLNet模型是紧随WIkiSQL数据集之后的一个比较知名的Baseline。由于WikiSQL数据集中的SQL比较简单,如下图所示为一个WIkiSQL中的示例,因而SQLNet将预测一个SQL语句转换为预测构成SQL语句的六部分任务分别解决。

如下图所示,SQLNet将WikiSQL中的SQL语句分为以下几个部分:包括SELECT后的聚合符、使用的column、WHERE子句后的column、操作符OP以及VALUE等。
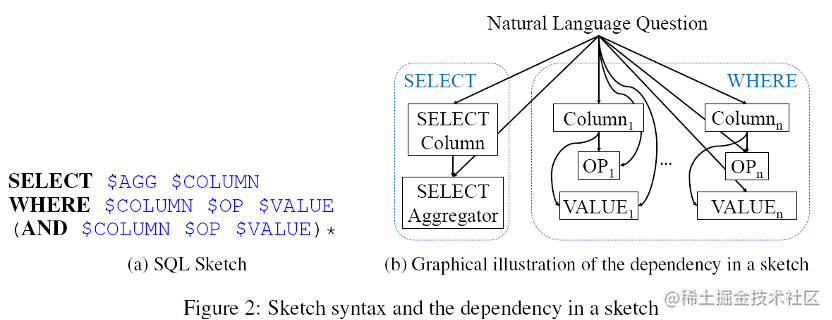
SQLNet模型
SQLNet使用slot filling的思想,引入了一个sketch(即上图所示的模板),申明需要预测的所有slot。
在SQLNet中,一共有以下六个模块需要预测:
- SELECT_COL(主句中填哪一个列名)
- AGG(主句中使用哪一个聚合函数)
- #COND(WHERE子句的条件数量)
- COND_COL(某个WHERE子句的条件为哪个column)
- OP(某个WHERE子句的条件使用哪个运算符,如><=)
- COND_VAL(某个WHERE子句的条件值)
通过这样建模,Text2SQL任务转换为分别填充模板中的各个slot的任务。
在预测时,各个slot之间值的预测其实有依赖关系,比如预测WHERE子句时要预测的OP和VALUE其实高度依赖于WHERE子句中column的预测。因此,在预测时,SQLNet充分利用了依存关系图,预测某个slot的时只用与当前token预测相关的信息(模块)。
技巧
SQLNet中有两个重要的技巧:seq2set和column attention。其简要概况如下:
- Seq2set:WHERE语句会包含有不同条件,多是并列关系,顺序不影响结果,问题转换为“预测WHERE语句中应该包含哪些columns”。
- Column attention:对于特定column的预测,Question中不同部分起到的作用是不一样的,引入Attention机制来表示这种关联关系。即使用Question对每个column做一个attention。
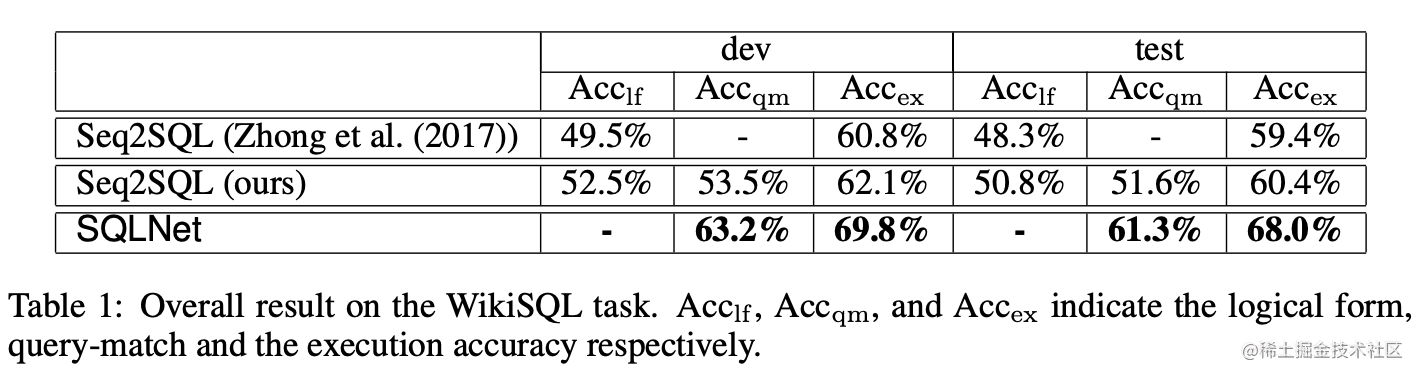
结果
通过这些技巧的引入,SQLNet在该数据集上相比seq2sql取得了巨大提升,取得了当时的SOTA。
TypeSQL: Knowledge-based Type-Aware Neural Text-to-SQL Generation
TypeSQL简介
之前的两种模型完全忽略了各个column的数据类型,但数据类型其实是一个很重要的信息,比如在预测WHERE子句时,只有数值类型的column才可以比较大小,字符串类型的值则不行。基于以上想法,TypeSQL充分利用了question中每个单词的类型信息(比如某个单词为列名、整数值等),并取得了新的SOTA。
类型信息的获取和利用
TypeSQL模型中的类型信息是通过将question先分词再在Freebase、table的column name和Table content之中search得到的。
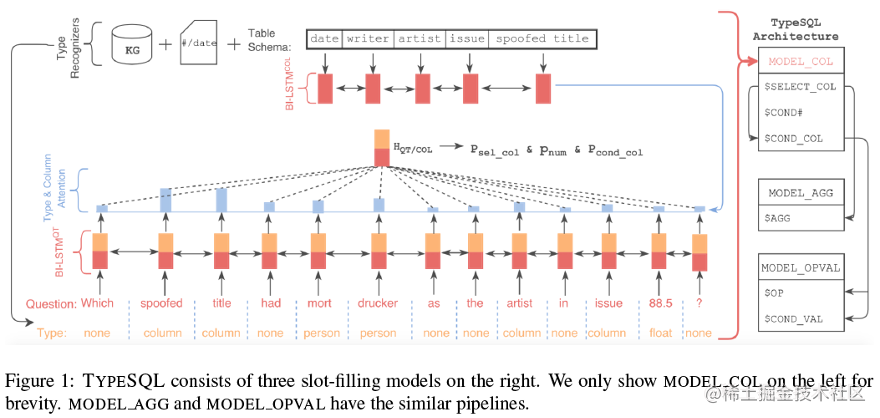
与SQL Net一样采用slot filling的思想,填充sketch的各个slot,并大幅度精简用到的BiLSTM(12->6)。 为了更好地建模文本中出现的罕见实体和数字,TypeSQL显式地赋予每个单词类型。
其类型识别过程如下:将问句分割n-gram (n取2到6),并搜索数据库表、列。对于匹配成功的部分赋值column类型赋予数字、日期四种类型:INTEGER、FLOAT、DATE、YEAR。对于命名实体,通过搜索FREEBASE,确定5种类型:PERSON,PLACE,COUNTREY,ORGANIZATION,SPORT。这五种类型包括了大部分实体类型。当可以访问数据库内容时,进一步将匹配到的实体标记为具体列名(而不只是column类型)。
模型架构
SQLNet为模版中的每一种成分(共6种)设定了单独的模型,而TypeSQL对此进行了改进,对于相似的成分,例如SELECT_COL 和COND_COL以及#COND(条件数),这些信息间有依赖关系,通过合并为单一模型,可以更好建模。TypeSQL使用3个独立模型来预测模版填充值:
- MODEL_COL:SELECT_COL,#COND,COND_COL
- MODEL_AGG:AGG
- MODEL_OPVAL:OP, COND_VAL
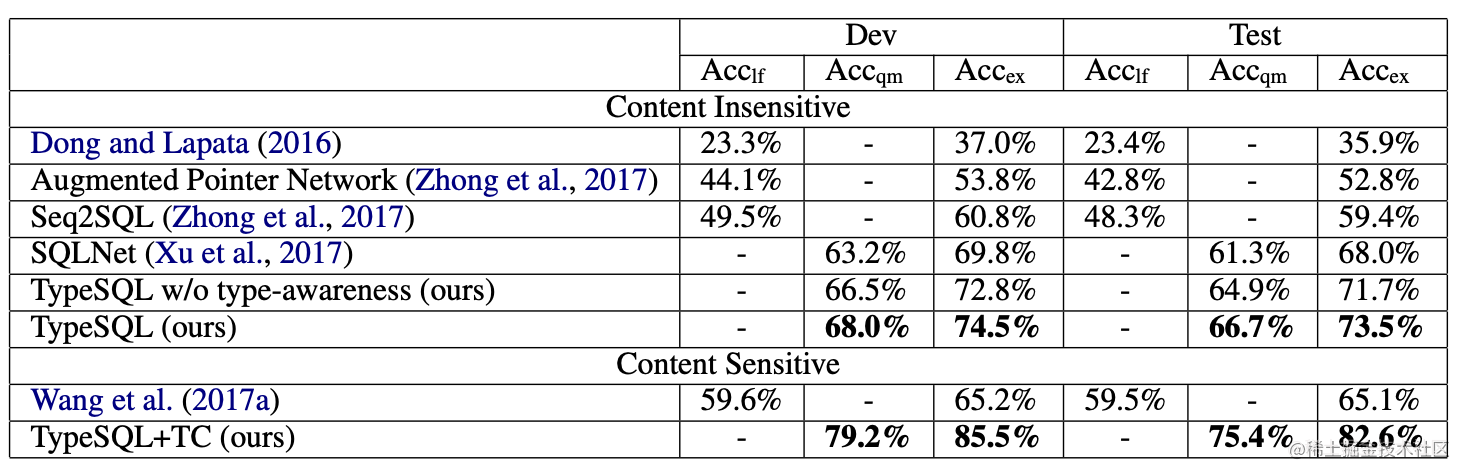
结果
实验结果如下,可以看到,TypeSQL通过对类型信息的有效利用,提升了模型性能,取得了新的SOTA。
总结
SQLNet和TypeSQL是WikiSQL提出早期两个重要的baseline。SQLNet从WikiSQL数据集SQL的特点出发,将Text2SQL任务转变为了slot filling的分割部分任务,对后续的研究产生了很大影响;而TypeSQL则抓住前人的工作中对类型信息的忽略,引入类型信息取得了新的SOTA。这也启发我们在后续工作中,要善于总结问题的特点,总结和发掘前人的疏忽和不足之处进行创新。
本篇博客介绍了WIkiSQL提出早期的一些工作,那时像BERT之类的预训练模型还未广泛应用,下一篇博客将介绍几个使用预训练模型的方法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!