Elasticsearch零基础实战
分享后可优化点(待完成)
java es8 查询如何打印查询入参 ?(直接执行的json)
es自定义分词器 如何实现?
kibana 监控jvm分子分母是什么 ?
es如何 改索引结构?
修改数据原理
分享前罗列大纲,挑出重点
分享时需要讲 原理+应用场景
根据笔记总结分享文档,代码截图等 (不要直接拿笔记出来讲)
任务目标
- 基础语法学习
- 从es6.8迁移至7.1
- 从es6.8迁移至8.7.0
- 相关java api升级(从spring boot 封住的es框架到原生es)
- 业务操作:订单历史数据从mysql迁移至es
- 断路器配置
- 监控器配置
- 快照配置
windows本地环境搭建(http)
下载es
es集群搭建
解压一个es8.7的zip,然后复制三份,像这样

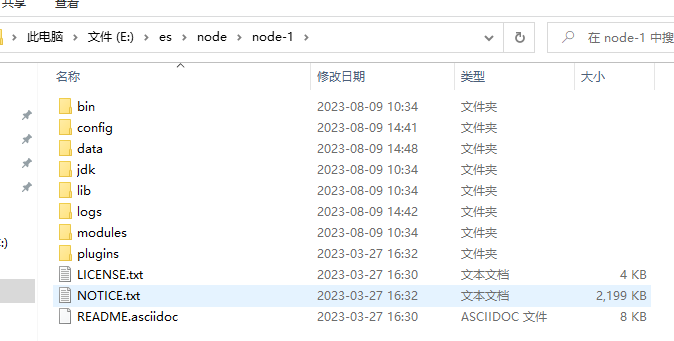
然后对config下的 elasticsearch.yml 分别进行设置
#节点 1 的配置信息:
# ---------------------------------- Cluster -----------------------------------
# 集群名称,节点之间要保持一致
cluster.name: my-application
# ------------------------------------ Node ------------------------------------
# 节点名称,集群内要唯一
node.name: node-1
# 节点角色 [主节点、数据节点]:注意这一点同7.x版本的区别配置
node.roles: [master,data]
# ---------------------------------- Network -----------------------------------
# 发布ip
network.host: localhost
# http 端口
http.port: 9200
# tcp 监听端口:注意这一点同7.x版本的区别配置
transport.port: 9301
# --------------------------------- Discovery ----------------------------------
# 初始主节点
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
# ---------------------------------- Various -----------------------------------
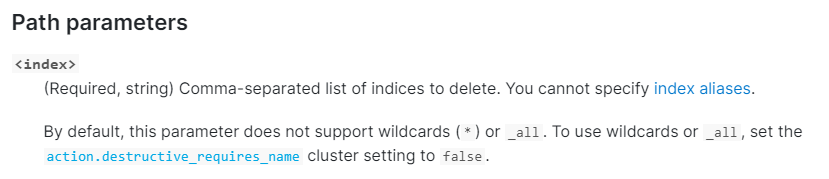
# 删除索引是否需要指定索引全名(false就是可以用正则)
#action.destructive_requires_name: false
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
# 节点 2 的配置信息:
# ---------------------------------- Cluster -----------------------------------
# 集群名称,节点之间要保持一致
cluster.name: my-application
# ------------------------------------ Node ------------------------------------
# 节点名称,集群内要唯一
node.name: node-2
# 节点角色 [主节点、数据节点]
node.roles: [master,data]
# ---------------------------------- Network -----------------------------------
# 发布ip
network.host: localhost
# http 端口
http.port: 9201
# tcp 监听端口
transport.port: 9302
# --------------------------------- Discovery ----------------------------------
# 自动发现集群节点ip
discovery.seed_hosts: ["localhost:9301"]
# discovery.zen.fd.ping_timeout: 1m
# discovery.zen.fd.ping_retries: 5
# 集群内的可以被选为主节点的节点列表
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# ---------------------------------- Various -----------------------------------
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
#节点 3 的配置信息:
# ---------------------------------- Cluster -----------------------------------
# 集群名称,节点之间要保持一致
cluster.name: my-application
# ------------------------------------ Node ------------------------------------
# 节点名称,集群内要唯一
node.name: node-3
# 节点角色 [主节点、数据节点]
node.roles: [master,data]
# ---------------------------------- Network -----------------------------------
# 发布ip
network.host: localhost
# http 端口
http.port: 9203
# tcp 监听端口
transport.port: 9303
# --------------------------------- Discovery ----------------------------------
# 自动发现集群节点ip
discovery.seed_hosts: ["localhost:9301", "localhost:9302"]
# discovery.zen.fd.ping_timeout: 1m
# discovery.zen.fd.ping_retries: 5
# 集群内的可以被选为主节点的节点列表
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# ---------------------------------- Various -----------------------------------
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
然后一次性都启动
cd E:\es\node\node-1\bin
.\elasticsearch.bat
cd E:\es\node\node-2\bin
.\elasticsearch.bat
cd E:\es\node\node-3\bin
.\elasticsearch.bat 注意点
直接集群启动,es默认走http,
如果不配置集群,单节点,启动,es会在配置文件中添加https相关配置
问题
提示jvm内存不足
修改下内存
找到elasticsearch的安装目录,然后找到config文件夹,里面都是相关的配置文件。
官方不建议直接修改jvm.options,而是复制jvm.options到jvm.options.d目录下,再修改。
其中,jvm.options可以修改es运行时候的内存分配。打开jvm.options文件,我们可以发现默认设置的内存是4g。
我们改成2g
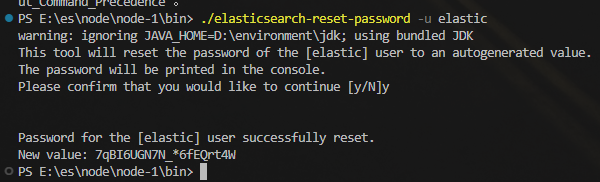
忘记密码
可能第一次启动的时候没有保存密码,在bin目录下执行命令:
# 随机密码
./elasticsearch-reset-password -u elastic注意:在某个节点执行一次即可,所有节点都会生效
参考文档
kibana启动
设置中文
在config的 kibana.yml 中新增
i18n.locale: "zh-CN"启动
由于es默认开启了security,但是我们又没配置证书,所以kibana直接启动会出错,
需要在三个es节点的配置文件添加如下配置
xpack.security.enabled: false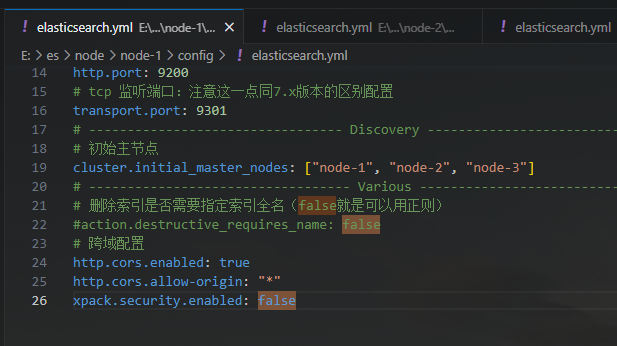
然后启动
cd E:\es\kibana-8.7.0-windows-x86_64\kibana-8.7.0\bin
.\kibana.bat
大功告成!
windows本地环境搭建(https)
es集群搭建
在http步骤上引入https,之前步骤请查看http部分
证书生成
在bin目录下执行命令,生成证书
./elasticsearch-certutil ca
./elasticsearch-certutil cert --ca elastic-stack-ca.p12然后将这两个证书文件拷贝到三个node节点的config的certs文件夹下

在配置文件中新增配置(三个节点都需要)
# 开启https协议
xpack.security.enabled: true
# 这行似乎不需要,测试环境copy过来的,先加上
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12然后重启es
kibana配置
修改 kibana_system 的密码
在node1节点的bin目录下执行
./elasticsearch-reset-password -u kibana_system修改 kibana_admin 的密码
./elasticsearch-reset-password -u kibana_admin
密码:config目录下的 kibana.yml 添加如下配置
server.port: 5601
server.host: "localhost"
server.name: "node-1"
elasticsearch.hosts: ["http://localhost:9200","http://localhost:9201","http://localhost:9203"]
elasticsearch.ssl.verificationMode: none
elasticsearch.requestTimeout: 90000
elasticsearch.username: "kibana_system"
# elasticsearch.password: "Mvwm@n12nal"
elasticsearch.password: "Ql2e3HvwXUL9QfBlb+06"然后启动,在bin目录执行
./kibana.bat在浏览器输入网址 http://localhost:5601/
使用 elastic账户登录
参考文档
linux环境搭建
略
基础语法
注意:es8的时候,已经默认不支持* 或者 _all了
查询
# 查询所有节点
GET /_cat/nodes?v
# 查询所有索引
GET /_cat/indices?v
GET /_cat/indices?v&h=health,status,index
# 获取所有的索引mapping信息
GET _all/_mapping
#获取当前索引信息
GET /community_encyclopedia
GET /community_encyclopedia/_settings
GET /community_encyclopedia/_mapping
# 查询当前索引总数
GET /community_encyclopedia/_count
# 查询当前索引数据
GET /community_encyclopedia/_search
# 查询当前索引单条数据
GET /community_encyclopedia/_doc/100
#只获取字段name,age
GET /bamboo/_doc/1?_source=name,age
#查询参数
GET /community_encyclopedia/_search
{
"query":{
"bool":{
"must":[
{
"match_phrase": {
"type":1
}
},{
"match_phrase": {
"status":1
}
}
]
}
},
"sort":[
{
"normalIndex":"asc"
},
{
"createTime.keyword":"desc"
}
]
}
# 范围查询
#查询参数
GET /t_car_order/_search
{
"query":{
"range": {
"create_time": {
"gte": "2017-07-24T21:26:21.000Z",
"lte": "2017-07-25T00:26:21.000Z"
}
}
}
}
# 聚集查询 id为1,2的数据
GET /bamboo/_doc/_mget
{
"docs":[
{
"_id": 2
},
{
"_id": 1
}
]
}
GET /bamboo/_doc/_search
{"query":{"bool":{"must":[{"match_all":{}}],"must_not":[],"should":[]}},"from":0,"size":10,"sort":[],"aggs":{}}
# 模糊查询
GET /community_encyclopedia/_search
{
"query":{
"bool": {
"must": [
{"wildcard": {"managerQuestion.keyword": "*汽车保险包括*"}}
]
}
}
}
# 多条件查询
GET /t_car_policy/_search
{
"query":{
"bool":{
"must":[
{
"match": {
"orderNo":"DCARRxFyaf000060147"
}
},{
"match": {
"appPolicyNo":"0106003202023026408"
}
}
],
"filter": [
{
"range": {
"createTime": {
"lt": "2023-10-23 00:00:00"
}
}
}
]
}
}
}
上面的语法中,filter不参与评分,也可以直接放在must中:
GET /t_car_policy/_search
{
"query":{
"bool":{
"must":[
{
"match": {
"orderNo":"DCARRxFyaf000060147"
}
},
{
"match": {
"appPolicyNo":"0106003202023026408"
}
},
{
"range": {
"createTime": {
"lt": "2023-10-23 00:00:00"
}
}
}
]
}
}
}
以上是匹配查询,更建议使用 .keyword 精确查询
#查询参数
GET /t_car_policy/_search
{
"query":{
"bool":{
"must":[
{
"term": {
"orderNo.keyword":"DCARRxFyaf000060147"
}
},
{
"term": {
"appPolicyNo.keyword":"0106003202023026408"
}
},
{
"range": {
"createTime": {
"lt": "2023-10-23 00:00:00"
}
}
}
]
}
}
}删除
# 删除所有索引
# DELETE /_all
# 删除部分索引
# DELETE /test-*
# 删除单个索引
# DELETE /bamboo
# 删除某条数据
# DELETE /bamboo/_doc/1创建
# 创建空索引
PUT /bamboo
# 创建索引和对应的mapping和setting
PUT /bamboo
{
"mappings": {
"properties": {
"title": { "type": "text" },
"name": { "type": "text" },
"age": { "type": "integer" },
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
},
"settings":{
"index":{
"number_of_shards": 5,
"number_of_replicas": 1
}
}
}
#添加一条数据
PUT /bamboo/_doc/1
{
"name":"zs",
"title":"张三",
"age":18,
"created":"2018-12-25"
}
# 修改一条数据的某个属性值
PUT /bamboo/_doc/1
{
"name":"lxs",
"title":"李小四"
}
# 批量插入多个document,_id不指定则系统生成字符串
POST /bamboo/_doc/_bulk
{"index":{"_id":2}}
{"name":"ww","title":"王五","age":18,"created":"2018-12-27"}
{"index":{}}
{"name":"zl","title":"赵六","age":25,"created":"2018-12-27"}
# 批量操作(包含修改和删除)
POST /bamboo/_doc/_bulk
{"update":{"_id":"1"}}
{"doc":{"title":"王小五"}}
{"delete":{"_id":"2"}}
参考链接:语法
es8语法
must, filter, should, must_not, constant_score的区别
and or
should:其查询子句应该被满足,也就是不一定都满足,逻辑相当于 or。
must:其查询子句必须全部被满足,逻辑相当于 and ,并且会计算分数。
filter:与 must 作用一样,但是不会计算分数。在 filter context 下的查询子句不会计算分数且会被缓存。
must_not:其查询子句必须都不被满足。当子句是在 filter context 下时,不会计算分数且会被缓存。
参考文档:
Elasticsearch 中 must, filter, should, must_not, constant_score 的区别
原理解析
查询es的某个索引,原理是怎样的?
引用一段话:
被混淆的概念是,一个 Lucene 索引我们在 Elasticsearch 称作分片 。 而在Elasticsearch中索引是分片的集合。 当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引),然后合并每个分片的结果到一个全局的结果集。
总结来说,查询某个索引时,会根据查询算法定位到某些分片,进而缩小查询范围,提高查询效率
7.*中为什么现在要移除type?
- 和数据库的库-表类比是错误的,因为es中同一个index中不同type是存储在同一个索引中的(lucene的索引文件),因此不同type中相同名字的字段的定义(mapping)必须一致。
- 当您想要索引一个deleted字段在不同的type中数据类型不一样。一个类型中为日期字段,另外一个类型中为布尔字段时,这可能会导致ES的存储失败,因为这影响了ES的初衷设计。
- 另外,在一个index中建立很多实体,type,没有相同的字段,会导致数据稀疏,最终结果是干扰了Lucene有效压缩文档的能力,说白了就是影响ES的存储、检索效率。
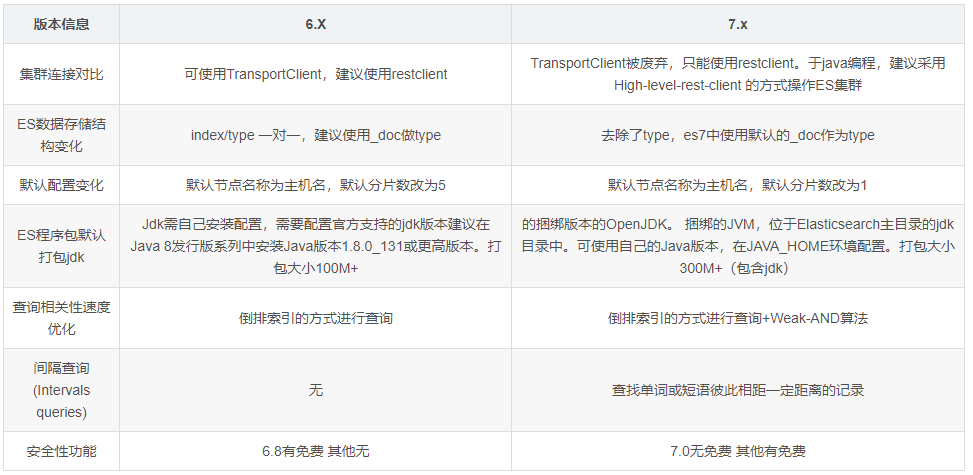
es6.x和7.x对比
如何分片, 几个节点?
节点数<=主分片数*(副本数)3个节点,3个主分片,1个副本数
可以简单设置成节点个数的倍数,以便在节点之间均匀分布数据
后续的高级操作可以考虑根据索引内容进行分片,比如根据时间进行分片等。
萌新发问
logging:
config: classpath:logback-spring.xml
elasticsearch:
# 多个IP逗号隔开
hosts: 10.7.176.72:9200,10.7.176.73:9200,10.7.176.74:9200
username: elastic
password: Mvwm@n12nalprivate void createIndexDetail(String indexName) throws IOException {
// 3.创建索引
CreateIndexResponse response = elasticsearchClient
.indices()
.create(c -> c
.index(indexName)
.settings(sBuilder -> sBuilder
.index(iBuilder -> iBuilder
// 5?个分片
.numberOfShards("5")
// 一个副本
.numberOfReplicas("1")))
.mappings(mBuilder -> mBuilder
.properties(OrderDetail.ORDER_NO, pBuilder -> pBuilder.keyword(keywordPropertyBuilder -> keywordPropertyBuilder.ignoreAbove(30)))
.properties(OrderDetail.MESSAGE, pBuilder -> pBuilder.text(textPropertyBuilder -> textPropertyBuilder.analyzer("ik_max_word").searchAnalyzer("ik_smart")))
)
);
log.info("createIndexDetail方法,acknowledged={}", response.acknowledged());
}这是我在springboot中对es8集群的配置,我想知道当我创建一个索引时,是三个hosts节点都会有我的索引吗?
5个分片,每个分片一个副本分片,所以也有5个副本分片,同一个主分片和副本分片不会在一台host节点上,然后集群会将这些分片打散分布在集群中。
加入我往这个索引中插入100条数据,数据大概是如何分布的呢
假如我往这个索引中插入100条数据,数据大概是如何分布的呢?
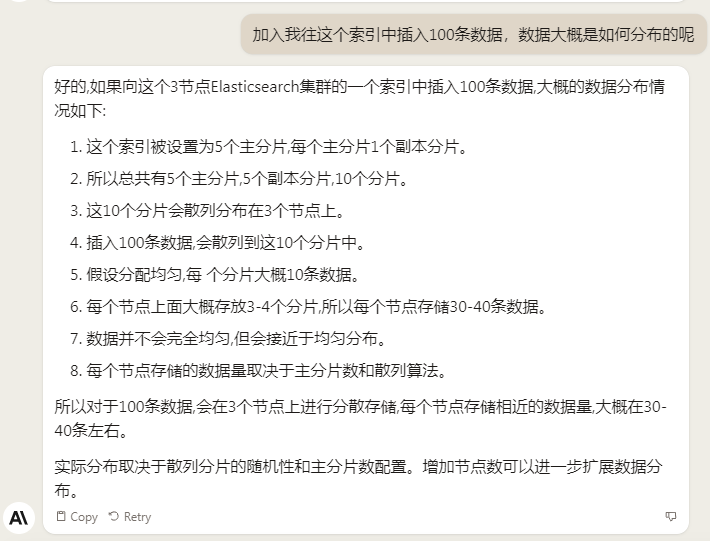
大概意思就是说,100条数据在5个主分片上,相当于存放在mysql表中,只是这个表的数据不在一个磁盘上
然后100备份数据放在副本分片上。 相当于主从mysql库
java代码升级
es6.8升级到es7.1.1
采用方式:spring Data Elasticsearch 方式
因为当前springboot版本支持7.1.1,所以采用此方式
版本对应
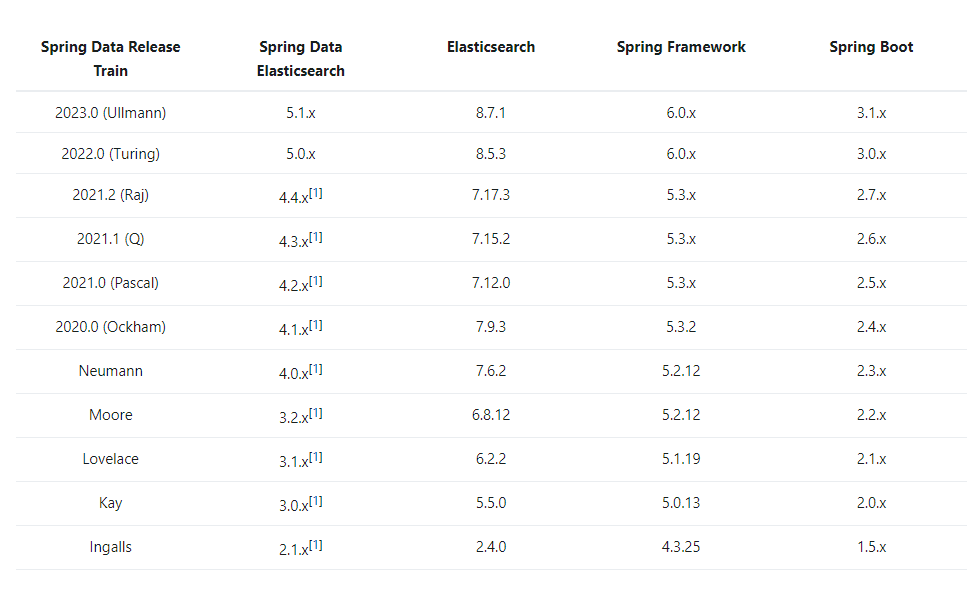
由于集团使用的是es7.1.1版本,所以我们对应使用spring Data Elasticsearch 4.0.x
相关api
QueryBuilders.matchQuery():全文查询的参数,会进行分词操作
QueryBuilders.termQuery():精确查询的参数
参考文档
es6.8升级到es8.7.0
采用方式:es8.7原生spi
由于升级spring boot成本过大,为了和其他微服务的spring boot版本保持一致,故采用此方式
参考文档:
Elasticsearch Java API Client官方文档
Springboot整合ES8(Java API Client)
springboo整合elasticSearch8 java client api
接口示例:
package com.djbx.dh.search.controller.dhwiki;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch._types.FieldSort;
import co.elastic.clients.elasticsearch._types.SortOptions;
import co.elastic.clients.elasticsearch._types.SortOrder;
import co.elastic.clients.elasticsearch._types.query_dsl.BoolQuery;
import co.elastic.clients.elasticsearch._types.query_dsl.QueryBuilders;
import co.elastic.clients.elasticsearch._types.query_dsl.TermQuery;
import co.elastic.clients.elasticsearch._types.query_dsl.WildcardQuery;
import co.elastic.clients.elasticsearch.core.GetResponse;
import co.elastic.clients.elasticsearch.core.SearchResponse;
import co.elastic.clients.elasticsearch.core.search.Hit;
import co.elastic.clients.elasticsearch.indices.CreateIndexResponse;
import com.alibaba.nacos.client.naming.utils.CollectionUtils;
import com.djbx.dh.common.exception.BusinessException;
import com.djbx.dh.common.model.po.ResultCode;
import com.djbx.dh.common.model.vo.ResultEntity;
import com.djbx.dh.search.common.constants.CommonConstants;
import com.djbx.dh.search.common.enums.ValidOrInvalidEnum;
import com.djbx.dh.search.common.enums.YesOrNoEnum;
import com.djbx.dh.search.common.util.UUIDUtil;
import com.djbx.dh.search.entity.dto.IdDTO;
import com.djbx.dh.search.entity.dto.dhwiki.CommunityEncyclopediaQuestionAnswerDTO;
import com.djbx.dh.search.entity.dto.dhwiki.ProductLibraryDTO;
import com.djbx.dh.search.entity.dto.dhwiki.QuestionAnswerUpdateDTO;
import com.djbx.dh.search.entity.po.dhwiki.CommunityEncyclopediaQuestionAnswer;
import com.djbx.dh.search.entity.po.dhwiki.CommunityEncyclopediaQuestionCategory;
import com.djbx.dh.search.entity.vo.dhwiki.CommunityEncyclopediaQuestionAnswerVO;
import com.djbx.dh.search.service.dhwiki.CommunityEncyclopediaQuestionCategoryService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.stream.Collectors;
/**
* @author DJ033979
*/
@Slf4j
@RestController
@RequestMapping("/encyclopedia")
@Api(tags = "搭伙百科")
public class CommunityEncyclopediaController {
@Resource
private CommunityEncyclopediaQuestionCategoryService communityEncyclopediaQuestionCategoryService;
@Resource
private ElasticsearchClient elasticsearchClient;
/**
* 保存数据
*
* @param questionAnswer 问答数据
* @return ResultEntity
*/
@PostMapping("/saveOrUpdate")
@ApiOperation(value = "问答数据保存OR更新")
public ResultEntity<?> saveOrUpdate(@RequestBody CommunityEncyclopediaQuestionAnswer questionAnswer) throws BusinessException, IOException {
//前置校验,判断索引是否存在
if (!elasticsearchClient.indices().exists(e -> e.index(CommonConstants.WIKI_INDEX)).value()) {
// 创建索引
createIndexDetail();
}
// 置顶或推荐判断排序值是否可用
if (YesOrNoEnum.isYes(questionAnswer.getIsCategoryTop()) && findValidOneByTypeAndStatusAndCategoryAndTopIndex(
ValidOrInvalidEnum.VALID.getValue(), YesOrNoEnum.YES.getValue(), questionAnswer.getCategory(), questionAnswer.getTopIndex())) {
log.error("有效的置顶顺序被占用,不能使用");
return ResultEntity.error("有效的置顶顺序被占用,不能使用");
}
if (YesOrNoEnum.isYes(questionAnswer.getIsHotRecommendTop()) && findValidOneByTypeAndStatusAndCategoryAndTopIndex(
ValidOrInvalidEnum.VALID.getValue(), YesOrNoEnum.YES.getValue(), questionAnswer.getCategory(), questionAnswer.getTopIndex())) {
log.error("有效的推荐顺序被占用,不能使用");
return ResultEntity.error("有效的推荐顺序被占用,不能使用");
}
// 此字段用于管理后台like查询
questionAnswer.setManagerQuestion(questionAnswer.getQuestion());
// 保存
if (StringUtils.isBlank(questionAnswer.getId())) {
//设置创建时间
questionAnswer.setId(UUIDUtil.uuid());
questionAnswer.setType(YesOrNoEnum.YES.getValue());
questionAnswer.setCreateTime(new Date());
} else {// 更新
// 根据id获取es的数据
CommunityEncyclopediaQuestionAnswer encyclopediaQuestionAnswer = getCommunityEncyclopediaQuestionAnswerById(questionAnswer.getId());
// 设置更新数据
questionAnswer.setCreateTime(encyclopediaQuestionAnswer.getCreateTime());
questionAnswer.setType(encyclopediaQuestionAnswer.getType());
questionAnswer.setUpdateTime(new Date());
}
try {
elasticsearchClient.index(s ->
s.index(CommonConstants.WIKI_INDEX)
.id(questionAnswer.getId())
.document(questionAnswer)
);
} catch (Exception e) {
log.error("问答数据保存OR更新至ES报错:{}", e.getMessage());
return ResultEntity.error("问答数据保存OR更新至ES报错");
}
return ResultEntity.success("问答数据保存OR更新至ES成功");
}
/**
* 根据问答ID查询问答数据记录
*
* @param dto 问答ID
* @return CommunityEncyclopediaQuestionAnswer
*/
@PostMapping("/getById")
@ApiOperation(value = "根据ID查询")
public ResultEntity<?> getById(@RequestBody IdDTO dto) throws BusinessException {
if (null == dto || StringUtils.isBlank(dto.getId())) {
log.error("百科问答ID不能为NULL");
return ResultEntity.error("百科问答ID不能为空和NULL");
}
return ResultEntity.success(getCommunityEncyclopediaQuestionAnswerById(dto.getId()));
}
/**
* 百科问答上下线操作
*/
@PostMapping("/updateStatus")
@ApiOperation(value = "百科问答上下线操作")
public ResultEntity<?> updateStatus(@RequestBody QuestionAnswerUpdateDTO dto) throws BusinessException, IOException {
if (null == dto || StringUtils.isBlank(dto.getId()) || null == dto.getStatus()) {
log.error("百科问答ID或发布状态不能为空和NULL");
return ResultEntity.error("百科问答ID或发布状态不能为空和NULL");
}
String id = dto.getId();
Integer status = dto.getStatus();
CommunityEncyclopediaQuestionAnswer encyclopediaQuestionAnswer = getCommunityEncyclopediaQuestionAnswerById(id);
if (status.equals(encyclopediaQuestionAnswer.getStatus())) {
log.error("百科问答当前状态已为上下线的操作状态");
return ResultEntity.error("百科问答当前状态已为上下线的操作状态");
}
// 上线时,判断置顶排序和推荐顺序是否占用
if (YesOrNoEnum.isYes(status) && null != encyclopediaQuestionAnswer.getTopIndex() && findValidOneByTypeAndStatusAndCategoryAndTopIndex(
ValidOrInvalidEnum.VALID.getValue(), status, encyclopediaQuestionAnswer.getCategory(), encyclopediaQuestionAnswer.getTopIndex())) {
log.error("有效的置顶顺序被占用,不能使用");
return ResultEntity.error("有效的置顶顺序被占用,不能使用");
}
if (YesOrNoEnum.isYes(status) && null != encyclopediaQuestionAnswer.getRecommendIndex() && findValidOneByTypeAndStatusAndRecommendIndex(
ValidOrInvalidEnum.VALID.getValue(), status, encyclopediaQuestionAnswer.getRecommendIndex())) {
log.error("有效的推荐顺序被占用,不能使用");
return ResultEntity.error("有效的推荐顺序被占用,不能使用");
}
// 更新上下线状态
encyclopediaQuestionAnswer.setStatus(status);
encyclopediaQuestionAnswer.setUpdateTime(new Date());
try {
elasticsearchClient.update(e -> e
.index(CommonConstants.WIKI_INDEX)
.id(id)
.doc(encyclopediaQuestionAnswer), CommunityEncyclopediaQuestionAnswer.class
);
} catch (Exception e) {
log.error("百科问答上下线操作失败:{}", e.getMessage());
return ResultEntity.error("百科问答上下线操作失败");
}
return ResultEntity.success("百科问答上下线操作成功");
}
/**
* 问题分类上下线而更新该分类下所有问答的上下线状态
*/
@PostMapping("/updateStatusByCategory")
@ApiOperation(value = "问题分类上下线同步百科问答上下线状态")
public ResultEntity<?> updateStatusByCategory(@RequestBody Map<String, Object> map) throws BusinessException, IOException {
Integer category = (Integer) map.get("category");
Integer status = (Integer) map.get("status");
List<CommunityEncyclopediaQuestionAnswer> encyclopediaQuestionAnswers = findValidListByTypeAndCategory(
ValidOrInvalidEnum.VALID.getValue(), category);
try {
if (!CollectionUtils.isEmpty(encyclopediaQuestionAnswers)) {
for (CommunityEncyclopediaQuestionAnswer encyclopediaQuestionAnswer : encyclopediaQuestionAnswers) {
// 上线时,判断推荐顺序是否占用,如占用设置为不是热门推荐
if (YesOrNoEnum.isYes(status) && null != encyclopediaQuestionAnswer.getRecommendIndex() && findValidOneByTypeAndStatusAndRecommendIndex(
ValidOrInvalidEnum.VALID.getValue(), status, encyclopediaQuestionAnswer.getRecommendIndex())) {
encyclopediaQuestionAnswer.setIsHotRecommend(YesOrNoEnum.NO.getValue());
encyclopediaQuestionAnswer.setIsHotRecommendTop(YesOrNoEnum.NO.getValue());
encyclopediaQuestionAnswer.setRecommendIndex(null);
}
// 更新上下线状态
encyclopediaQuestionAnswer.setStatus(status);
encyclopediaQuestionAnswer.setUpdateTime(new Date());
elasticsearchClient.update(e -> e
.index(CommonConstants.WIKI_INDEX)
.id(encyclopediaQuestionAnswer.getId())
.doc(encyclopediaQuestionAnswer), CommunityEncyclopediaQuestionAnswer.class
);
}
}
} catch (Exception e) {
log.error("该问题分类下的百科问答上下线操作失败:{}", e.getMessage());
return ResultEntity.error("该问题分类下的百科问答上下线操作失败");
}
return ResultEntity.success("该问题分类下的百科问答上下线操作成功");
}
/**
* 根据问答ID删除问答数据记录
*/
@PostMapping("/delete")
@ApiOperation(value = "根据ID删除百科问答")
public ResultEntity<?> delete(@RequestBody IdDTO dto) throws BusinessException {
if (null == dto || StringUtils.isBlank(dto.getId())) {
log.error("百科问答ID不能为空和NULL");
return ResultEntity.error("百科问答ID不能为空和NULL");
}
CommunityEncyclopediaQuestionAnswer encyclopediaQuestionAnswer = getCommunityEncyclopediaQuestionAnswerById(dto.getId());
// 更新有效无效,逻辑删除
encyclopediaQuestionAnswer.setType(ValidOrInvalidEnum.INVALID.getValue());
// 去除占用的排序值,设置为默认255
encyclopediaQuestionAnswer.setTopIndex(null);
encyclopediaQuestionAnswer.setRecommendIndex(null);
encyclopediaQuestionAnswer.setUpdateTime(new Date());
try {
elasticsearchClient.update(e -> e
.index(CommonConstants.WIKI_INDEX)
.id(dto.getId())
.doc(encyclopediaQuestionAnswer), CommunityEncyclopediaQuestionAnswer.class
);
} catch (Exception e) {
log.error("删除百科问答操作失败:{}", e.getMessage());
return ResultEntity.error("删除百科问答操作失败");
}
return ResultEntity.success("删除百科问答操作成功");
}
/**
* 取消推荐
*/
@PostMapping("/cancelRecommend")
@ApiOperation(value = "取消推荐")
public ResultEntity<?> cancelRecommend(@RequestBody IdDTO dto) throws BusinessException {
if (null == dto || StringUtils.isBlank(dto.getId())) {
log.error("百科问答ID不能为空和NULL");
return ResultEntity.error("百科问答ID不能为空和NULL");
}
CommunityEncyclopediaQuestionAnswer encyclopediaQuestionAnswer = getCommunityEncyclopediaQuestionAnswerById(dto.getId());
// 取消推荐
encyclopediaQuestionAnswer.setIsHotRecommend(YesOrNoEnum.NO.getValue());
encyclopediaQuestionAnswer.setIsHotRecommendTop(YesOrNoEnum.NO.getValue());
encyclopediaQuestionAnswer.setRecommendIndex(null);
encyclopediaQuestionAnswer.setUpdateTime(new Date());
try {
elasticsearchClient.update(e -> e
.index(CommonConstants.WIKI_INDEX)
.id(dto.getId())
.doc(encyclopediaQuestionAnswer), CommunityEncyclopediaQuestionAnswer.class
);
} catch (Exception e) {
log.error("取消推荐操作失败:{}", e.getMessage());
return ResultEntity.error("取消推荐操作失败");
}
return ResultEntity.success("取消推荐操作成功");
}
// todo user服务接口指向有问题,应该是 user服务的接口写错了,应和search服务保持一致,待修改
/**
* 管理后台查询
* 多条件查询,分页,过滤,排序
*/
@PostMapping("/listEncyclopediaQuestionAnswer")
@ApiOperation(value = "分页查询百科问答列表")
public ResultEntity<?> listEncyclopediaQuestionAnswer(@RequestBody CommunityEncyclopediaQuestionAnswerDTO questionAnswerDTO) throws IOException {
BoolQuery.Builder boolQuery = QueryBuilders.bool()
.must(TermQuery.of(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_TYPE).value(1))._toQuery());
if (!StringUtils.isBlank(questionAnswerDTO.getQuestion())) {
boolQuery.must(WildcardQuery.of(w -> w.field(CommunityEncyclopediaQuestionAnswer.FIELD_MANAGER_QUESTION).value("*" + questionAnswerDTO.getQuestion() + "*"))._toQuery());
}
if (null != questionAnswerDTO.getCategory()) {
boolQuery.must(TermQuery.of(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_CATEGORY).value(questionAnswerDTO.getCategory()))._toQuery());
}
if (null != questionAnswerDTO.getIsCategoryTop()) {
boolQuery.must(TermQuery.of(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_IS_CATEGORY_TOP).value(questionAnswerDTO.getIsCategoryTop()))._toQuery());
}
if (null != questionAnswerDTO.getIsHotRecommend()) {
boolQuery.must(TermQuery.of(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_IS_HOT_RECOMMEND).value(questionAnswerDTO.getIsHotRecommend()))._toQuery());
}
if (null != questionAnswerDTO.getStatus()) {
boolQuery.must(TermQuery.of(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_STATUS).value(questionAnswerDTO.getStatus()))._toQuery());
}
SearchResponse<CommunityEncyclopediaQuestionAnswer> search = elasticsearchClient.search(s -> s
.index(CommonConstants.WIKI_INDEX)
.query(q -> q
.bool(boolQuery.build())
)
.from(questionAnswerDTO.getPageNo() - 1)
.size(questionAnswerDTO.getPageSize())
.sort(sortOptionsBuilder -> sortOptionsBuilder
.field(fieldSortBuilder -> fieldSortBuilder
.field(CommunityEncyclopediaQuestionAnswer.FIELD_TOP_INDEX).order(SortOrder.Asc)
.field(CommunityEncyclopediaQuestionAnswer.FIELD_NORMAL_INDEX).order(SortOrder.Asc)
.field(CommunityEncyclopediaQuestionAnswer.FIELD_CREATE_TIME).order(SortOrder.Desc)))
, CommunityEncyclopediaQuestionAnswer.class);
List<CommunityEncyclopediaQuestionAnswer> questionAnswerList = search.hits().hits().stream().map(Hit::source).collect(Collectors.toList());
List<CommunityEncyclopediaQuestionCategory> questionCategoryList = communityEncyclopediaQuestionCategoryService.listCommunityEncyclopediaQuestionCategory();
if (null != questionCategoryList && !questionCategoryList.isEmpty()) {
List<Integer> questionCategoryIdList = questionCategoryList.stream().map(CommunityEncyclopediaQuestionCategory::getId).collect(Collectors.toList());
questionAnswerList = questionAnswerList.stream()
.filter(questionAnswer -> questionCategoryIdList.contains(questionAnswer.getCategory()))
.collect(Collectors.toList());
} else {
questionAnswerList = new ArrayList<>();
}
Map<String, Object> map = new HashMap<>(16);
map.put("total", Objects.requireNonNull(search.hits().total()).value());
map.put("dataList", questionAnswerList);
return ResultEntity.success(map);
}
/**
* APP查询
* 根据问题关键词和问题类别查询问答列表
*/
@PostMapping(value = "/listCommunityEncyclopediaQuestionAnswer")
@ApiOperation(value = "APP百科问答搜索")
public ResultEntity<?> listCommunityEncyclopediaQuestionAnswer(@RequestBody CommunityEncyclopediaQuestionAnswerDTO questionAnswerDTO) throws IOException {
// 设置多条件
BoolQuery.Builder boolQuery = QueryBuilders.bool()
.must(TermQuery.of(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_TYPE).value(YesOrNoEnum.YES.getValue()))._toQuery())
.must(TermQuery.of(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_STATUS).value(YesOrNoEnum.YES.getValue()))._toQuery());
if (!StringUtils.isBlank(questionAnswerDTO.getQuestion())) {
boolQuery.must(WildcardQuery.of(w -> w.field(CommunityEncyclopediaQuestionAnswer.FIELD_QUESTION).value(questionAnswerDTO.getQuestion()))._toQuery());
}
SortOptions.Builder sortBuilder = new SortOptions.Builder();
if (null != questionAnswerDTO.getCategory()) {
// 热门问答
if (0 == questionAnswerDTO.getCategory()) {
boolQuery.must(TermQuery.of(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_IS_HOT_RECOMMEND).value(YesOrNoEnum.YES.getValue()))._toQuery());
sortBuilder.field(FieldSort.of(f -> f.field(CommunityEncyclopediaQuestionAnswer.FIELD_RECOMMEND_INDEX).order(SortOrder.Asc)));
// 分类别查询
} else {
boolQuery.must(TermQuery.of(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_CATEGORY).value(questionAnswerDTO.getCategory()))._toQuery());
sortBuilder.field(FieldSort.of(f -> f.field(CommunityEncyclopediaQuestionAnswer.FIELD_TOP_INDEX).order(SortOrder.Asc)));
}
}
// 设置排序字段
sortBuilder.field(FieldSort.of(f -> f.field(CommunityEncyclopediaQuestionAnswer.FIELD_NORMAL_INDEX).order(SortOrder.Asc)));
sortBuilder.field(FieldSort.of(f -> f.field(CommunityEncyclopediaQuestionAnswer.FIELD_CREATE_TIME).order(SortOrder.Desc)));
SearchResponse<CommunityEncyclopediaQuestionAnswer> search = elasticsearchClient.search(s -> s
.index(CommonConstants.WIKI_INDEX)
.query(q -> q
.bool(boolQuery.build())
)
.from(questionAnswerDTO.getPageNo() - 1)
.size(questionAnswerDTO.getPageSize())
.sort(sortBuilder.build())
, CommunityEncyclopediaQuestionAnswer.class);
List<CommunityEncyclopediaQuestionCategory> categoryList = communityEncyclopediaQuestionCategoryService.getAllList();
List<CommunityEncyclopediaQuestionAnswer> questionAnswerList = search.hits().hits().stream().map(Hit::source).collect(Collectors.toList());
List<CommunityEncyclopediaQuestionAnswerVO> questionAnswerVOList = questionAnswerList.stream()
.map(questionAnswer -> {
CommunityEncyclopediaQuestionAnswerVO questionAnswerVO = new CommunityEncyclopediaQuestionAnswerVO();
questionAnswerVO.setId(questionAnswer.getId());
questionAnswerVO.setQuestion(questionAnswer.getQuestion());
questionAnswerVO.setAnswer(questionAnswer.getAnswer());
if (categoryList != null && !categoryList.isEmpty()) {
for (CommunityEncyclopediaQuestionCategory communityEncyclopediaQuestionCategory : categoryList) {
if (communityEncyclopediaQuestionCategory.getId().equals(questionAnswer.getCategory())) {
questionAnswerVO.setCategoryTitle(communityEncyclopediaQuestionCategory.getTitle());
break;
}
}
}
return questionAnswerVO;
}).collect(Collectors.toList());
Map<String, Object> map = new HashMap<>(16);
map.put("total", Objects.requireNonNull(search.hits().total()).value());
map.put("dataList", questionAnswerVOList);
return ResultEntity.success(map);
}
private CommunityEncyclopediaQuestionAnswer getCommunityEncyclopediaQuestionAnswerById(String id) throws BusinessException {
if (null == id) {
log.error("问答ID不能为NULL");
throw new BusinessException(ResultCode.ERROR.getCode(), "问答ID不能为NULL");
}
GetResponse<CommunityEncyclopediaQuestionAnswer> optionalById;
try {
// 根据问答ID查询到问答数据记录
optionalById = elasticsearchClient.get(s -> s.index(CommonConstants.WIKI_INDEX).id(id), CommunityEncyclopediaQuestionAnswer.class);
} catch (Exception e) {
log.error("es服务异常,请联系管理员:{}", e.getMessage());
throw new BusinessException(ResultCode.ERROR.getCode(), "es服务异常,请联系管理员");
}
if (!optionalById.found()) {
log.error("根据ID未查询到对应问答数据记录");
throw new BusinessException(ResultCode.ERROR.getCode(), "根据问答ID未查询到问答数据记录");
}
CommunityEncyclopediaQuestionAnswer communityEncyclopediaQuestionAnswer = optionalById.source();
assert communityEncyclopediaQuestionAnswer != null;
if (!ValidOrInvalidEnum.isValid(communityEncyclopediaQuestionAnswer.getType())) {
log.error("根据ID查询的问答数据无效");
throw new BusinessException(ResultCode.ERROR.getCode(), "根据ID查询的问答数据无效");
}
return communityEncyclopediaQuestionAnswer;
}
/**
* 查询有效的百科问答列表
*/
@PostMapping("/findValidListByType")
@ApiOperation(value = "查询有效的百科问答列表")
public ResultEntity<?> findValidList() throws BusinessException {
try {
// 根据问答ID查询到问答数据记录
List<CommunityEncyclopediaQuestionAnswer> encyclopediaQuestionAnswerList = findValidListByType(ValidOrInvalidEnum.VALID.getValue());
return ResultEntity.success(encyclopediaQuestionAnswerList);
} catch (Exception e) {
log.error("es服务异常,请联系管理员:{}", e.getMessage());
return ResultEntity.error("es服务异常,请联系管理员");
}
}
/**
* 根据问答分类查询有效上线置顶的百科问答
*/
@PostMapping("/findValidListByCategory")
@ApiOperation(value = "根据问答分类查询有效上线置顶的百科问答")
public ResultEntity<?> findValidListByCategory(@RequestBody CommunityEncyclopediaQuestionAnswerDTO dto) throws BusinessException {
if (null == dto || null == dto.getCategory()) {
log.error("百科问答类别不能为NULL");
return ResultEntity.error("百科问答类别不能为NULL");
}
try {
// 根据问答ID查询到问答数据记录
List<CommunityEncyclopediaQuestionAnswer> questionAnswerList = findValidListByTypeAndStatusAndCategoryAndIsCategoryTop(ValidOrInvalidEnum.VALID.getValue(),
YesOrNoEnum.YES.getValue(), dto.getCategory(), YesOrNoEnum.YES.getValue());
return ResultEntity.success(questionAnswerList);
} catch (Exception e) {
log.error("es服务异常,请联系管理员:{}", e.getMessage());
return ResultEntity.error("es服务异常,请联系管理员");
}
}
/**
* 查询有效上线推荐的百科问答
*/
@PostMapping("/findValidListByRecommend")
@ApiOperation(value = "查询有效上线推荐的百科问答")
public ResultEntity<?> findValidListByRecommend() throws BusinessException {
try {
List<CommunityEncyclopediaQuestionAnswer> questionAnswerList =
findValidListByTypeAndStatusAndIsHotRecommend(ValidOrInvalidEnum.VALID.getValue(),
YesOrNoEnum.YES.getValue(), YesOrNoEnum.YES.getValue());
return ResultEntity.success(questionAnswerList);
} catch (Exception e) {
log.error("es服务异常,请联系管理员:{}", e.getMessage());
return ResultEntity.error("es服务异常,请联系管理员");
}
}
/**
* 查询有效上线关联产品productCode的百科问答
*/
@PostMapping("/findValidListByProductCode")
@ApiOperation(value = "查询有效上线关联产品productCode的百科问答")
public ResultEntity<?> findValidListByProductCode(@RequestBody ProductLibraryDTO dto) throws BusinessException {
try {
List<CommunityEncyclopediaQuestionAnswer> questionAnswerList =
findValidListByTypeAndStatusAndProductCode(ValidOrInvalidEnum.VALID.getValue(),
YesOrNoEnum.YES.getValue(), dto.getProductCode());
return ResultEntity.success(questionAnswerList);
} catch (Exception e) {
log.error("es服务异常,请联系管理员:{}", e.getMessage());
return ResultEntity.error("es服务异常,请联系管理员");
}
}
private boolean findValidOneByTypeAndStatusAndCategoryAndTopIndex(Integer type, Integer status, Integer category, Integer topIndex) throws IOException {
return Objects.requireNonNull(elasticsearchClient.search(s -> s
.index(CommonConstants.WIKI_INDEX)
.query(q -> q
.bool(b -> b
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_TYPE).value(type)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_STATUS).value(status)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_CATEGORY).value(category)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_TOP_INDEX).value(topIndex)))
)
), CommunityEncyclopediaQuestionAnswer.class).hits().total()).value() > 0;
}
private boolean findValidOneByTypeAndStatusAndRecommendIndex(Integer type, Integer status, Integer recommendIndex) throws IOException {
return Objects.requireNonNull(elasticsearchClient.search(s -> s
.index(CommonConstants.WIKI_INDEX)
.query(q -> q
.bool(b -> b
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_TYPE).value(type)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_STATUS).value(status)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_RECOMMEND_INDEX).value(recommendIndex)))
)
), CommunityEncyclopediaQuestionAnswer.class).hits().total()).value() > 0;
}
private List<CommunityEncyclopediaQuestionAnswer> findValidListByTypeAndCategory(Integer type, Integer category) throws IOException {
return elasticsearchClient.search(s -> s
.index(CommonConstants.WIKI_INDEX)
.query(q -> q
.bool(b -> b
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_TYPE).value(type)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_CATEGORY).value(category)))
)
), CommunityEncyclopediaQuestionAnswer.class).hits().hits().stream().map(Hit::source).collect(Collectors.toList());
}
private List<CommunityEncyclopediaQuestionAnswer> findValidListByType(Integer type) throws IOException {
return elasticsearchClient.search(s -> s
.index(CommonConstants.WIKI_INDEX)
.query(q -> q
.bool(b -> b
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_TYPE).value(type)))
)
), CommunityEncyclopediaQuestionAnswer.class).hits().hits().stream().map(Hit::source).collect(Collectors.toList());
}
private List<CommunityEncyclopediaQuestionAnswer> findValidListByTypeAndStatusAndCategoryAndIsCategoryTop(Integer type, Integer status, Integer category, Integer categoryTop) throws IOException {
return elasticsearchClient.search(s -> s
.index(CommonConstants.WIKI_INDEX)
.query(q -> q
.bool(b -> b
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_TYPE).value(type)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_STATUS).value(status)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_CATEGORY).value(category)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_IS_CATEGORY_TOP).value(categoryTop)))
)
), CommunityEncyclopediaQuestionAnswer.class).hits().hits().stream().map(Hit::source).collect(Collectors.toList());
}
private List<CommunityEncyclopediaQuestionAnswer> findValidListByTypeAndStatusAndIsHotRecommend(Integer type, Integer status, Integer isHotRecommend) throws IOException {
return elasticsearchClient.search(s -> s
.index(CommonConstants.WIKI_INDEX)
.query(q -> q
.bool(b -> b
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_TYPE).value(type)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_STATUS).value(status)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_IS_HOT_RECOMMEND).value(isHotRecommend)))
)
), CommunityEncyclopediaQuestionAnswer.class).hits().hits().stream().map(Hit::source).collect(Collectors.toList());
}
private List<CommunityEncyclopediaQuestionAnswer> findValidListByTypeAndStatusAndProductCode(Integer type, Integer status, String productCode) throws IOException {
return elasticsearchClient.search(s -> s
.index(CommonConstants.WIKI_INDEX)
.query(q -> q
.bool(b -> b
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_TYPE).value(type)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_STATUS).value(status)))
.must(m -> m.term(t -> t.field(CommunityEncyclopediaQuestionAnswer.FIELD_PRODUCT_CODE).value(productCode)))
)
), CommunityEncyclopediaQuestionAnswer.class).hits().hits().stream().map(Hit::source).collect(Collectors.toList());
}
private void createIndexDetail() throws IOException {
CreateIndexResponse response = elasticsearchClient
.indices()
.create(c -> c
.index(CommonConstants.WIKI_INDEX)
.settings(sBuilder -> sBuilder
.index(iBuilder -> iBuilder
// 三个分片
.numberOfShards("5")
// 一个副本
.numberOfReplicas("1")))
.mappings(mBuilder -> mBuilder
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_ID, pBuilder -> pBuilder.keyword(keywordPropertyBuilder -> keywordPropertyBuilder.ignoreAbove(256)))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_QUESTION, pBuilder -> pBuilder.text(tBuilder -> tBuilder.analyzer("ik_max_word").searchAnalyzer("ik_smart")))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_MANAGER_QUESTION, pBuilder -> pBuilder.keyword(keywordPropertyBuilder -> keywordPropertyBuilder.ignoreAbove(256)))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_ANSWER, pBuilder -> pBuilder.text(tBuilder -> tBuilder.analyzer("ik_max_word").searchAnalyzer("ik_smart")))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_CATEGORY, pBuilder -> pBuilder.integer(integerNumberPropertyBuilder -> integerNumberPropertyBuilder))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_STATUS, pBuilder -> pBuilder.integer(integerNumberPropertyBuilder -> integerNumberPropertyBuilder))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_NORMAL_INDEX, pBuilder -> pBuilder.integer(integerNumberPropertyBuilder -> integerNumberPropertyBuilder))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_IS_CATEGORY_TOP, pBuilder -> pBuilder.integer(integerNumberPropertyBuilder -> integerNumberPropertyBuilder))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_TOP_INDEX, pBuilder -> pBuilder.integer(integerNumberPropertyBuilder -> integerNumberPropertyBuilder))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_IS_HOT_RECOMMEND, pBuilder -> pBuilder.integer(integerNumberPropertyBuilder -> integerNumberPropertyBuilder))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_IS_HOT_RECOMMEND_TOP, pBuilder -> pBuilder.integer(integerNumberPropertyBuilder -> integerNumberPropertyBuilder))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_RECOMMEND_INDEX, pBuilder -> pBuilder.integer(integerNumberPropertyBuilder -> integerNumberPropertyBuilder))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_TYPE, pBuilder -> pBuilder.integer(integerNumberPropertyBuilder -> integerNumberPropertyBuilder))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_OPERATE_REAL_NAME, pBuilder -> pBuilder.keyword(keywordPropertyBuilder -> keywordPropertyBuilder.ignoreAbove(256)))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_OPERATE_DJ_CODE, pBuilder -> pBuilder.keyword(keywordPropertyBuilder -> keywordPropertyBuilder.ignoreAbove(256)))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_CREATE_TIME, pBuilder -> pBuilder.date(datePropertyBuilder -> datePropertyBuilder.format("yyyy-MM-dd HH:mm:ss")))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_UPDATE_TIME, pBuilder -> pBuilder.date(datePropertyBuilder -> datePropertyBuilder.format("yyyy-MM-dd HH:mm:ss")))
.properties(CommunityEncyclopediaQuestionAnswer.FIELD_PRODUCT_CODE, pBuilder -> pBuilder.keyword(keywordPropertyBuilder -> keywordPropertyBuilder.ignoreAbove(256)))
)
);
log.info("createIndexDetail方法,acknowledged={}", response.acknowledged());
}
}
es8代码升级遇到的问题
pom.xml 关于 jackson 的版本不兼容问题
引入依赖后服务无法正常启动
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.3</version>
</dependency>通过mvn命名进行排查
mvn dependency:tree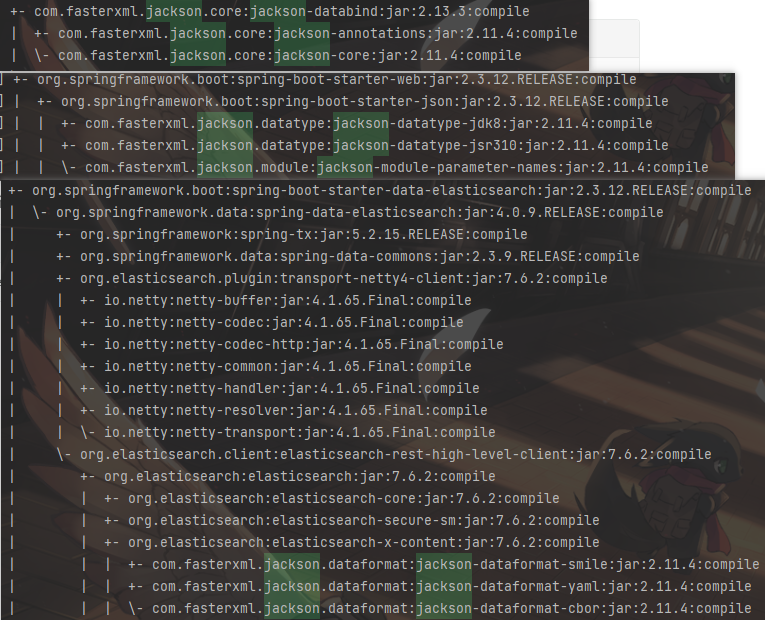
观察依赖树发现,可能是 jackson 2.13版本下其他依赖可能和已有版本存在冲突
解决方案
将 依赖保持和已有依赖一致
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.11.4</version>
</dependency>ElasticSearch查询报错JsonpMappingException
说明某些字段无法转换,根据报错信息排查
重新导入es数据,删除version、timestamp 两个额外字段即可
或者使用兜底方案(不一定成):
在实体类上加注解
@JsonIgnoreProperties(ignoreUnknown=true)ElasticSearch查询报错JsonpMappingException
WildcardQuery 查询不到数据
Query wildcardQuery = WildcardQuery.of(w -> w.field("managerQuestion").value("*" + questionAnswerDTO.getQuestion() + "*"))._toQuery();
SearchResponse<CommunityEncyclopediaQuestionAnswer> search = elasticsearchClient.search(s -> s
.index("community_encyclopedia")
.query(q -> q
.bool(b -> b
.must(type)
.must(wildcardQuery)
)
), CommunityEncyclopediaQuestionAnswer.class);将字段 managerQuestion 改为 managerQuestion.keyword
查询后Date类型 的 @JsonFormat 未生效
待解决
es间数据迁移
迁移方式对比

参考链接:三种常用的 Elasticsearch 数据迁移方案
es6.8到7.1.1
采用方式
ElasticSearch-dump
安装
npm install elasticdump -g
在 D:\environment\nodejs\node_global\node_modules\elasticdump\bin 目录下运行命令相关命令
在线迁移单个索引
elasticdump --input=http://"elastic:pB0@uI"@10.221.50.102:9200/community_encyclopedia --output=http://localhost:9200/community_encyclopedia --type=mapping
elasticdump --input=http://"elastic:pB0@uI"@10.221.50.102:9200/community_encyclopedia --output=http://localhost:9200/community_encyclopedia --type=data
elasticdump --input=http://"elastic:pB0@uI"@10.221.50.102:9200/orgnization --output=http://localhost:9200/orgnization --type=mapping
elasticdump --input=http://"elastic:pB0@uI"@10.221.50.102:9200/orgnization --output=http://localhost:9200/orgnization --type=data
elasticdump --input=http://localhost:9200/dragon --output=http://"elastic:pB0@uI"@10.221.50.102:9200/dragon --type=mapping
elasticdump --input=http://localhost:9200/dragon --output=http://"elastic:pB0@uI"@10.221.50.102:9200/dragon --type=data
elasticdump --input=http://"elastic:pB0@uI"@10.221.50.102:9200/community_encyclopedia --output=http://"elastic:pB0@uI"@localhost:9200/community_encyclopedia --type=mapping
elasticdump --input=http://"elastic:pB0@uI"@10.221.50.102:9200/community_encyclopedia --output=https://"elastic:pB0@uI"@localhost:9200/community_encyclopedia --type=data
elasticdump --input=http://"elastic:pB0@uI"@10.221.50.102:9200/community_encyclopedia --output=http://"elastic:pB0@uI"@10.7.176.72:9200/community_encyclopedia --type=mapping
http://10.7.176.72:9200/
dragon
离线迁移全部索引(需要手动创建目录) -- 未测试
# 导出
multielasticdump --direction=dump --match='^.*$' --input=http://"elastic:pB0@uI"@10.221.50.102:9200 --output=/tmp/es_backup --includeType='data,mapping' --limit=2000
# 导入
multielasticdump --direction=load --match='^.*$' --input=/tmp/es_backup --output=http://localhost:9200 --includeType='data,mapping' --limit=2000
multielasticdump --direction=dump --match='^.*$' --input=http://"elastic:pB0@uI"@10.221.50.102:9200 --output=E:\file\back_test --includeType='data,mapping' --limit=2000
multielasticdump --direction=load --match='^.*$' --input=E:\file\back_test --output=http://localhost:9200 --includeType='data,mapping' --limit=2000
参数含义
- --input: 源地址,可为 ES 集群 URL、文件或 stdin,可指定索引,格式为:{protocol}://{host}:{port}/{index}--input-index: 源 ES 集群中的索引
- --output: 目标地址,可为 ES 集群地址 URL、文件或 stdout,可指定索引,格式为:{protocol}://{host}:{port}/{index}
- --output-index: 目标 ES 集群的索引
- --type: 迁移类型,默认为 data,表明只迁移数据,可选 settings, analyzer, data, mapping, alias
参考链接
elasticsearch-dump工具:GitHub - elasticsearch-dump/elasticsearch-dump: Import and export tools for elasticsearch & opensearch
使用该工具迁移文档:使用ElasticSearch-dump进行数据迁移、备份_elasticsearchdump 大于4g_刘李404not found的博客-CSDN博客
es6.8 到 8.7.0(本地)
采用方式
ElasticSearch-dump(需要配置安全证书,暂时不采用这种方式)
logstash
启动方式
在logstash新建 mysql/logstash-es.conf 文件
然后用一下命令启动
bin\logstash.bat -f mysql\logstash-es.conf配置文件
#logstash输入配置
input {
elasticsearch {
hosts => ["10.221.50.102:9200"]
index => "community_encyclopedia"
user => "elastic"
password => "pB0@uI"
#设置为true,将会提取ES文档的元数据信息,例如index、type和id。貌似没用
# docinfo => true
}
}
#logstash输出配置
output {
# stdout { codec => json_lines}
stdout { codec => rubydebug}
elasticsearch {
hosts => ["localhost:9200"]
user => "elastic"
password => "pB0@uI"
ssl => true
ssl_certificate_verification => false
index => "community_encyclopedia"
document_id => "%{id}"
}
}es6.8 到 8.7.0(测试环境)
特别说明
为保证es中索引结构相同,请先在代码端/页面 运行下保存相关接口,在es中创建索引后再进行数据迁移
采用方式
ElasticSearch-dump(需要配置安全证书,暂时不采用这种方式)
logstash
启动方式
在logstash新建 mysql/logstash-es.conf 文件
然后用一下命令启动
bin\logstash.bat -f mysql\logstash-es.conf
[linux]:
sudo ./bin/logstash -f mysql_test/logstash-es.conf
# sudo 加不加都可
./bin/logstash -f extend/job/logstash-t_settle_order_info.conf配置文件
#logstash输入配置
input {
elasticsearch {
hosts => ["10.221.50.102:9200"]
index => "community_encyclopedia"
user => "elastic"
password => "pB0@uI"
#设置为true,将会提取ES文档的元数据信息,例如index、type和id。貌似没用
# docinfo => true
}
}
filter {
mutate {
remove_field => ["@version", "@timestamp"]
}
}
#logstash输出配置
output {
# stdout { codec => json_lines}
stdout { codec => rubydebug}
elasticsearch {
# hosts => ["10.7.176.72:9200"]
hosts => ["10.7.176.72:9200","10.7.176.73:9200","10.7.176.74:9200"]
# hosts => ["10.7.176.72:9300"]
user => "elastic"
# password => "pB0@uI"
password => "Mvwm@n12nal"
# ssl => true
# ssl_certificate_verification => false
index => "community_encyclopedia"
document_id => "%{id}"
}
}mysql到es数据迁移
订单历史数据从mysql迁移至es(单表测试)
搭伙app订单查询接口分析
url:https://agentd.djbx.com/order/orderInfo/orderInfoList
method:POST
requestTime:2023.06.28-14:02:56:820
responseTime:2023.06.28-14:02:57:31
duration:211ms
body:{
"pageNo": "1",
"pageSize": "10",
"param": {
"memberId": "4OnzMs73",
"productType": [],
"status": "3",
"policyStatus": null,
"startDate": null,
"endDate": null,
"appntName": null,
"lcnNo": null
}
}
params:{}
header:{content-type: application/json; charset=utf-8, systemType: android, systemVersion: 9, deviceID: PQ3A.190705.003, bundleId: com.djcx.dahuo, appVersion: 4.3.10, phoneModel: Xiaomi 2203121C, token: 7pyvLZQfD6UUP0d4yPTgkXTgdq8, content-length: 174}采用方式
logstash
启动运行
在【程序目录】目录执行以下命令启动:
【windows】bin\logstash.bat -f mysql\logstash-db-sync.conf
【linux】nohup ./bin/logstash -f mysql_test/logstash-es.conf & (后台)
sudo ./bin/logstash -f mysql_test/logstash-es.conf需求
从mysql:dh.order 的 t_car_order 中迁移已支付和已取消的订单到es
条件:ORDER_STATUS in (3,4)
数据量

一个月30w,一年300w(占用磁盘大约1GB)
索引类创建方案
按月分索引:数据量太少,不建议
按年划分索引:感觉可行,试一下
都试一下,看看查询效率,删除效率如何(什么情况下会删除数据呢?)
logstash相关配置
#logstash输入配置
input {
#jdbc输入配置,用来指定mysql中需要同步的数据查询SQL及同步周期
jdbc {
type => "jdbc"
jdbc_connection_string => "jdbc:mysql://10.221.50.106:3306/dh_order?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false"
# 数据库连接账号密码;
jdbc_user => "dh_test"
jdbc_password => "Y2017dh123"
# MySQL依赖包路径;
jdbc_driver_library => "mysql/mysql-connector-java-5.1.49.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库重连尝试次数
connection_retry_attempts => "3"
# 判断数据库连接是否可用,默认false不开启
jdbc_validate_connection => "true"
# 数据库连接可用校验超时时间,默认3600S
jdbc_validation_timeout => "3600"
# 是否开启分页
jdbc_paging_enabled => true
# statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
# statement => "SELECT * FROM `t_car_order`"
# statement => "SELECT DATE_FORMAT(tco.create_time, '%Y.%m') index_date, tco.* FROM t_car_order tco limit 200"
statement => "SELECT DATE_FORMAT(tco.create_time, '%Y') index_year, tco.* FROM t_car_order tco"
# statement => "SELECT ID, order_no, order_type, MEMBER_ID, owner_id, team_id, CHANNEL_CODE, pay_type, PAY_NO, TOTAL_AMOUNT, PAY_AMOUNT, DISCOUNT_AMOUNT, DISCOUNT_RATE, ROLE_TYPE, PRODUCT_VALUE, ORDER_STATUS, SUB_ORDER_STATUS, step_url, total_annual_prem, paidTime, subject, transfer, identity, msg, date_format(update_time,'%Y-%m-%d %H:%i:%s') update_time, date_format(create_time,'%Y-%m-%d %H:%i:%s') create_time, uuid, renewal_redis_key, clue_id, union_type, system_type, operation_code, cx_order_no, fin_typ
# FROM t_car_order limit 10"
# statement => "SELECT * FROM t_car_order limit 1"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
# lowercase_column_names => false
# Value can be any of: fatal,error,warn,info,debug,默认info;
# sql_log_level => warn
sql_log_level => debug
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
# record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;
# use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
# tracking_column => "ModifyTime"
# Value can be any of: numeric,timestamp,Default value is "numeric"
# tracking_column_type => timestamp
# record_last_run上次数据存放位置;
# last_run_metadata_path => "mysql/last_id.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
# clean_run => false
# 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务,这里设置为每5分钟同步一次
# schedule => "*/5 * * * * *"
# 用来控制增量更新的字段,一般是自增id或者创建、更新时间,注意这里要采用sql语句中select采用的字段别名
# tracking_column => "unix_ts_in_secs"
# tracking_column 对应字段的类型
# tracking_column_type => "numeric"
# timezone => "Asia/Shanghai" # 你的时区
}
}
#logstash输入数据的字段匹配和数据过滤
# filter {
# mutate {
# copy => { "id" => "[@metadata][_id]"}
# remove_field => ["id", "@version", "unix_ts_in_secs"]
# }
# }
filter {
# date {
# match => ["update_time", "yyyy-MM-dd HH:mm:ss"]
# target => "update_time"
# }
# grok {
# match => {"message" => "(?<create_time>(?:%{YEAR}-%{MONTHNUM2}-%{MONTHDAY} %{HOUR}:%{MINUTE}:%{SECOND}))"}
# }
# mutate {
# add_field => {"temp_ts" => "%{create_time}"}
# }
# date {
# match => ["temp_ts", "yyyy-MM-dd HH:mm:ss"]
# target => "@timestamp"
# }
# date {
# match => ["create_time", "yyyy-MM-dd HH:mm:ss"]
# target => "create_time"
# }
# ruby {
# code => 'event.set("create_time", event.get("create_time").strftime("%Y-%m-%d %H:%M:%S"))'
# }
# date {
# # match => ["create_time", "yyyy-MM-dd HH:mm:ss"]
# match => ["create_time", "ISO8601"]
# target => "create_time"
# timezone => "Asia/Shanghai" # 你的时区
# # timezone => "America/New_York" # 你的时区
# }
# mutate {
# add_field => { "index_date" => "%{create_time}" }
# }
# mutate {
# rename => { "create_time_string" => "index_date" }
# }
# date {
# # match => ["index_date", "ISO8601"]
# match => ["index_date", "ISO8601"]
# # target => "index_date"
# }
# }
# date {
# match => ["index_date", "yyyy-MM-dd HH:mm:ss"]
# # target => "index_date"
# # target => "index_date"
# }
# mutate {
# add_field => {
# "index_date1" => "%{index_date}"
# }
# mutate {
# remove_field => ["@version","index_date"]
# }
ruby {
code => "event.set('@timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('update_time', event.get('update_time').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('create_time', event.get('create_time').time.localtime + 8*60*60)"
}
# ruby {
# code => "event.set('create_time',event.get('timestamp'))"
# }
# mutate {
# add_field => { "[@metadata][index_date]" => "%{index_date}" }
# remove_field => ["@version", "index_date"]
# }
mutate {
add_field => { "[@metadata][index_year]" => "%{index_year}" }
remove_field => ["@version", "index_year"]
}
}
#logstash输出配置
output {
# 采用stdout可以将同步数据输出到控制台,主要是调试阶段使用
# stdout { codec => json_lines}
stdout { codec => rubydebug}
# 指定输出到ES的具体索引
# elasticsearch {
# index => "rdbms_sync_idx"
# document_id => "%{[@metadata][_id]}"
# }
elasticsearch {
# host => "192.168.1.1"
# port => "9200"
# 配置ES集群地址
# hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
hosts => ["localhost:9200"]
# 索引名字,必须小写
# index => "t_car_order-%{+YYYY.MM.dd}"
# index => "t_car_order-%{index_date}"
# index => "t_car_order-%{[@metadata][index_date]}"
# index => "t_car_order_@timestamp"
index => "t_car_order"
# index => "t_car_order-%{[@metadata][index_year]}"
# 数据唯一索引(建议使用数据库KeyID)
# document_id => "%{KeyId}"
document_id => "%{id}"
# document_id => "ID"
}
}
参考链接
通过Logstash将RDS MySQL数据同步至Elasticsearch
问题
logstash日期格式转换问题(暂未解决)
多个logstash版本测试
日期转换不可用,sql层面也不行,打算在接口层处理。
日期格式问题,暂缓。。。 心累了,估计是日期插件问题,全网没有找到解决方案,走sql修改吧
提了个bug:无法将date类型进行格式化操作 · Issue #158 · logstash-plugins/logstash-filter-date · GitHub
参考链接
Elasticsearch 滞后8个小时等时区问题,一网打尽!
logstash 7.x 中时间问题,@timestamp 与本地时间相差 8个小时
现有订单数据保存到es方案
修改保存接口,保存到mysql改为es,或者可以考虑消息队列中间件
订单历史数据从mysql迁移至es(实际业务场景)
背景1:由于无法在单sql中查询数据,因此无法使用logstash工具
背景2:订单迁移分为订单详情和订单列表两大类
背景3:订单信息涉及多张表,无法进行单表简单迁移
迁移方案
订单信息获取
search服务设置一个定时任务,通过feign调用car服务查询接口,进行全量和增量查询需要的订单信息
订单信息迁移至es
分两大类创建索引:订单详情和订单列表,每一类按照年维度进行索引构建,用别名进行查询
es结构按订单号为id,报文信息为message
定时任务详情
参数
订单创建日期开始日期,订单创建日期截止日期
默认参数:最近三个月
如何获取符合条件的增量数据的订单号?通过binlog日志
通过时间段(每三个月跑一次)
参考链接
java与es8实战之六:用JSON创建请求对象(比builder pattern更加直观简洁)
参考文档
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!