MySQL Server 层和引擎层是如何交互的
Server 层、引擎层、BufferPool、磁盘间的关系
大体来说, MySQL可以分为Server层和存储引擎层两部分。
1)Server 层:Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
2)引擎层:在 Server 层下方的是各种存储引擎层,它们是 MySQL 的核心部分,负责数据的存储和检索。从 MySQL 5.5.5 版本开始 MySQL 将 InnoDB 设为默认存储引擎,它使用 BufferPool 作为缓存池来缓存磁盘中的数据,从而减少对磁盘的IO操作。
3)BufferPool:BufferPool 是 InnoDB 引擎中的一块儿缓存池,用于缓存磁盘中的数据。它位于引擎层和磁盘之间,起到了一个桥梁的作用。通过将数据缓存在内存中,可以减少对磁盘的访问次数,提高数据库的性能。
4)磁盘:磁盘是计算机的外部存储设备,用于存储大量的数据。在 MySQL 中,磁盘主要用于存储数据库的数据文件、日志文件等。
Server 层和引擎层是相对独立的两个模块,它们之间要配合完成工作,就会存在数据交互的过程,今天我们就以 Server 层从存储引擎层读取数据来讲讲这个起着关键作用的数据交互过程。
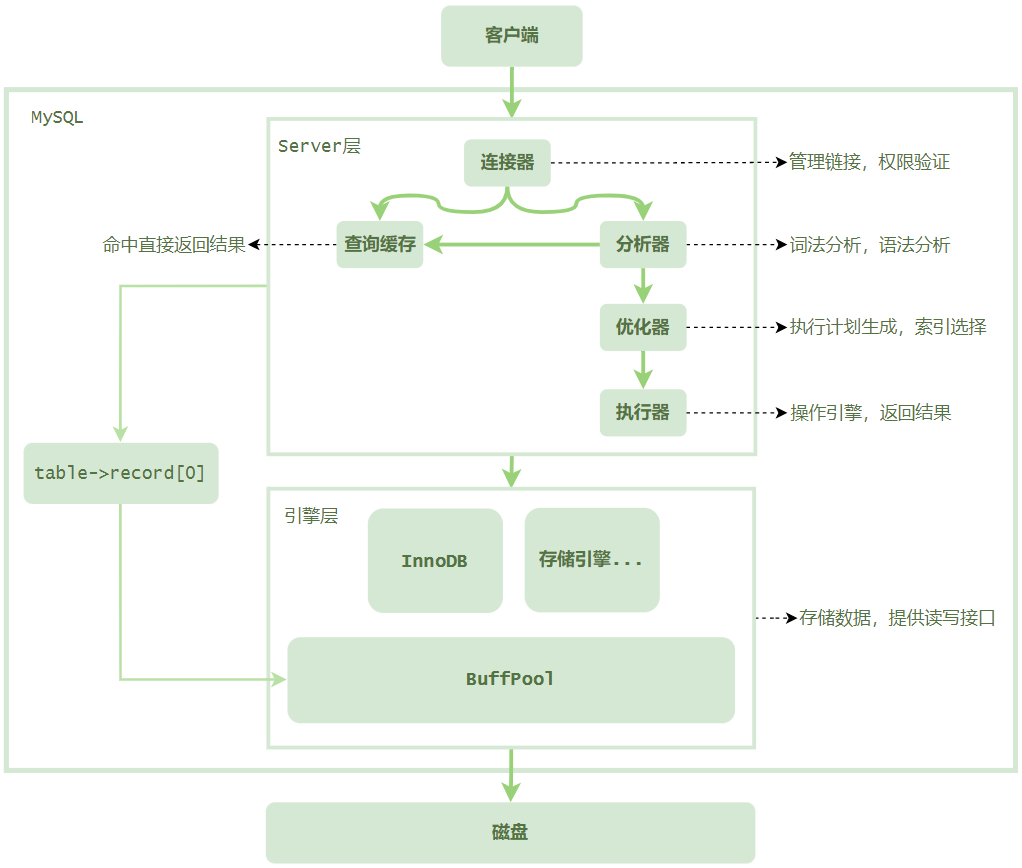
Server 层和引擎层交互原理
在源码中,数据库中的每个表都会对应?TABLE?类的一个实例,实例中有个?record?属性,record 属性是一个有着 2 个元素的数组,Server 层每次调用引擎层的方法读取数据时,都会用?table->record[0]?的形式把第 1 个元素的地址传给引擎层(这个地址实际上是指向 BufferPool 中存储的数据页的地址,即 Server 层通过使用 table->record[0] 间接访问 BufferPool)。引擎层从磁盘或者内存中读取数据之后,把引擎层的数据格式转换为 Server 层的数据格式,然后写入到这个地址对应的内存空间里,Server 层就可以拿这个数据来干各种事情了(比如:WHERE 条件筛选、分组、排序等)。
整个交互过程就是这么简单,这个交互过程之所以这么简单,是因为 Server 层前期做了足够的准备工作,才让这个过程看起来像百度的搜索框那么简单。
为了一探究竟,接下来就是我们往前追溯准备工作的时间了。
准备工作
在创建表时,会计算出来每个字段在记录(也就是我们常说的行)中的?Offset,以及一条记录的最大长度(包含存储变长字段的长度需要占用的字节数)。
当我们第一次查询某个表的时候,MySQL 会从 frm 文件中读取字段、索引等信息,以及刚刚提到的字段 Offset?、一条记录的最大长度。
接下来会根据记录的最大长度,为第 1 小节中提到的?TABLE?类实例的?record?属性申请内存,record 数组的两个元素 record[0]、record[1] 占用的字节数都等于记录的最大长度。
在源码中,每个字段都对应?Field?子类的一个实例,实例中有个?ptr?属性,指向每个字段在?record[0]?中对应的内存地址。对于变长字段,Field 子类实例中还会存储内容长度占用的字节数。
存储引擎从磁盘或者内存中读取一条记录的某个字段后,会判断字段的类型,如果是定长字段,把字段内容经过相应的格式转换后写入 ptr 指向的内存空间。如果是变长字段,先把内容长度写入 ptr 指向的内存空间,然后紧挨着把字段内容经过相应的格式转换后写入内容长度之后的内存空间。
说明:定长字段、变长字段是指数据类型的特性,具体可查看 MySQL 数据类型。
接下来会用一个实际的表为例子,并且通过一张图来展示 record[0] 的内存布局,以便有个直观的了解。
实例分析
示例表:
CREATE TABLE t(`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`i1` int(10) unsigned DEFAULT '0',
`str1` varchar(32) DEFAULT '',
`str2` varchar(255) DEFAULT '',
`c1` char(11) DEFAULT '',
`e1` enum('北京','上海','广州','深圳') DEFAULT '北京',
`s1` set('吃','喝','玩','乐') DEFAULT '',
`bit1` bit(8) DEFAULT b'0',
`bit2` bit(17) DEFAULT b'0',
`blob1` blob,
`d1` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;这是 record[0] 的内存布局:

示例表和内存布局图都有了,接下来我们对照着图来分析一下各个字段对应的内存空间的情况:
字段 NULL 值标记区域
这个区域是标记一条具体的记录中,定义表结构时没有指定 NOT NULL?的字段,实际的内容是不是 NULL,如果是 NULL,在这个区域中对应的位置会设置为?1,如果不是 NULL,则在这个区域中对应的位置会设置为?0,每个字段的 NULL 标记占用?1 bit。
这个字段在 record[0] 的开头处,所以它的 Offset = 0,由于示例表中,有 10 个字段都没有指定 NOT NULL,所以总共需要 10 bit 来存储 NULL 标记,共占用?2 字节。
存储引擎读取每个字段时,如果该字段在字段 NULL 值标记区域有一席之地,就会把它对应的位置设置个值(0 或者 1)。
id 字段
id 字段的类型是 int,定长字段,占用 4 字节,Offset = 字段 NULL 值标记区域占用字节数 = 2,ptr 属性指向 Offset 2。
存储引擎读取到 id 字段内容,经过大小端存储模式转换之后(把引擎层的数据格式转换为 Server 层的数据格式),把内容写入到 ptr 属性指向的内存空间。
由于 InnoDB 中,内容是按大端模式存储的(内容高位在前,低位在后),而 server 层是按照小端模式读取的,所以在写入整数字段内容到 record[0] 之前会进行大小端存储模式的转换。
i1 字段
i1 字段的类型是 int,定长字段,占用 4 字节,Offset = id Offset(2) + id 长度(4) = 6,ptr 属性指向 Offset 6。
存储引擎读取到 i1 字段内容,经过大小端存储模式转换之后,把内容写入到 ptr 属性指向的内存空间。
str1 字段
str1 字段的类型是 varchar,变长字段,Offset = i1 Offset(6) + i1 长度(4) = 10,ptr 属性指向 Offset 10。
str1 字段定义时指定要存储?32?个字符,表的字符集是 utf8,每个字符最多会占用 3 字节(一个汉字字符占 3 字节),32 个字符最多会占用 96 字节,96 < 255,只需要?1 字节就够存储 str1 内容的长度了,所以?str1 len?区域占用?1 字节。(补充:VARCHAR(n) 存储可变长度的字符串(不会使用空格填充),n 表示字符的最大数量(即字符串的长度),取值范围从 0 到 65535 。VARCHAR 需要额外的 1 或者 2 字节存储字符串的长度,最大长度(此处最大长度是指 n 个字符最多占用字节数)小于等于 255 时额外需要1字节,否则需要2字节。)
str1 字段内容紧挨着?str1 len?之后,由于?str1 len?占用 1 字节,所以 str1 内容的 Offset = 10 + 1 = 11。
存储引擎读取 str1 字段的内容时,也会读取到 str1 的内容长度,会先把内容长度写入 ptr 属性指向的内存空间,然后紧挨着写入 str1 的内容。
str2 字段
str2 字段的类型也是 varchar,变长字段,Offset = str1 Offset(10) + str1 内容长度占用字节数(1) + 内容最大占用字节数(96) = 107,ptr 属性指向 Offset 107。
str2 字段定义时指定要存储?255?个字符,最多会占用 255 * 3 = 765 字节,需要?2 字节才能存储 str2 的内容长度,所以?str2 len?区域占用?2 字节。
str2 字段内容紧挨着?str2 len?之后存储,由于?str2 len?占用 2 字节,所以 str2 内容的 Offset = 107 + 2 = 109。
存储引擎读取 str2 字段内容后,会先把内容长度写入 ptr 属性指向的内存空间,然后紧挨着写入 str2 的内容。
c1 字段
c1 字段的类型是 char,定长字段,Offset = str2 Offset(107) + str2 内容长度占用字节数(2) + 内容最大占用字节数(765) = 874,ptr 属性指向 Offset 874。
c1 字段定义时指定要存储?11?个字符,最多会占用 11 * 3 = 33 字节。
存储引擎读取 c1 字段内容后,会把内容写入 ptr 属性指向的内存空间。如果 c1 字段的实际内容长度比字段内容最大字节数小,会挨着刚刚写入的内容,再写入一定数量的空格。
比如:实际内容长度为 11 字节,而字段内容最大字节数为 33,则会在实际内容之后再写入 22 个空格。?
e1 字段
e1 字段类型是 enum,定长字段,只有 4 个选项,占用 1 字节,Offset = c1 Offset(874) + 内容最大长度占用字节数(33) = 907。
enum 类型在存储引擎中是用整数存储的,存储引擎读取 e1 字段内容后,会对内容进行大小端转换,把转换后的内容写入 ptr 属性指向的内在空间。
s1 字段
s1 字段类型是 set,定长字段,只有 4 个选项,占用 1 字节,Offset = e1 Offset(907) + e1 长度(1) = 908。
set 类型在存储引擎中也是按照整数存储的,存储引擎读取 s1 字段内容后,也需要对内容进行大小端转换,把转换后的内容写入 ptr 属性指向的内存空间。
set 字段是用 enum 来实现的,最多占用 8 字节,共 64 bit,每个选项用 1 bit 表示,所以 1 个 set 字段总共可以有 64 个选项。enum、set 字段的需要长度说明一下,如果创建表时定义的选项数量不一样,字段的长度也可能会不一样(1 ~ 8 字节),但是字段长度在创建表时就已经是确定的了,所以它们也是定长字段。
bit1 字段
bit1 字段的类型是 bit,定长字段,创建表时定义的长度表示的是 bit,不是字节数,Offset = s1 Offset(908) + s1 长度(1) = 909。
bit1 字段定义时指定的是 bit(8),表示该字段长度为 8 bit,也就是?1 字节。
bit 类型的字段在存储引擎中是按 char 存储的,存储引擎读取 bit1 字段的内容后,把内容写入到 ptr 属性指向的内存空间。
这里的 char 是指的 C/C++ 里的 char,不是指的 MySQL 的 char 类型。
bit2 字段
bit2 字段的类型也是 bit,定长字段,创建表时定义的是 bit(17),占用 3 字节,Offset = bit1 Offset(909) + bit1 长度(1) = 910。
bit 类型的字段,如果创建表时指定的 bit 数不是 8 的整数倍,存储引擎在插入数据到磁盘或者内存时,就会在前面补充 0,比如 bit(17),占用 3 字节,内容为 00010000010010011 时,会在前面再补充 7 个 0 变成?000000000010000010010011,读出来的时候也还是这样的内容。
之所以定义 2 个 bit 字段,是为了测试 bit 类型的字段,定义的 bit 位数不是 8 的整数倍时,是不是会把多出来的那些 bit 存储到?字段值 NULL 标记区域中,后来发现,只有 MyISAM、NDB 存储引擎才会这样处理,InnoDB 中 bit 字段是按 char 存储的,bit 位数不是 8 的整数倍时,多出来的 bit 还需要占用 1 字节,比如:bit(17) 需要占用 3 字节。
blob1 字段
blob1 字段的类型是 blob,变长字段,Offset = bit2 Offset(910) + bit2 长度(3) = 913。
blob 类型的字段,最多可以存储 2 ^ 16 = 65536 字节 = 64K。
存储引擎读取 blob1 字段内容之后,会分配一块能够容纳 blob1 字段内容的内存空间,把读取出来的内容写入该内存空间中。然后把 blob1 字段的内容长度写入 ptr 属性指向的内存空间处,占用 2 字节,然后紧挨着写入刚刚分配的那块内存空间的首地址,占用 8 字节。
注意:只是把 blob1 字段的内容的首地址,而不是 blob1 字段的完整内容写入 record[0]。示例中只使用了 blob 类型的字段,实际 blob 类型分为 4 种:tinyblob、blob、mediumblob、longblob,这 4 种类型的内容长度分别占用 1 ~ 4 字节。另外,还需要说明的一点是:tinytext、text、mediumtext、longtext 也是用上面相应的 blob 类型实现的,json 类型是用 longblob 类型实现的。
d1 字段
d1 字段的类型是 decimial,定长字段,Offset = blob1 Offset(913) + blob1 长度占用字节数(2) + blob1 内容首地址占用字节数(8) = 923。
decimal 类型的字段,在存储引擎中是用二进制存储的,在创建表的时候,就计算出来了需要用几字节来存储。
存储引擎读取 d1 字段的内容之后,把内容写入 ptr 属性指向的内存空间。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!