Linux 进程地址空间
知识回顾
在 C 语言的学习过程中,我们知道内存是可以被划分为栈区,堆区,全局数据区,字符常量区,代码区的。他的空间排布可能是下面的样子:

其中,全局数据区,可以划分为已初始化全局数据区和未初始化全局数据区!
- 栈区向下增长。(表现形式之一:同一个栈桢中先定义的变量地址更高,后定义的变量地址更低)
- 堆区向上增长。(随着堆区的使用,变量的地址是向上增长的!)
堆栈之间的区域叫做共享区,这个会在动静态库的时候详解!
内核空间:这是操作系统的代码和数据!
我们可以写一个简单的代码来验证一下:
#include<stdio.h>
#include<stdlib.h>
int g_val = 10;
int main()
{
int a = 1;
int b = 2;
char* str = "hello linux";
int* heap1 = (int*)malloc(sizeof(int));
printf("栈区先定义的变量: &a: %p\n", &a);
printf("栈区后定义的变量: &b: %p\n", &b);
printf("堆区定义的变量: &heap1: %p\n", &heap1);
printf("全局数据: &g_val_init: %p\n", &g_val);
printf("字符常量区: &str: %p\n", str);
return 0;
}

这里说明一下:static 修饰的局部变量,只能初始化一次,作用域在局部,但是生命周期和全局变量一样,那是因为在编译的时候就将这个局部变量定义在了全局数据区,你可以通过打印静态变量的地址看出来!
进程地址空间引入
我们学习了进程地址空间之后,就能解决在进程创建的那一节中提出的一个问题:用 id 变量接收 fork 函数的返回值,为什么一个变量能读出来两个不同的值?
我们来看一段代码:定义一个全局变量 g_val = 100,使用 fork 创建子进程,子进程每隔一秒打印 pid ppid g_val g_val,5 秒之后将 g_val 修改为 200;父进程每隔一秒打印 pid g_val &g_val。看看能观察到什么现象:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int g_val = 100;
int main()
{
pid_t id = fork();
if(id == 0)
{
//这是子进程
int cnt = 5;
while(1)
{
printf("I am child process, pid: %d, ppid: %d, g_val: %d, &g_val: %p\n", getpid(), getppid(), g_val, &g_val);
sleep(1);
if(cnt) cnt--;
else
{
g_val = 200;
printf("child process change g_val: 100->200\n");
cnt--;
}
}
}
else if(id > 0)
{
while(1)
{
printf("I am parent, pid: %d, g_val: %d, &g_val: %p\n", getpid(), g_val, &g_val);
sleep(1);
}
}
else
{
perror("fork():");
}
return 0;
}
5 秒中之后子进程修改全局变量 g_val ,子进程修改父子进程的共享数据发生写时拷贝,为子进程的 g_val 重新开辟空间!打印的时候子进程的 g_val 等于 200,父进程的 g_val 等于 100。这没问题!但是我们发现,发生写时拷贝之后,父子进程打印出来的 &g_val 是一样的!

怎么可能同一个变量,同一个地址,同时读取,读到了不同的内容呢?
因此我们得到一个结论:这里打印出来的地址绝对不是物理地址,我们把这个打印出来的地址称为虚拟地址或者线性地址。
我们在写 C/C++ 程序中使用的指针,地址其实都不是物理地址!
什么是进程地址空间
我们先不说什么是进程地址空间,我们先来看子进程创建时父子进程是如何做到共享代码和数据的!
- 首先,父进程有自己的
task_struct在这个结构体中,有一个字段叫做mm_struct*,能通过这个字段找到父进程的虚拟地址(线性地址)。我们定义了一个全局变量g_val就会给这个变量分配一个虚拟地址!在Linux操作系统中有一个叫做页表的东西,你可以把他理解为一个map他存储的是虚拟地址到物理地址的映射关系!也就是说,通过页表,我们能够通过虚拟地址访问物理地址(物理内存)! fork()创建子进程,会为子进程创建task_struct,拷贝父进程的虚拟内存,拷贝虚拟内存的页表!- 拷贝父进程的虚拟内存: 那么,这个全局变量的虚拟地址在父子进程中都是一样的!
- 拷贝父进程的页表:那么,通过相同的虚拟地址,相同的页表,就能做到访问相同的物理内存!
上面的论述证明了父子进程数据是共享的!代码共享的原理是一样的!
我们可以画出示意图:

这个示意图可以帮助大家理解虚拟地址和物理地址,其中页表这么画是不对的,我们后面会详解页表的真实结构!不过页表以这种结构来理解是没有大问题的!
子进程是如何做到 g_val 的写时拷贝的?
父子进程代码和数据是共享的,当我们在子进程中对 g_val 做出修改的时候,操作系统就会为子进程重新开辟 g_val 类型大小的空降,然后将 g_val 拷贝到这块新的空间,并修改 g_val 的值,最后修改 g_val 虚拟地址映射的物理地址!完成写时拷贝!

写时拷贝的本质就是重新开辟空间,但是这个过程中,左侧的虚拟地址是 0 感知的,虚拟地址不关心,也不会被影响!
现在我们就能解决当初遗留的问题啦:为啥 fork 之后的 id 有两个值?
fork()函数在return之前就将子进程创建好了!return的本质也是写入!也就是说会发生写时拷贝!父子进程虽然在访问同一个id,但是根据页表访问的是不同的物理地址(物理内存),这就是一个id变量能够读出两个值的原因!
地址空间
以 32 位的 Linux 操作系统为例,地址空间就是地址排列组合形成的地址范围:
[
0
,
2
32
)
[0, 2^{32})
[0,232)。
在 32 位操作系统中,有 32 位的地址总线和数据总线,CPU 和 内存通过系统总线相连,每一根总线有 0,1 两种状态(高电平,低电平,那么 32 根总线,就有
2
32
2^{32}
232 种组合!通过 CPU 与 内存相连的总线,CPU 能读取内存的数据!
2
32
2^{32}
232 对应
4
G
B
4GB
4GB 的内存大小!因此想要映射出来
4
G
B
4GB
4GB 的物理内存,就需要同等范围的虚拟内存!
如何理解地址空间的区域划分
这篇文章的开头我们看到的内存区域划分就是地址空间的区域划分!我们又知道了地址空间就是地址排列组形成的地址范围!地址空间的本质是内核的一个数据结构对象,地址空间也是要被操作系统管理起来的!
因此我们就能以一种较为简单的方式对地址空间进行区域划分:

只要维护两个指针用来标识一个区域划分的起始地址和结束地址就是对地址空间做划分啦!
对虚拟地址的空间做出这样的划分之后,我们就能够粗略判断访问变量的时候是否发生越界访问啦!
在地址空间中最小单位就是一个地址,这个地址是可以被直接使用的!
为了检验我们的结论正确性,可以看看 Linux 内核的源代码是不是这个样子:
我们可以看到在 task_struct 中有一个 struct mm_struct,跳转到 mm_struct 内部,我们看到了诸如 start_code end_code 这样的字段,证明我们得出的结论是没有问题的!

为什么要有进程地址空间
让所有的进程以统一的视角看待内存
任何一个进程都有自己的地址空间,地址空间上的虚拟地址通过页表的映射访问物理内存!
这就是任何一个进程访问物理内存的逻辑!在访问内存的方式做到了统一!
如果没有进程地址空间,task_struct 中就得维护进程的代码和数据在内存中的位置,一旦进程的状态发生切换,就会修改 task_struct 中的内容,太过麻烦!
保护物理内存
增加进程地址空间后,我们想要访问物理内存就必须通过页表的转换,在这个转化的过程,我们就可以对寻址进行审查,一旦出现访问异常,操作系统就能及时拦截!使得请求不会到达内存,能够有效地保护物理内存
事实上页表中还维护了一个字段,表示对物理内存的读写权限!
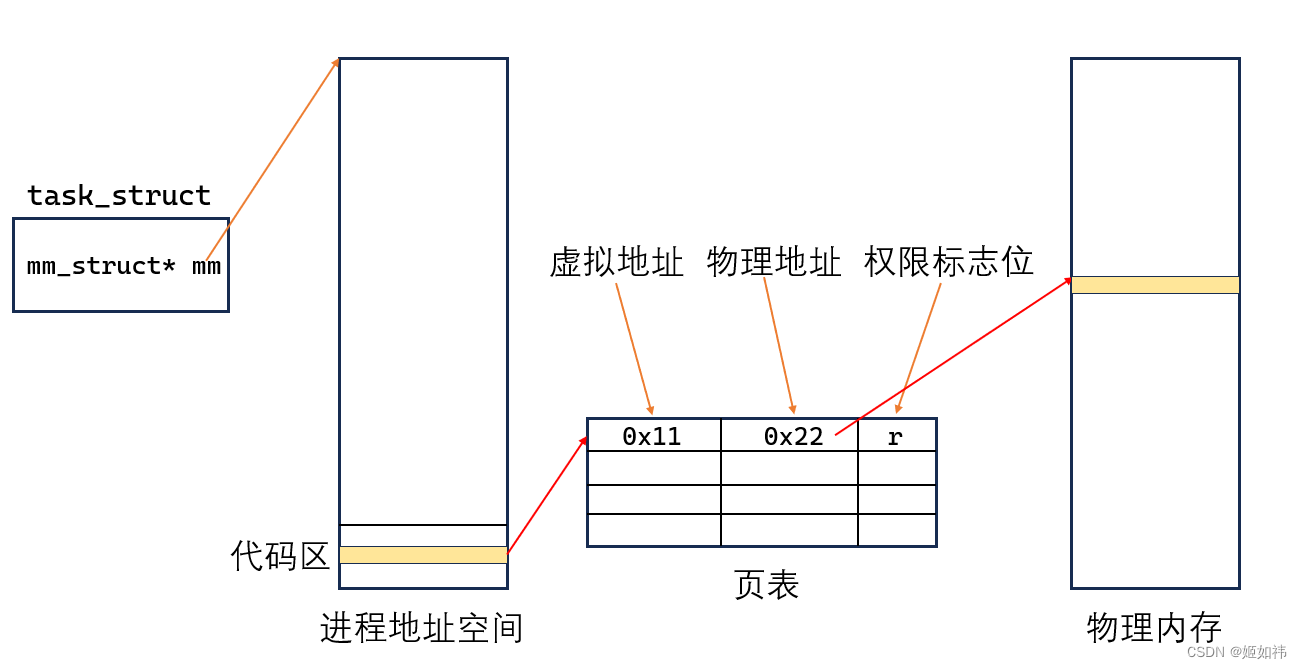
如图,在代码区有一段代码,虚拟地址是 0x11 物理地址是 0x22 通过页表他们之间就存在映射关系!代码区的代码权限标志位都是 r。当我们尝试对代码区做修改时,根据 CPU 中的 cr3 寄存器找到页表,发现我们想要对权限标志位为 r 的物理内存做修改,操作系统会直接拦截!保证了物理内存的安全!
根据上面的现象,我们能够得出结论:
- ==物理内存根本没有权限管理的概念!==不然可执行程序是如何被加载到内存中的?
cr3寄存器为何能够直接访问物理内存,而不做权限的检查? - 凭什么代码是只读的?程序加载到内存中就是对物理内存进行写入!物理内存本身并没有只读一说!因此,是虚拟地址通过页表映射到物理地址上时,页表中权限标志位为
r,即只读!当我们对代码区做修改,操作系统能够根据权限标志位进行拦截!所以才说代码区是只读的!
实现进程管理模块与内存管理模块的解耦
- 虚拟化: 进程地址空间提供了虚拟化的抽象,使得每个进程都以为它拥有整个系统的内存。这使得进程可以独立运行,而无需关心其他进程的内存布局。
- 独立的页表: 每个进程都有自己的页表,负责将其虚拟地址空间映射到物理地址。这样,不同进程可以有不同的页表,实现了内存空间的隔离。页表的管理成为内存管理模块的责任。
- 惰性加载:
Linux操作系统可以采用懒加载的策略,只在需要时将进程的部分地址空间加载到物理内存中。这种分页和惰性加载的方式使得内存管理更加灵活。
进程之间的地址空间是隔离的,一个进程的内存操作不会直接影响其他进程。这有助于提高系统的安全性和稳定性。
换句话说,进程之间可以有完全相同的虚拟地址,但是能根据相同的虚拟地址访问到不同的物理地址!
程序的惰性加载
不知道大家是否有一个疑问:我们完的电脑游戏下载 下来可能就是几十个 GB,但是我们的物理内存就那么一点儿大!这是怎么做到将游戏运行起来的呢?
在学习进程的状态时,我们知道在操作系统学科中有挂起的状态,进程处于挂起状态时,他的代码和数据会被放在磁盘中,只保留 PCB 在物理内存!
可是 Linux 操作系统中并没有挂起状态啊,如何知道当前进程的代码和数据在不在内存中呢?
- 首先,我们需要达成一个共识:现代操作系统,几乎不会做浪费时间和空间的事情!
- 假设我们有一个可执行程序,他的代码和数据有 20 MB,在加载可执行程序的时候,我们加载了
5MB的代码和数据!于是这个进程跑起来了!结果发现在这个进程被调度的过程中,只用到了1MB的代码和数据,可是当初加载可执行程序的时候加载了5MB哇!于是就产生了内存空降的浪费!这是不被允许的!!因为现代操作系统中,几乎不会做浪费时间和空间的事情!
事实上在页表中还有一个字段,用来标识某个虚拟地址的代码和数据是否加载到内存!比如该标志位为 1 代表代码和数据已经加载到内存中啦!
当我们执行代码时,CPU 通过 cr3 寄存器找到页表,发现该虚拟地址并未加载代码,就会引发缺页中断,进程发生缺页中断就会再加载一部分代码和数据,先分配内存空间。然后将物理地址填充到对应的虚拟地址,就可以继续执行代码啦!
正是因为有页表和虚拟内存的存在,进程不需要关系内存的事儿!当发生缺页中断的时候,操作系统就会自动调用内存管理模块的相关功能!也就实现了进程管理与内存管理的解耦!
现在我们就可以回答上面的问题啦!不管你的代码和数据有多少,加载可执行程序的时候我就加载一点点,剩下的代码和数据往页表中填充虚拟地址就行,当我们要访问这些为加载的代码和数据就会引发缺页中断!再次加载一部分代码和数据!这也提高了内存的使用效率!
知识巩固
-
什么是进程呢?学到这里,内核数据结构又多了一部分啦!
进程 = 内核数据结构 ( t a s k s t r u c t m m s t r u c t 页表 ) + 代码和数据 进程 = 内核数据结构(task_struct mm_struct 页表) + 代码和数据 进程=内核数据结构(tasks?tructmms?truct页表)+代码和数据 -
进程切换:因为
mm_struct是被维护在task_struct中的,cr3寄存器指向当前进程的页表,cr3寄存器中的内容属于进程的上下文!因此进程地址空间与页表都是自动切换的! -
进程之间具有独立性!怎么做到的?
- 每个进程都有自己独立的内核数据结构。
- 每个进程的虚拟地址可以完全一样,只要通过页表映射出来的物理地址不一样就行!实现了代码和数据层面的解耦!进程资源的释放并不会影响其他进程!
因此,进程的代码和数据加载到物理内存的位置并不重要
知识点总结:
- 什么是进程地址空间
- 为什么要有地址空间

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!