非递归实现的快速排序
目录
序列文章
非递归实现的快速排序:http://t.csdnimg.cn/UEcL6
快速排序的挖坑法与双指针法:http://t.csdnimg.cn/I1L7Q
快速排序的hoare法:http://t.csdnimg.cn/SV0nA
前言
????????一般来说,我们在写排序时都比较喜欢使用递归的方式,但是递归如果层次太深可能会引起栈溢出的问题,所以我们在本篇会讲解如何使用非递归的方式实现快速排序\( ̄︶ ̄*\))
学前补充
对于递归改非递归我们其实已经不是第一次写了,比如斐波那契数列中的递归改非递归:
//递归实现斐波那契数列
#include <stdio.h>
int count = 0;
int Fid(int n)
{
if (n <= 0)
return 0;
else if (n == 1)
return 1;
else
count++;
return Fid(n - 1) + Fid(n - 2);
}
int main()
{
int n = 0;
printf("请输入要求第几个斐波那契数列中的数字:>");
scanf_s("%d", &n);
int ret = Fid(n);
printf("该数字为:%d\n", ret);
printf("需要计算的次数为: %d\n", count);
return 0;
}
//迭代(循环)实现斐波那契数列
#include <stdio.h>
int count = 0;
int Fun(int n)
{
int a = 1;
int b = 1;
int c = 1;
while (n > 2) //当n>2时开始进行循环相加
{
c = a + b;
a = b;
b = c;
count++;
n--;
}
return c; //当n<2时直接输出1
}
int main()
{
int n = 0;
printf("请输入要求第几个斐波那契数列中的数字:>");
scanf_s("%d", &n);
int num = Fun(n);
printf("该数字为:%d\n", num);
printf("所需要的次数为:%d",count);
return 0;
}
????????我们会发现,可以实现递归改迭代的问题,它们使用迭代实现的思路会比递归更加的好理解,所以一般来说我们在进行递归改非递归的过程中,会将递归改为迭代的形式。
????????但是对于快速排序而言,我们会利用栈来将它改为非递归的方式而不是迭代,这是因为在快速排序中,每次划分操作会将原始数组划分为两个较小的子数组。然后我们需要对这两个子数组进行进一步的划分和排序。这种嵌套关系导致了一个逻辑上的函数调用链。
????????使用循环来实现非递归版本时,我们无法直接模拟出函数调用链中各级函数之间传递参数和保存局部变量等信息的机制。而通过使用栈数据结构,在每次遇到新的待处理子数组时,我们可以将相关信息(如起始索引、结束索引)压入栈中,并在下一轮迭代时从栈中弹出并取出相应信息进行处理。
????????换句话说,通过利用栈作为辅助数据结构,在代码层面上模拟了逻辑上函数调用链所需传递和保存状态信息等功能。这样就能够以迭代方式按照特定顺序处理所有待处理子问题(即待切割和排序的子数组),达到完成整体排序任务。
结论:在非递归实现快速排序算法时选择使用栈来管理状态信息是一种常见且有效的策略
非递归快速排序
注意事项(重要)
????????我们利用栈存储的是每次要进行排序的数组元素的下标的值,而不是该数组元素的值,我们会将这些下标代入到之前实现过的单趟的快速排序中(比如伪双指针法快速排序),每次循环都进行一次单趟排序,这样就可以不再像递归那样排序时,需要借助栈帧
实现步骤
1、将数组首尾元素下标0和9入栈,将栈顶元素分别赋值给变量left和right后,栈顶元素出栈(赋值一个出一个,一共四步:入->出->入->出)将作left和right传入快速排序(其实就是begin和end)实现单趟排序
2、将单趟排序后形成的左区间和右区间的四个下标值入栈(单趟排序返回的是作为分界线元素的下标的值)


3、后续入栈出栈过程不予解释建议自行理解?
代码实现
//非递归排序
void QuickSortNonR(int* a, int begin, int end)
{
//初始化栈
ST s;
STInit(&s);
//将数组首尾元素的下标的值作为x入栈
STPush(&s, end);
STPush(&s, begin);
//栈不为空就循环
while (!STEmpty(&s))
{
//获取栈顶元素值(原数组中的下标),并让栈顶元素出栈(获取完此时的栈顶元素就出,获取两个栈顶元素就开始排序)
int left = STTop(&s);
STPop(&s);
int right = STTop(&s);
STPop(&s);
//将获取的两个下标值进行单趟排序(利用之前的伪双指针法)
int keyi = PartSort3(a, left, right);
// [left, keyi-1] keyi [keyi+1, right]
//当左区间范围不为1时(没法继续缩小问题规模),将划分后左区间两个边界位置元素的下标值入栈
if (left < keyi - 1)
{
STPush(&s, keyi - 1);
STPush(&s, left);
}
//当右区间范围不为1时(没法继续缩小问题规模),将划分后右区间两个边界位置元素的下标值入栈
if (keyi + 1 < right)
{
STPush(&s, right);
STPush(&s, keyi + 1);
}
}
//最后销毁栈空间
STDestroy(&s);
}时空复杂度
最坏时间复杂度:O(N^2)(当输入数组完全有序时,每次切分操作都可能将数组分为一个较小的部分和一个较大的部分,导致每次切分只能减少一项)
最好时间复杂度:O(N*logN)(每次划分都能将数组均匀地分成两个接近子数组,N个元素要进行logN次的排序,N*logN,跟前面的递归排序的意思差不多)
空间复杂度:O(logN)(不需要额外的栈空间来保存状态信息,只需维护一个辅助堆栈用于存储待处理子数组的起止索引即可)

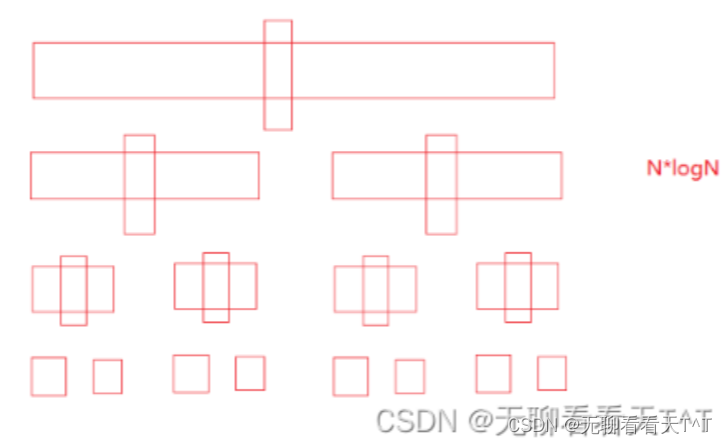
快速排序的特性
- 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
- 稳定性:不稳定
栈的相关代码
代码太多,就不再全部展示了,需要的自提:http://t.csdnimg.cn/kheGO
~over~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!