2024.1.3 Spark架构角色和提交任务流程
?
目录
一 . Yarn的角色回顾
资源管理层面
? ? ? ? 集群资源管理者(Master) : ResourceManager
? ? ? ? 单机资源管理者(Worker) : NodeManager
任务计算层面
? ? ? ? 单任务管理者(Master) : ApplicationMaster
? ? ? ? 单位执行者(Worker) : Task (容器内计算框架的工作角色)
Spark中有多个角色,每个角色都有不同的功能和责任。以下是Spark中常见的角色:
-
Driver:驱动程序是Spark应用程序的主要组件,负责定义应用程序的逻辑和控制执行流程。它将应用程序转化为任务,并将任务分发给集群中的执行器进行执行。
-
Executor:执行器是在集群中运行的工作进程,负责执行驱动程序分发的任务。每个执行器都有自己的资源,包括CPU和内存,并且可以同时执行多个任务。
-
Master:主节点是Spark集群的管理节点,负责分配任务给各个执行器,并监控它们的状态。它还负责维护集群的元数据信息,如应用程序的进度和资源分配情况。
-
Worker:工作节点是集群中的计算资源提供者,负责接收和执行任务。它们通过与主节点通信来接收任务,并将任务分配给执行器进行执行。
-
Cluster Manager:集群管理器是负责管理整个Spark集群的组件,它可以是Standalone模式下的Spark自带的集群管理器,也可以是其他第三方集群管理器,如YARN或Mesos。
-
Application:应用程序是由驱动程序和执行器组成的Spark任务的集合。它定义了数据处理和计算逻辑,并通过驱动程序将任务分发给执行器进行执行。
-
Task:任务是应用程序中的最小执行单元,由驱动程序定义并分发给执行器进行执行。每个任务都会处理一部分数据,并生成中间结果或最终结果。
-
Stage:阶段是一组相互依赖的任务的集合,它们可以并行执行。Spark将应用程序的任务划分为多个阶段,以便更好地利用并行计算能力。
-
RDD:弹性分布式数据集(RDD)是Spark中的核心数据抽象,它是一个可分区、可并行计算的数据集合。RDD可以在内存中缓存,并支持容错和恢复。
-
DataFrame:DataFrame是一种以表格形式组织的分布式数据集,类似于关系型数据库中的表。它提供了丰富的数据操作和查询功能,并支持多种数据格式。
二、Spark提交任务流程
1、Spark On Standalone
-
spark集群启动后,Worker向Master注册信息
-
spark-submit命令提交程序后,driver和application也会向Master注册信息
-
创建SparkContext对象:主要的对象包含DAGScheduler和TaskScheduler
-
Driver把Application信息注册给Master后,Master会根据App信息去Worker节点启动Executor
-
Executor内部会创建运行task的线程池,然后把启动的Executor反向注册给Dirver
-
DAGScheduler:负责把Spark作业转换成Stage的DAG(Directed Acyclic Graph有向无环图),根据宽窄依赖切分Stage,然后把Stage封装成TaskSet的形式发送个TaskScheduler; 同时DAGScheduler还会处理由于Shuffle数据丢失导致的失败;
-
TaskScheduler:维护所有TaskSet,分发Task给各个节点的Executor(根据数据本地化策略分发Task),监控task的运行状态,负责重试失败的task;
-
所有task运行完成后,SparkContext向Master注销,释放资源;
2.? Spark on Yarn
Spark On Yarn的本质?
Master角色由YARN的ResourceManager担任。
Worker角色由YARN的NodeManager担任。
Driver角色运行在YARN容器内 或 提交任务的客户端进程中,真正干活的Executor运行在YARN提供的容器内。
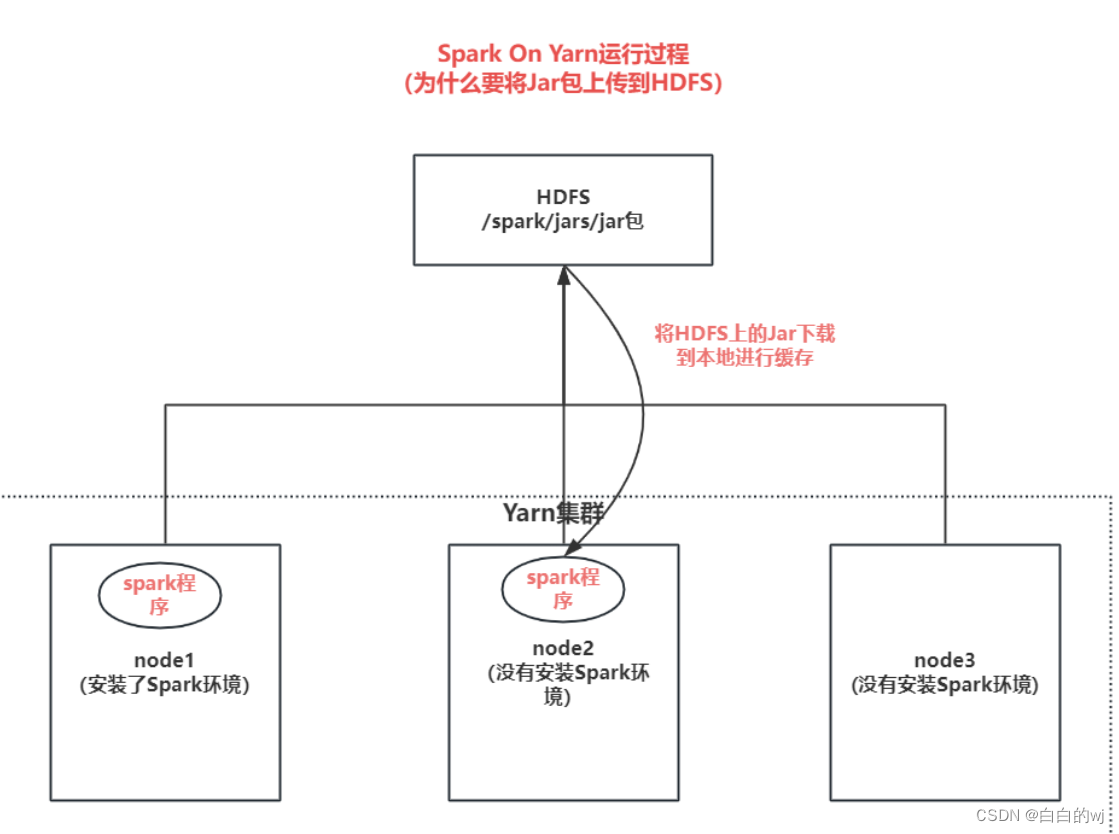
Spark on yarn运行过程,为什么需要将jar包上传到hdfs:
因为集群环境中,只有node1安装了Spark环境,node2和node3都没有安装,所以node2和node3要运行Spark的时候,会先去hdfs中把Jar包下载到本地进行缓存,所以node2和node3才可以运行Spark
三. Spark?比MapReduce执行效率高的原因
1.内存计算:Spark将反复使用的数据缓存在内存中,减少了数据加载的耗时,相比之下,MapReduce将中间结果保存在文件中,需要频繁地进行磁盘读写操作,导致性能较低
2.数据交换:Spark使用内存进行数据交换,而MapReduce需要将数据写入磁盘再进行读取,这样的过程会增加IO开销,因此,Spark在数据交换方面更快.
3.DAG计算模型:Spark采用DAG(有向无环图)计算模型,可以将多个任务合并为一个DAG图,从而减少了任务之间的数据传输和磁盘读写.而MapReduce每个任务之间都需要进行磁盘读写,导致效率较低
综上所述,Spark通过内存计算,数据交换和DAG计算模型等方式提高了执行效率,相比之下,MapReduce在可靠性和内存占用方面更优,但性能较低
四.Spark的排序算子
sortByKey :对数据按照Key键进行排序
sortBy : 根据自定义规则对数据进行排序
top : 对数据进行降序排序,然后取前N个元素,返回的结果是List列表
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!