RDD编程
目录
一、RDD编程基础
(一)RDD创建
????????Spark采用textFile()方法来从文件系统中加载数据创建RDD 该方法把文件的URI作为参数,这个URI可以是: 本地文件系统的地址、或者是分布式文件系统HDFS的地址或者是Amazon S3的地址等等。
1、从文件系统中加载数据创建RDD
"file:///home/zhc/mycode/word.txt"文件内容如下:
Hadoop is good
Spark is better
Spark is fast
(1)从本地文件系统中加载数据创建RDD
>>> lines = sc.textFile("file:///home/zhc/mycode/word.txt")
>>> lines.foreach(print)
Hadoop is good
Spark is better
Spark is fast
![]()
(2)从分布式文件系统HDFS中加载数据?
>>> lines = sc.textFile("hdfs://localhost:9000/user/zhc/word.txt")
>>> lines = sc.textFile("/user/zhc/word.txt")
>>> lines = sc.textFile("word.txt")三条语句是完全等价的,可以使用其中任意一种方式。
>>> lines.foreach(print)
Hadoop is good
Spark is better
Spark is fast2. 通过并行集合(列表)创建RDD
????????可以调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(列表)上创建,从而实现并行化处理。
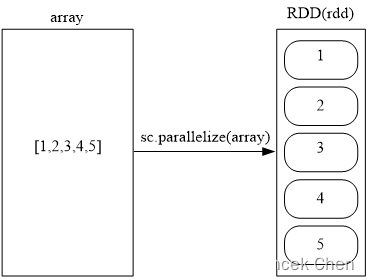
>>> array = [1,2,3,4,5]
>>> rdd = sc.parallelize(array)
>>> rdd.foreach(print)
1
2
3
4
5(二)RDD操作
1、转换操作
????????对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用 转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作。
| 操作 | 含义 |
|---|---|
| filter(func) | 筛选出满足函数func的元素,并返回一个新的数据集 |
| map(func) | 将每个元素传递到函数func中,并将结果返回为一个新的数据集 |
| flatMap(func) | 与map()相似,但每个输入元素都可以映射到0或多个输出结果 |
| groupByKey() | 应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集 |
| reduceByKey(func) | 应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果 |
(1)filter(func)
filter(func)会筛选出满足函数func的元素,并返回一个新的数据集。
>>> lines = sc.textFile("file:///home/zhc/mycode/word.txt")
>>> linesWithSpark = lines.filter(lambda line: "Spark" in line)
>>> linesWithSpark.foreach(print)
Spark is better
Spark is fast
(2)map(func)
map(func)操作将每个元素传递到函数func中,并将结果返回为一个新的数据集。
>>> data = [1,2,3,4,5]
>>> rdd1 = sc.parallelize(data)
>>> rdd2 = rdd1.map(lambda x:x+10)
>>> rdd2.foreach(print)
11
13
12
14
15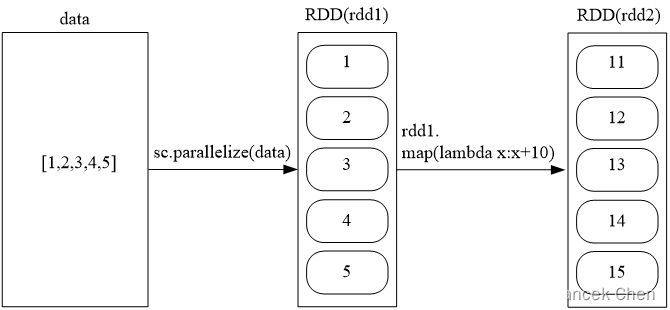
另外一个实例:
>>> lines = sc.textFile("file:///home/zhc/mycode/word.txt")
>>> words = lines.map(lambda line:line.split(" "))
>>> words.foreach(print)
['Hadoop', 'is', 'good']
['Spark', 'is', 'fast']
['Spark', 'is', 'better']
(3)flatMap(func)
>>> lines = sc.textFile("file:///home/zhc/mycode/word.txt")
>>> words = lines.flatMap(lambda line:line.split(" "))
(4)groupByKey()
groupByKey()应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集。
>>> words = sc.parallelize([("Hadoop",1),("is",1),("good",1), \
... ("Spark",1),("is",1),("fast",1),("Spark",1),("is",1),("better",1)])
>>> words1 = words.groupByKey()
>>> words1.foreach(print)
('Hadoop', <pyspark.resultiterable.ResultIterable object at 0x7fab13a8d160>)
('fast', <pyspark.resultiterable.ResultIterable object at 0x7fab13a8d0b8>)
('better', <pyspark.resultiterable.ResultIterable object at 0x7fab13a8d160>)
('is', <pyspark.resultiterable.ResultIterable object at 0x7fab13a8d160>)
('good', <pyspark.resultiterable.ResultIterable object at 0x7fab13a8d0b8>)
('Spark', <pyspark.resultiterable.ResultIterable object at 0x7fab13a8d160>)
(5)reduceByKey(func)
reduceByKey(func)应用于(K,V)键值对的数据集时,返回一个新的(K, V)形式的数据集,其中的每个值是将每个key传递到函数func中进行聚合后得到的结果。
>>> words = sc.parallelize([("Hadoop",1),("is",1),("good",1),("Spark",1), \
... ("is",1),("fast",1),("Spark",1),("is",1),("better",1)])
>>> words1 = words.reduceByKey(lambda a,b:a+b)
>>> words1.foreach(print)
('good', 1)
('Hadoop', 1)
('better', 1)
('Spark', 2)
('fast', 1)
('is', 3)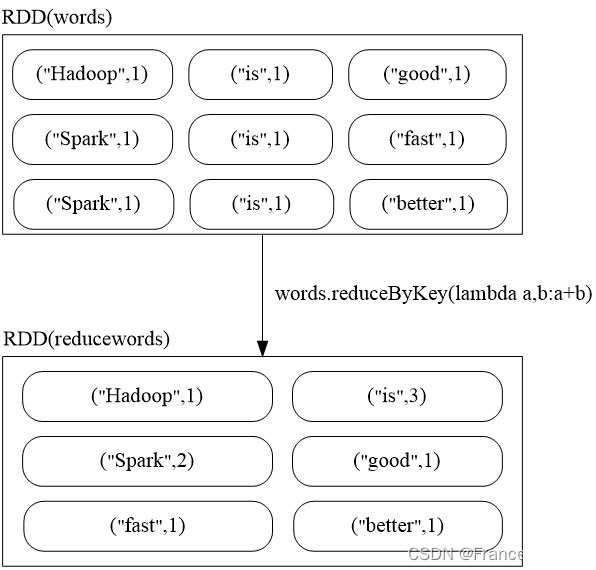
rdd.reduceByKey(lambda a,b:a+b)
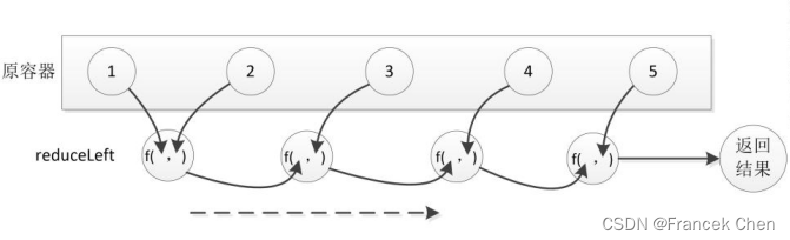
<“spark”,<1,1,1>>
2、行动操作
????????行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。
| 操作 | 含义 |
|---|---|
| count() | 返回数据集中的元素个数 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| first() | 返回数据集中的第一个元素 |
| take(n) | 以数组的形式返回数据集中的前n个元素 |
| reduce(func) | 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素 |
| foreach(func) | 将数据集中的每个元素传递到函数func中运行 |
以下是通过一个实例来介绍上表中的各个行动操作,这里同时给出了在pyspark环境中执行的代码及其结果。
>>> rdd = sc.parallelize([1,2,3,4,5])
>>> rdd.count()
5
>>> rdd.first()
1
>>> rdd.take(3)
[1, 2, 3]
>>> rdd.reduce(lambda a,b:a+b)
15
>>> rdd.collect()
[1, 2, 3, 4, 5]
>>> rdd.foreach(lambda elem:print(elem))
1
2
3
4
5
3、惰性机制
????????所谓的“惰性机制”是指,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算。这里给出一段简单的语句来解释Spark的惰性机制。
>>> lines = sc.textFile("file:///home/zhc/mycode/word.txt")
>>> lineLengths = lines.map(lambda s:len(s))
>>> totalLength = lineLengths.reduce(lambda a,b:a+b)
>>> print(totalLength)
42(三)持久化
????????在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据。下面就是多次计算同一个RDD的例子:
>>> list = ["Hadoop","Spark","Hive"]
>>> rdd = sc.parallelize(list)
>>> print(rdd.count()) #行动操作,触发一次真正从头到尾的计算
3
>>> print(','.join(rdd.collect())) #行动操作,触发一次真正从头到尾的计算
Hadoop,Spark,Hive
????????可以通过持久化(缓存)机制避免这种重复计算的开销。具体方法是使用persist()方法对一个RDD标记为持久化,之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化。持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用。
persist()的圆括号中包含的是持久化级别参数:
persist(MEMORY_ONLY):表示将RDD作为反序列化的对象存储于JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容。
persist(MEMORY_AND_DISK)表示将RDD作为反序列化的对象存储在JVM中,如果内存不足,超出的分区将会被存放在硬盘上。
????????一般而言,使用cache()方法时,会调用persist(MEMORY_ONLY)。针对上面的实例,增加持久化语句以后的执行过程如下:
>>> list = ["Hadoop","Spark","Hive"]
>>> rdd = sc.parallelize(list)
>>> rdd.cache() #会调用persist(MEMORY_ONLY),但是,语句执行到这里,并不会缓存rdd,因为这时rdd还没有被计算生成
>>> print(rdd.count()) #第一次行动操作,触发一次真正从头到尾的计算,这时上面的rdd.cache()才会被执行,把这个rdd放到缓存中
3
>>> print(','.join(rdd.collect())) #第二次行动操作,不需要触发从头到尾的计算,只需要重复使用上面缓存中的rdd
Hadoop,Spark,Hive? ? ? ? 持久化RDD会占用内存空间,当不需要一个RDD时,可以使用unpersist()方法手动地把持久化的RDD从缓存中移除,释放内存空间。
(四)分区
????????RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上。
1、分区的作用
(1)增加并行度
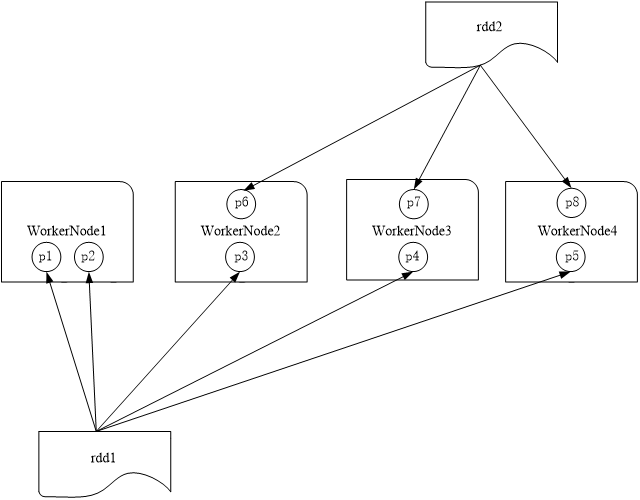
(2)减少通信开销
UserData(UserId,UserInfo)
Events(UserID,LinkInfo)
UserData 和Events 表进行连接操作,获得(UserID,UserInfo,LinkInfo)
未分区时对UserData和Events两个表进行连接操作:
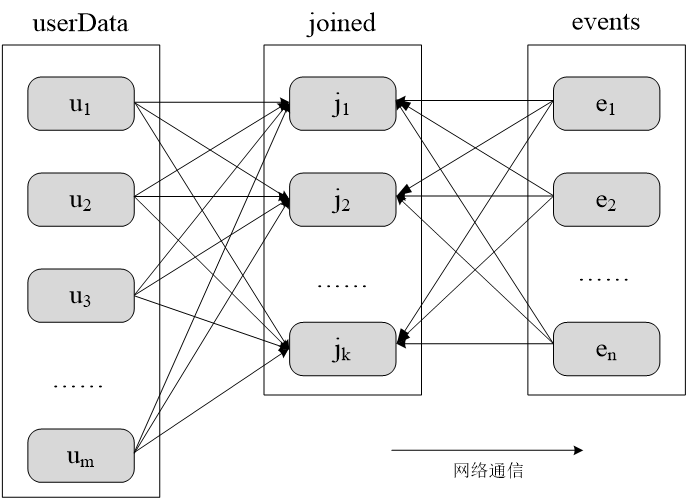
????????实际上,由于userData这个RDD要比?events大很多,所以,可以选择对userData进行区。?比如,可以采用哈希分区方法,把userData这个RDD分区成m个分区,这些分区分布在节点u1、u2……um上。?对userData进行分区以后,在执行连接操作时,就不会产生上图的数据混洗情况。
采用分区以后对UserData和Events两个表进行连接操作:?
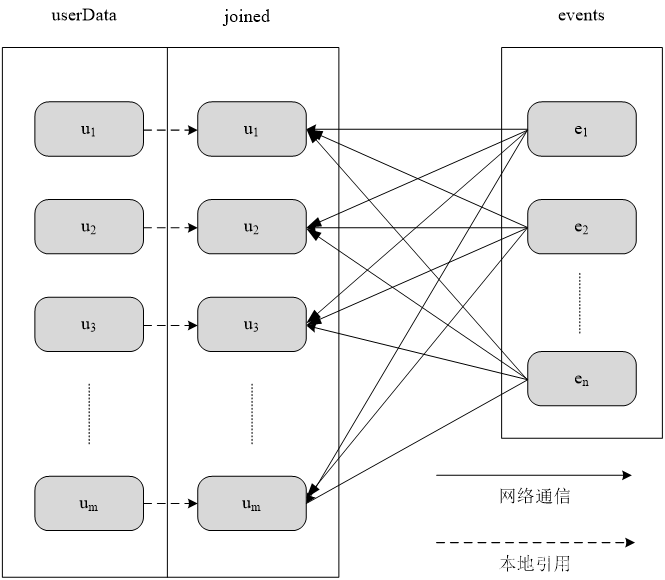
????????由于已经对userData根据哈希值进行了分区,因此,在执行连接操作时,不需要再把userData?中的每个元素进行哈希求值以后再分发到其他节点上,只需要对events?这个RDD的每个元素求哈希值(采用与userData相同的哈希函数)。然后,根据哈希值把每个events?中的RDD元素分发到对应的节点u1、u2……um上面。整个过程中,只有events发生了数据混洗,产生了网络通信,而userData?的数据都是在本地引用,不会产生网络传输开销。由此可以看出,Spark通过数据分区,可以大大降低一些特定类型的操作(比如join()、leftOuterJoin()、groupByKey()、reduceByKey()等)的网络传输开销。
2、RDD分区原则
????????RDD分区的一个原则是使得分区的个数尽量等于集群中的CPU核心(core)数目。对于不同的Spark部署模式而言(本地模式、Standalone模式、YARN模式、Mesos模式),都可以通过设置spark.default.parallelism这个参数的值,来配置默认的分区数目,一般而言:
*Local模式:默认为本地机器的CPU数目,若设置了local[N],则默认为N。
*Standalone或YARN:在“集群中所有CPU核心数目总和”和“2”二者中取较大值作为默认值。
*Apache Mesos:默认的分区数为8。
3、设置分区的个数
(1)创建RDD时手动指定分区个数
在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如下: sc.textFile(path, partitionNum)
其中,path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。下面是一个分区实例。
>>> list = [1,2,3,4,5]
>>> rdd = sc.parallelize(list,2) #设置两个分区对于paralelize0而言,如果没有在方法中指定分区数,则默认为spark.default.parallelism。对于textFile()而言,如果没有在方法中指定分区数,则默认为min(defaultParallelism,2),其中,defaultParallelism对应的就是spark.default.parallelism。如果是从HDFS?中读取文件,则分区数为文件分片数(比如,128MB/片)。
(2)使用reparititon方法重新设置分区个数
通过转换操作得到新 RDD 时,直接调用 repartition 方法即可。例如:
>>> data = sc.parallelize([1,2,3,4,5],2)
>>> len(data.glom().collect()) #显示data这个RDD的分区数量
2
>>> rdd = data.repartition(1) #对data这个RDD进行重新分区
>>> len(rdd.glom().collect()) #显示rdd这个RDD的分区数量
14.自定义分区方法
????????Spark提供了自带的HashPartitioner(哈希分区)与RangePartitioner(区域分区),能够满足大多数应用场景的需求。与此同时,Spark也支持自定义分区方式,即通过提供一个自定义的分区函数来控制RDD的分区方式,从而利用领域知识进一步减少通信开销。
实例:根据key值的最后一位数字,写到不同的文件
例如:10写入到part-00000,11写入到part-00001 . . . 19写入到part-00009。
打开一个Linux终端,使用vim编辑器创建一个代码文件“/home/zhc/mycode/TestPartitioner.py”,输入以下代码:
from pyspark import SparkConf, SparkContext
def MyPartitioner(key):
print("MyPartitioner is running")
print('The key is %d' % key)
return key%10
def main():
print("The main function is running")
conf = SparkConf().setMaster("local").setAppName("MyApp")
sc = SparkContext(conf = conf)
data=sc.parallelize(range(10),5)
data.map(lambda x:(x,1)) \
.partitionBy(10,MyPartitioner) \
.map(lambda x:x[0]) \
.saveAsTextFile("file:///usr/local/spark/mycode/rdd/partitioner")
if __name__ == '__main__':
main()
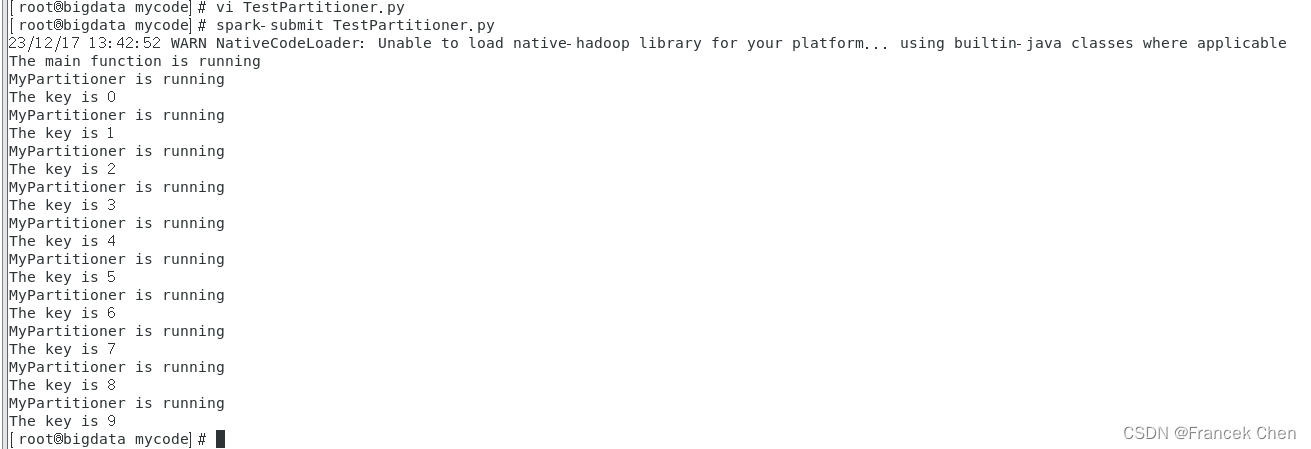
[root@bigdata mycode]# vi TestPartitioner.py
[root@bigdata mycode]# python3 TestPartitioner.py
或者通过spark-submit提交文件:
[root@bigdata mycode]# spark-submit TestPartitioner.py
运行结果:?
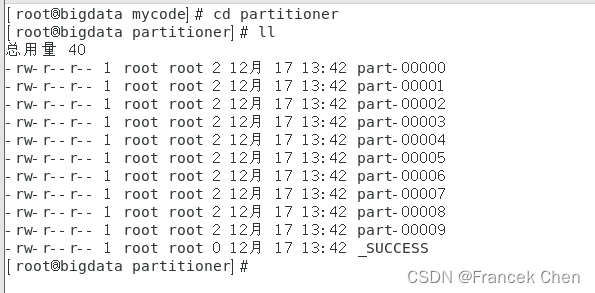
????????运行结束后可以看到,在本地文件系统的“file://home/zhc/mycode/partitioner"目录下面,会生成?part-00000、part-00001、part-00002……part-00009和_SUCCESS等文件。其中,part-00000?文件中包含了数字0,part-00001文件中包含了数字1,?part-00002文件中包含了数字2。
(五)一个综合实例
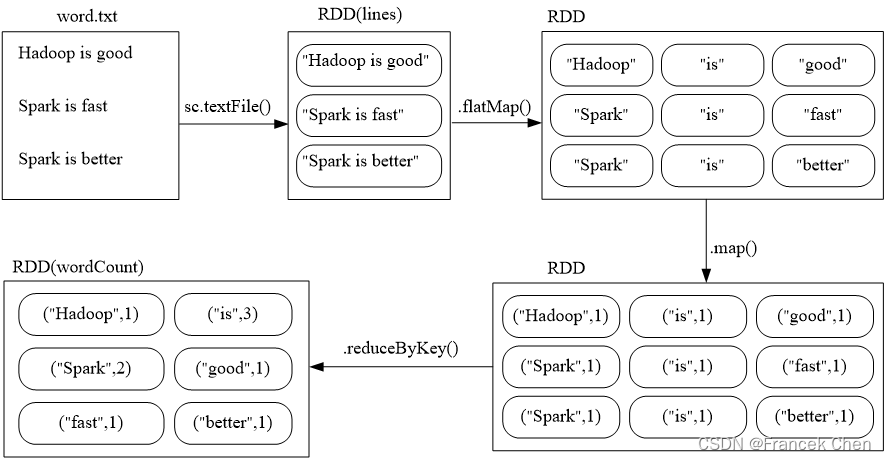
????????假设有一个本地文件word.txt,里面包含了很多行文本,每行文本由多个单词构成,单词之间用空格分隔。可以使用如下语句进行词频统计(即统计每个单词出现的次数):
>>> lines = sc. \
... textFile("file:///home/zhc/mycode/word.txt")
>>> wordCount = lines.flatMap(lambda line:line.split(" ")). \
... map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b)
>>> print(wordCount.collect())
[('good', 1), ('Spark', 2), ('is', 3), ('better', 1), ('Hadoop', 1), ('fast', 1)] ?
?
词频统计执行示意图:?
????????在实际应用中,单词文件可能非常大,会被保存到分布式文件系统HDFS中,Spark和Hadoop会统一部署在一个集群上。
二、键值对RDD
? ? ? ? 键值对RDD(Pair RDD)是指每个 RDD 元素都是(key,value)键值对类型,是一种常见的RDD类型,可以应用于很多应用场景。
(一)键值对RDD的创建
1、第一种创建方式:从文件中加载生成RDD
????????在Linux系统本地文件新建“/home/zhc/mycode/pairrdd/word.txt”,里面包含如下内容:
I love Hadoop
Hadoop is good
Spark is fast
????????首先使用textFile()方法从文件中加载数据,使用map()函数转换得到相应的键值对RDD。
>>> lines = sc.textFile("file:///home/zhc/mycode/pairrdd/word.txt")
>>> pairRDD = lines.flatMap(lambda line:line.split(" ")).map(lambda word:(word,1))
>>> pairRDD.foreach(print)
('Spark', 1)
('I', 1)
('is', 1)
('fast', 1)
('love', 1)
('hadoop', 1)
('Hadoop', 1)
('is', 1)
('good', 1)????????在上述语句中,map(lambda word:(word,1))函数的作用是,取出RDD中的每个元素,也就是每个单词,赋值给word,然后,把word转换成(word,1)的键值对形式。
2、第二种创建方式:通过并行集合(列表)创建RDD
????????下面代码从一个列表创建一个键值对RDD:? ? ? ?
>>> list = ["Hadoop","Spark","Hive","Spark"]
>>> rdd = sc.parallelize(list)
>>> pairRDD = rdd.map(lambda word:(word,1))
>>> pairRDD.foreach(print)
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)(二)常用键值对转换操作
????????常用键值对转换操作包括reduceByKey(func)、groupByKey()、keys、values、sortByKey()、sortBy()、mapValues(func)、join()和combineByKey等。
1、reduceByKey(func)
????????reduceByKey(func)的功能是,使用func函数合并具有相同键的值。
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
>>> pairRDD = sc.parallelize([("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)])
>>> pairRDD.reduceByKey(lambda a,b:a+b).foreach(print)
('Spark', 2)
('Hive', 1)
('Hadoop', 1)
2、groupByKey()
????????groupByKey()的功能是,对具有相同键的值进行分组。比如,对四个键值对("spark",1)、("spark",2)、("hadoop",3)和("hadoop",5),采用groupByKey()后得到的结果是:("spark",(1,2))和("hadoop",(3,5))。
(spark,1)
(spark,2)
(hadoop,3)
(hadoop,5)
>>> list = [("spark",1),("spark",2),("hadoop",3),("hadoop",5)]
>>> pairRDD = sc.parallelize(list)
>>> pairRDD.groupByKey()
PythonRDD[27] at RDD at PythonRDD.scala:48
>>> pairRDD.groupByKey().foreach(print)
('hadoop', <pyspark.resultiterable.ResultIterable object at 0x7f2c1093ecf8>)
('spark', <pyspark.resultiterable.ResultIterable object at 0x7f2c1093ecf8>)
reduceByKey和groupByKey的区别
????????reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。
????????groupByKey也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
>>> words = ["one", "two", "two", "three", "three", "three"]
>>> wordPairsRDD = sc.parallelize(words).map(lambda word:(word, 1))
>>> wordCountsWithReduce = wordPairsRDD.reduceByKey(lambda a,b:a+b)
>>> wordCountsWithReduce.foreach(print)
('one', 1)
('two', 2)
('three', 3)
>>> wordCountsWithGroup = wordPairsRDD.groupByKey(). \
... map(lambda t:(t[0],sum(t[1])))
>>> wordCountsWithGroup.foreach(print)
('two', 2)
('three', 3)
('one', 1)
???????上面得到的wordCountsWithReduce和wordCountsWithGroup是完全一样的,但是,它们的内部运算过程是不同的。
3、keys
????????keys只会把Pair RDD中的key返回形成一个新的RDD。
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
>>> list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
>>> pairRDD = sc.parallelize(list)
>>> pairRDD.keys().foreach(print)
Hadoop
Spark
Hive
Spark
4、values
????????values只会把Pair RDD中的value返回形成一个新的RDD。
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
>>> list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
>>> pairRDD = sc.parallelize(list)
>>> pairRDD.values().foreach(print)
1
1
1
1
5、sortByKey()
????????sortByKey()的功能是返回一个根据键排序的RDD。
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
>>> list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
>>> pairRDD = sc.parallelize(list)
>>> pairRDD.foreach(print)
('Hadoop', 1)
('Spark', 1)
('Hive', 1)
('Spark', 1)
>>> pairRDD.sortByKey().foreach(print)
('Hadoop', 1)
('Hive', 1)
('Spark', 1)
('Spark', 1)
6、sortBy()
????????sortBy()可以根据其他字段进行排序。
>>> d1 = sc.parallelize([("c",8),("b",25),("c",17),("a",42), \
... ("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9)])
>>> d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x,False).collect()
[('g', 21), ('f', 29), ('e', 17), ('d', 9), ('c', 27), ('b', 38), ('a', 42)]
>>> d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[0],False).collect()
[('g', 21), ('f', 29), ('e', 17), ('d', 9), ('c', 27), ('b', 38), ('a', 42)]
>>> d1.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[1],False).collect()
[('a', 42), ('b', 38), ('f', 29), ('c', 27), ('g', 21), ('e', 17), ('d', 9)]
????????在上述语句中,?sortBy(lambda?x:x[1],False)中的"x[1]”表示每个键值对RDD元素的value,也就是根据value来排序,False表示按照降序排序。
与sortByKey()对比:
>>> d1 = sc.parallelize([("c",8),("b",25),("c",17),("a",42), \
... ("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9)])
>>> d1.reduceByKey(lambda a,b:a+b).sortByKey(False).collect()
[('g', 21), ('f', 29), ('e', 17), ('d', 9), ('c', 27), ('b', 38), ('a', 42)]
????????sortByKey(False)括号中的参数False表示按照降序排序,如果没有提供参数False,则默认采用升序排序(即参数取值为True)。从排序后的效果可以看出,所有键值对都按照key的降序进行了排序,因此输出[(g,?21),(f,29),?(e',17),(d,?9),(c,27),(b,38),(a',?42)]。
????????但是,如果要根据21、29、17等数值进行排序,就无法直接使用sortByKey0来实现,这时可以使用sortBy()。
7、mapValues(func)
????????对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化。
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
>>> list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)]
>>> pairRDD = sc.parallelize(list)
>>> pairRDD1 = pairRDD.mapValues(lambda x:x+1)
>>> pairRDD1.foreach(print)
('Hadoop', 2)
('Spark', 2)
('Hive', 2)
('Spark', 2)
8、join()
????????join就表示内连接。对于内连接,对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集。
>>> pairRDD1 = sc. \
... parallelize([("spark",1),("spark",2),("hadoop",3),("hadoop",5)])
>>> pairRDD2 = sc.parallelize([("spark","fast")])
>>> pairRDD3 = pairRDD1.join(pairRDD2)
>>> pairRDD3.foreach(print)
('spark', (1, 'fast'))
('spark', (2, 'fast'))
? ? ? ? 从上述代码及其执行结果可以看出,pairRDD1中的键值对("spark",1)和pairRDD2中的键值对("spark","fast"),因为二者具有相同的key(即"spark"),所以会产生连接结果("spark",(1,"fast"))。
9、combineByKey
? ? ? ? 创建一个代码文件“/home/zhc/mycode/Combine.py”,并输入如下代码:
#/home/zhc/mycode/Combine.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("Combine ")
sc = SparkContext(conf = conf)
data=sc.parallelize([("company-1",88),("company-1",96),("company-1",85), \
("company-2",94),("company-2",86),("company-2",74),("company-3",86), \
("company-3",88),("company-3",92)],3)
res = data.combineByKey(\
lambda income:(income,1),\
lambda acc,income:(acc[0]+income, acc[1]+1),\
lambda acc1,acc2:(acc1[0]+acc2[0],acc1[1]+acc2[1])). \
map(lambda x:(x[0],x[1][0],x[1][0]/float(x[1][1])))
res.repartition(1).saveAsTextFile("file:///home/zhc/mycode/combineresult")
执行如下命令运行该程序:
[root@bigdata mycode]# spark-submit Combine.py
23/12/17 16:14:25 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable执行后,在“file:///home/zhc/mycode/combineresult”目录下查看part-00000文件。
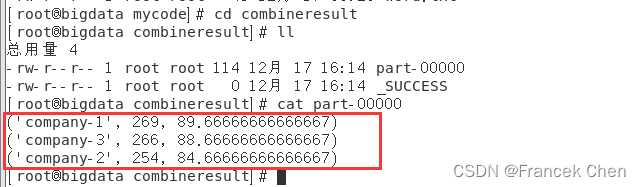
(三)一个综合实例
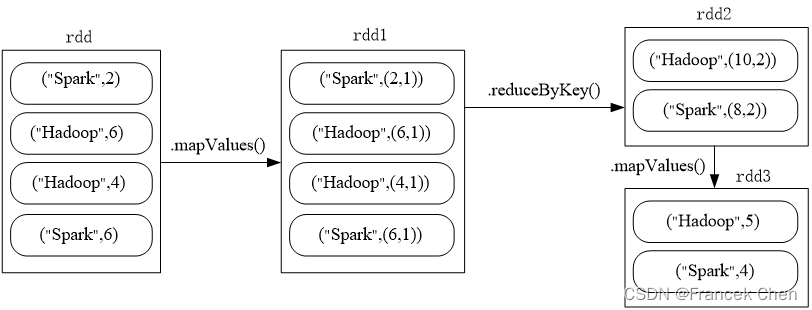
题目:给定一组键值对("spark",2),("hadoop",6),("hadoop",4),("spark",6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
>>> rdd = sc.parallelize([("spark",2),("hadoop",6),("hadoop",4),("spark",6)])
>>> rdd.mapValues(lambda x:(x,1)).\
... reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])).\
... mapValues(lambda x:x[0]/x[1]).collect()
[('hadoop', 5.0), ('spark', 4.0)]
三、数据读写
介绍在RDD编程中如何进行文件数据读写和HBase数据读写。
(一)文件数据读写
1、本地文件系统的数据读写
(1)从文件中读取数据创建RDD
"file:///home/zhc/mycode/word.txt"文件内容如下:
Hadoop is good
Spark is better
Spark is fast
>>> textFile = sc.textFile("file:///home/zhc/mycode/word.txt")
>>> textFile.first()
'Hadoop is good'
????????因为Spark采用了惰性机制,在执行转换操作的时候,即使输入了错误的语句,spark-shell也不会马上报错(假设word123.txt不存在)。只有当后面继续执行textFile.first()操作时,系统才会报错。
>>> textFile = sc.textFile("file:///home/zhc/mycode/word123.txt")(2)把RDD写入到文本文件中
>>> textFile = sc.textFile("file:///home/zhc/mycode/word.txt")
>>> textFile.saveAsTextFile("file:///home/zhc/mycode/writeback")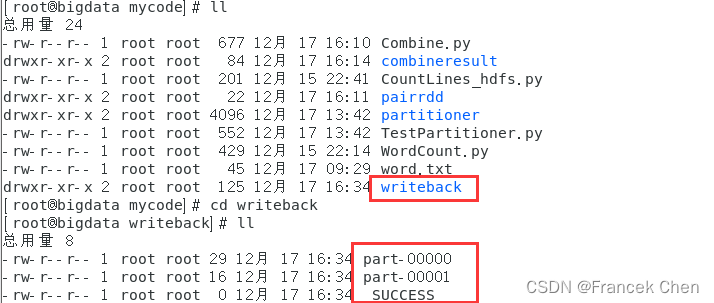
2、分布式文件系统HDFS的数据读写
????????从分布式文件系统HDFS中读取数据,也是采用textFile()方法,可以为textFile()方法提供一个HDFS文件或目录地址,如果是一个文件地址,它会加载该文件,如果是一个目录地址,它会加载该目录下的所有文件的数据。具体语句如下:
>>> textFile = sc.textFile("hdfs://localhost:9000/user/zhc/word.txt")
>>> textFile.first()如下三条语句都是等价的:
>>> textFile = sc.textFile("hdfs://localhost:9000/user/zhc/word.txt")
>>> textFile = sc.textFile("/user/zhc/word.txt")
>>> textFile = sc.textFile("word.txt")同样,可以使用saveAsTextFile()方法把RDD中的数据保存到HDFS文件中,命令如下:
>>> textFile = sc.textFile("word.txt")
>>> textFile.saveAsTextFile("writeback")
(二)读写HBase数据
Hbase的下载安装与配置可以参照博客:
大数据存储技术(3)—— HBase分布式数据库-CSDN博客![]() https://blog.csdn.net/Morse_Chen/article/details/1350362961、创建一个HBase表
https://blog.csdn.net/Morse_Chen/article/details/1350362961、创建一个HBase表
????????因为HBase是伪分布式模式,需要调用HDFS,所以,请首先在终端中输入下面命令启动Hadoop:
[root@bigdata zhc]# start-dfs.sh
? ? ? ? 然后,执行命令启动HBase:
[root@bigdata zhc]# start-hbase.sh
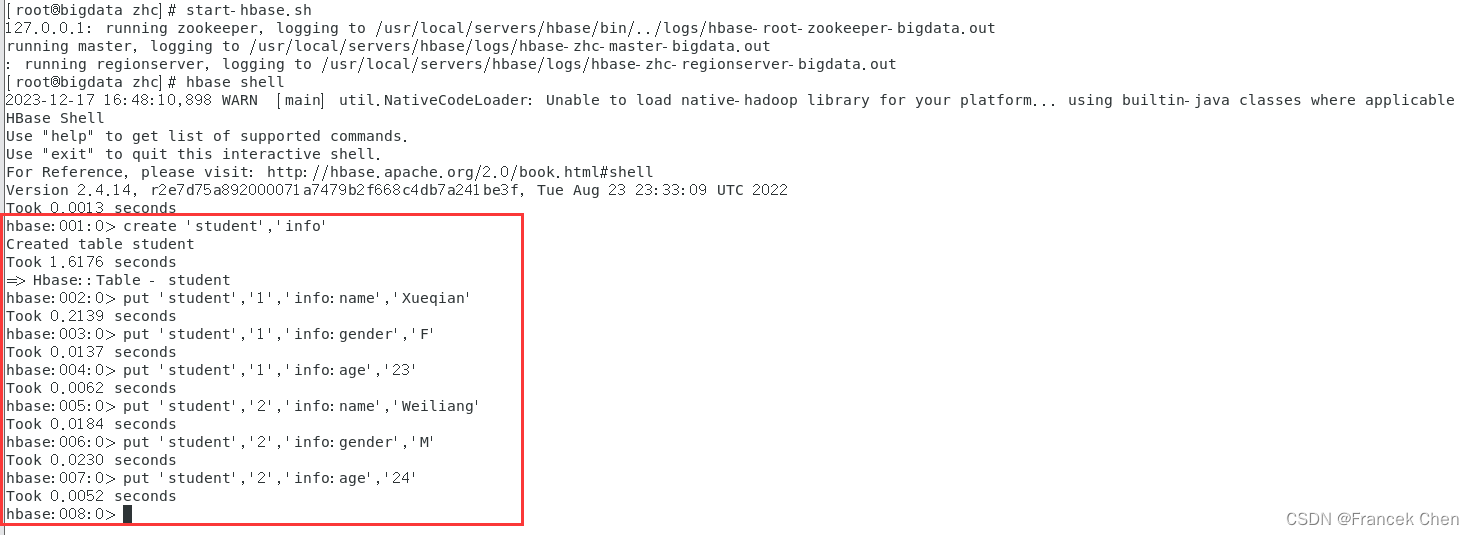
[root@bigdata zhc]# hbase shell
????????其次,创建一个student表,在这个表中录入数据。

hbase> create 'student','info'
hbase> put 'student','1','info:name','Xueqian'
hbase> put 'student','1','info:gender','F'
hbase> put 'student','1','info:age','23'
hbase> put 'student','2','info:name','Weiliang'
hbase> put 'student','2','info:gender','M'
hbase> put 'student','2','info:age','24'
录入结束后,可以执行如下命令查看已经录入的数据:
hbase> get 'student','1' # 查看第一行数据
hbase> scan 'student' # 查看全部数据
2、配置Spark
参考博客:三、(三)配置Spark
大数据存储技术(3)—— HBase分布式数据库-CSDN博客![]() https://blog.csdn.net/Morse_Chen/article/details/1350362963、编写程序读取HBase数据
https://blog.csdn.net/Morse_Chen/article/details/1350362963、编写程序读取HBase数据
????????如果要让Spark读取HBase,就需要使用SparkContext提供的newAPIHadoopRDD这个API将表的内容以RDD的形式加载到Spark中。
在“/home/zhc/mycode/RDD/SparkOperateHBase.py”文件中输入:
#/home/zhc/mycode/RDD/SparkOperateHBase.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("ReadHBase")
sc = SparkContext(conf = conf)
host = 'localhost'
table = 'student'
conf = {"hbase.zookeeper.quorum": host, "hbase.mapreduce.inputtable": table}
keyConv = "org.apache.spark.examples.pythonconverters.ImmutableBytesWritableToStringConverter"
valueConv = "org.apache.spark.examples.pythonconverters.HBaseResultToStringConverter"
hbase_rdd = sc.newAPIHadoopRDD("org.apache.hadoop.hbase.mapreduce.TableInputFormat","org.apache.hadoop.hbase.io.ImmutableBytesWritable","org.apache.hadoop.hbase.client.Result",keyConverter=keyConv,valueConverter=valueConv,conf=conf)
count = hbase_rdd.count()
hbase_rdd.cache()
output = hbase_rdd.collect()
for (k, v) in output:
print (k, v)
执行该代码,命令如下:
[root@bigdata RDD]# vi SparkOperateHBase.py
[root@bigdata RDD]# spark-submit SparkOperateHBase.py 得到如下结果:?

4、编写程序向HBase写入数据

在“/home/zhc/mycode/RDD/SparkWriteHBase.py”文件中输入:
#/home/zhc/mycode/RDD/SparkWriteHBase.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("ReadHBase")
sc = SparkContext(conf = conf)
host = 'localhost'
table = 'student'
keyConv = "org.apache.spark.examples.pythonconverters.StringToImmutableBytesWritableConverter"
valueConv = "org.apache.spark.examples.pythonconverters.StringListToPutConverter"
conf = {"hbase.zookeeper.quorum": host,"hbase.mapred.outputtable": table,"mapreduce.outputformat.class": "org.apache.hadoop.hbase.mapreduce.TableOutputFormat","mapreduce.job.output.key.class": "org.apache.hadoop.hbase.io.ImmutableBytesWritable","mapreduce.job.output.value.class": "org.apache.hadoop.io.Writable"}
rawData = ['5,info,name,Rongcheng','5,info,gender,M','5,info,age,26','6,info,name,Guanhua','6,info,gender,M','6,info,age,27']
sc.parallelize(rawData).map(lambda x: (x[0],x.split(','))).saveAsNewAPIHadoopDataset(conf=conf,keyConverter=keyConv,valueConverter=valueConv)
执行该代码,命令如下:
[root@bigdata RDD]# vi SparkWriteHBase.py
[root@bigdata RDD]# spark-submit SparkWriteHBase.py得到如下结果:
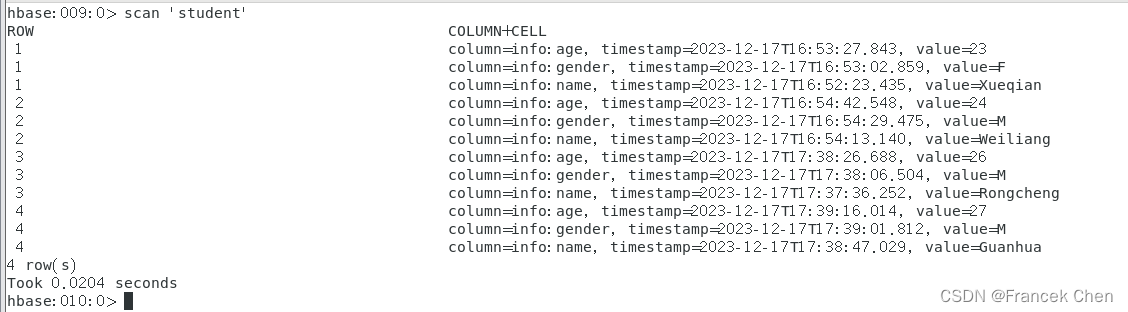
?
最后友情提醒:使用完HBase和Hadoop后,要先关闭HBase,再关闭Hadoop!?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!