self-attention机制详解
目前,对于我们的network,给定的input大都是一个向量:
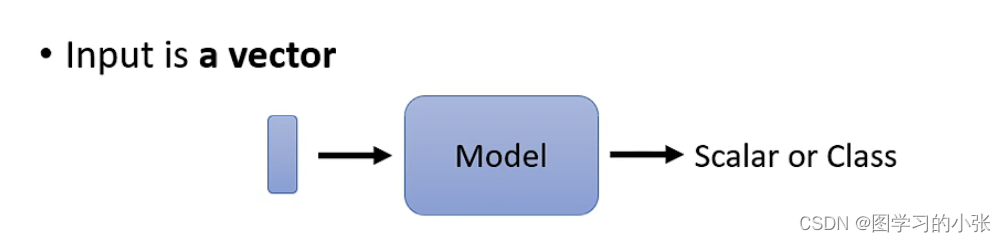
但是对于更复杂的情况,我们的input是a set of vec:
举例:
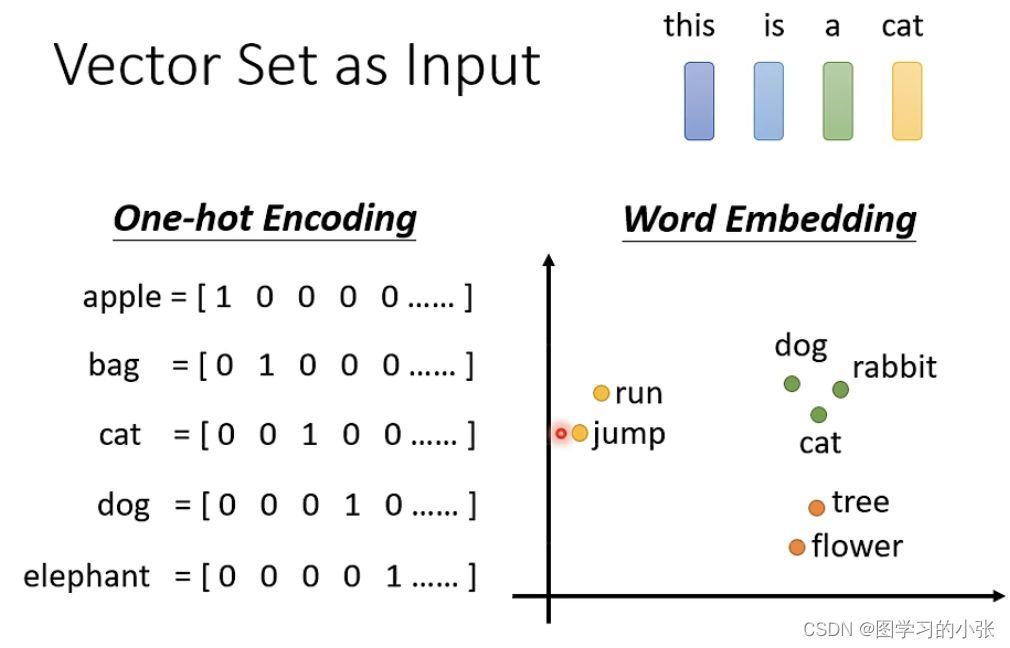
nlp中的句子,对于每个word都是一个word embedding:
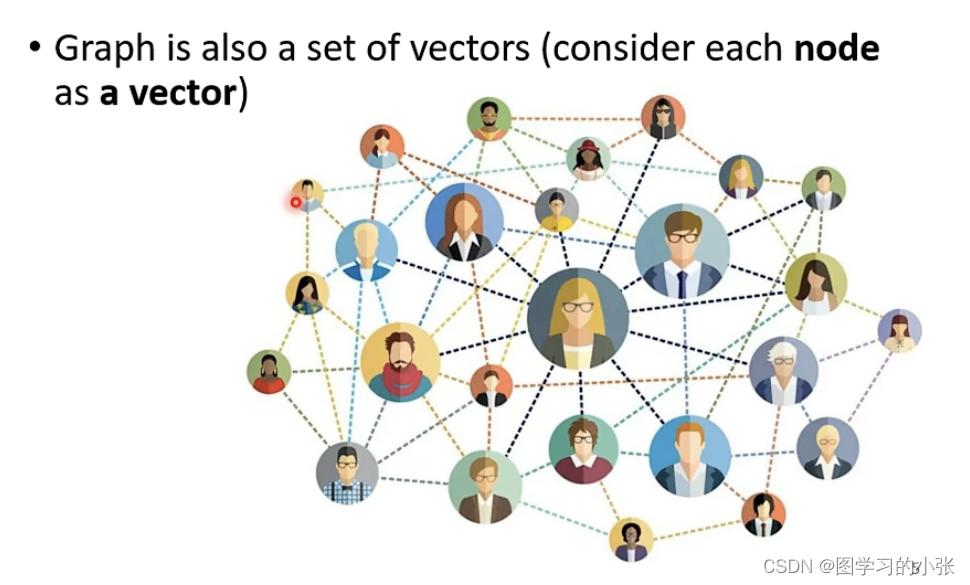
图学习中每个节点有一个embedding:
 那我们的output都是什么样子呢?
那我们的output都是什么样子呢?
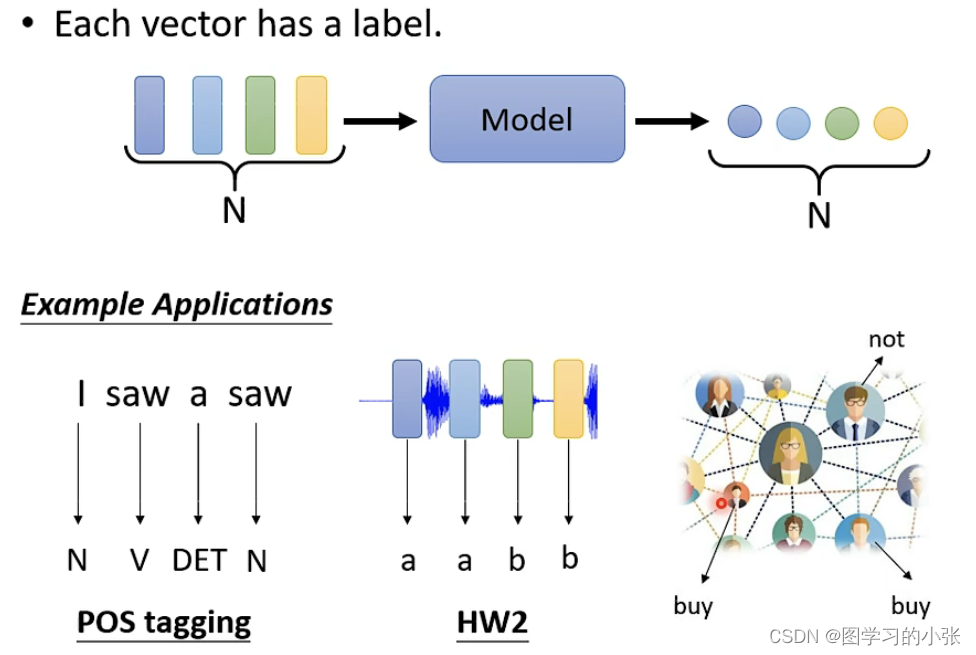
第一种:输入与输出数量相同,每个embedding都有一个label(sequence labeling):
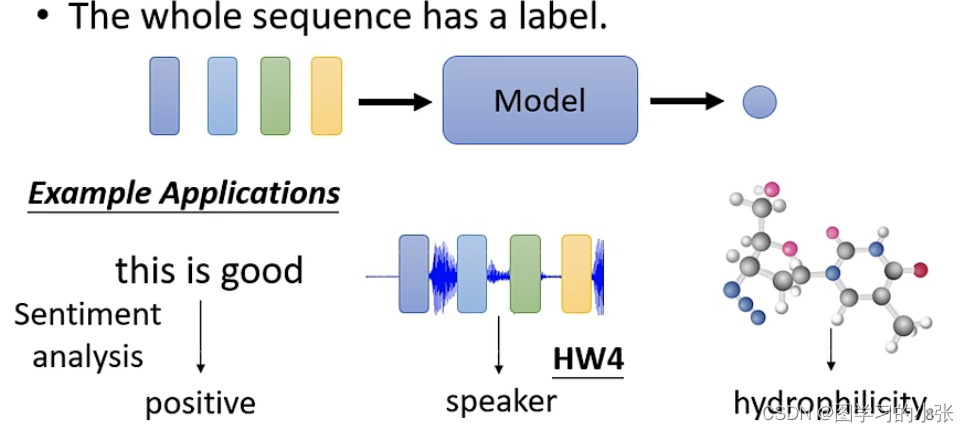
第二种:整个输入有一个label:
 第三种:model自己决定有多少长度的输出(seq2seq):
第三种:model自己决定有多少长度的输出(seq2seq):

对于第一种问题,假设我们要进行的是预测词性的任务,即:
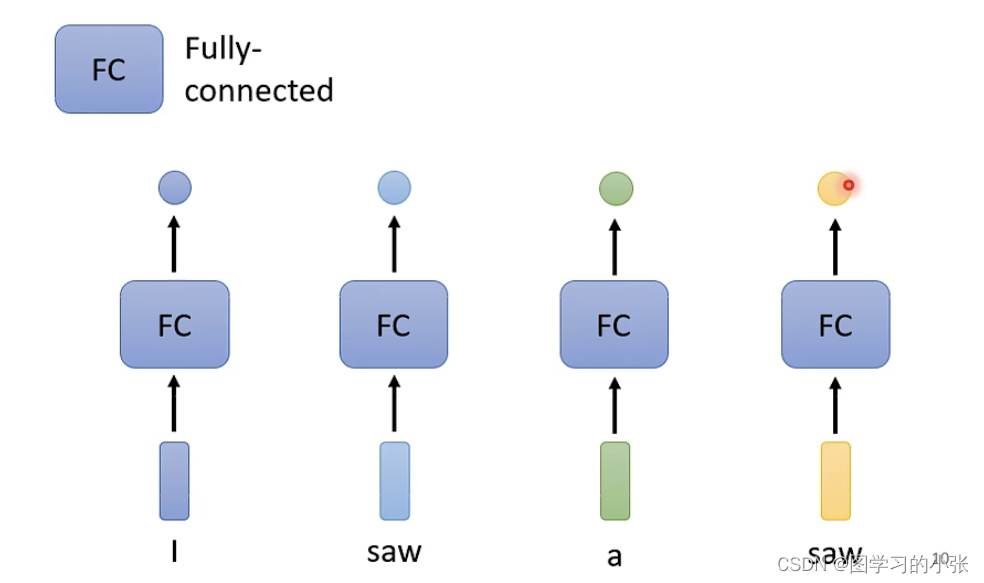 只用每个word embedding加一个fc是不行的,model无法对第二个和第四个saw预测出不同的词性,那么我们就需要consider the context,这就是self-attention的作用:
只用每个word embedding加一个fc是不行的,model无法对第二个和第四个saw预测出不同的词性,那么我们就需要consider the context,这就是self-attention的作用:
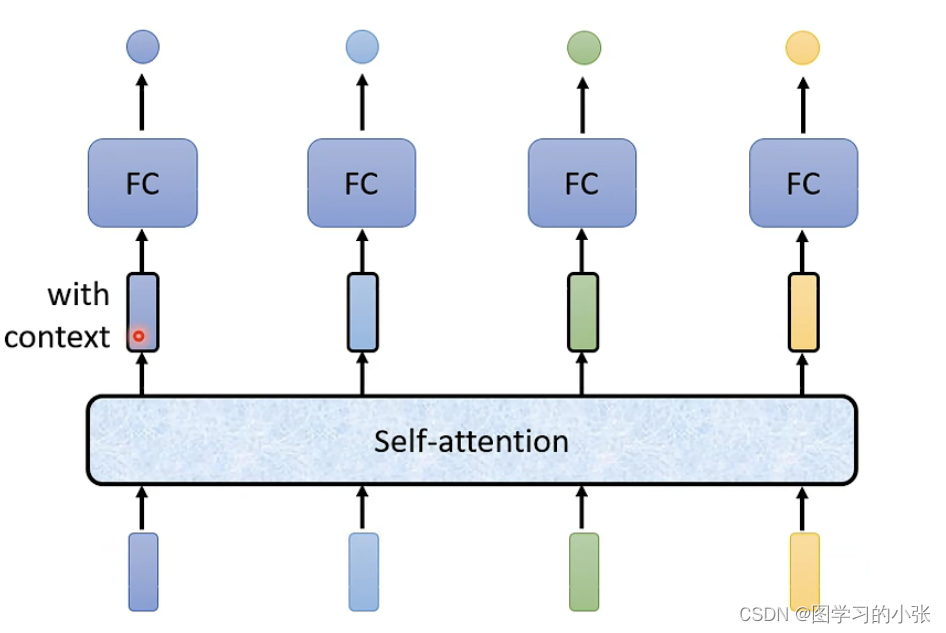 经过self-attention后生成的新的word enbedding就包含了整个context的信息,也可以使用多个attention层叠加:
经过self-attention后生成的新的word enbedding就包含了整个context的信息,也可以使用多个attention层叠加:
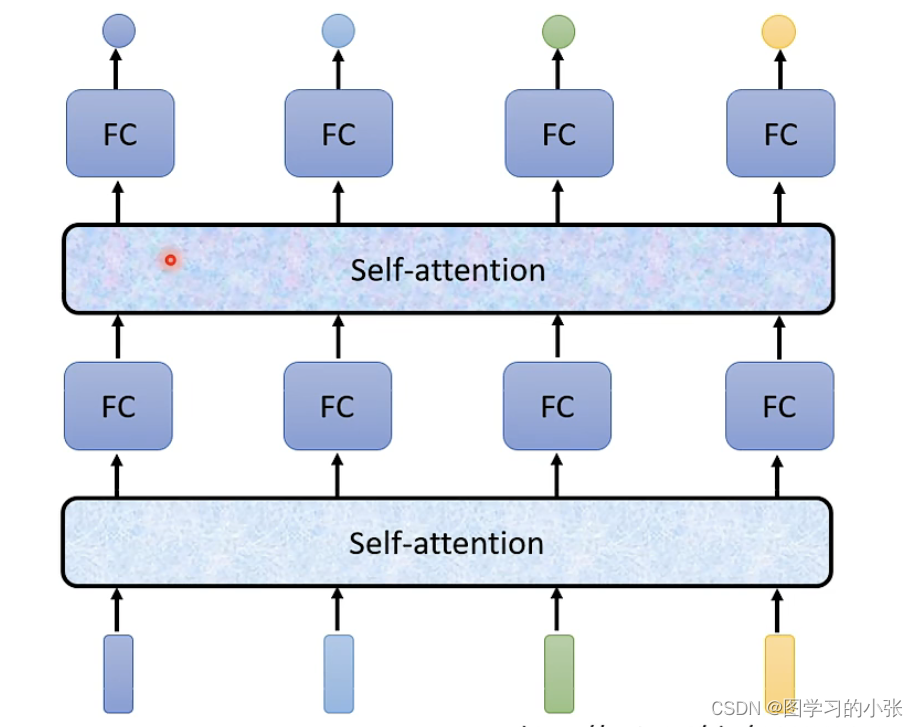 最出名的一篇文章:Attention is all you need,在这篇文章里谷歌提出了Transformer,这个后面再谈,我们先来看看attention的运作方式。
最出名的一篇文章:Attention is all you need,在这篇文章里谷歌提出了Transformer,这个后面再谈,我们先来看看attention的运作方式。
实现对整个context的关注,最简单的想法就是把他们全连接起来:
 但是,对于a1生成b1来说,我们不能直接融合所有的embedding,我们的模型应该可以找到a这一层其他的向量哪些对a1是相关的、重要的,可以帮助判断a1类型的embedding,那么,对a1和每一个em的相关性,用一个α表示:
但是,对于a1生成b1来说,我们不能直接融合所有的embedding,我们的模型应该可以找到a这一层其他的向量哪些对a1是相关的、重要的,可以帮助判断a1类型的embedding,那么,对a1和每一个em的相关性,用一个α表示:
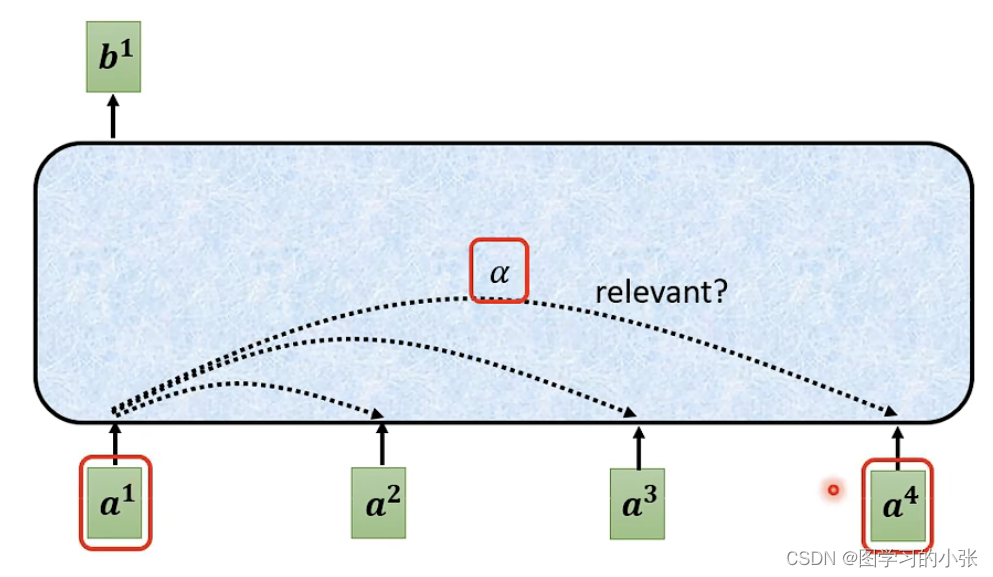 那么我们的attention模型,就需要可以计算出每两个向量之间的α,常用的方法:
那么我们的attention模型,就需要可以计算出每两个向量之间的α,常用的方法:
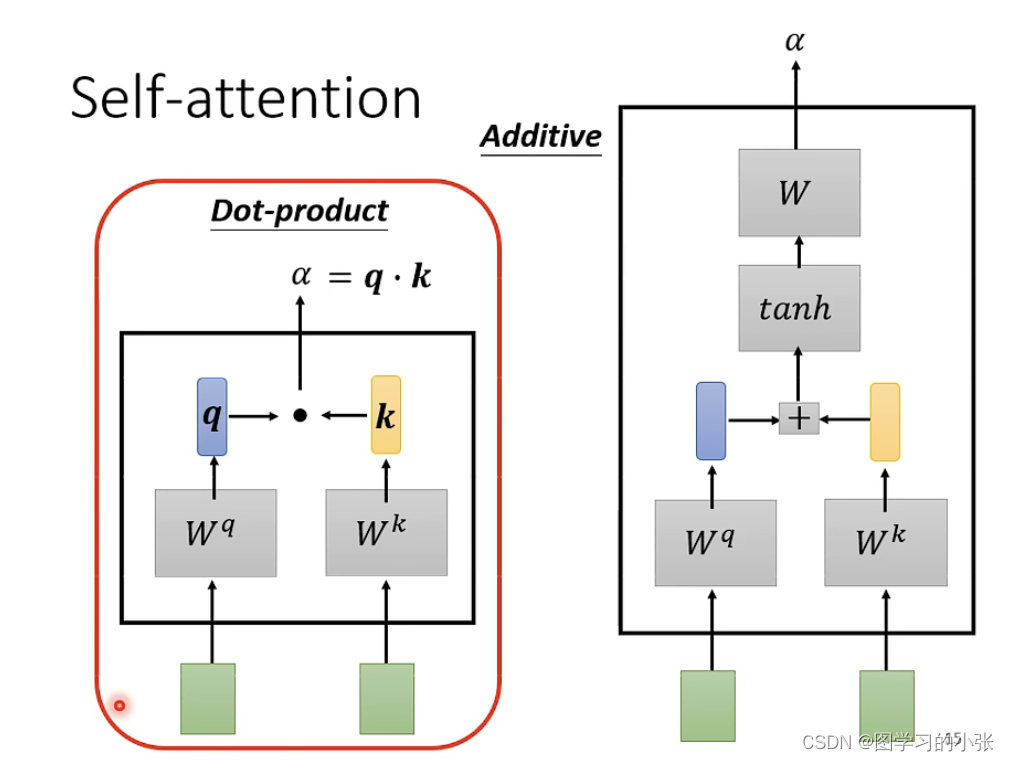 Dot-product是目前最常用的方法,也是transformer中的方法,那么在attention中就是这样的:
Dot-product是目前最常用的方法,也是transformer中的方法,那么在attention中就是这样的:
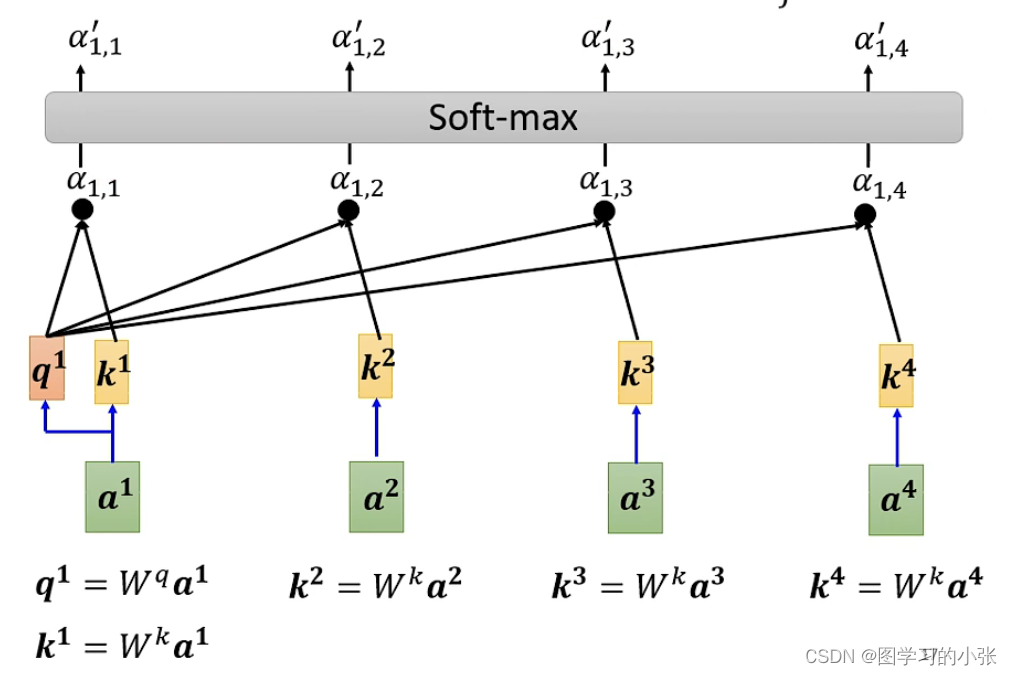 如图计算a1与所有向量的α,用的都是Dot-product的方法,再过一层softmax,生成a1对每个向量的注意力。
如图计算a1与所有向量的α,用的都是Dot-product的方法,再过一层softmax,生成a1对每个向量的注意力。
得到α后,我们已经知道a1和哪些向量是最有关联性性的,那么下一步就是根据α抽取信息,即:
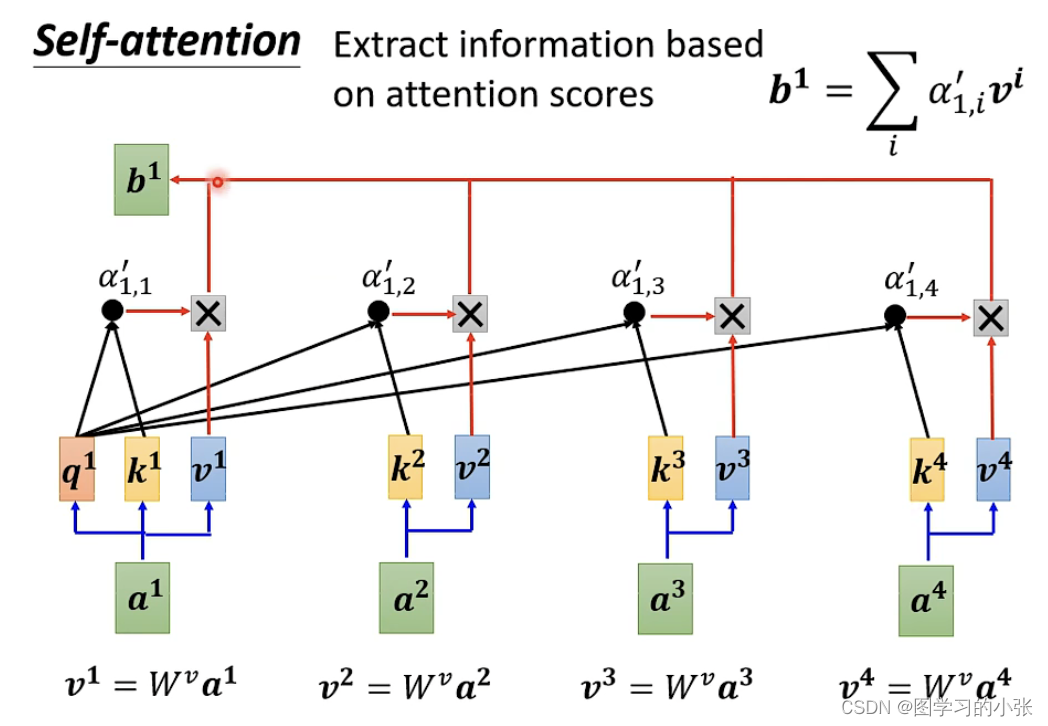 最终得到b1,就是融合了attention信息的新的表示,对于每一个向量我们都进行同样的操作,这个操作是同时进行的。
最终得到b1,就是融合了attention信息的新的表示,对于每一个向量我们都进行同样的操作,这个操作是同时进行的。
公式推导有空再写。
笔记整理自台大李宏毅自注意力机制和Transformer详解
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!