【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行环境搭建
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 概述-CSDN博客
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行环境搭建-CSDN博客
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行模式-CSDN博客
1、模板虚拟机环境准备
1.1、?hadoop100 虚拟机配置要求如下
(1)使用 yum 安装需要虚拟机可以正常上网,yum 安装前可以先测试下虚拟机联网情况
[root@hadoop100 ~]# ping www.baidu.com(2)安装epel-release
[root@hadoop100 ~]# yum install -y epel-release(3)注意:如果Linux 安装的是最小系统版,还需要安装如下工具;如果安装的是Linux桌面标准版,不需要执行如下操作
net-tool:工具包集合,包含ifconfig 等命令
vim:编辑器
[root@hadoop100 ~]# yum install -y net-tools
[root@hadoop100 ~]# yum install -y vim1.2、 关闭防火墙,关闭防火墙开机自启
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld.service1.3、?创建普通用户,并修改普通用户的密码
[root@hadoop100 ~]# useradd Tom
[root@hadoop100 ~]# passwd Tom1.4、?配置普通用户具有 root 权限,方便后期加sudo 执行 root 权限的命令
[root@hadoop100 ~]# vim /etc/sudoers修改/etc/sudoers 文件,在%wheel 这行下面添加一行,如下所示:
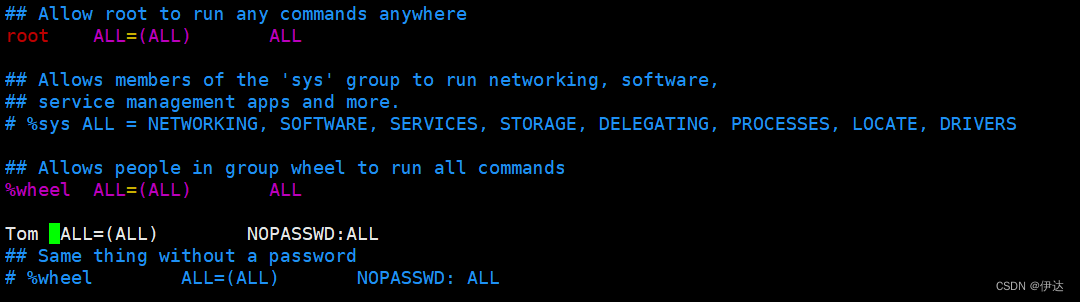
注意:Tom这一行不要直接放到 root行下面,因为所有用户都属于 wheel组,你先配置了Tom具有免密功能,但是程序执行到 %wheel行时, 该功能又被覆盖回需要密码 。所以Tom要放到 %wheel这行下面。
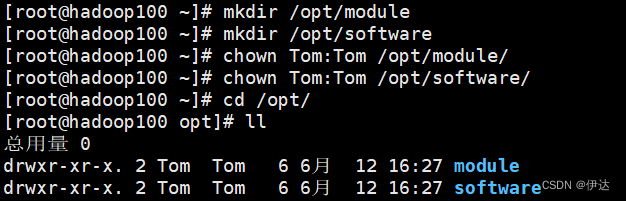
2.1.5 在 /opt目录下创建文件夹 ,并修改所属用户和所属组
2.1.6 卸载虚拟机自带的 JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodepsrpm -qa:查询所安装的所有rpm软件包
grep -i:忽略大小写
xargs -n1:表示每次只传递一个参数
rpm -e --nodeps:强制卸载软件
注意:注意:如果你的虚拟机是最小化安装不需要执行这一步。
1.7|?重启虚拟机
[root@hadoop100 ~]# reboot
2.2 克隆虚拟机
2.1、 利用模板机 hadoop100,克隆 三台虚拟机 hadoop102 hadoop103 hadoop104
注意:克隆时,要先关闭 hadoop100
2.2、 修改克隆机 IP,以 hadoop102 举例说明
(1)修改克隆虚拟机的静态 IP:
[Tom@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 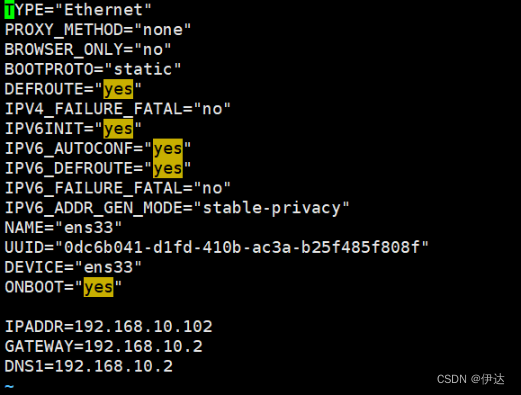
(2)查看 Linux虚拟机的虚拟网络编辑器,编辑 ->虚拟网络编辑器 ->VMnet8
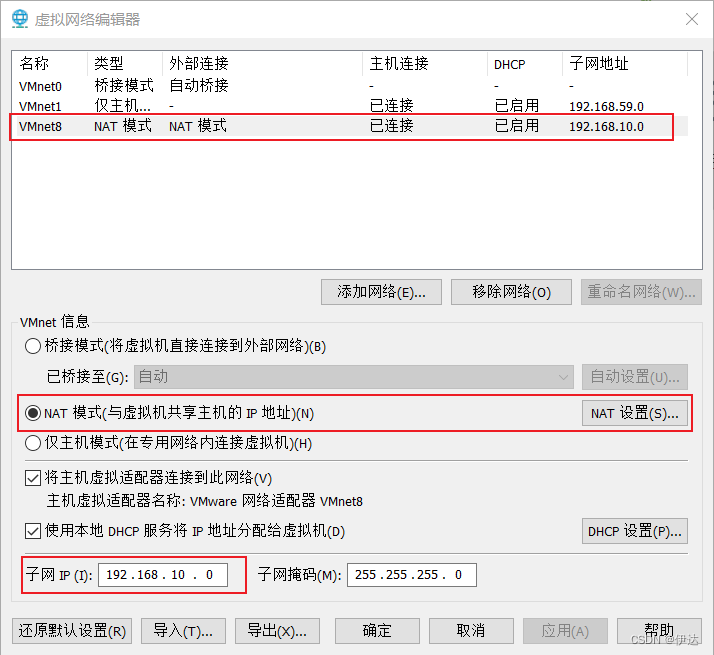
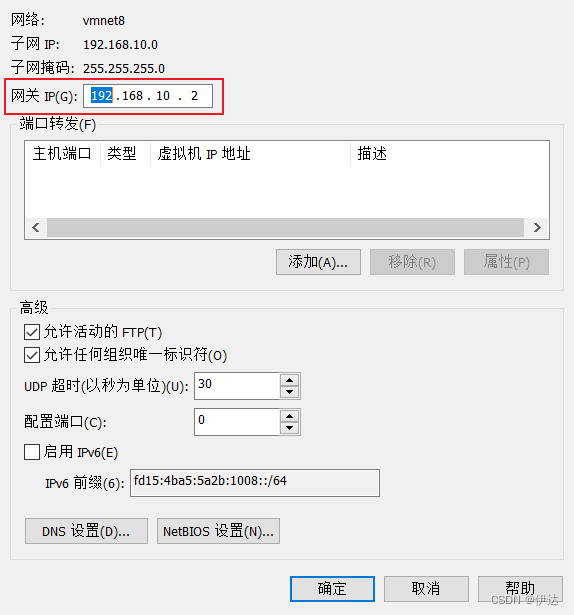
(3)查看 Windows系统适配器 VMware Network Adapter VMnet8的 IP地址
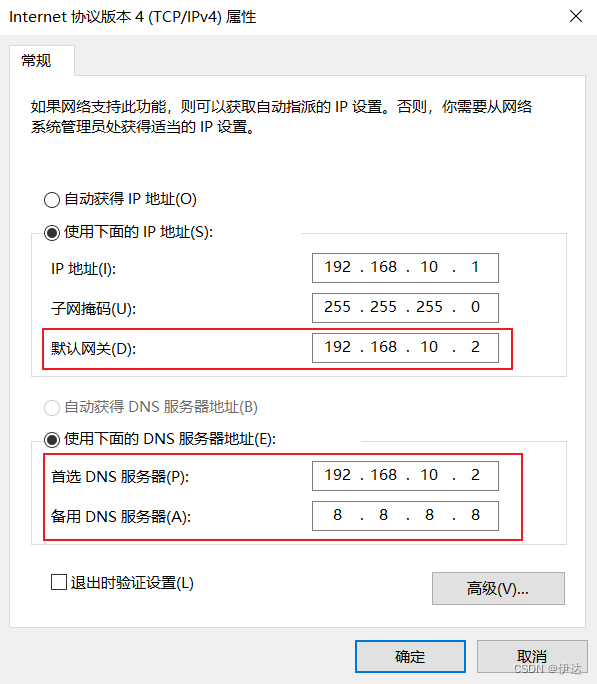
(4)保证 Linux系统 ifcfg-ens33文件中 IP地址、虚拟网络编辑器地址和 Windows系统 VMnet8网络 IP地址相同。
2.3、 修改克隆机主机名 ,以 hadoop102举例说明
(1)修改主机名称
[root@hadoop100 ~]# vim /etc/hostname (2)配置 Linux克隆机主机名称映射 hosts文件 打开 /etc/hosts
[root@hadoop100 ~]# vim /etc/hosts2.4、 重启克隆机 hadoop102
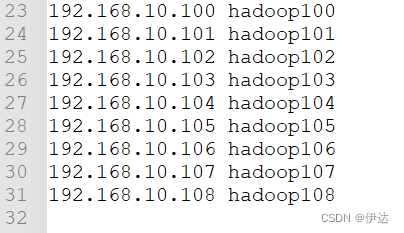
[root@hadoop100 ~]# reboot2.5、 修改 windows的主机映射文件(hosts文件)
进入C:\Windows\System32\drivers\etc路径,打开 hosts文件并添加如下内容 ,然后保存。
3、 在 hadoop102 安装 JDK
3.1、卸载现有 JDK
注意:安装 JDK前,一定确保提前删除了虚拟机自带的 JDK。
3.2、用 XShell传输工具将 JDK导入到 opt目录下面的 software文件夹下面
3.3、在 Linux系统下的 opt目录中查看软件包是否导入成功
[Tom@hadoop102 ~]$ ls /opt/software/
jdk-8u212-linux-x64.tar.gz3.4、解压 JDK到 /opt/module目录下
[Tom@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/3.5、配置 JDK环境变量
[Tom@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh?
source一下 /etc/profile文件 ,让新的环境变量 PATH生效
[Tom@hadoop102 software]$ source /etc/profile测试JDK是否安装成功
[Tom@hadoop102 software]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[Tom@hadoop102 software]$?4、 在 hadoop102 安装 Hadoop
4.1、用 XShell文件传输 工具将 hadoop-3.1.3.tar.gz导入到 opt目录下面的 software文件夹下面
4.2、解压安装文件到 /opt/module下面
[Tom@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/4.3、查看是否解压成功
[Tom@hadoop102 software]$ ls /opt/module/
hadoop-3.1.3 ?jdk1.8.0_2124.4、将 Hadoop添加到环境变量
[Tom@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh?
让修改后的文件生效
[Tom@hadoop102 software]$ source /etc/profile4.5、测试是否安装成功
[Tom@hadoop102 software]$ hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
[Tom@hadoop102 software]$?
4.6、重启 如果 Hadoop命令不能用再重启虚拟机
[Tom@hadoop102 hadoop-3.1.3]$ sudo reboot5、 Hadoop 目录结构
查看 Hadoop目录结构
[Tom@hadoop102 hadoop-3.1.3]$ ll
总用量 184
-rw-rw-r--. 1 Tom Tom ? ? 25 5月 ?28 16:49 a.txt
drwxr-xr-x. 2 Tom Tom ? ?183 9月 ?12 2019 bin
drwxrwxr-x. 4 Tom Tom ? ? 37 5月 ?29 10:54 data
drwxr-xr-x. 3 Tom Tom ? ? 20 9月 ?12 2019 etc
drwxrwxr-x. 3 Tom Tom ? ? 18 5月 ?29 10:53 hdfsdata
drwxr-xr-x. 2 Tom Tom ? ?106 9月 ?12 2019 include
drwxr-xr-x. 3 Tom Tom ? ? 20 9月 ?12 2019 lib
drwxr-xr-x. 4 Tom Tom ? ?288 9月 ?12 2019 libexec
-rw-rw-r--. 1 Tom Tom 147145 9月 ? 4 2019 LICENSE.txt
drwxrwxr-x. 3 Tom Tom ? 4096 5月 ?29 15:36 logs
-rw-rw-r--. 1 Tom Tom ?21867 9月 ? 4 2019 NOTICE.txt
-rw-rw-r--. 1 Tom Tom ? 1366 9月 ? 4 2019 README.txt
drwxr-xr-x. 3 Tom Tom ? 4096 9月 ?12 2019 sbin
drwxr-xr-x. 4 Tom Tom ? ? 31 9月 ?12 2019 share
drwxrwxr-x. 2 Tom Tom ? ? 22 5月 ? 6 22:23 wcinput
[Tom@hadoop102 hadoop-3.1.3]$?重要目录
(1) bin目录:存放对 Hadoop相关服务( hdfs yarn mapred)进行操作的脚本
(2) etc目录: Hadoop的配置文件目录,存放 Hadoop的配置文件
(3) lib目录:存放 Hadoop的本地库(对数据进行压缩解压缩功能)
(4) sbin目录:存放启动或停止 Hadoop相关服务的脚本
(5) share目录:存放 Hadoop的依赖 jar包 、文档和官方案例
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!