TiDB SQL调优案例TiFlash
背景
早上收到某系统的告警tidb节点挂掉无法访问,情况十万火急。登录中控机查了一下display信息,4个TiDB、Prometheus、Grafana全挂了,某台机器hang死无法连接,经过快速重启后集群恢复,经排查后是昨天上线的某个SQL导致频繁OOM。
于是开始亡羊补牢,来一波近期慢SQL巡检 #手动狗头#。。。
随便找了一个出现频率比较高的慢SQL,经过优化后竟然性能提升了1500倍以上,感觉有点东西,分享给大家。
分析过程
该慢SQL逻辑非常简单,就是一个单表聚合查询,但是耗时达到8s以上,必有蹊跷。
脱敏后的SQL如下:
SELECT
cast( cast( CAST( SUM( num ) / COUNT( time ) AS CHAR ) AS DECIMAL ( 9, 2 )) AS signed ) speed,
... -- 此处省略n个字段
FROM
(
SELECT
DATE_FORMAT( receive_time, '%Y-%m-%d %H:%i:00' ) AS time,
COUNT(*) AS num
FROM
db1.table
WHERE
create_time > DATE_SUB( sysdate(), INTERVAL 20 MINUTE )
GROUP BY
time
ORDER BY
time
) speed;
碰到慢SQL不用多想,第一步先上执行计划:
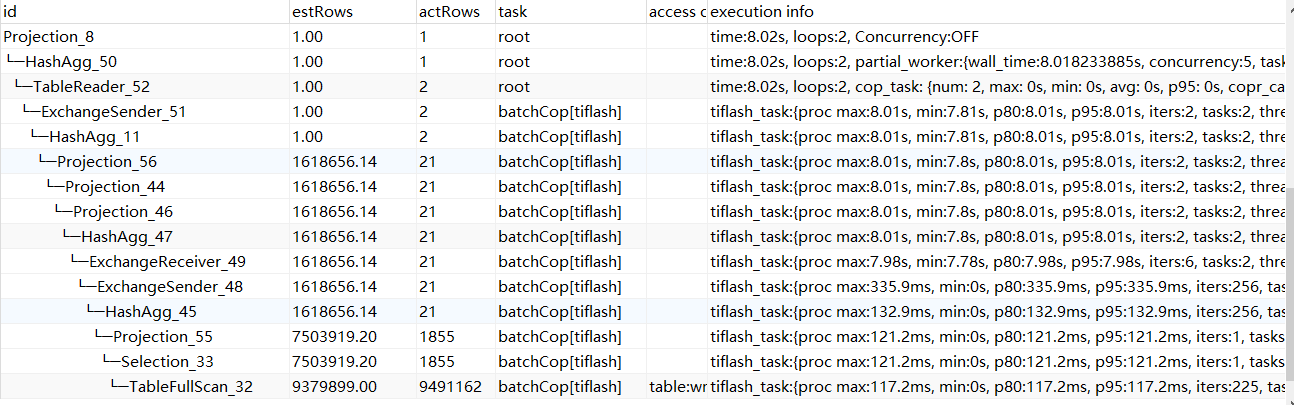
很明显,这张900多万行的表因为创建了TiFlash副本,在碰到聚合运算的时候优化器选择了走列存查询,最终结果就是在TiFlash完成暴力全表扫描、排序、分组、计算等一系列操作,返回给TiDB Server时基本已经加工完成,总共耗时8.02s。
咋一看好像没啥优化空间,但仔细观察会发现一个不合理的地方。执行计划倒数第二排的Selection算子,也就是SQL里面子查询的where过滤,实际有效数据1855行,却扫描了整个表接近950W行,这是一个典型的适合索引加速的场景。但遗憾的是,在TiFlash里面并没有索引的概念,所以只能默默地走全表扫描。
那么优化的第一步,先看过滤字段是否有索引,通常来说create_time这种十有八九都建过索引,检查后发现确实有。
第二步,尝试让优化器走TiKV查询,这里直接使用hint的方式:
SELECT /*+ READ_FROM_STORAGE(TIKV[db1.table]) */
cast( cast( CAST( SUM( num ) / COUNT( time ) AS CHAR ) AS DECIMAL ( 9, 2 )) AS signed ) speed,
... -- 此处省略n个字段
FROM
(
SELECT
DATE_FORMAT( receive_time, '%Y-%m-%d %H:%i:00' ) AS time,
COUNT(*) AS num
FROM
db1.table
WHERE
create_time > DATE_SUB( sysdate(), INTERVAL 20 MINUTE )
GROUP BY
time
ORDER BY
time
) speed;
再次生成执行计划,发现还是走了TiFlash查询。这里就引申出一个重要知识点,关于hint作用域的问题,也就是说hint只能在指定的查询范围内生效。具体到上面这个例子,虽然指定了db1.table走TiKV查询,但是对于它所在的查询块来说,压根不知道db1.table是谁直接就忽略掉了。所以正确的写法是把hint写到子查询中:
SELECT
cast( cast( CAST( SUM( num ) / COUNT( time ) AS CHAR ) AS DECIMAL ( 9, 2 )) AS signed ) speed,
... -- 此处省略n个字段
FROM
(
SELECT ?/*+ READ_FROM_STORAGE(TIKV[db1.table]) */
DATE_FORMAT( receive_time, '%Y-%m-%d %H:%i:00' ) AS time,
COUNT(*) AS num
FROM
db1.table
WHERE
create_time > DATE_SUB( sysdate(), INTERVAL 20 MINUTE )
GROUP BY
time
ORDER BY
time
) speed;
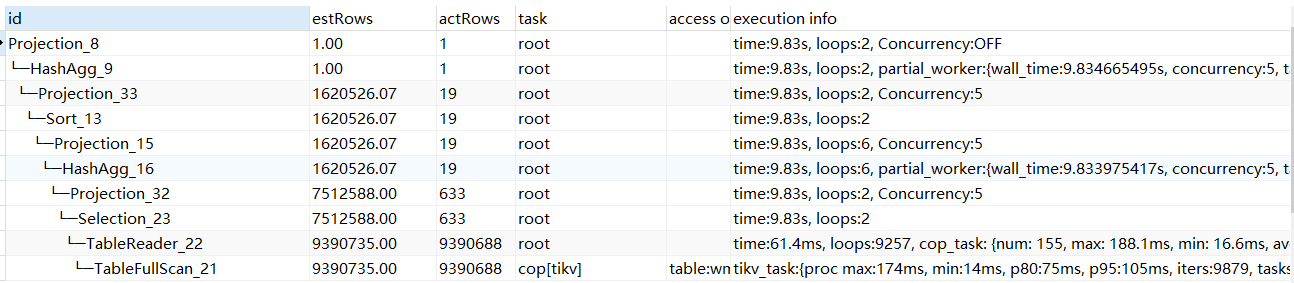
对应的执行计划为:
小提示:
也可以通过
set session tidb_isolation_read_engines = 'tidb,tikv';来让优化器走tikv查询。
发现这次虽然走了TiKV查询,但还是用的TableFullScan算子,整体时间不降反升,和我们预期的有差距。
没走索引那肯定是和查询字段有关系,分析上面SQL的逻辑,开发是想查询table表创建时间在最近20分钟的数据,用了一个sysdate()函数获取当前时间,问题就出在这。
获取当前时间常用的函数有now()和sysdate(),但这两者是有明显区别的。引用自官网的解释:
now()得到的是语句开始执行的时间,是一个固定值sysdate()得到的是该函数实际执行的时间,是一个动态值
听起来比较饶,来个栗子一看便知:
mysql> select now(),sysdate(),sleep(3),now(),sysdate();
+---------------------+---------------------+----------+---------------------+---------------------+
| now() ? ? ? ? ? ? ? | sysdate() ? ? ? ? ? | sleep(3) | now() ? ? ? ? ? ? ? | sysdate() ? ? ? ? ? |
+---------------------+---------------------+----------+---------------------+---------------------+
| 2023-03-16 15:55:18 | 2023-03-16 15:55:18 | ? ? ? ?0 | 2023-03-16 15:55:18 | 2023-03-16 15:55:21 |
+---------------------+---------------------+----------+---------------------+---------------------+
1 row in set (3.06 sec)
这个动态时间就意味着TiDB优化器在估算的时候并不知道它是个什么值,走索引和不走索引哪个成本更高,最终导致索引失效。
从业务上来看,这个SQL用now()和sysdate()都可以,那么就尝试改成now()看看效果:
SELECT
cast( cast( CAST( SUM( num ) / COUNT( time ) AS CHAR ) AS DECIMAL ( 9, 2 )) AS signed ) speed,
... -- 此处省略n个字段
FROM
(
SELECT ?/*+ READ_FROM_STORAGE(TIKV[db1.table]) */
DATE_FORMAT( receive_time, '%Y-%m-%d %H:%i:00' ) AS time,
COUNT(*) AS num
FROM
db1.table
WHERE
create_time > DATE_SUB( now(), INTERVAL 20 MINUTE )
GROUP BY
time
ORDER BY
time
) speed;
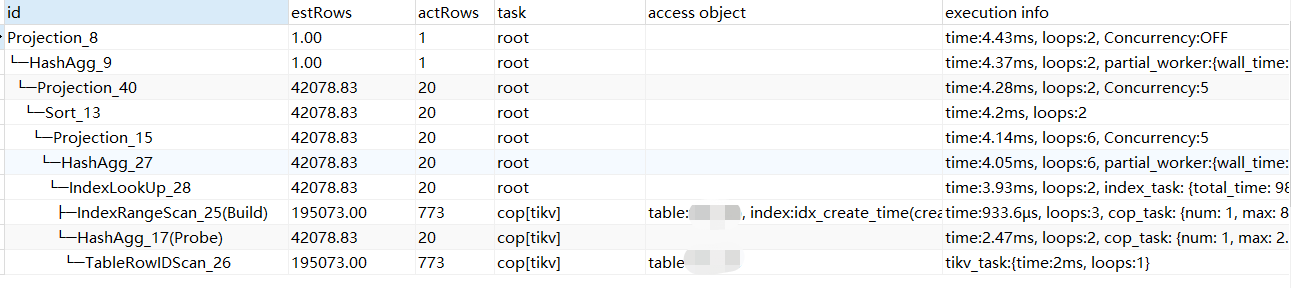
最终结果4.43ms搞定,从8.02s到4.43ms,1800倍的提升。
滥用函数,属于是开发给自己挖的坑了。
解决方案
经过以上分析,优化思路已经很清晰了,甚至都是常规优化不值得专门拿出来讲,但前后效果差异太大,很适合作为一个反面教材来提醒大家认真写SQL。
其实就两点:
- 让优化器不要走TiFlash查询,改走TiKV,可通过hint或SQL binding解决
- 非必须不要使用动态时间,避免带来索引失效的问题
深度思考
优化完成之后,我开始思考优化器走错执行计划的原因。
在最开始的执行计划当中,优化器对Selection算子的估算值estRows和实际值actRows相差非常大,再加上本身计算和聚合比较多,这可能是导致误走TiFlash的原因之一。不清楚TiFlash的estRows计算原理是什么,如果在估算准确的情况并且索引正常的情况下会不会走TiKV呢?
另外,我还怀疑过动态时间导致优化器判断失误(认为索引失效才选择走TiFlash),但是在尝试只修改sysdate()为now()的情况下,发现依然走了TiFlash,说明这个可能性不大。
在索引字段没问题的时候,按正常逻辑来说,我觉得一个成熟的优化器应该要能够判断出这种场景走TiKV更好。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!