图神经网络简介
图神经网络简介
参考:https://distill.pub/2021/gnn-intro/
https://www.bilibili.com/video/BV1iT4y1d7zP/?spm_id_from=333.337.search-card.all.click&vd_source=9909d829cf471fba676680693d2da49a
图表无处不在;现实世界的对象通常根据它们与其他事物的联系来定义。一组对象以及它们之间的联系自然地表示为图形。十多年来,研究人员已经开发了对图数据进行操作的神经网络(称为图神经网络或GNN)。最近的发展提高了它们的能力和表现力。我们开始看到在抗菌发现、物理模拟、假新闻检测、流量预测和推荐系统等领域的实际应用。
本文探讨并解释了现代图神经网络。我们将这项工作分为四个部分。首先,我们看看哪种数据最自然地表述为图表,以及一些常见的例子。其次,我们探讨了是什么让图形与其他类型的数据不同,以及我们在使用图形时必须做出的一些专门选择。第三,我们构建一个现代GNN,遍历模型的每个部分,从该领域的历史建模创新开始。我们逐渐从基本的实现转向最先进的GNN模型。第四,也是最后一点,我们提供了一个GNN游乐场,你可以在其中玩一个真实的任务和数据集,以建立对GNN模型的每个组成部分如何贡献它所做的预测的更强的直觉。
首先,让我们确定什么是图。图形表示实体(节点)集合之间的关系(边)。
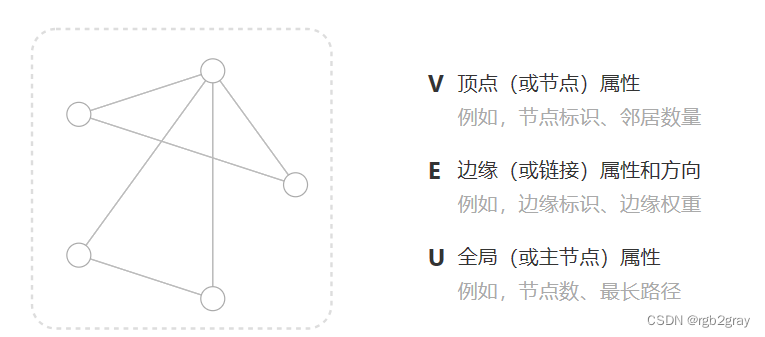
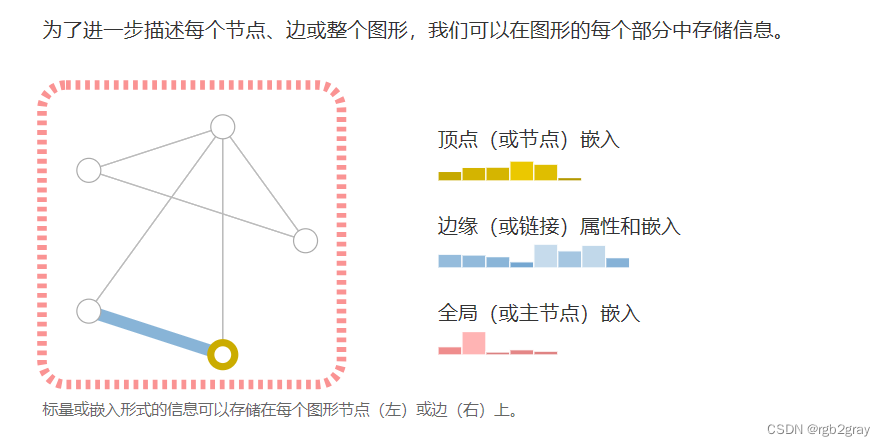

在机器学习中使用图形的挑战
那么,我们如何用神经网络来解决这些不同的图任务呢?第一步是考虑如何表示与神经网络兼容的图形。
机器学习模型通常采用矩形或网格状数组作为输入。因此,如何以与深度学习兼容的格式表示它们并不直观。图形最多有四种类型的信息,我们可能希望使用这些信息来进行预测:节点、边缘、全局上下文和连通性。前三个相对简单:例如,通过节点,我们可以形成节点特征矩阵N,通过为每个节点分配一个索引 i,虽然这些矩阵的样本数量不定,但无需任何特殊技术即可对其进行处理。
但是,表示图形的连通性更为复杂。也许最明显的选择是使用邻接矩阵,因为这很容易张量。但是,这种表示方式有一些缺点。从示例数据集表中,我们看到图中的节点数可能达到数百万个,并且每个节点的边数可以高度可变。通常,这会导致非常稀疏的邻接矩阵,这些矩阵的空间效率低下。
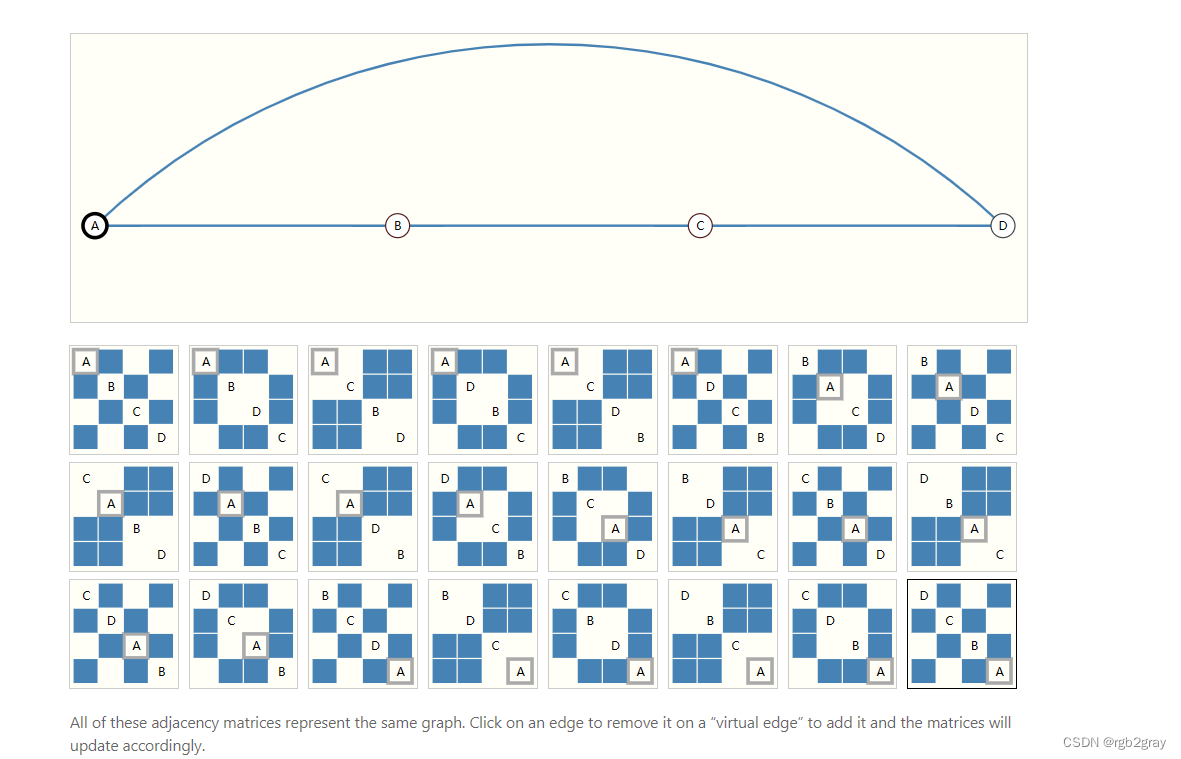
另一个问题是,有许多邻接矩阵可以编码相同的连通性,并且不能保证这些不同的矩阵会在深度神经网络中产生相同的结果(也就是说,它们不是排列不变的)。
学习排列不变运算是最近研究的一个领域。
例如,前面的奥赛罗图可以用这两个邻接矩阵等效地描述。它也可以用节点的所有其他可能的排列来描述。
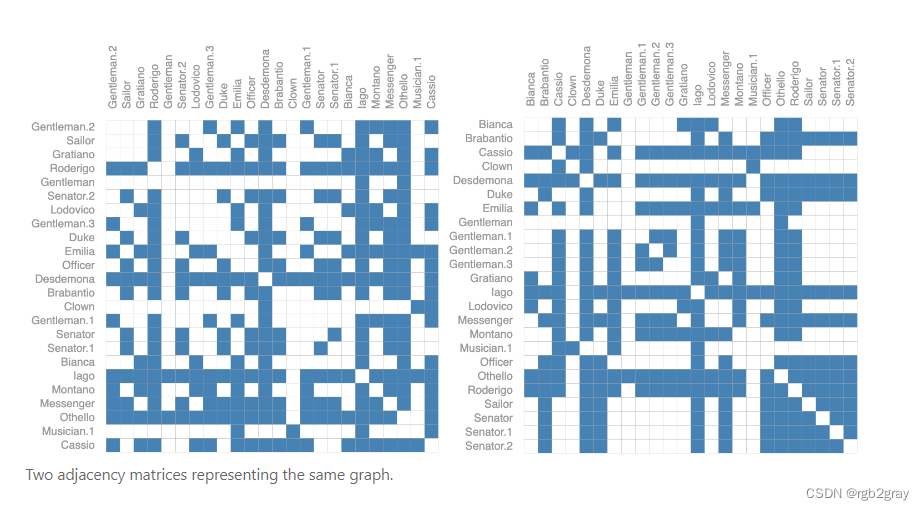
下面的示例显示了可以描述这个包含 4 个节点的小图的每个邻接矩阵。这已经是相当多的邻接矩阵——对于像奥赛罗这样的大例子来说,这个数字是站不住脚的。
一种优雅而内存高效的表示稀疏矩阵的方式是使用邻接表。这些邻接表将边e_k连接的节点n_i和n_j的连通性描述为邻接表的第k个条目中的元组(i, j)。由于我们预期边的数量远远小于邻接矩阵的条目数量
(
n
nodes
2
)
(n_{\text{nodes}}^2)
(nnodes2?),因此我们避免在图的未连接部分进行计算和存储。
另一种陈述这一观点的方式是使用大O符号,即最好具有 O ( n edges ) O(n_{\text{edges}}) O(nedges?)而不是 O ( n nodes 2 ) O(n_{\text{nodes}}^2) O(nnodes2?)。
为了使这个概念更具体,我们可以看看不同图中的信息是如何根据这个规范表示的:
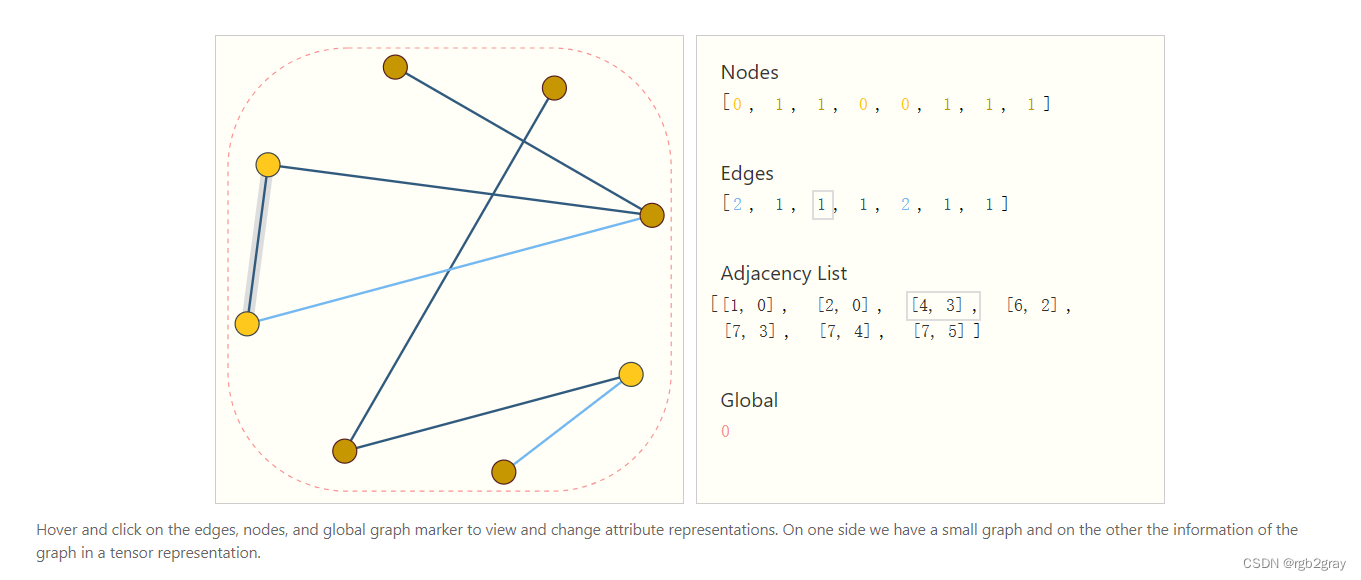
图神经网络
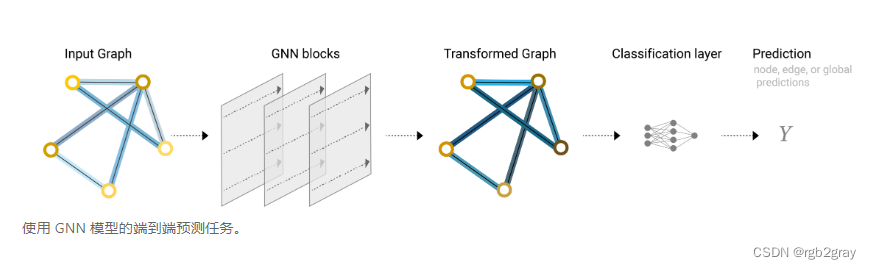
现在,图的描述采用排列不变的矩阵格式,我们将描述使用图神经网络 (GNN) 来解决图预测任务。GNN 是对图的所有属性(节点、边、全局上下文)的可优化转换,它保留了图的对称性(排列不变性)。我们将使用 Gilmer 等人提出的“消息传递神经网络”框架构建 GNN,并使用 Battaglia 等人介绍的图网络架构原理图。 GNN 采用“图输入,图输出”架构,这意味着这些模型类型接受图作为输入,将信息加载到其节点、边缘和全局上下文中,并逐步转换这些嵌入, 而不更改输入图的连通性。
最简单的GNN
通过我们上面构建的图形的数值表示(使用向量而不是标量),我们现在已准备好构建 GNN。我们将从最简单的 GNN 架构开始,在这个架构中,我们学习了所有图属性(节点、边、全局)的新嵌入,但我们还没有使用图的连通性。
这个GNN在图的每个组成部分上使用一个单独的多层感知器(MLP)(或你最喜欢的可微模型);我们称之为GNN层。对于每个节点向量,我们应用 MLP 并返回一个学习到的节点向量。我们对每条边都做同样的事情,学习每条边的嵌入,也对全局上下文向量做同样的事情,学习整个图的单个嵌入。
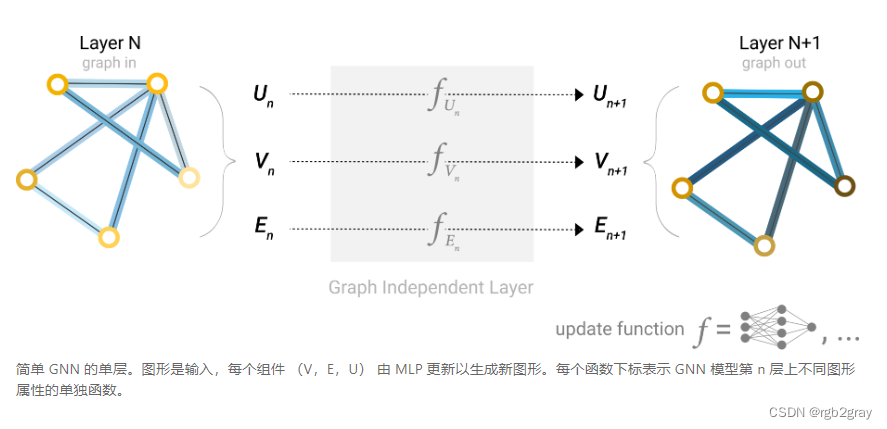
与神经网络模块或层一样,我们可以将这些GNN层堆叠在一起。
由于 GNN 不会更新输入图的连通性,因此我们可以描述具有与输入图相同的邻接列表和相同数量的特征向量的 GNN 的输出图。但是,输出图更新了嵌入,因为 GNN 更新了每个节点、边缘和全局上下文表示。
按池化信息预测的 GNN
我们已经构建了一个简单的GNN,但是我们如何在上面描述的任何任务中做出预测呢?
我们将考虑二元分类的情况,但这个框架可以很容易地扩展到多类或回归的情况。如果任务是在节点上进行二元预测,并且图形已经包含节点信息,则方法很简单——对于每个节点嵌入,应用线性分类器。
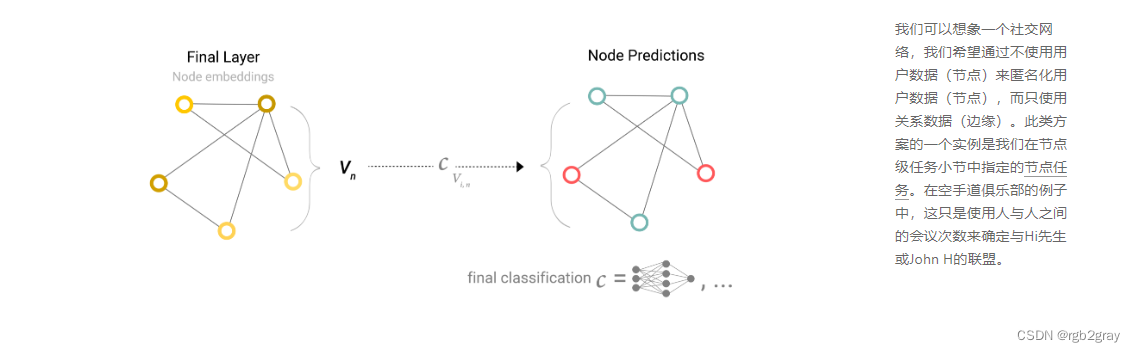
然而,它并不总是那么简单。例如,您可能将图形中的信息存储在边中,但在节点中没有信息,但仍需要对节点进行预测。我们需要一种方法来从边缘收集信息并将其提供给节点进行预测。我们可以通过池化来做到这一点。池化分两步进行:
对于要池化的每个项目,收集它们的每个嵌入并将它们连接成一个矩阵。
然后,通常通过求和运算聚合收集的嵌入。
有关聚合操作的更深入讨论,请转到比较聚合操作部分。我们用字母表示池化操作ρ,并表示我们正在收集从边到节点的信息pEn→Vn
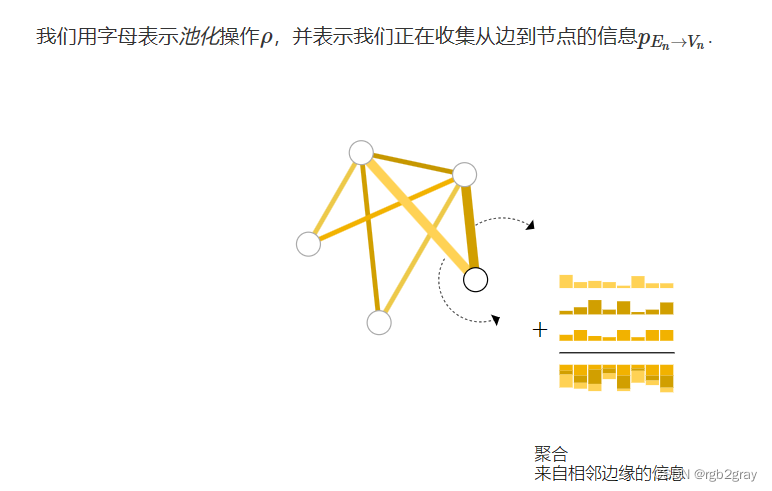
因此,如果我们只有边缘级特征,并试图预测二进制节点信息,我们可以使用池化将信息路由(或传递)到需要去的地方。模型如下所示。

如果我们只有节点级特征,并试图预测二进制边缘级信息,则模型如下所示。
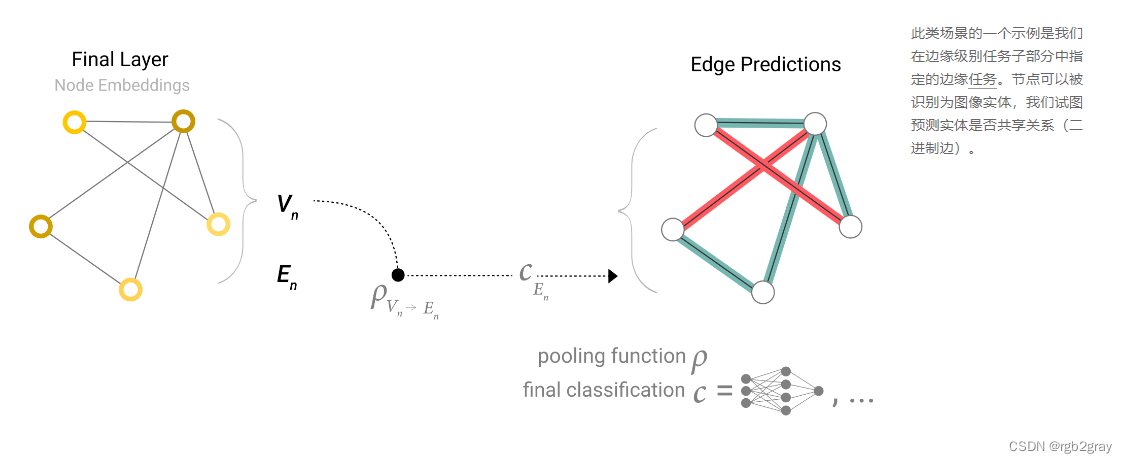
如果我们只有节点级特征,并且需要预测二进制全局属性,则需要将所有可用的节点信息收集在一起并聚合它们。这类似于 CNN 中的 Global Average Pooling 图层。对边缘也可以这样做。
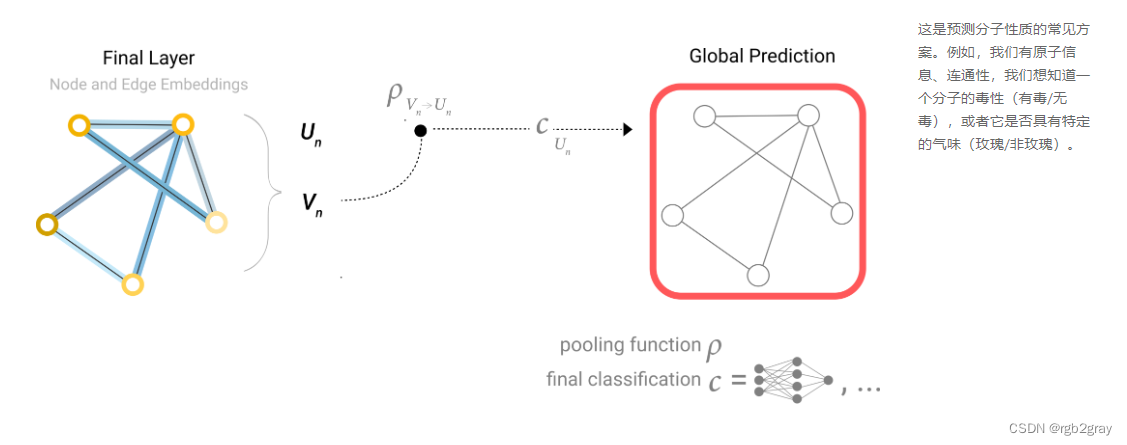
在我们的示例中,分类模型c可以很容易地用任何可微分模型替换,或者使用广义线性模型适应多类分类。
现在我们已经证明了我们可以构建一个简单的GNN模型,并通过在图形的不同部分之间路由信息来进行二元预测。这种池化技术将作为构建更复杂的GNN模型的构建块。如果我们有新的图形属性,我们只需要定义如何将信息从一个属性传递到另一个属性。
请注意,在这个最简单的 GNN 公式中,我们根本没有在 GNN 层内使用图的连通性。每个节点都是独立处理的,每个边以及全局上下文也是如此。我们仅在汇集信息进行预测时才使用连通性。
在图形的各个部分之间传递消息
我们可以通过在GNN层中使用池化来做出更复杂的预测,以便使我们学习的嵌入意识到图的连通性。我们可以使用消息传递来做到这一点,其中相邻节点或边缘交换信息并影响彼此更新的嵌入。
消息传递分三个步骤进行:
- 对于图中的每个节点,收集所有相邻的节点嵌入(或消息),即g 功能如上所述。
- 通过聚合函数聚合所有消息(如 sum)。
- 所有池化消息都通过更新函数(通常是学习的神经网络)传递。
您还可以 1) 收集消息,3) 更新消息,2) 聚合消息,并且仍然具有排列不变操作。
正如池化可以应用于节点或边缘一样,消息传递也可以发生在节点或边缘之间。
这些步骤是利用图形连接的关键。我们将在 GNN 层中构建更复杂的消息传递变体,以产生具有增强表现力和功率的 GNN 模型。
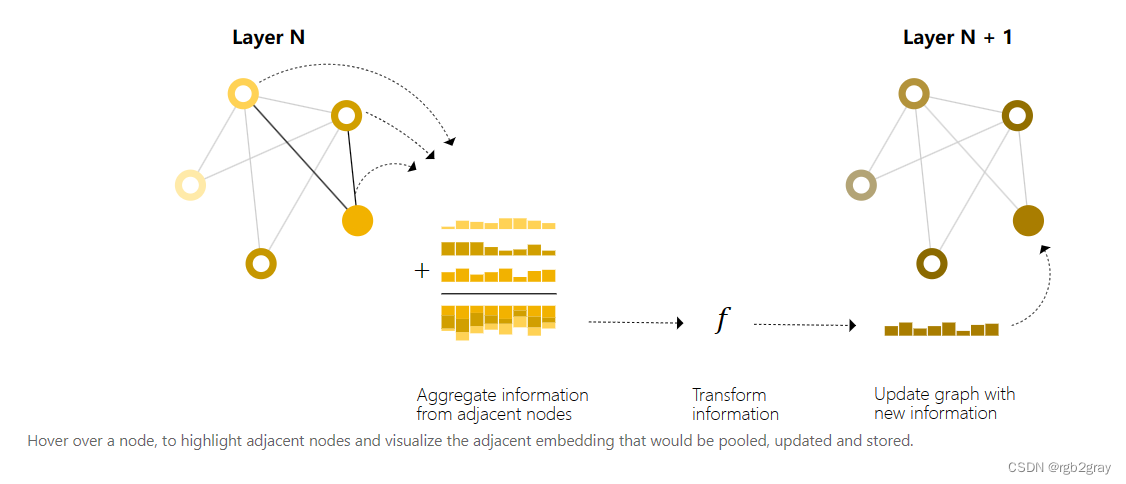
当应用一次时,此操作序列是最简单的消息传递 GNN 层类型。
这让人想起标准卷积:从本质上讲,消息传递和卷积是聚合和处理元素邻居信息以更新元素值的操作。在图形中,元素是一个节点,而在图像中,元素是一个像素。但是,图形中相邻节点的数量可以是可变的,这与图像中每个像素都有一定数量的相邻元素不同。
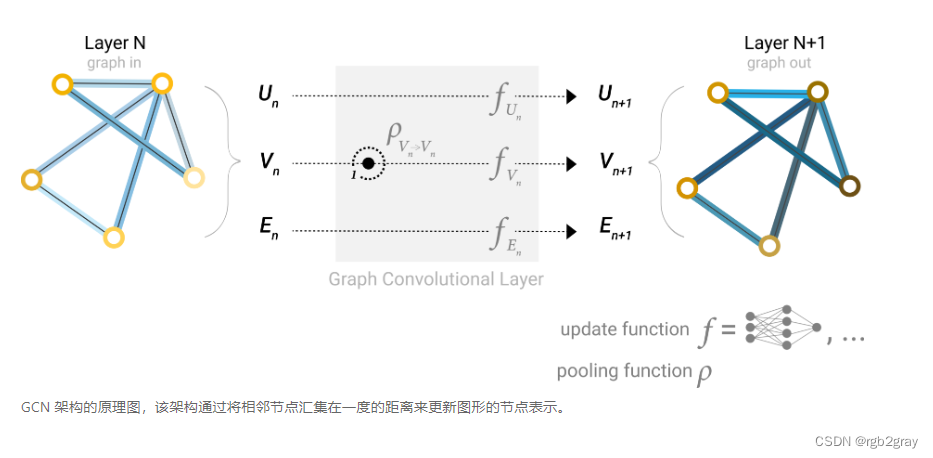
通过将传递GNN的消息层堆叠在一起,一个节点最终可以整合来自整个图的信息:在三层之后,一个节点拥有关于距离它三步远的节点的信息。
我们可以更新我们的架构图,以包含节点的这个新信息源:
学习边缘表示
我们的数据集并不总是包含所有类型的信息(节点、边缘和全局上下文)。 当我们想对节点进行预测,但我们的数据集只有边缘信息时,我们在上面展示了如何使用池化将信息从边缘路由到节点,但仅限于模型的最后预测步骤。我们可以使用消息传递在 GNN 层内的节点和边之间共享信息。
我们可以像之前使用相邻节点信息一样,通过汇集边缘信息,使用更新函数对其进行转换,然后存储它,来合并来自相邻边缘的信息。
然而,存储在图中的节点和边信息不一定具有相同的大小或形状,因此如何组合它们并不清楚。一种方法是学习从边空间到节点空间的线性映射,反之亦然。或者,可以在更新函数之前将它们连接在一起。
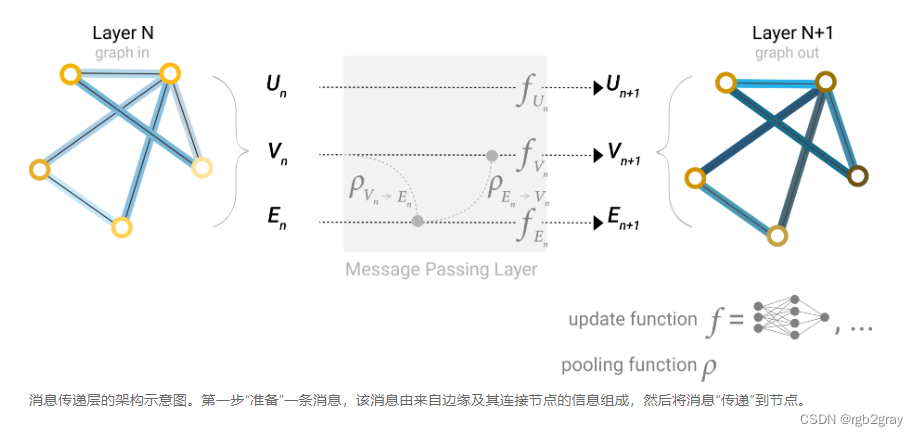
在构建 GNN 时,我们更新哪些图形属性以及更新它们的顺序是一个设计决策。我们可以选择是在边缘嵌入之前更新节点嵌入,还是相反。这是一个具有各种解决方案的开放研究领域——例如,我们可以以“编织”的方式进行更新,其中我们有四个更新的表示,这些表示被组合成新的节点和边缘表示:节点到节点(线性)、边缘到边缘(线性)、节点到边缘(边缘层)、边缘到节点(节点层)。

添加全局表示
到目前为止,我们所描述的网络存在一个缺陷:即使我们多次应用消息传递,图中彼此相距较远的节点可能永远无法有效地相互传输信息。对于一个节点,如果我们有 k 层,信息最多会在 k 步外传播。如果预测任务依赖于相距很远的节点或节点组,这可能是一个问题。一种解决方案是让所有节点能够相互传递信息。 不幸的是,对于大型图来说,这很快就会变得计算成本高昂(尽管这种方法被称为“虚拟边”,已被用于分子等小图)。
此问题的一个解决方案是使用图形 (U) 的全局表示,有时称为主节点或上下文向量。这个全局上下文向量连接到网络中的所有其他节点和边缘,可以充当它们之间的桥梁来传递信息,从而为整个图形构建表示。这创建了比以其他方式学习的更丰富、更复杂的图形表示.
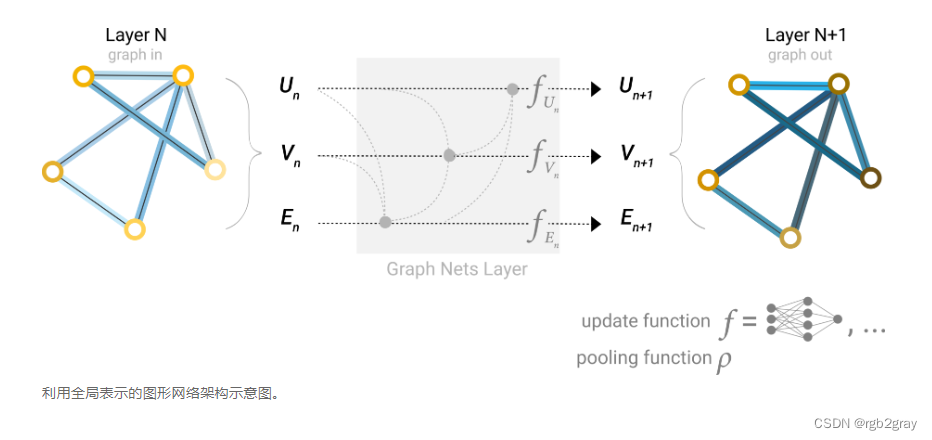
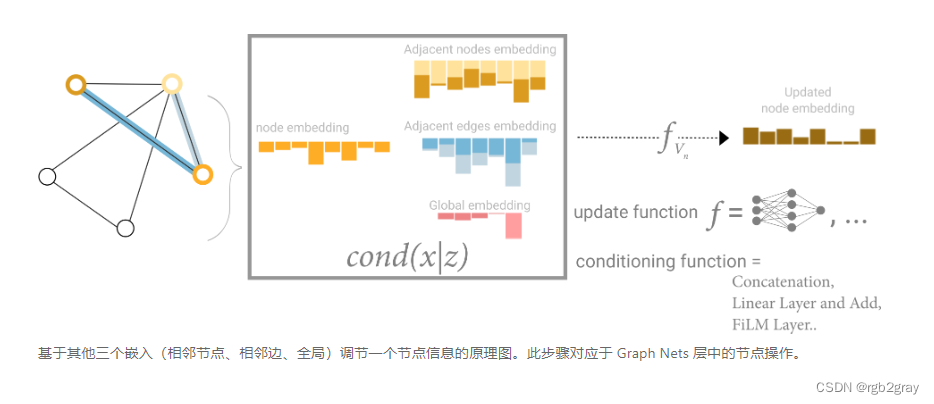
在这个视图中,所有图属性都学习了表示,因此我们可以在池化过程中通过调节我们感兴趣的属性相对于其余属性的信息来利用它们。例如,对于一个节点,我们可以考虑来自相邻节点、连接边和全局信息的信息。为了在所有这些可能的信息源上嵌入新节点,我们可以简单地将它们连接起来。此外,我们还可以通过线性映射将它们映射到同一空间,并将它们添加或应用特征调制层,这可以被认为是一种特征性注意力机制.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!