漏洞补丁存在性检测技术洞察
1、 漏洞补丁存在性检测技术是什么?
漏洞补丁存在性检测技术通俗的理解就是检测目标对象中是否包含修复特定已知漏洞的补丁代码,目标检测对象可能是源码,也能是二进制文件。
2、 漏洞补丁存在性检测技术业务背景
- 补丁检测这个问题背景是产品线的需求而来的,一个典型场景是linux-kernel通常版本是4.x.x 三位版本号,而通常开源软件漏洞库只能关联到4.x这种两位版本号,导致开源软件扫描检出kernel时,整个4.x几百个版本漏洞合并到一起,发生了漏洞误报问题,近千个漏洞确认困难。
- 另一个场景是 linux-kernel上有一份源码,各家linux发行版从上游取patch自行维护各家自己的小版本,这样你拿到一个kernel的rpm,可能版本号写的是4.x.x-x.hx. 各家维护的版本号不同,出现了你能获得的上游版本号很低,但该发行版自己维护的小版本很高,实际漏洞已经修复的情况,又导致了漏洞误报问题。
3、 漏洞补丁存在性检测技术有哪些应用场景?
给定某个存在漏洞的某版本开源软件源码/二进制文件,以及对应漏洞信息,检查它是否已经对该漏洞进行打补丁操作,从而消减对应文件检出的漏洞信息。
4、 漏洞补丁存下性检测技术方案
对于检查漏洞是否存在当前主流方法通常分为动态和静态两种方法。
>动态检测:
检测对象通常为二进制文件,常用的动态方法就是通过POC进行检测。对于一个特定的漏洞poc信息,通常为能触发该漏洞的一种方法,可能是一段脚本代码、一串命令参数、一个文件等。将软件运行起来,输入或者执行poc,检查程序输出是否存在异常即可检查是否存在漏洞。
优点:
- 这种检查方法准确率极高,如果触发poc基本可以确认存在漏洞。
缺点:
- 漏洞poc数据收集困难, 不是每一个漏洞都存在poc信息,而网上又有很多根据热点漏洞进行钓鱼的,收集与鉴别poc信息,需要对漏洞有深刻的理解,要求很高,否则一不小心就给自己种个后门,不如不检查。
- 环境配置困难,对于每个漏洞相关的软件和平台可能都不同,触发条件不同需要针对每个漏洞都要额外配置虚拟环境,这个工作量更甚于漏洞poc收集与检查。
>静态检测:
静态检查方法是指不需要运行检测目标就可以实现检测的技术统称。根据检查对象的不同静态检查方法有针对源代码的检测技术和针对二进制的检测技术。
? 源码静态检测技术:
基于源码的漏洞补丁存性静态检测核心技术是代码克隆检测。代码克隆检测技术通常有2大类4小类不同的检测方法,其中Type-4技术难点最大,同时检测鲁棒性也最好。
| 小类 | 大类 | 描述 |
|---|---|---|
| Type-1 | 句法克隆检测 | 去除空格、空行和注释后,源码内容格式完全相同 |
| Type-2 | 句法克隆检测 | 除了对一下函数名、类名、变量从命名以外,源码内容格式完全相同 |
| Type-3 | 句法克隆检测 | 片段部分被修改,如添加、删除、从新排序部分代码片段 |
| Type-4 | 语义克隆检测 | 语义相似,但源码句法完全不同 |
应用场景:开源软件检测、隐秘漏洞发现、已知漏洞补丁存在性检测等。
优点:
- 源码文件都是文本文件,对编译器、编译选项、cpu架构、操作系统类型等无关、不敏感,检测技术对不同语言基本通用。
缺点:
- 需要提供源代码,相对二进制来说,由于源代码属于敏感的隐私数据,因此对工具运行环境和部署方式比较敏感,比如公有云部署方式就不及本地部署方式让客户更能接受。
? 二进制静态检测技术:
基于二进制的漏洞补丁存在性静态检测核心技术是函数代码相似性检测,俗称二进制代码克隆检查 Binary code similarity detection (BCSD),通俗的理解就是来检测两个二进制代码是否由相同源代码编译而来的。
. 二进制克隆与源码代码克隆的技术难度差异:
虽然两者的检测的最终目的都是判断两段代码是否一致,但由于源代码文件编译生成的二进制文件影响因素非常的多,即使相同的源代码通过不同编译参数或相同参数多次构建,生成的二进制文件也是不同的,甚至是差别巨大。影响二进制生成的主要因素有:
- 不同的编译器及相同编译器不同版本,如gcc、clang、MSVC等。
- 不同的编译优化选项:如O0、O1、O2、O3、Os。
- 不同的安全编译选项:如NX ASLR PIE CANARY FORTIFY RELRO等。
- 不同的平台:如windows、linux、mac,32位、64位等。
- 不同的cpu架构:如x86、arm、mips、powerpc、risc-v等。
另外从源代码编译成二进制的过程中,很多源码中存在的信息都被丢弃了,比如变量类型、函数名称等符号信息。由于在源代码编译成二进制文件过程中存在多种影响因素,所以二进制克隆检测技术一直是业界研究的前沿技术,特别是怎么样来提升检测技术的鲁棒性,即一个检测算法或模型能对相同源码生成的不同二进制文件都有好的检测效果,正是二进制克隆检测技术难度大,所以工业界一直也没有一款好的商业工具可以提供漏洞补丁存在性检测能力。
同时由于二进制克隆检测对象为二进制文件,因此和源代码相比对工具的部署方式和运行环境相对宽松很多,既可以公有云方式来部署,也可以本地化来部署。
. 二进制克隆检测方法:
a. 传统方法
通过二进制反汇编出汇编指令,然后生成中间语言IR(可选),结合控制流图cfg进行图匹配,下面这篇论文的的结构很经典,大多数的BCSD问题基本都是这个结构。然后辅以一些统计学上的信息,比如反汇编出来的函数基本块中包含某些常量/指令信息、基本块哈希什么的处理方法。
?

一个典型例子是谷歌开发的bindiff,通过ida pro反汇编文件,然后对于cfg和基本块信息进行匹配。对于相同优化选项的函数匹配效果尚可,但是如果算上 架构 * 优化选项 数量的样本构建 与解析这个时间成本就难以接受了。
优点:
- 传统方法稳定, 且可解释性强,不考虑漏报情况的话,检出结果准确率高。
缺点:
- 抗扰动能力比较差。上文所说的 多架构,多优化选项的场景,传统方法就很难处理了。大多传统方法主要基于控制流图匹配,当优化选项变动时, 控制流图变动很大,难以进行相同函数匹配,在这基础上想要漏洞匹配则更难以实现。跨架构场景由于指令集不同,控制流图也可能进行较大变动,且对于不同指令集,相关的统计学信息会发生变动,较难处理。就算通过人工写不同指令之间映射关系,对于不同指令集的不同指令要求编写者对于对应的指令集有较深了解,要求较高。
- 控制流图匹配当前常用算法是匈牙利算法与KM算法,解决二分图匹配问题。时间复杂度为O(V*E),对于一个大函数节点数(几百上千)和边数(数倍或者十数倍于节点数)的数量极高,单次匹配代价已经不低。以linux kernel为样本,一个二进制文件约3w+函数,一次漏洞函数匹配代价已经无法接受。
b. 结合AI的检查方法
传统方法历史悠久,但对于跨编译选项和跨架构情况处理效果不好。所以在近期AI流行之后,学界主流对于BCSD问题解决的方法转向了使用AI。由于上述传统方法的效率问题,也导致只能求助于AI方法。
从较远的CNN、RNN、LSTM, 再到现在较为主流的BERT,处理原理大致相似。都是采用自然语言理解(nlp)的方法套用到汇编语言的检查上。
?
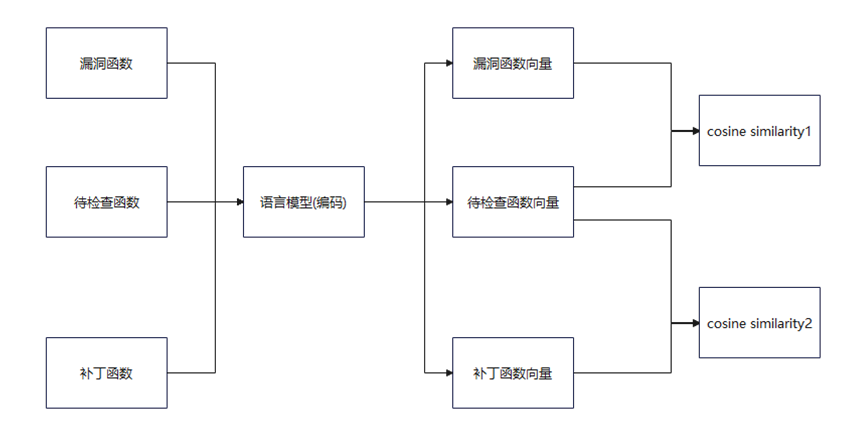
单个函数检测流程如上图所示,将汇编语言通过语言模型进行编码,函数编码后生成向量信息,然后对于这些向量直接进行相似度匹配,或者再通过孪生网络训练,最后进行相似度匹配。通常使用向量间的余弦距离来确认两个向量(函数)之间的相似度。对于单次匹配来说,如果相同架构相同编译选项的待检测函数与漏洞函数与补丁函数相似度一定会有差异,这样便实现了补丁函数与漏洞函数相似度确认,达成补丁检测的目的。
原理上大致与机器翻译类似。(以seq2seq模型举例便于理解,仅做打比方, 忽略实际token处理细节) seq2seq模型是一种循环神经网络模型(RNN) 在机器翻译上表现效果不错。网络分为一个Encoder和一个Decoder, 一种语言通过encoder进行编码,然后通过另一种语言的decoder来解码实现机器翻译。这样一个“简单”的模型却行之有效。
?

解决传统方法解决困难的跨架构问题大致原理就是如此,将一种架构指令集看作为第一种语言,然后将第二种架构指令集看作为第二种语言,通过神经网络将其编码成向量,然后进行相似度比较。差异在于seq2seq是直接翻译成另一种语言,而补丁检测使用的是将两边指令集编码为向量。而解决跨优化选项则将两种不同优化选项的汇编语言看成是相同语言的相同语义的不同表达, 让模型学习到该架构指令集的语义信息。
优点:
- AI对于BCSD问题处理有一个优势在于AI将待匹配函数编码为一个向量来进行匹配操作,与传统方法的cfg图匹配效率有显著的提升。
- (由于可解释性存疑) 对于跨架构和跨编译选项场景,由于将汇编编码成了向量,处理难度相较传统方法来说,处理难度比较容易。
缺点:
- AI模型的通病,可解释性不强,与传统方法不同,AI的结果只能靠经验解释。
- 结果不稳定,由于可解释性不强,学习到的知识无法具化,所以可能部分场景表现可以,但部分结果表现不好,较难定位,全靠经验来猜测解决。
c. 学术论文及工程实践
-
TREX: Learning Execution Semantics from Micro-Traces for Binary Similarity,这篇论文投在IEEE 2022上,可以算是通过BERT解决BCSD问题的鼻祖了,之前大多数是通过使用卷积神经网络(GNN)训练CFG,结合提取基本块/函数级特征然后通过CNN/LSTM等网络来训练。作者使用相对先进的BERT模型(相比于CNN RNN等),采用unicorn框架对二进制代码进行模拟执行。然后对于执行路径的汇编代码和寄存器随机初始化的进行记录。然后对汇编代码和寄存器进行Mask了MLM任务训练。(BERT用作强化理解语义的一个任务) 然后对训练的模型对样本进行微调处理,最后用来预测未训练的函数的效果。总体来说基于BERT模型来实现汇编层面的语言理解,可以交好的解决由于编译影响因素不同而生成的不同二进制的检测鲁棒性。
-
另外最有工程化成果的就是腾讯科恩实验室的两篇论文:
-
基于Gemini论文上又进行优化,将基本块调用升级为邻接矩阵训练https://keenlab.tencent.com/zh/2019/12/10/Tencent-Keen-Security-Lab-Order-Matters/
-
codecmr 跨模态代码搜索检测, 基于上一篇论文的基础,实现的二进制代码到原代码的搜索。https://keenlab.tencent.com/zh/2020/11/03/neurips-2020-cameraready/
这应该是这个方向上唯一算是工程化了的成果。但是限制很多,腾讯的方案是通过ghidra(美国国安局开源的一款逆向工具)将汇编代码反编译为源码,然后将反编译出来的源码进行代码搜索。这就涉及了上文所说的反汇编工具好坏的问题了。二进制文件->汇编语言相对有唯一性,用什么工具反汇编结果都差不多。但是汇编语言->c伪代码这个中间的变数就很多了,当今暂时没有一款工具能完美还原这个问题的,所以这条路要实现精准漏洞匹配还有很长的路和技术问题需要解决。
【总结】:二进制漏洞补丁存下性检测技术,总体来说是技术难度极大,通过依靠传统检测方法无法很好的解决编译影响因素导致的检测鲁棒性,但随着AI技术的引入,特别是LLM大语言模型的涌现,模型对于二进制汇编代码语义理解能力的增强,对二进制代码克隆的检测能力在工业界工具中落地使用成为可能,我相信在不久的将来一定会有成熟的工具来实现已知漏洞补丁存下性检测。
原文作者:安全技术猿
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!