c++语法学习
C++学习记录)
本文档根据b站黑马程序员发布的c++课程做的个人笔记。
视频链接:https://www.bilibili.com/video/BV1et411b73Z/?spm_id_from=333.337.search-card.all.click
相关的实现项目会上传附件。
机房管理系统:
https://download.csdn.net/download/Eoneanyna/88625209
演讲比赛流程管理系统:
https://download.csdn.net/download/Eoneanyna/88625203
vs的安装
vs全称为visual studio,是美国微软公司的开发工具:适用于 Windows 上 .NET 和 C++ 开发人员的最全面 IDE。 完整打包了一系列丰富的工具和功能,可提升和增强软件开发的每个阶段。
为了学习c++,笔者安装并使用了vs2019版本;其他编辑器如:dev-c++、eclipse也可。
安装:在网上搜索安装教程和资源下载。
特别注意:
笔者在创建空项目时,发现选项中没有空项目
此时应该是在由于相关的工具包没有下载,于是下滑拉到最底下,点击:安装多个工具和功能; 勾选相应的工具包:使用c++的桌面开发;进行下载
勾选相应的工具包:使用c++的桌面开发;进行下载

代码的语法
注释
单行注释
//注释内容
多行注释
/*注释内容*/
main
main函数是一个程序的入库,每个程序都必须有那么一个函数,有且仅有一个
变量
变量的定义
变量的作用:用于代码使用值,如定义名称为a的变量的值为10,则在后续的程序编写中,可以使用a来代表10;a作为变量可以重新赋值,当写:a = 20;时,在此条语句执行之后,使用a的地方a都代表20。
语法:数据类型 变量名 = 初始值;
如:
int a = 10;
数据类型的意义在于:给变量分配一个合适的内存,存储代表的值。
注:分号;在每写完一条程序语句时都要写,代表语句的结束
变量取名的时候,为了便于管理和代码阅读,变量命名有相关的一套规则:
- 不能是关键字,是的话会编译不通过
- 只能由字母、数字、下划线组成
- 第一个字符只能是字母或者下划线
- 标识符中字母区分大小写
变量的数据类型有:
整数类型
| 名称 | 关键字 | 占用(内存)字节数 | 取值范围 |
|---|---|---|---|
| 整数 | int | 4字节 | (-2^15 ~ 2^15-1) |
| 短整型 | short | 2字节 | (-2^31 ~ 2^31-1) |
| 长整型 | long | windows为4字节,linux为4字节(32位),8字节(64位) | (-2^31 ~ 2^31-1) |
| 长长整型 | long long | 8字节 | (-2^63 ~ 2^63-1) |
浮点数
| 名称 | 关键字 | 占用(内存)字节数 | 取值范围 |
|---|---|---|---|
| 单精度浮点数 | float | 4字节 | 7位有效数字 |
| 双精度浮点数 | double | 8字节 | 15~16位有效数字 |
float作为单精度,赋值时应该注意:
float f1 = 3.14;
//此时3.14默认为double,编译时先把double3.14转为float再赋值给f1
//正确应该写为:
float f1 = 3.14f;
//是把3.14的float单精度数赋值给f1不会进行强制转换
//科学计数法
float f2 = 3e2;//3*10^2
//3e-2 是3*0.1^2
默认情况下,输出一个小数,会显示出6位有效数字
字符型
| 名称 | 关键字 | 占用内存大小 | |
|---|---|---|---|
| 单字节 | char | 1个字节 | 赋值时使用单引号‘’ |
| c风格的字符串 | char 变量名[] | 按照值的大小 | 赋值时使用双引号“” |
| c++的字符串 | string | 按照值的大小 | 赋值时使用双引号“” |
扩展:字符型变量对应的ascii编码
//输出字符型变量对应的ascii编码
cout<< (int)ch << endl;
//'a'输出97
//'A'输出65
//c风格的字符串
char a[] = "hello world";
//c++风格的字符串
//记得引用头文件
#include<string>
string a = "hello world"
bool类型的定义
布尔类型代表真、假
| 名称 | 关键字 | 占用内存大小 | |
|---|---|---|---|
| 布尔类型 | bool | 1个字节 | true = 1 false = 0 |
sizeof(计算变量大小)
此函数统计数据类型所占的内存大小
sizeof(数据类型或者变量)
cout<<"a占用的内存空间为:"<<sizeof(a)<<"字节"<<endl;
常量的定义
常量和变量相同,都是用于代码编写过程中使用某个数值或内容(内容是指字符类型),和变量不同的是:常量初次定义值后,无法更改代表的值了。而变量就可以重新赋值。
define
define关键字定义的常量通常在文件最上方定义,此定义作用于全项目
语法:
#define 常量名 常量值
如:
#define a 10;
const
const修饰的常量,通常在变量定义钱加关键字const,修饰该变量为常量,之后不可修改,此定义作用于当前函数或当前项目
语法:
const 数据类型 常量名 = 常量值
如:
const int a = 10;
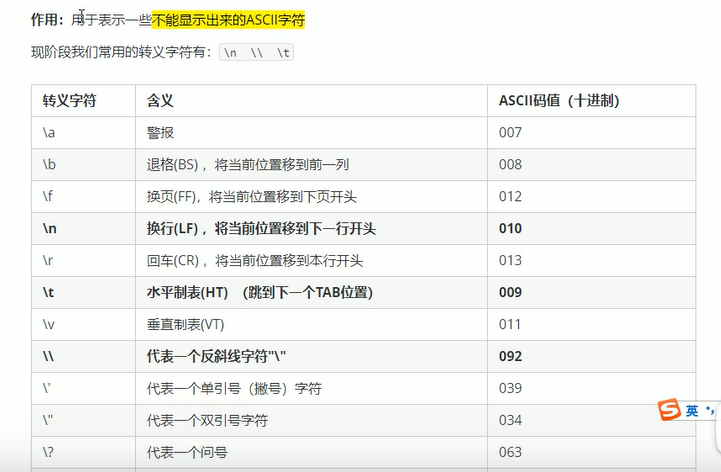
转义字符
数据的输入
cin
cin关键字
int a = 0;
//从键盘输入变量a的值
cin >> a;
运算符
算数运算符
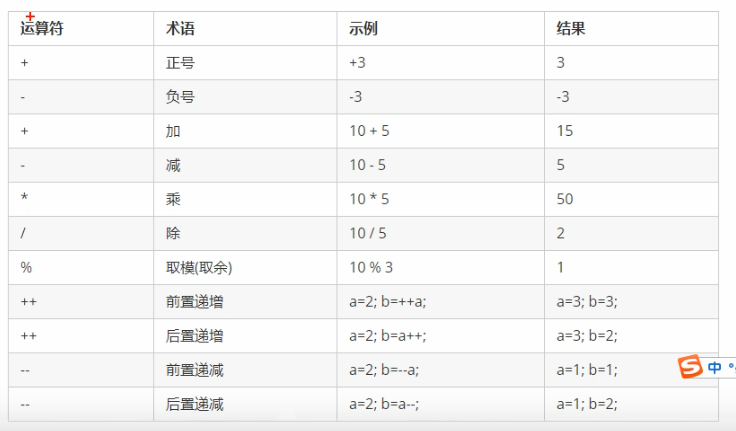
注:
/ :除法中,两个整数相除,结果依然是整数。
两个小数相除,结果可以是小数
%:取模运算的本质就是求余运算,10%20=10
两个小数是不能做取模运算的。
++、–:前置递增先对变量进行++,再计算表达式,后置递增相反
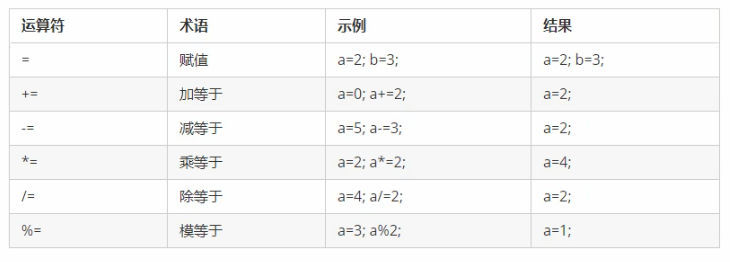
赋值运算符
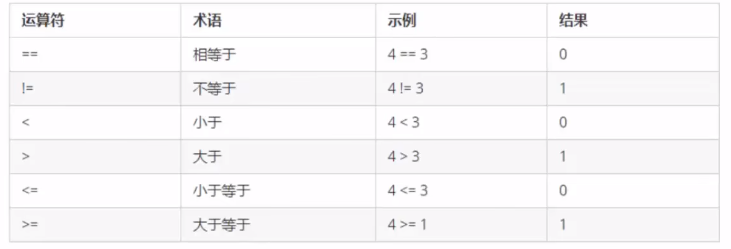
比较运算符
逻辑运算符

程序流程结构
顺序结构
按顺序执行,不发生跳转
选择结构
if
if语句
if(a > 20){
}else if(a>40){
}else{
}
switch
switch(表达式){
case 结果1:
执行语句;
break;
//不写break的话还会继续执行之后的case判断
case 结果2:
执行语句;
break;
default:
执行语句;
break;
}
switch执行效率高但是只能判断整型或字符型。
三目运算符(a>b?a:b)
含义:
如果a>b,则为真,返回a;
如果a<=b,为假,返回b;
循环结构
whlie
while(条件){
执行语句
}
//while中条件满足时则执行{}中的条件,如果不满足条件则跳出循环
do while
do{
循环语句;
}while(条件)
//与while的区别在于:do……while会先执行一次循环语句,再判断循环条件
for
for(int i = 0;i<10;i++){
}
//定义一个局部变量i的初始值为0,for循环执行的条件是i<10;每执行一次for循环,i++
continue
continue;语句:结束本次循环,进入下一次循环
goto
可以无条件跳转语句;
解释:如果标记的名称存在,执行到go to语句时,会跳转到标记的位置
int main(){
goto FLAG;
cout<<"执行语句"<<endl;
FLAG;
}
//不会输出 执行语句 四个字
数组
一维数组
数组的定义(定义数组的时候,必须有初始长度):
1.数据类型 数组名[数组长度];
2.数组类型 数组名[数组长度] = {值1,值2,值3……};
3.数组类型 数组名[] = {值1,值2,值3……}
int arr[5];
//定长为5的空数组
int arr1[5] = {1,2,3,5}
//定长和有初始值的数组,值为{1,2,3,5,0}
int arr[] = {111}
//定长为1的数组,初始值为111
二维数组
二维数组的定义:
1.数据类型 数组名[行数][列数];
2.数据类型 数组名[行数][列数] = {数据1,数据2},{数据3,数据4};
3.数据类型 数组名[行数][列数]={数据1,数据2,数据3,数据4};
4.数据类型 数组名[][列数] = {数据1,数据2,数据3,数据4}
类似列表:如一个二维数组为 int arr[2][3]如下
| 1 | 2 | 3 |
|---|---|---|
| 3 | 4 | 5 |
多维数组
数组名的用途
1.可以用sizeof(数组名)获取数组的长度
2.可以获取数组在内存中的首地址:
cout<<(int)arr <<endl;
第一个元素的地址:(int)&arr[0]
注:数组名代表数组的首地址,是一个常量,无法赋值
函数
函数的定义:
返回值类型 函数名(入参类型 入参名称){
}
//如果函数不需要返回值则声明的时候返回值类型可以写:void
int add(int num1,int num2){
int sum = num1 + num2;
num1 = 20
return sum;
}
//函数中入参的值改变,不能改变实际的入参数值
如:
void main(){
int a = 10;
int b =20;
add(10,20)
//执行完成之后a = 10,b=20,;但执行add函数时,add函数中num1最后的值其实为20
}
函数的声明
由于函数必须在调用之前就要定义,但是全放文件开头太杂乱。
因此可以先提前在文件头声明一个函数,但是函数的具体内容可以写在另外的靠后位置。
声明的格式:
返回值类型 函数名(入参类型 入参名称);
函数的分文件编写
1.创建后缀名为.h的头文件
2.创建后缀名为.cpp的源文件
3.在头文件中写函数声明
4.在源文件中写函数的定义
例如:
//add.h
#pragma once //防止头文件重复包含
#include<iostream>
using namespace std;
void add(int num1,int num2);
//add.cpp
#include<iostream>
#include "add.h"
using namespace std;
void add(int num1,int num2){
cout<<"num1+num2 = "<<num1+num2<<endl;
}
//main.cpp
#include<iostream>
//重要的引用
#include"add.h"
using namespace std;
void main() {
int a = 1;
int b = 2;
add(a, b);
}
指针
指针的作用:通过指针来访问内存
指针的定义
//定义一个变量,变量分配了4字节的内存,有内存就有地址
int a = 10;
//指针定义的语法:数据类型 *指针变量名
//定义了一个指针的变量,此变量可以存储一个地址
int * p;
//此时p是一个空指针,值为null,不可访问
//让p记录变量a的内存地址
p = &a;
//使用指针
//指针前加*,代表解引用,找到指针指向的内存中的数据
cout<<*p <<" = "<<a<<endl
| 名称 | 关键字 | 占用内存 |
|---|---|---|
| 指针 | int* | 32位系统下:占用4个字节;64位系统下,占用8个字节。 |
空指针和野指针
空指针:指针没有指向任何地址,值为null
野指针:指针指向了非法的内存空间(地址没有进行申请,但是指向了对应的内存地址)
//指针p被指向0x1100这个地址
//但是这个地址没有被申请分配内存,所以此时指针p被称为野指针
int* p = (int*0)0x1100;
const
const修饰指针(常量指针)
const修饰的是指针,指针的指向可以更改,但是指针指向的值不可以更改
int a = 10;
int b = 10;
//常量指针
const int* p = &a;
p = &b;
//这个写法是正确的,因为b=10=a
*p = 100;//错误,不可更改值
const修饰常量
const修饰的是常量,指针的指向不可以改,指针指向的值可以改
int * const p = &a
*p = 20 //正确,将a从10改成了20
p = &b //错误,不能指向另一个地址
const又修饰指针又修饰常量
const int * const p = &a//指针指向的值和指针存储的地址都不可以更改
指针和数组与函数
//指针和数组
//利用指针访问数组中的元素
int arr[5] = {1,2,3,4,5};
int *p = arr;//arr是数组首地址
//遍历数组
for (int i = 0;i<sizeof(arr)/sizeof(arr[0]);i++){
cout << *p <<endl;
if (i != sizeof(arr)/sizeof(arr[0])-1){
p++;//让指针向后偏移,访问数组下一个元素
}
}
//函数入参为指针时,可以更改相应的变量
void instead(int* p){
*p = 20;
}
void main(){
int a= 10;
instead(&a);
}
引用
作用:给变量取别名
语法:数据类型 &别名 = 原名
引用的本质:在c++内部实际是一个指针常量
//两行代码的含义是一样的
int * const ref = &a
int &b = a
常量引用:
使用场景:用来修饰形参,防止误操作。
int &ref = 10;//错误的写法
const int &ref = 10;//正确的
//代码实际可以理解为:
//int temp = 10;
//const int &ref = temp;
//10分配了一块合法的空间。
ref = 20;//错误的,不可以修改ref指向的值
//如:
void showValue(const int &val){
}
//这样写的话,在函数内给val赋值时,编译器就会报错
引用的注意事项
- 引用必须初始化
int &b;//错误的必须赋值
- 引用一旦初始化之后,就不可以再更改了。
int c = 20;
b = c;
//不会报错,但是这不是更换了引用,而是赋值操作。
//将b=a=20
引用做函数参数
作用:函数传参时,可以利用引用技术让形参修饰实参
优点:可以简化指针修改实参
//交换ab的值
void mySwap(int &a,int &b){
int temp =a;
a=b;
b=temp;
}
int main(){
int a = 10;
int b = 20;
//调用
mySwap(a,b);
}
引用做函数的返回值
注意:
1.不要返回局部变量的引用(局部变量在栈区中,使用一次之后会被释放)
2.函数的调用可以作为左值
函数的默认参数
在c++中,函数的形参列表中的形参是可以有默认值的
语法: 返回值类型 函数名(参数 = 默认值){}
int func(int a,int b = 20,int c = 30){
return a+b+c;
}
注意:
- 如果某个位置以及有了默认值,那么从这个位置往后(往右),之后的形参都必须有默认参数
- 函数声明和实现中只能有一个地方有默认参数。如果文件头部中的函数声明中有默认参数,函数的具体的实现就不能有默认参数了。
函数的占位参数
语法:返回值类型 函数名(形参类型 形参名称,形参类型){}
void func (int a,int = 10){
}
//调用时:必须要填;如果占位参数有默认参数时,可以不填
func(10,20);
函数的重载
作用:函数名可以详谈,提高复用性
条件:
1.同一个作用域下
2.函数名称详谈
3.函数参数类型不同,或个数不同,或顺序不同
注:
- 函数返回值不同,入参相同不是重载,不可如此使用,会报错
- 引用作为重载的条件
void func(const int &a){
}
void func(int &a){
}
//在调用时
int main(){
int a = 10;
func(a);//调用的是void func(int &a)
//a是一个变量,刻读可写,所以调用没有const的
func(10);//调用的是void func(const int &a)
}
- 重载中可以有默认参数,但是要小心
void func(int a,int b = 10){
}
void func(int a){
}
int main(){
int a = 10;
func(a);
//这样调用会导致不知道调用哪个函数,由歧义,所以要避免这种情况
}
## 结构体 语法: ```cpp struct Student{ //结构体成员列表 string name; int id; };
//在创建结构体时,顺便创建结构体变量
struct s{
string name;
}s3;
void main(){
//定义:1.定义空的结构体变量
struct Student s1;
//通过.来访问结构体变量中的属性,赋值
s1.name = “张三”;
//定义2:定义并赋值
struct Student s2 = {"李四",2};
}
<a name="hA2Hu"></a>
### 结构体数组
struct 结构体名 数组名[元素个数] = {{},{},{}}
<a name="Dz5UN"></a>
### 结构体指针
```cpp
//1.创建学生结构体变量
struct student s;
//2.通过指针指向结构体变量
student * p = &s
//3.通过指针访问结构体变量中的数据
cout<< p->name <<endl;
结构体嵌套结构体
结构体中的成员可以嵌套另一个结构体
struct student {
string name;
}
struct teacher{
string name;
struct student stu;
}
void main(){
teacher t;
t.stu.name = "张三";
}
内存分区模型
c++程序在运行时,将内存大方向划分为4个区域:
1.代码区:存放函数体的二进制代码,由操作系统进行管理的
2.全局区:存放全局变量和静态变量以及常量
3.栈区:由编译器自动分配释放,存放函数此参数值,局部变量等
4.堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统进行系统回收。
程序运行前:
代码区:
- 存放cpu执行的机器指令;
- 代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
- 代码区是只读的,原因是为了防止程序意外修改了它的指令。
全局区:
- 全局变量和静态变量存放于此。
静态变量:static int a = 10;
- 全局区海包含了常量区,字符串常量和其他常量也存放在此。
字符串常量 cout<<“字符串常量”;
const修饰的全局变量也叫常量(const 修饰的局部变量不在全局区)
- 该区域的数据在程序结束后由操作系统释放。
程序运行时:
程序运行时才可能会有栈区和堆区;
栈区:由编译器自动分配释放,存放在栈区的局部变量。
在函数执行完之后自动释放,但是如果函数中返回**局部变量(分配在栈区的变量)**的地址,则不会被释放,第一次使用这个局部变了则可以正确打印,因为编译器做了保留,但是使用第二次的时候,这个数据就不再保留了,会报错。
注意:在函数中,不要随便返回局部变量的地址。
- 函数形参存放在栈区
堆区:在c++中主要利用new在堆区开辟内存。
//指针p本质是一个局部变量,存放在栈区中;
//但是10这个int存放于堆区
int *p = new int(10);
//回收内存时,使用关键字delete
delete p;
int * arr = new int[10];
//释放数组需要加中括号
delete[] arr;
类和对象
c++面向对象的三大特性:封装,继承,多态
具有相同性质的对象,我们可以抽象称为类。
语法:
class 类名{
//访问权限
//公共权限
public:
//属性和行为都统称为 成员
//属性:变量,成员变量,成员属性
int m_r;
//行为:函数,成员函数,成员方法
double func(){
return 2;
}
};
成员变量和成员函数是分开存储的
c++会给每个空对象也分配一个字节的空间,是为了区分空对象占内存空间的位置。
如果对象中定义了非静态成员变量,则会按照全部非静态成员变量的内存去分配空间。
//1个字节
class person{}
//4个字节
class person1{
int m_A; //算类的对象
static int m_B;//静态成员变量,不属于类的对象
void func(){}//非静态成员函数,不属于类的对象
static void func2(){}//静态成员函数,不属于类的对象上
}
封装
类在设计时,可以把属性和行为放在不同的权限下:
1.public 公共权限
类内可以访问,类外可以访问
2.protected 保护权限
类内可以访问,类外不可以访问
继承中:儿子可以访问父亲中的保护内容
3.private 私有权限
类内可以访问,类外不可以访问
继承中:儿子不可以访问父亲的私有内容
类内:类定义的成员函数中访问,叫类内
继承
可以减少重复的代码
class BasePage{
public:
void print(){
cout<<"这是基础"<<endl;
}
};
class Python:public BasePage{
public:
void context(){
cout<<"这是python"<<endl;
}
};
//python类也有basepage的print方法
//python类也称为basepage的子类,python继承了baseage的方法
- 公共继承 public
- 保护继承 protected
- 私有继承 private
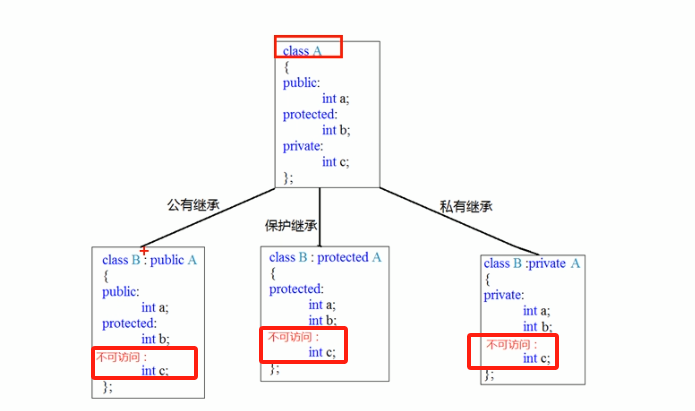
继承后的子类,初始化时,会开辟对应的父类的所有参数的内存空间。
继承中:先调用父类构造函数,再调用子类构造函数,析构顺序和构造顺序相反
继承中:子类可以有相同名称的成员,但是要通过子类访问到父类的同名成员需要加作用域写法
class base{
public:
int m_A = 200;
void func(){};
void func(int i){};
};
class son:public base{
public:
int m_A = 100;
void func(){};
};
//访问子类中的m_A
son s;
cout << s.m_A << endl;//100
cout << s.base:m_A <<endl;//200
//如果子类中出现和父类同名的成员函数,
//子类的同名成员会隐藏掉父类中所有的同名函数成员
s.func(100);//错误
//会报错,因为子类的void func(){};把父类的void func的两个函数都覆盖了
s.base::func(100);//正确的访问
//静态成员可以通过类名访问
son::base::静态成员或函数名
多继承
一个子类需要同时继承多个基础类
class son:public base1,public base2{
};
当两个基础类有相同名称的成员时,需要指定基础类再使用成员,不然会报错
虚继承
菱形继承问题:
两个子类继承同一个基类,又有某个类同时继承两个子类。
class animal{
public:
int m_age;
};
class sheep:public animal{};
class TUO:public animal{};
class sheepTUO:public sheep,public TUO{};
void test01(){
sheepTUO st;
st.m_age = 18;//错误,不明确
st.TUO::m_age = 18;//正确
st.sheep::m_age = 20;//正确
//但此时的st有两份m_age数据
//想要st只要一个m_age数据时,就需要用到虚拟继承
/*
将
class sheep:public animal{};
class TUO:public animal{};
改为
class sheep:virtual public animal{};
class TUO:virtual public animal{};
*/
};
多态
虚函数
子类重写相关成员函数
class animal{
public:
void speak(){
cout<<"未知动物叫"<< endl;
}
};
class cat:public animal{
public:
void speak(){
cout<<"小猫喵喵喵"<< endl;
}
};
class duck:public animal{
public:
void speak(){
cout<<"鸭子嘎嘎嘎"<< endl;
}
};
//此函数可以调用相应的speak函数
void doSpeak(animal &a){
a.speak();
}
int main(){
cat c;
doSpeak(c);//输出:未知动物在说话
/*
如果要输出小猫喵喵喵,则需要修改
class animal{
public:
void speak(){
cout<<"未知动物叫"<< endl;
}
};
为(子类对应的函数也要加virtual):
class animal{
public:
//虚函数被调用时,没有在编译时段写入函数地址,所以可以调用到对应的speak
virtual void speak(){
cout<<"未知动物叫"<< endl;
}
};
……
*/
}
如果不是虚函数,初始化的类所占内存大小为1,占位
如果有虚函数成员,则所占内存大小为4,4字节为一个地址存储,此地址指向一个虚函数的地址表,地址表里存储了子类对应的虚函数实现。
纯虚函数与抽象类
通常父类中的虚函数实现是没有意义的,主要都是调用子类写的内容
所以可以把父类中的虚函数写为纯虚函数,不写实现
语法: virtual 返回值类型 函数名(参数列表) = 0;
当类中有了纯虚函数,这个类也称为抽象类;
抽象类:
1.无法实例化对象
2.子类必须重写抽象类中的纯虚函数,否则也属于抽象类
虚析构和纯虚析构
多态使用时,如果子类有属性开辟到堆区,父类指针在释放时无法调用到子类的析构函数
解决方式:将父类中的析构函数改为虚析构或纯虚析构
- 虚析构:
virtual ~类名(){};
- 纯虚析构:
virtual ~类名() = 0;
struct和class的区别
struct和class区别不大,
struct 默认权限是:公共 public
class 默认权限是:私有 private
类分文件
//point.h
#pragma once //防止头文件重复包含
#inlcude<iostream>
class Point{
private:
int p_x;
int p_y;
public:
void set_X(int x);
}
//point.cpp
#inlcude<iostream>
#include"point.h"
void Point::set_X(int x){
p_x = x;
}
枚举
enum class Role {
manager = 1,
teacher = 2,
student = 3,
};
//enum role定义枚举值中的字符串不能重复
//enum class role中在两个枚举值定义中
//字符manager可以重复定义在两个枚举中
class User {
public:
string m_Account;
string m_Password;
string m_Name;
Role m_Role;//1管理员 2教师 3学生
}
对象的初始化和清理
编译器自动调用构造函数和析构函数,如果自己不自定义,那么将会调用自带的空析构和构造函数
默认情况下,c++编译器至少给一个类添加3个函数
- 默认构造函数(无参,函数体为空)
- 默认析构函数(无参,函数体为空)
- 默认拷贝构造函数,对属性进行值拷贝(浅拷贝)
- 赋值运算符operator =,对属性进行值拷贝。
构造函数调用规则如下:
1.如果用户定义有参构造函数,c++不再提供默认的无参构造函数
2.如果用户定义拷贝构造函数,c++不会再提供其他构造函数
构造函数
初始化对象
语法: 类名(){}
1.构造函数,没有返回值也不写void
2.函数名称和类名相同
3.构造函数可以有参数,因此可以发生重载
4.程序在调用对象的时候会自动调用构造函数,无须手动调用,而且只会调用一次
构造函数的分类及调用
1.有参构造
- 拷贝构造函数
person(const person &p){
//将p的类所有属性,拷贝到本类身上
age = p.age;
}
####### 深拷贝和浅拷贝
1.浅拷贝:把p1中的数据全部复制一遍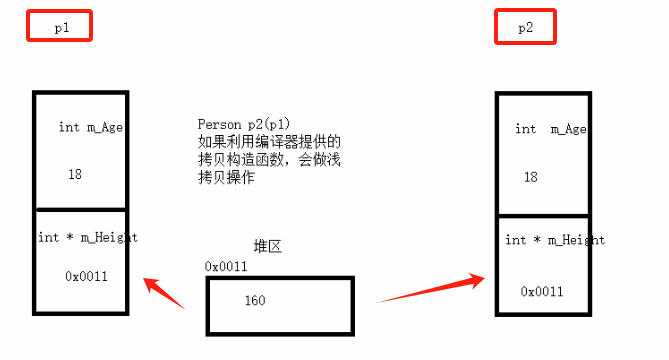
问题:析构函数中,如果写了释放堆内存的代码,释放p1后再释放p2,可能存在堆区的内存重复释放;
因为都释放了0x0011
2.深拷贝:不仅将p1中的数据全部复制一遍,对于存储的指针的变量还会开辟新内存,再存入
初始化列表
c++提供了初始化列表语法,用来初始化属性
语法:构造函数():属性1(值1),属性2(值2)……{}
//构造函数
person():name("张三"),id(1){
}
person(string name = "张三",int id = 1):name(name),id(id){
}
2.无参构造
构造函数的调用
- 括号法:
person p;//默认构造函数调用
person p2(10);//有参构造函数
person p3(p);//拷贝构造函数
//注意事项
//调用默认构造函数的时候,不要加()
//因为下面这行代码,编译器会认为这是一个自定义的函数声明
person p1(); // 跟 void func(); 一样
- 显示法
person p1;
person p2 = person(10);//有参构造
person p3 = person(p2);//拷贝构造
person(10);//匿名对象
//特点:当前行执行完成之后,会里面回收这个对象
person(p3);
//不要利用拷贝构造函数 初始化匿名对象
//编译器会认为:person(p3); == person p3;
- 隐式转换法
person p4 = 10; //相当于写了:person p4 = person(10);
person p5 = p4; //拷贝构造
拷贝构造函数的调用时机
1.使用一个创建完毕的对象来初始化另一个对象
2.在函数形参调用,进行值传递时
3.在函数返回值调用,进行值传递返回时
析构函数
清理对象中构造在堆中的数据
语法:~类名(){}
1.析构函数,没有返回值也不写void
2.函数名称和类名相同,在名称前加~号
3.析构函数不可以有参数,因此不可以发生重载
4.程序在对象销毁前会自动调用析构函数,无须手动调用,而且只会调用一次
静态成员
静态成员就是在成员变量和成员函数前加上关键字static,称为静态成员
- 静态成员变量
- 所有对象共享同一份数据
- 在编译阶段分配内存
- 类内声明,类外初始化
//静态成员变量也是有访问权限的
class person{
public:
static int m_A;
private:
static int m_B;
}
int person::m_A = 100;
int main(){
//访问时
//m_B是私有权限,类外无法访问;
//1.通过对象进行访问
person p;
cout<<p.m_A<<endl;
//2.通过类名进行访问
cout<<person::m_A<<endl;
}
- 静态成员函数
- 所有对象共享同一个函数
- 静态成员函数只能访问静态成员变量(因为编译时,静态成员函数就构建好了,如果访问变量的话,不知道访问哪个变量类的成员变量)
this指针概念
每一个非静态成员只会诞生一份函数实例,也就是说多个同类型的对象会共用同一块代码。通过this指针可以区分那个对象调用函数的
c++通过提供特殊的对象指针,this指针,指向被调用的成员函数所属的对象,本质是一个指针常量,指针的指向是不可修改的。
this指针不需要定义,直接使用即可。
class person{
public:
int m_Age;//m_ == member
person(int age){
this->m_Age = age;
}
person addAge(person p1){
//this指向的是p1的指针
//而*this指向的就是p1这个对象
this->m_Age += p1.m_Age;
}
}
int main(){
person p;
p.addAge(p);
//注意:此时addAge返回的是一个被拷贝的值,而不是p
}
在成员函数后面加const,修饰的是this的指向,让指针指向的值也不可以修改。这个函数后面加const,这个函数就是常函数。
常对象:声明对象前加const称该对象为常对象
常对象只能调用常函数。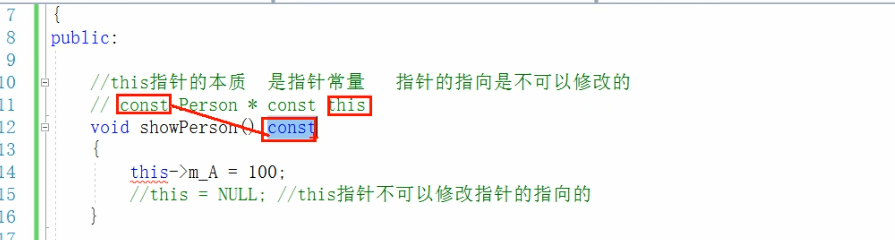
mutable特殊变量
mutable的特殊变量修饰词,即使在常函数中,也可以修改这个值
class person
{
int m_A;
mutable int m_B;
}
int main(){
person p;
p.m_A = 10;//报错
p.m_B = 100;//不会报错
return 0;
}
友元
生活中你的家有客厅(public),卧室(private)
客厅所有客人都可以访问,但是卧室是私有的只有自己可以进去,但是可以允许你的好朋友进去。
同比:
在程序里,有些私有属性也想让类外特殊的一些函数或者类进行访问,就需要用到友元的技术。
友元目的:让一个函数或类,访问另一个类中私有成员
关键字:friend
实现:
- 全局函数做友元
class Building{
friend void goodGay(Building * building);
public:
Building(){}
private:
string m_BedRoom;
}
void goodGay(Building * building){
cout << building -> m_BedRoom << endl;
}
- 友元类
class GoodGay{
public:
void visit(){
cout << building->m_BedRoom<<endl;
}//访问building中的私有属性
Building *building;
}
class Building{
friend class GoodGay;
public:
Building(){}
private:
string m_BedRoom;
}
- 成员函数做友元
class GoodGay{
public:
void visit(){
cout << building->m_BedRoom<<endl;
}//访问building中的私有属性
Building *building;
}
class Building{
//
friend void GoodGay::visit();
public:
Building(){}
private:
string m_BedRoom;
}
运算符重载
对已有的运算符进行重新定义,适用不同的数据类型
对应自定义的类相加,没有相应的运算符算法,需要自己重载定义
person p2,p1;
person p3 = p2 + p1
加号运算符重载
实现两个自定义数据类型相加的运算
operator+
//成员函数重载
class person{
public:
int m_A;
int m_B;
person operator+(person &p2){
person temp;
temp.m_A = m_A +p2.m_A;
temp.m_B = m_B +p2.m_B;
return temp;
}
}
//全局函数重载
person operator+(person &p1,person &p2){
person temp;
temp.m_A = p1.m_A +p2.m_A;
temp.m_B = p1.m_B +p2.m_B;
return temp;
}
int main(){
person p1,p2;
p1.m_A = 10;
p1.m_B = 20;
p2.m_A = 10;
p2.m_B = 20;
//成员函数重载本质调用
person p3 = p1.operator+(p2);
//全局函数的调用
person p4 = operatoe(p1,p2)
person p5 = p1+p2
}
左移运算符的重载
<<
用于 cout<< person <<endl;
//一般不会利用成员函数重载<<运算符,因为无法实现cout在左侧
void operator<<(cout){}//错误
//全局函数
//cout全局只有一个,所以只能用引用的方式
ostream & operator<<(ostream &cout,person &p){
cout<< p.m_name;
return cout;
}
//如果m_name是私有private成员,则全局函数不能访问此成员。
//因此应该将这个重载的全局函数设为person的友元
递增运算符
//前置++
person& operator++(){
m_num++;
return *this
}
//后置++
//int代表占位参数,可以用于区分前置或后置的++
person& operator++(int){
//先记录当前结果
person temp = *this
m_num++;
//把记录结果返回
return temp;
}
赋值运算符
person& opertor=(person &p){
//深拷贝
//1.先判断是否有属性在堆区,如果有先释放干净,然后再深拷贝
if (m_age != NULL){
delete m_age;
m_age = NULL;
}
m_age = new int(*p.m_age);
return *this;//返回自身,不然无法用 p1=p2 =p3
}
关系运算符重载
==
bool operator==(person &p){
if (m_age ==p.m_age)&&(m_name == p.m_name){
return true;
}
return false;
}
bool operator!=(person &p){
if (m_age !=p.m_age)||(m_name != p.m_name){
return true;
}
return false;
}
仿函数(函数调用运算符重载)
由于重载后使用的方式非常像函数的调用,因此被称为仿函数
class person{
public:
void operator()(string test){
cout << test<<endl;
}
}
//全局函数
void myPrint(string test){
cout << test <<endl;
}
//调用时,使用起来和全局函数一样,所以叫仿函数
person p1;
p1("12434");
//匿名函数对象:
person()("12345")//person()返回了一个匿名函数对象,用了一次就释放了。
myPrint("1234");
文件读取
c++中对文件操作需要包含头文件
操作文件的三大类:
- ofstream :写操作
- ifstream: 读操作
- fstream: 读写操作
写文件
步骤:
1、包含头文件
#include
2.创建流对象
ofstream ofs;
3.打开文件
ofs.open(“文件路径”,打开方式);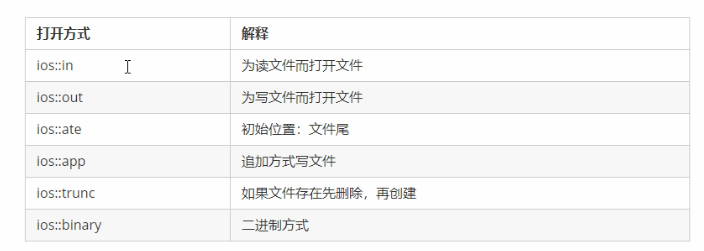
注意:文件打开方式可以配合使用,利用|操作符
例如:用二进制方式写文件 ios::binary | ios::out
4.写数据
ofs<<“写入的数据”;
5.关闭文件
ofs.close();
二进制写文件
以二进制的方式对文件进行读写操作
//主要调用流对象调用成员函数write
函数原型:ostream& write(const char* buffer,int len)
字符指针buffer指向内存中一段存储空间,len是读写的字节数
//主要调用流对象调用成员函数write
class person{
public:
char m_Name[64];
int m_Age;
};
void wFile(){
//创建+打开文件
ofstream ofs("./text.txt",ios::out | ios:: binary);
person p = {"张三",18};
ofs.write((const char *)&p,sizeof(person));
ofs.close();
}
读文件
1.包含头文件
#include
2.创建流对象
ifstream ifs;
3.打开文件并判断文件是否打开成功
ifs.open(“文件路径”,打开方式);
4.读数据
- 用数组读取
char buf[1024] = {0};
//当ifs读出结尾则会退出循环
while(ifs >> buf){
cout<<buf<<endl;
}
- ifs.getline(buf)
char buf[1024] = {0};
while(ifs.getline(buf,sizeof(buf))){
cout << buf <<endl;
}
- string读取
string buf;
//一行一行读取
while(getline(ifs.buf)){
cout << buf <<endl;
}
- 单个字符读取
char c;
//EOF 是end of file
whlie((c = ifs.get()) != EOF){
cout<< c;
}
5.关闭文件
ifs.close();
二进制读文件
void rWrite(){
ifstream ifs;
ifs.open("text.txt",ios::in | ios:: binary);
if (!ifs.is_open()){
cout<<"文件打开失败"<<endl;
}
person p;
ifs.read((char *)&p,sizeof(person));
ifs.close();
}
void Manager::LoadFile() {
ifstream ifs;
ifs.open("./text.csv", ios::in | ios::binary);
if (!ifs.is_open()) {
cout << "当前没有比赛记录" << endl;
ifs.close();
return;
}
else {
map<int, string> record;
string data;
int index = 0;
while (ifs >> data) {
int pos = -1;
int start = 0;
string r;
int in = 0;
while (true) {
pos = data.find(",",start);
if (pos == -1) {
break;
}
//找到了进行分割
string tmp = data.substr(start, pos - start);
in++;
switch (in) {
case 1:
case 4:
case 7:
r += "编号为:" + tmp+" ";
break;
case 2:
case 5:
case 8:
r += "选手名称为:" + tmp + " ";
break;
case 3:
case 6:
case 9:
r += "最后得分为:"+ tmp + "\n";
break;
}
start = pos + 1;
}
r += "\n";
index++;
record.insert(make_pair(index, r));
}
for (map<int, string>::iterator it = record.begin(); it != record.end(); it++) {
cout << "第" << it->first << "场比赛\n" << "结果为:\n" << it->second << endl;
}
}
ifs.close();
system("pause");
};
泛型编程和STL
模板
模板:是建立通用的模具,大大提高复用性
语法:
template<typename T>
函数声明
- template --声明创建模板
- typename --表明其后面的符号是一种数据类型,可以用class代替
- T --通用的数据类型,名称可以替换,通常为大写字母
函数模板
template<typename T>
//声明一个模板,告诉编译器后面代码中紧跟着的T不要报错
//T是一个通用的数据模型
void mySwap(T &a,T &b){
T temp = a;
a = b;
b = temp;
}
//调用
void test(){
int a=10;
int b=20;
// 1. 自动类型推导
//(ab必须是同样的数据类型T,如果b为double则不可使用)
mySwap(a,b);
//2.显示指定类型
mySwap<int>(a,b);
}
//无法确定class的数据类型
template<class T>
void func(){
cout<<"调用"<<endl;
}
void test(){
//模板必须确定出T的数据类型,才可以使用
func<int>();
//通过空模板参数列表,强制调用函数模板
func<>();
}
模板的局限性
模板并不是万能的,有些特定数据类型,需要用具体化方式做特殊实现
//对比两个类变量是否相等
template<class T>
void func(T &a,T &b){
if(a == b){
return true;
}else{
return false;
}
}
class person{
public:
string m_Name;
int m_age;
}
void test(){
person a = person("张三",12);
person b = person("李四",13);
func(a,b);//错误,因为a==b没有具体调用实现
//解决方案:
//1.函数成员重载==
//2.重载模板func函数,具体写为void func(person &a,person &b)
}
类模板
建立一个通用类,类中的成员数据类型可以不具体指定,用一个虚拟的类型来代表
template<typename T>
类
template<class NameType,class AgeType>
class Person
{
public:
NameType m_Name;
AgeType m_Age;
Person(NameType m_Name,AgeType m_Age){
this->m_Name = m_Name;
this->m_Age = m_Age;
}
}
void test(){
Person<string,int>p1("孙悟空",999);
}
类模板中成员函和普通类中成员函数创建实际是有区别的:
1.普通类中的成员函数一开始就可以创建
2.类模板中的成员函数在调用时才创建实例
类模板做函数入参
template<class T1,class T2>
class Person
{
public:
T1 m_Name;
T2 m_Age;
Person(T1 m_Name,T2 m_Age){
this->m_Name = m_Name;
this->m_Age = m_Age;
}
void showPerson(){
cout<<this->m_Name<<this->m_Age<<endl;
}
}
//入参必须指定类的成员变量类型
//1.指定参数入参类型
void printPerson(Person<string,int> &p){
p.showPerson();
}
//2.参数模板化
template<class T1,class T2>
void printPerson2(Person<T1,T2> &p){
cout << "t1的类型为:"<< typeid(T1).name()<<endl;
p.showPerson();
}
//3.整个类模板化
template<class T>
void printPerson3(T &p){
p.showPerson();
}
类模板与继承
- 子类继承的父类是一个类模板时,子类在声明的时候,要指定出父类的T的类型
- 如果不指定,编译器无法给子类分配内存
- 如果想灵活指定出父类中T中的类型,子类也需要变为类模板
template<class T1>
class Base
{
public:
T1 m_Name;
}
class Person:public Base{}//报错的定义,必须指定T1数据类型
class Person:public Base<int>{}//正确
template<class T1,class T2>
class Person2:public Base<T1>{
public:
T2 m_age;
Person2(){};
}
//构造函数的类外实现
template<class T1,class T2>
Person2<T1,T2>::Person2(T1 name,T2 age){
this->m_Name = name;
this->m_age = age;
}
void test(){
Person2<int,char> s2;
}
类模板的分文件
- 第一种解决方式:
需要引用“xxx.cpp”
因为类模板中的成员函数在调用时才创建实例
只引用了“xxx.h”编译时没有创建相应的成员函数调用,所以会报错
或者
- 第二种解决方式:将.h和.cpp中的内容写到一起,将后缀改为.hpp文件
类模板的友元的类外实现
建议还是在类内实现,因为类外太麻烦
//提前让编译器指定person存在
template<class T1,class T2>
class Person;
//类外实现
template<class T1,class T2>
void printPerson(Person<T1,T2> p){
cout << p.m_Name << p.m_age;
}
类模板与函数模板的区别
- 类模板没有自动类型推导的使用方式
- 类模板在模板参数列表中可以有默认参数
template<class NameType,class AgeType =
int>
class Person
{
public:
NameType m_Name;
AgeType m_Age;
Person(NameType m_Name,AgeType m_Age){
this->m_Name = m_Name;
this->m_Age = m_Age;
}
}
void test(){
Person<string>p1("孙悟空",999);
}
STL
stl(standard template library)标准模板库
stl从广义上分为:容器,算法,迭代器
实际上有六大组件:
- 容器:各种数据结构,如vector、list、deque、map等,用来存数据
- 算法:各种常用的算法,如sort、find、copy、for_each
- 迭代器:容器与算法之前的胶合剂
可以一次访问容器所含的各个元素。
常用的容器迭代器种类为:双向迭代器,随机访问迭代器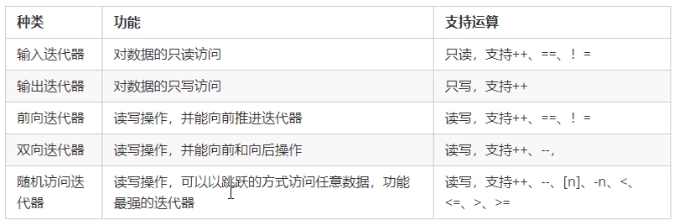
- 仿函数:行为类似函数,可作为算法的某种策略
- 适配器(配接器):修饰容器或仿函数或迭代器接口的东西
- 空间配置器:负责空间的配置与管理
容器和算法之间通过迭代器进行无缝连接,stl几乎所有代码都采用了模板类或者模板函数
容器
*vector(单端数组)
容器:vector
算法:for_each
迭代器:vertor::iterator
数组是静态空间,而vector可以动态扩展
动态扩展:创建一个更大的空间,并把原数据拷贝到新空间,释放原来的空间。
#include<vector>
void test(){
//创建了一个vector容器,数组
vector<int> v;
//插入数据
v.push_back(10);
v.push_back(20);
v.push_back(30);
v.push_back(40);
//通过迭代器访问容器中的数据
vector<int>::iterator isBegin = v.begin();
//起始迭代器,指向容器中第一个元素
vector<int>::iterator isEnd= v.end();
//结束迭代器,指向容器中最后一个元素的下一个位置
//第一种遍历方式:
while(itBegin != itEnd){
cout << *itBegin <<endl;
itBegin++;
}
//第二种遍历方式
for(vector<int>::iterator it = v.begin();it != v.end();it++){
cout << *it << endl;
}
}
//第三种遍历方法,利用stl提供的遍历方法
#include<algorithm>
void myPrint(int val){
cout << val << endl;
}
void test01(){
vector<int> v;
v.push_back(10);
v.push_back(20);
v.push_back(30);
v.push_back(40);
//函数回调myPrint
for_each(v.begin(),v.end(),myPrint);
}
class Person{
public:
string m_Name;
int m_Age;
Person(string name,int age){
this->m_Name = name;
this->m_Age = age;
}
};
void test(){
vector<Person> v;
Person p1("aaa",10);
Person p2("aab",20);
Person p3("aac",30);
Person p4("aad",40);
//向容器中添加数据
v.push_back(p1);
v.push_back(p2);
v.push_back(p3);
v.push_back(p4);
//遍历容器中的数据
for(vector<Person>::iterator it = v.begin();it != v.end();it++){
cout<< (*it).m_Name<<endl;
cout<<it->m_Age<<endl;
}
}
//创建自定义类的指针的容器
void test(){
vector<Person *> v;
Person p1("aaa",10);
Person p2("aab",20);
Person p3("aac",30);
Person p4("aad",40);
//向容器中添加数据
v.push_back(&p1);
v.push_back(&p2);
v.push_back(&p3);
v.push_back(&p4);
//遍历容器中的数据
for(vector<Person>::iterator it = v.begin();it != v.end();it++){
cout<< *(*it).m_Name<<endl;
cout<<(*it)->m_Age<<endl;
}
}
void test(){
vector<vector<int>> v;
//创建子容器
vector<int> v1,v2,v3,v4;
for(int i = 0;i<4;i++){
v1.push_back(i+1);
v2.push_back(i+2);
v3.push_back(i+3);
v4.push_back(i+4);
}
//将小容器插入大容器中
v.push_back(v1);
v.push_back(v2);
v.push_back(v3);
v.push_back(v4);
//遍历:
for(vector<vector<int>>::iterator it = v.begin();it != v.end();it++){
for(vector<int>::iterator vit = it.begin();vit != it.end();vit++){
cout << (*vit) << endl;
}
}
}
vector的构造函数

vector的容量和大小

vector插入和删除

vector数据存取

vector互换容器
两个容器的元素进行互换
实际用途:使用swap可以收缩内存空间
vector<int>v;
for(int i = 0;i<100000;i++){
v.push_back(i);
}
//此时v的容量为130000+,而实际大小为100000
v.rsize(3);//重新指定v的长度为3,多出的元素被容器删除,但
vector<int>(v).swap(v);
//根v创建一个匿名对象,
//匿名对象指向的内存空间和v指向的匿名空间交换
//匿名对象在这个语句执行之后就被释放了
//v之前创建的100000空间也随之释放。
//而新创建的匿名对象的大小按照v来创建的,所以大小为3
vector预留空间

不用频繁拷贝容器。
string容器
string是c++风格的字符串,而string本质上是一个类
string和char 的区别:
1.char 是一个指针
2.string是一个类,类内部封装了char,管理这个字符串,是char型的一个容器
string的构造函数:
1.string();//创建一个空的字符串
string(const char *s)//使用字符串s初始化
2.string(const string &s);//使用一个string对象初始化另一个string对象
3.string(int n,char c);//使用n个字符c初始化
字符串赋值

字符串拼接

string的查找和替换
find和rfind的区别:rfind从右往左查找 find从左往右查找
string字符存取


deque容器(双端数组)
双端数组,可以对头端进行插入、删除操作
deque内部有个中控器,维护每段缓冲区的内容,缓冲区中存放真实数据
中控器维护的是每个缓冲区的地址,使得使用deque时像一片连续的内存空间,
头尾插入时,从缓冲区内空的空间进行插入;如果没有空间了,则会开辟新的缓冲区,在中控器中记录开辟的新缓冲区的地址。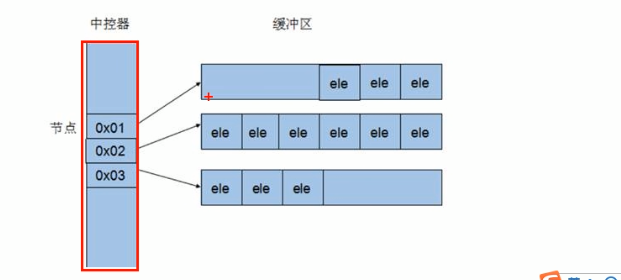
构造函数

赋值操作

大小改变操作

插入和删除

数据存取

排序

从小到大,升序排列
stack(栈)

queue(队列)

*list(链表)
链表的组成:由一系列的结点组成
结点的组成:一个时存储数据元素的数据域,另一个时存储下一个结点地址的指针域
优点:可以从任意位置插入或删除元素
缺点:遍历速度没有vector快,占用空间更大
赋值函数

构造函数

大小改变

插入和删除

数据存取

反转和排序

反转:队尾变队头,队头变队尾
自定义数据类型的排序
class person{
public :
string name;
int age;
int height;
person(string name,int age,int height){
this->name = name;
this->age = age;
this->height = height;
}
};
//写排序回调函数,按照年龄从小到大,如果年龄相同则按身高从高到底
bool comparePerson(person &p1,person &p2){
if (p1.age == p2.age){
return p1.height > p2.height;
}
return p1.age < p2.age;
}
void test(){
list<person> l;
//插入数据
person p1("张三",45,160);
//……
l.push_back(p1);
//遍历
for(list<person>::iterator it = l.begin();it != l.end();it++){
cout <<"姓名:"<<(*it).name;
}
//排序
l.sort(comparePerson);
}
SET/multise容器
set:
所有元素都会在插入时被自动排序(默认从小到大)
本质:
属于关联式容器,底层结构是用二叉树实现
set和multise的区别
- set不允许容器中有重复的元素
如果有重复元素不会报错,但是不会插入成功
- multise允许容器中有重复的元素
插入数据删除数据
只有insert方法,不是pop_back
set<int> s;
pair<set<int>::iterator,bool> ret = s.insert(10);
if(ret.second){
cout <<"第一次插入成功"<<endl;
}else{
cout <<"第一次插入失败"<<endl;
}
大小改变

set查找和统计

改变set排序
利用仿函数,可以改变排序规则
class myComapare{
public:
bool operator(int v1,int v2){
return v1>v2;
}
}
void test(){
//默认排序
set<int> s;
s.insert(10);
s.insert(20);
s.insert(30);
s.insert(40);
//自定义排序
set<int,myComapare>s2;
}
自定义数据类型,都会指定排序规则
主要实现为:写仿函数(重写())
map&&multimap
- map中所有元素都是pair
- pair中第一个元素为key(键值),起到索引作用,第二个元素为value(实际的值)
- 所有元素都会根据元素的键值自动排序
map属于关联式容器,底层结构式用二叉树实现
map&&multimap的区别
- map不允许容器中有重复key值的元素
- multimap允许容器中有重复键值的元素
//创建map容器
map<int,int> m;
//插入
//第一种
m.insert(pair<int,int>(1,10));
//第二种
m.insert(make_pair(2,20));
//第三种
m.insert(map<int,int>::value_type(3,30));
//第四种
m[4]=40;
//删除
//第一种
m.erase(m.begin());
//第二种
//按照key删除
m.erase(3);
//第三种
//全清空
m.clear();

map查找和统计
对于map,结果为0或者1
multimap,结果>=0的整数
map自定义排序
写一个有仿函数的类(自定义类型必须要指定排序规则)
class myComapare{
public:
bool operator(int v1,int v2){
return v1>v2;
}
}
算法
算法在使用时,需要包含头文件
#include<algorithm>
函数对象
重载函数调用操作符的类,其对象被称为函数对象
函数对象使用重载()时,行为类似函数调用,也叫仿函数。
- 函数对象可以作为参数传递
### 谓词 仿函数,返回值类型是bool数据类型,称为谓词 #### 一元谓词 入参只有一个元素 ###### find_if() 查找容器中有满足某个条件的数据 ```cpp class person{ public: string name; int age; }
class biger5{
public :
bool operator()(person &a){
return a.age>18;
}
}
void test(){
vector v;
v.pop_back(person p1(“张三”,20));
v.pop_back(person p2(“李四”,2));
vector<person>::iterator it = find_if(v.begin(),v.end(),biger5());
if(it == v.end()){
cout << "未找到"<<endl;
}else{
cout << "找到了名称为"<< (*t).name<<endl;
}
}
<a name="Kphtz"></a>
###### 二元谓词
**入参有两个元素**<br />改变sort的排序策略,需要出参写一个bool,入参两个元素。<br />return a>b;//从大到小排列<br />return a<b;//从小到大排列
<a name="EqX9D"></a>
###### 算术仿函数
<br />使用内建(c++定义好的)函数对象时,需要引入头文件<br />**#include <functional>**
<a name="Nzc2a"></a>
###### 关系仿函数

<a name="DpQ24"></a>
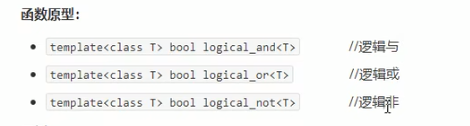
###### 逻辑仿函数
<a name="CKSC2"></a>
###### 遍历仿函数
func为回调函数<br /><br />遍历并搬运赋值到另一个容器<br />
<a name="ocW3a"></a>
###### 常用查找算法
<br /><br />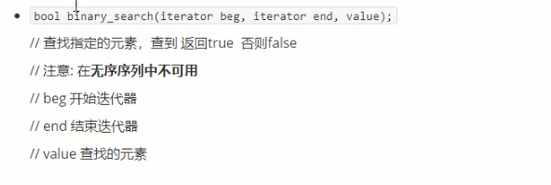<br /><br />cout满足条件的元素数量<br />
<a name="pLIrh"></a>
###### 常用排序算法
<br />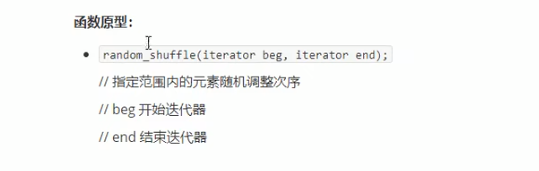<br /><br />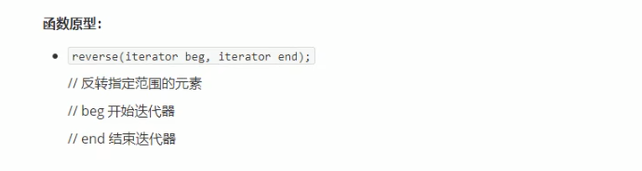
<a name="SIyDI"></a>
###### 拷贝和替换算法
<br /><br />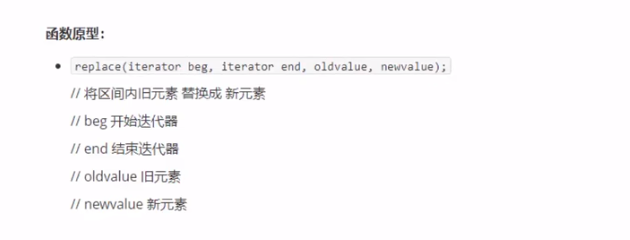<br /><br />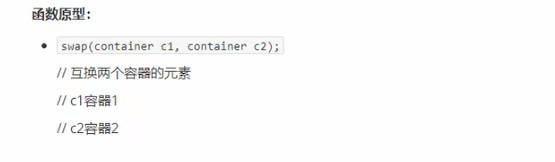
<a name="FLQ1S"></a>
###### 常用算术生成算法
<br /><br />容器创建完成之后再在其中填充值<br />
<a name="cg0Gy"></a>
###### 常用集合算法
<br />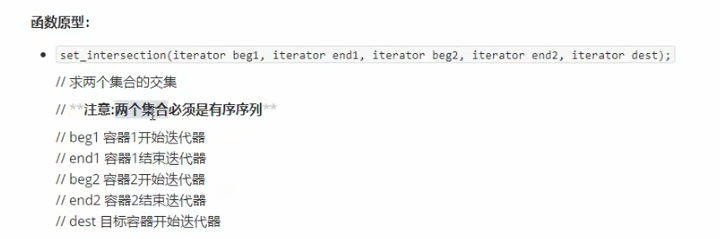<br />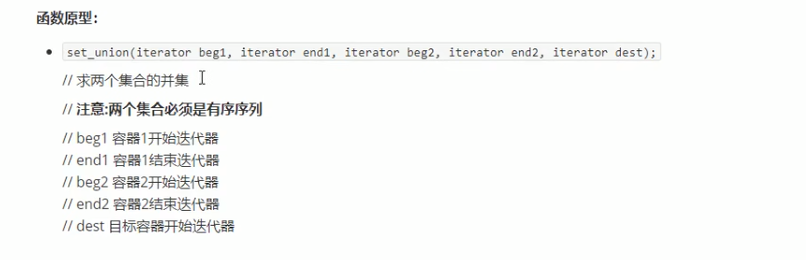<br />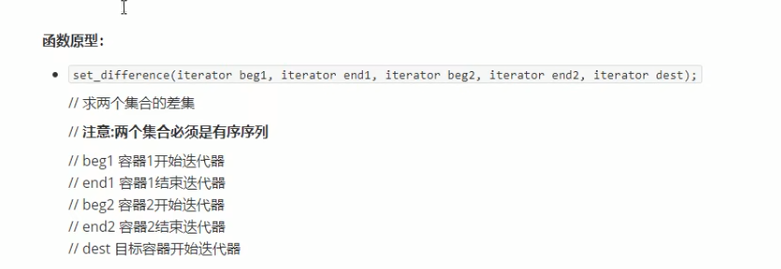<br />三个仿函数的返回值都是集合的最后一个元素的位置。<br />输出时,在返回值处结束就行,不然多开辟的空间会输出默认值。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!