机器学习的一般步骤
2023-12-30 05:03:30
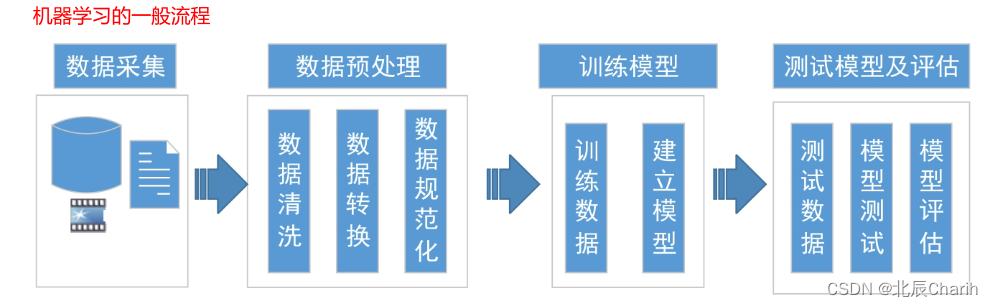
机器学习专注于让机器从大量的数据中模拟人类思考和归纳总结的过程,获得计算模型并自动判断和推测相应的输出结果。机器学习的一般步骤可以概括为以下几个阶段:
-
数据收集和准备:
- 收集与问题相关的数据,并确保数据的质量和完整性。
- 对数据进行探索性分析,了解数据的特征、分布和相关性。
- 对数据进行预处理,包括数据清洗、缺失值处理、特征选择、特征转换等。
-
数据划分:
- 将数据集划分为训练集、验证集和测试集。
- 训练集用于模型的训练和参数调优。
- 验证集用于模型的选择和调参。
- 测试集用于评估模型的性能。
-
特征工程(对收集到的数据进行预处理,包括数据的清洗、数据的转换、数据标准化、缺失值的处理、特征的提取、数据的降维等):
- 根据问题的需求和数据的特点进行特征工程,包括特征提取、特征表示和特征构建。
- 可以使用统计方法、领域知识或者自动化特征选择算法来选择最优的特征子集。
-
模型选择和训练:
- 根据问题的类型和数据的特点选择适合的机器学习算法。
选择机器学习模型进行训练:首先,根据要处理的数据有没有标签来确定选择监督学习模型还是非监督学习模型;其次,根据预测值是离散的还是连续的,确定采用分类问题算法还是回归问题算法。在选择模型时,通常会比较不同模型训练的结果,优先考虑性能最佳的。? - 使用训练集对选定的模型进行训练,并调整模型的超参数。
- 可以使用交叉验证等技术来评估模型的性能和泛化能力。
- 根据问题的类型和数据的特点选择适合的机器学习算法。
-
模型评估和优化:
- 使用验证集评估模型的性能,并根据评估结果调整模型的参数。
- 可以使用不同的性能指标(如准确率、精确率、召回率、F1-score等)来评估模型的性能。
- 如果模型性能不满足需求,可以尝试改进特征工程、调整模型结构或尝试其他算法。
注:在信息检索领域,通常采用查准率、召回率等指标来评价模型的好坏;在推荐系统领域,有推荐的准确率、多样性和覆盖率等评价指标。此外,针对小数据集,还可以采用交叉验证来保证模型结果的可靠性。针对欠拟合和过拟合问题,可通过对模型进行正则化等策略进行缓解。
-
模型测试和部署:
- 使用测试集对最终确定的模型进行评估,验证模型的泛化能力。
- 如果模型通过测试,可以将其部署到实际应用中进行预测和推断。
- 监测模型在实际应用中的性能,并根据需要进行模型更新和改进。
 这些步骤通常是迭代性的,需要不断地进行调整和改进。同时,选择合适的算法、特征工程和评估指标也是非常重要的,需要根据具体问题和数据进行灵活选择。
这些步骤通常是迭代性的,需要不断地进行调整和改进。同时,选择合适的算法、特征工程和评估指标也是非常重要的,需要根据具体问题和数据进行灵活选择。
值得注意的是,不同的机器学习任务可能会有所差异,因此具体的步骤可能会有所调整和扩展。
“数据决定了机器学习的上界,而模型和算法只是逼近这个上界。”这句话体现了,数据在机器学习过程中的重要地位。即使你提出的模型和算法再好,如果没有高质量的数据,其效果也会非常差。
文章来源:https://blog.csdn.net/m0_62110645/article/details/135300013
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!