初探 Reactor、Proactor 线程模型与 BIO、AIO、NIO
1 前言
工作中或者是技术上经常会遇到 I/O 、线程模型相关的问题,以及同步、异步、阻塞、非阻塞等各种基础问题,之前上学时候的概念认知总是模糊的,一知半解。趁这次了解希望能够更加深入的去了解这方面的知识,于是有了接下来这篇文章。
2 概念介绍
BIO/NIO/AIO 这些只是数据传输的输入输出流的一些形式而已。也就是说他们的本质就是输入输出流。只是存在同步异步,阻塞和非阻塞的问题。
reactor 和 proactor 呢,Reactors 和 Proactors 是两种用于处理并发网络请求的线程模型。它们主要用于高性能网络服务器和应用程序中,用以有效地管理多个同时发生的连接和请求。
总结来说,BIO、NIO和 AIO 是处理 I/O操作的不同方式,分别对应同步阻塞、同步非阻塞和异步非阻塞I/O。Reactor模型通常与NIO结合使用,而Proactor模型则与AIO结合使用,这样可以有效地处理高并发网络请求。这些模型的选择取决于应用程序的需求和特定的使用场景。
接下来也是文章会对他们一一进行大概的介绍。
3 操作 IO 的方式
首先说到这里,我们需要理解 IO 的原理。
无论是 Java 还是其他的语言,本质上 IO 读写操作的原理是类似的,编程语言开发的程序,一般都是工作在用户态空间,但由于 IO 读写对于计算机而言,属于高危操作,所以 OS 不可能 100% 将这些功能开放给用户态的程序使用,所以正常情况下的程序读写操作,本质上都是在调用 OS 内核提供的函数:read()、 write()。
也就是说,在程序中试图利用 IO 机制读写数据时,仅仅只是调用了内核提供的接口函数而已,本质上真正的 IO 操作还是由内核自己去完成的。
IO 的分类又有哪些呢
IO 以不同的维度划分,可以被分为多种类型,比如可以从工作层面划分成磁盘 IO(本地 IO)和网络 IO:
磁盘 IO:指计算机本地的输入输出,从本地读取一张图片、一段音频、一个视频载入内存,这都可以被称为是磁盘 IO。
网络 IO:指计算机网络层的输入输出,比如请求 / 响应、下载 / 上传等,都能够被称为网络 IO。
也可以从工作模式上划分,例如常听的 BIO、NIO、AIO,还可以从工作性质上分为阻塞式 IO 与非阻塞式 IO,亦或从多线程角度也可被分为同步 IO 与异步 IO.
3.1 同步与异步、阻塞与非阻塞
阻塞 IO
先来看看阻塞 I/O,当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。过程如下图:

非阻塞 IO
来看看非阻塞 I/O,非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。过程如下图:
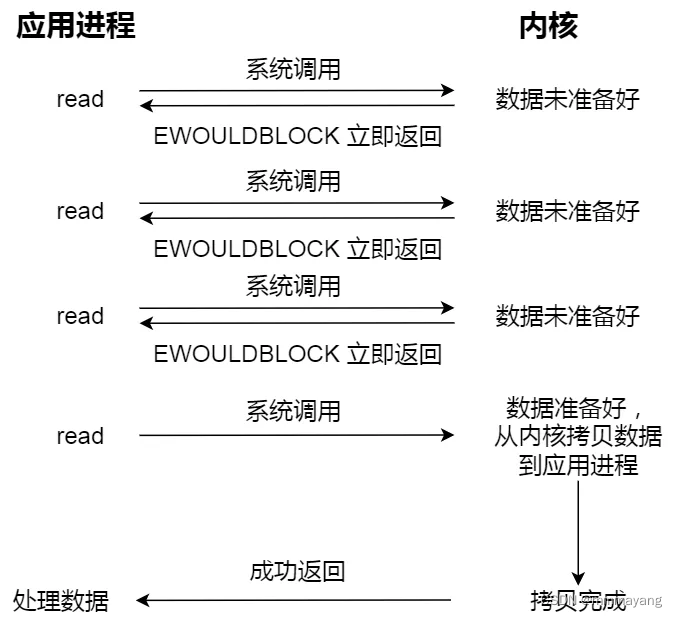
注意,这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。只是非阻塞说不会去等待数据准备好的这个过程。在中间线程可以去干别的事,对于数据的拷贝以及返回还是同步的。
异步
因此,无论 read 和 send 是阻塞 I/O,还是非阻塞 I/O 都是同步调用。因为在 read 调用时,内核将数据从内核空间拷贝到用户空间的过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
而真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。当我们发起 aio_read (异步 I/O) 之后,就立即返回,内核自动将数据从内核空间拷贝到用户空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。过程如下图:
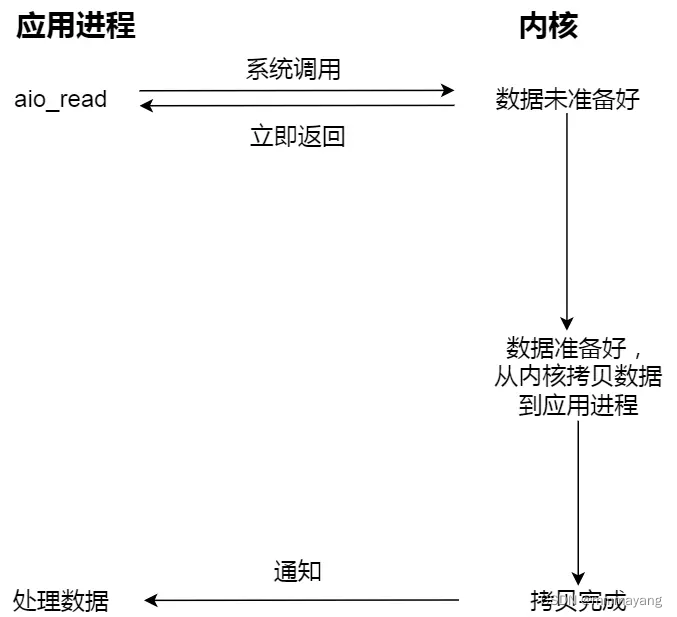
很明显,异步 I/O 比同步 I/O 性能更好,因为异步 I/O 在「内核数据准备好」和「数据从内核空间拷贝到用户空间」这两个过程都不用等待。
这里顺便说个题外话什么是零拷贝
3.2 零拷贝
零拷贝(Zero-Copy)是一种在计算机系统中高效传输数据的技术,尤其在网络和文件系统操作中非常重要。它的核心目标是减少数据在系统内部传输过程中的拷贝次数,从而提高效率和减少延迟。零拷贝并不意味着没有任何数据拷贝发生,而是减少了在用户空间和内核空间之间的数据拷贝。
在理解零拷贝之前,我们先看看传统的数据传输过程:
在传统的数据传输(特别是在网络传输和文件读写中)中,数据通常会经历多次拷贝:
.从磁盘到内核空间:首先,数据从磁盘读取到内核空间的缓冲区。
从内核空间到用户空间:然后,数据被拷贝到用户空间的应用程序缓冲区。
再次从用户空间到内核空间:当数据需要发送到网络时,它再次被拷贝回内核空间的网络缓冲区。
最后从内核空间到网络接口:最后,数据从内核空间发送到网络接口。
这种传统方法中,数据在用户空间和内核空间之间多次来回拷贝,造成了不必要的CPU负载和内存带宽消耗。
零拷贝
零拷贝技术的目的是减少这种在用户空间和内核空间之间的拷贝次数。它通常通过以下方式实现:
内核缓冲区直接传输:数据可以直接从内核缓冲区传输到网络,无需拷贝到用户空间。
内存映射(Memory-mapped files):应用程序可以通过映射文件到内存的方式直接在用户空间访问文件数据,减少拷贝次数。
sendfile 系统调用:这是一种特殊的系统调用,它可以直接在内核空间将文件数据发送到网络,无需先拷贝到用户空间。
其中什么是内存映射呢?
内存映射文件
内存映射文件通过将文件内容映射到进程的地址空间来改变这个过程:
文件映射到内存:操作系统创建一个文件内容的映射在进程的地址空间。这个映射区域的内存地址直接对应于文件数据在磁盘上的物理位置。
.
直接访问文件数据:应用程序可以直接在映射的内存区域中读写数据,就像访问普通的内存数组一样。这样做的时候,操作系统会确保这些操作反映到底层的文件上。
.
无需用户空间和内核空间之间的拷贝:因为应用程序直接在映射的内存区域操作数据,所以不需要将数据从内核空间拷贝到用户空间。
零拷贝与同步/异步IO
零拷贝技术与同步/异步IO的关系主要体现在它如何与这些IO模型结合以提高效率:
同步IO(阻塞/非阻塞):即使是在同步IO中,使用零拷贝可以减少CPU的使用和上下文切换,提高数据处理速度。
异步IO:异步IO的本质是减少IO操作对应用程序执行流的阻塞。结合零拷贝,它可以进一步提高效率,特别是在处理大量数据时。
总之,零拷贝是一种减少数据在不同内存区域(用户空间和内核空间)之间拷贝次数的技术,从而提高数据处理效率,减少CPU负担。它与同步或异步IO的特性结合使用,可以在多种场景下提高系统性能。
其实讲述了上面的这些案例和场景,再理解下面的 BIO、NIO、AIO 就比较简单了,那我们就简单的过一下。
3.3 BIO
BIO(Blocking-IO)
原理: BIO,即阻塞式I/O,是最传统的I/O模型。在BIO中,当一个线程执行I/O操作时(如读写文件、网络通信),线程会被阻塞,直到I/O操作完成。如果I/O操作延迟,线程就会在此期间一直等待,无法执行其他任务。
底层原理: BIO通常通过系统调用实现,这意味着当一个应用程序执行I/O操作时,它会调用操作系统的功能,然后等待操作系统返回结果。在这个过程中,线程处于阻塞状态。
应用场景: 简单的客户端应用或小规模的网络应用,其中并发量不高。
3.4 NIO
NIO(Non-Blocking-IO)
原理: NIO,即非阻塞式I/O,是一种允许线程在等待I/O操作完成时继续执行其他任务的模型。在NIO中,线程可以发起多个I/O请求,然后继续执行,不会停留在任何一个请求上等待其完成。
底层原理:
- 选择器(Selector):NIO 的核心组件,允许单个线程管理多个 I/O 通道(Channel)。选择器会不断轮询注册在其上的通道,检查它们的 I/O 状态(如可读、可写)。
- 缓冲区(Buffer):NIO 中数据的处理都是通过缓冲区进行的。每个操作都是围绕缓冲区进行的。
- 通道(Channel):通道是双向的,可以用于读、写或同时进行读写操作,不像传统的流只能单向传输(输入或输出)。
应用场景: 高性能的服务器应用,如网络服务器和数据库服务器,其中需要处理大量并发连接。
其中 NIO(Non-blocking I/O)模型中的缓冲区(Buffer)和在讨论非阻塞I/O时提到的内核中的缓冲区是两个不同的概念。
NIO 中的缓冲区(Buffer)
.
定义: 在Java的NIO模型中,缓冲区是一块可以读写数据的内存区域。这个缓冲区存在于Java虚拟机(JVM)的内存中,而不是操作系统的内核空间。
作用: 缓冲区主要用于在非阻塞I/O操作过程中临时存储数据。当从一个通道(Channel)读取数据时,数据被读入到缓冲区;当往通道写数据时,数据从缓冲区写出。
类型: Java NIO 提供了多种类型的缓冲区,如 ByteBuffer, CharBuffer, IntBuffer 等,分别用于存储不同类型的数据。
控制: 缓冲区提供了对数据的细粒度控制,包括限制(limit)、位置(position)和容量(capacity)等属性,使得数据处理更加灵活。
非阻塞I/O中的内核缓冲区
.
定义: 非阻塞I/O中的内核缓冲区是操作系统内核空间中的一块内存区域,用于存储I/O操作的数据。
作用: 当进行网络或文件I/O操作时,数据会被存储在内核的缓冲区中,直到它们准备好被进程读取或已经被进程写入。
管理: 这些缓冲区完全由操作系统管理,应用程序无法直接访问或修改它们。应用程序通过系统调用与这些缓冲区交互。
总的来说,NIO 缓冲区是 Java NIO库中的一部分,由 Java 程序直接管理,主要用于 NIO 操作中的数据存储和传输。而非阻塞 I/O 中的内核缓冲区是操作系统管理的,用于在底层进行数据的存储和传输。这两者虽然都被称为“缓冲区”,但它们存在于不同的系统层次,并且由不同的实体管理。
3.5 AIO
AIO(Async-IO)
原理: AIO,即异步I/O,是一种不需要线程参与I/O操作等待的模型。在AIO模型中,应用程序可以直接发起一个I/O操作,并立即返回继续执行其他任务。当I/O操作完成后,操作系统会通知应用程序,或者启动一个回调函数处理结果。
底层原理:
- 异步通道和完成处理器: AIO通过异步通道来执行I/O操作,当操作完成时,通过完成处理器(Completion Handler)或者Future对象来通知应用程序。
- 操作系统支持: AIO需要操作系统底层支持异步I/O操作。在Linux系统中,这通常是通过IOCP(I/O Completion Port)等机制实现的。
应用场景: 适用于高并发和大规模网络应用,特别是那些I/O延迟较高的应用,如长时间等待响应的网络服务。
3.6 IO 上的区别
阻塞与否:BIO是阻塞的,NIO是非阻塞的,AIO是完全异步的。
线程使用:BIO需要为每个连接单独使用一个线程,而NIO可以使用单个线程管理多个连接,AIO则不需要线程持续等待I/O操作。
性能和适用场景:BIO适用于连接数较少且固定的应用场景,NIO适用于连接数较多但单个连接活动不是很高的场景,AIO适用于连接数多且连接非常活跃的高并发场景。
总的来说,这三种I/O模型各有优劣,
4 线程模型
4.1 Reactor 线程模型
Reactor 模型是一种事件驱动的架构模式,用于处理多个并发输入源的服务请求。这个模型主要用于实现高性能网络服务器。
工作原理
单一事件循环(Event Loop): Reactor 模式使用一个主循环,不断监听事件(如网络请求)。
事件多路分解器(Event Demultiplexer): 这个组件负责等待事件发生(例如,I/O操作完成、数据可读写等),并快速地将这些事件通知给相应的事件处理器。
事件处理器(Event Handlers): 每种类型的事件都有相应的事件处理器。当事件多路分解器捕获到事件时,它会调用对应的事件处理器进行处理。
这里我们使用小林哥文章里 [多 Reactor 多进程 / 线程] 的图概述一下。其中也有单 Reactor 单进程 / 线程的情况,后文会讲述到。
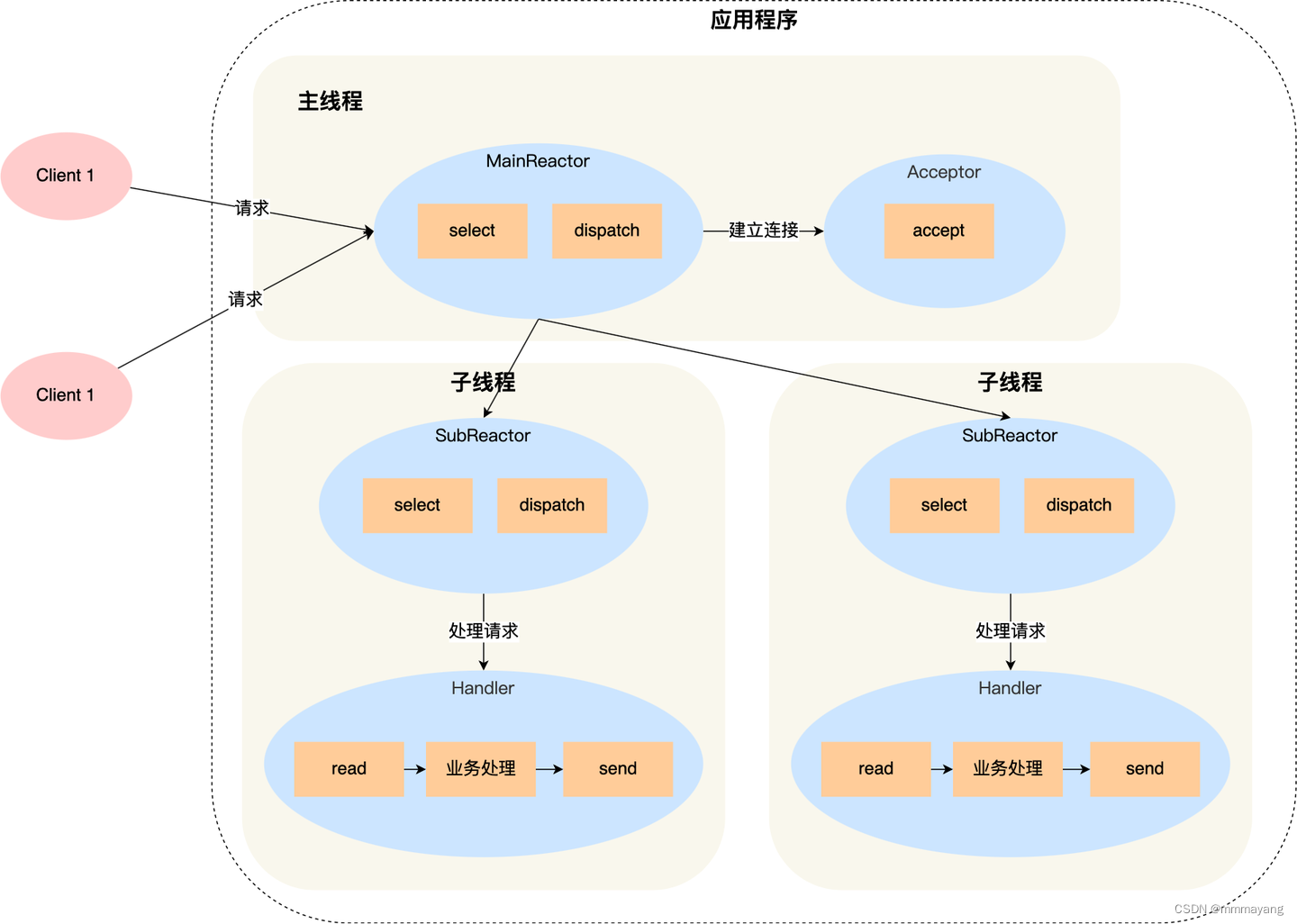
Reactor 单线程/进程 与 单 Reactor 多线程/多进程
这两种变体主要差异在于如何处理事件处理器的执行。
单 Reactor 单线程/进程:
原理: 所有的I/O处理(接收连接、读写数据)和请求处理都在同一个线程中完成。
优点: 简单,无需考虑多线程同步问题。
缺点: 一个线程处理所有任务可能成为性能瓶颈,特别是处理器密集型的任务。
单 Reactor 多线程/多进程:
原理: Reactor线程只负责I/O事件的监听和分发,真正的请求处理交给工作线程或进程来完成。
优点: 可以充分利用多核CPU,提高吞吐量,尤其适合于处理器密集型任务。
缺点: 复杂度高,需要处理线程间的同步和通信问题。
共同点与区别
- 共同点:两者都采用事件驱动的方式处理请求,使用事件循环来监听和分发事件。
区别: - 性能瓶颈:单线程模型的瓶颈在于无法同时处理多个请求或任务,而多线程模型的挑战在于线程管理和同步。
- 适用场景:单线程模型适合轻量级和少量并发的场景,多线程模型更适合高并发、处理器密集型的场景。
总的来说,Reactor模型的选择(单线程还是多线程)取决于应用场景的具体需求,包括并发量、任务类型(I/O密集型还是CPU密集型)等因素。
应用与使用
网络服务器: Reactor 模型被广泛用于编写高性能网络服务器,如 HTTP 服务器、数据库服务器等。
框架和库: 许多流行的网络编程库和框架,如 Java 的 NIO 库、Node.js 的事件循环,都使用了Reactor模式。
目前的应用有哪些在用呢?
- Web服务器: 如Apache、Nginx等。
- 数据库: 如Redis。
- 应用服务器: 例如Tomcat的NIO连接器。
4.2 Proactor 线程模型
其实上面已经讲到了很多同步与异步的区别。那么我们再说 proactor 模型。
Proactor 模型是一种异步处理并发输入源的服务请求的架构模式,常用于实现高性能网络服务器,特别是在需要处理大量并发I/O操作的场景中。
工作原理
异步操作发起: 在Proactor模型中,应用程序发起一个或多个异步I/O操作(如读取文件、网络数据传输)。
继续执行: 应用程序继续执行其他任务,而不是等待I/O操作完成。这样做可以充分利用CPU资源,避免了阻塞。
完成处理器(Completion Handler): 一旦异步I/O操作完成,系统会自动调用预设的完成处理器(或回调函数)来处理I/O操作的结果。
事件分发: 完成处理器处理异步I/O操作的结果,并可能根据需要触发其他操作或响应。
应用与使用
- 网络编程: Proactor模式广泛用于网络编程中,尤其是在高性能服务器和客户端应用中,如大规模的Web应用、数据库系统等。
- 框架和库: 一些现代编程语言和框架提供了对Proactor模式的支持,如Python的asyncio库。
4.3 区别与共同点
Q:既然多线程多进程的 reactor 线程模型最后能用线程池去处理这个问题,那跟异步处理的 proactor 线程模型的区别在什么地方呢?
A:
主要区别
I/O操作的同步性与异步性: Reactor模型中,即使使用多线程,I/O操作仍然是同步的;而在Proactor模型中,I/O操作是完全异步的。
线程阻塞: Reactor模型中,执行I/O操作的线程在操作完成前会阻塞;Proactor模型中,线程发起I/O操作后不会阻塞,I/O操作完成时通过回调进行通知。
处理器角色:Reactor模型中的处理器主要是分发事件;Proactor模型中的处理器是处理已完成的异步I/O操作。
.
总结
虽然多线程/多进程的Reactor模型通过线程池提高了并发处理能力,但它仍然依赖于同步I/O操作,适合于I/O操作较快的场景。而Proactor模型完全基于异步I/O,适合于I/O操作较多或较慢的高并发场景。选择哪种模型取决于应用程序的特定需求和I/O特性。
5 总结
所有这些模型和技术都旨在提高网络和I/O操作的效率。无论是通过同步还是异步方法,它们的目的都是最大限度地减少资源浪费,并提高应用程序处理并发请求的能力。
不同的处理方式
BIO (Blocking I/O): 适用于低负载、低并发的应用程序,易于理解和实现。
NIO (Non-blocking I/O): 适合高并发情况,通过单个线程管理多个连接,减少资源消耗。
AIO (Asynchronous I/O): 完全异步的方式处理I/O,适合I/O延迟较高的场景,如大量网络请求和大规模数据处理。
线程模型的进化
Reactor 模型: 基于事件驱动,高效管理多个连接。在NIO中得到了广泛应用。
Proactor 模型: 异步I/O的天然实现,通过异步操作和回调机制提高了程序的响应性和吞吐量。
技术选择的依据
选择这些技术的关键在于了解应用程序的需求:
对于简单的应用,BIO可能是一个简单直接的选择。
.
如果应用需要处理大量并发连接,但每个连接的实际活动不多,NIO或Reactor模型可能更合适。
.
对于需要处理大量异步I/O操作的高性能和高可伸缩性应用,AIO或Proactor模型可能是更好的选择。
在网络和 I/O 编程领域,没有一种通用的解决方案适用于所有情况。理解不同模型和技术的优势和局限性是关键。随着应用需求的不断变化,我们应该针对业务与需求选择合适的技术栈和架构模型。
6 引用
如何深刻理解Reactor和Proactor?
Java 中 BIO、NIO、AIO 有什么区别?
对线面试官:IO模型之BIO、NIO、AIO
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!