原子操作类原理剖析
UC包提供了一系列的原子性操作类,这些类都是使用非阻塞算法CAS实现的,相比使用锁实现原子性操作这在性能上有很大提高。
由于原子性操作类的原理都大致相同,所以只讲解最简单的AtomicLong类的实现原理以及JDK8中新增的LongAdder和LongAccumulator类的原理。
有了这些基础,再去理解其他原子性操作类的实现就不会感到困难了。
原子变量操作类
JUC并发包中包含有Atomiclnteger、AtomicLong和AtomicBoolean等原子性操作类,它们的原理类似,AtomicLong是原子性递增或者递减类,其内部使用Unsafe来实现。

代码(1)通过Unsafe.getUnsafe()方法获取到Unsafe类的实例,这里你可能会有疑问,为何能通过Unsafe.getUnsafe()方法获取到Unsafe类的实例?其实这是因为AtomicLong类也是在rt.jar包下面的,AtomicLong类就是通过BootStarp类加载器进行加载的。
代码(5)中的value被声明为volatile的,这是为了在多线程下保证内存可见性,value是具体存放计数的变量。
代码(2)(4)获取value变量在AtomicLong类中的偏移量。下面重点看下AtomicLong中的主要函数。
递增和递减操作代码

代码内部都是通过调用Unsafe的getAndAddLong方法来实现操作,这个函数是个原子性操作,这里第一个参数是AtomicLong实例的引用,第二个参数是value变量在AtomicLong中的偏移值,第三个参数是要设置的第二个变量的值。
boolean compareAndSet(long expect,long update)方法

在内部还是调用了unsafe.compareAndSwapLong方法。如果原子变量中的value值等于expect,则使用update值更新该值并返回true,否则返回false。
在没有原子类的情况下,实现计数器需要使用一定的同步措施,比如使用synchronized关键字等,但是这些都是阻塞算法,对性能有一定损耗,而这些原子操作类都使用CAS非阻塞算法,性能更好。
但是在高并发情况下AtomicLong还会存在性能问题。
JDK8提供了一个在高并发下性能更好的LongAdder类,下面我们来讲解这个类。
JDK8新增的原子操作类LongAdder
LongAdder简单介绍
前面讲过,AtomicLong通过CAS提供了非阻塞的原子性操作,相比使用阻塞算法的同步器来说它的性能已经很好了,但是JDK开发组并不满足于此。
使用AtomicLong时,在高并发下大量线程会同时去竞争更新同一个原子变量,但是由于同时只有一个线程的CAS操作会成功,这就造成了大量线程竞争失败后,会通过无限循环不断进行自旋尝试CAS的操作,而这会白白浪费CPU资源。
因此JDK8新增了一个原子性递增或者递减类LongAdder用来克服在高并发下使用AtomicLong的缺点。
既然AtomicLong的性能瓶颈是由于过多线程同时去竞争一个变量的更新而产生的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源,是不是就解决了性能问题?是的,LongAdder就是这个思路。
下面通过图来理解两者设计的不同之处。
使用AtomicLong时,是多个线程同时竞争同一个原子变量。
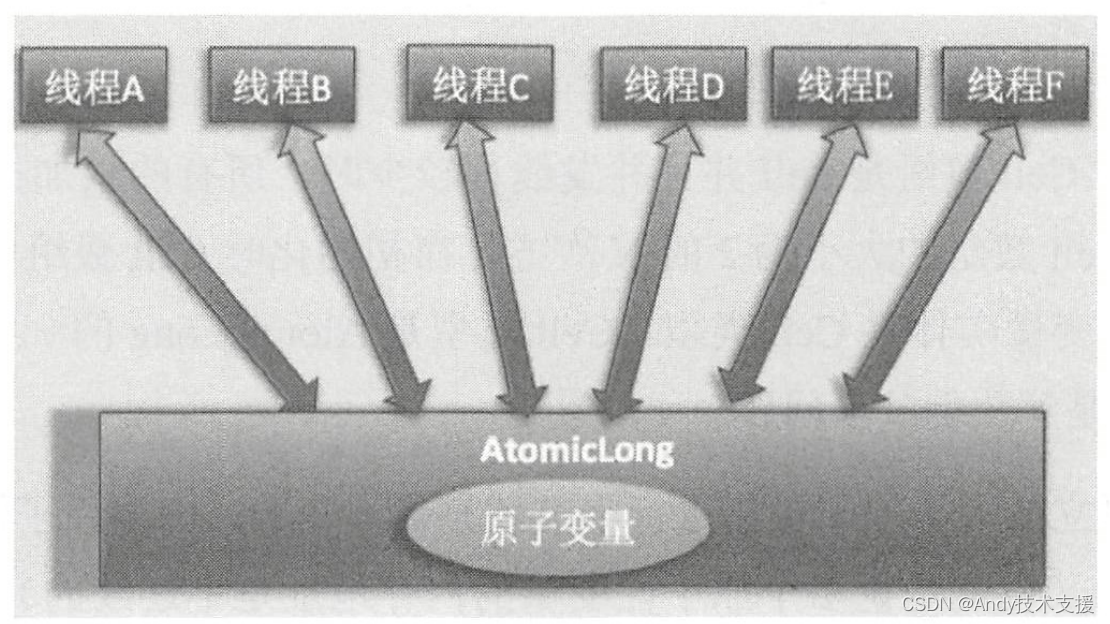
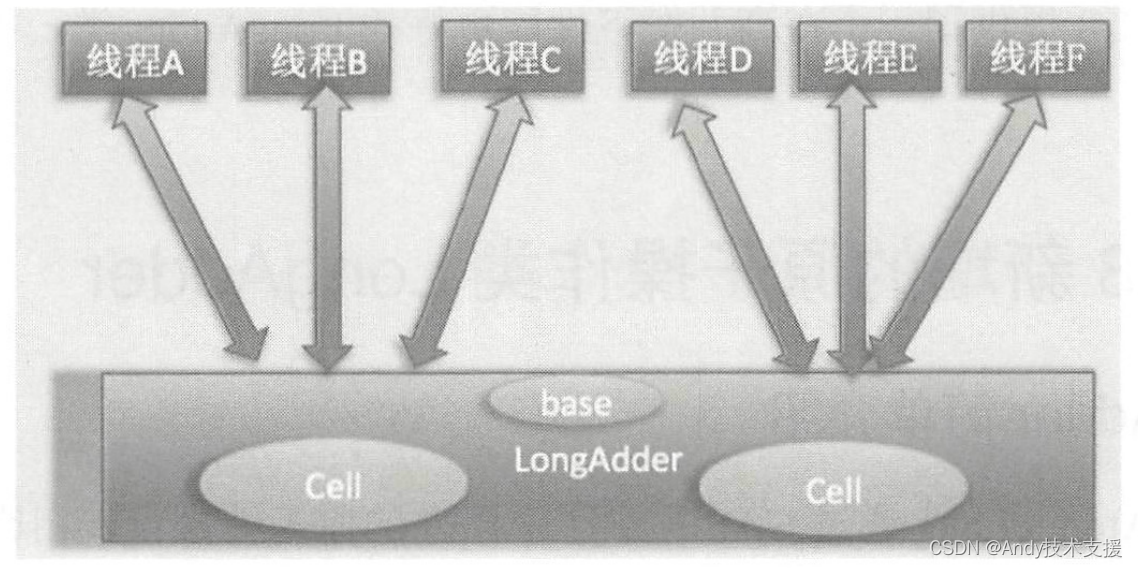
使用LongAdder时,则是在内部维护多个Cell变量,每个Cell里面有一个初始值为0的long型变量,这样,在同等并发量的情况下,争夺单个变量更新操作的线程量会减少,这变相地减少了争夺共享资源的并发量。
另外,多个线程在争夺同一个Cell原子变量时如果失败了,它并不是在当前Cell变量上一直自旋CAS重试,而是尝试在其他Cell的变量上进行CAS尝试,这个改变增加了当前线程重试CAS成功的可能性。
最后,在获取LongAdder当前值时,是把所有Cell变量的value值累加后再加上base返回的。
LongAdder维护了一个延迟初始化的原子性更新数组(默认情况下Cell数组是null)和一个基值变量base。
由于Cells占用的内存是相对比较大的,所以一开始并不创建它,而是在需要时创建,也就是惰性加载。
当一开始判断Cell数组是null并且并发线程较少时,所有的累加操作都是对base变量进行的。
保持Cell数组的大小为2的N次方,在初始化时Cell数组中的Cell元素个数为2,数组里面的变量实体是Cell类型。
Cell类型是AtomicLong的一个改进,用来减少缓存的争用,也就是解决伪共享问题。
对于大多数孤立的多个原子操作进行字节填充是浪费的,因为原子性操作都是无规律地分散在内存中的(也就是说多个原子性变量的内存地址是不连续的),多个原子变量被放入同一个缓存行的可能性很小。
但是原子性数组元素的内存地址是连续的,所以数组内的多个元素能经常共享缓存行,因此这里使用@sun.misc.Contended注解对Cell类进行字节填充,这防止了数组中多个元素共享一个缓存行,在性能上是一个提升。
LongAdder代码分析
为了解决高并发下多线程对一个变量CAS争夺失败后进行自旋而造成的降低并发性能问题,LongAdder在内部维护多个Cell元素(一个动态的Cell数组)来分担对单个变量进行争夺的开销。
下面围绕以下话题从源码角度来分析LongAdder的实现:
(1)LongAdder的结构是怎样的?
(2)当前线程应该访问Cell数组里面的哪一个Cell元素?
(3)如何初始化Cell数组?
(4)Cell数组如何扩容?
(5)线程访问分配的Cell元素有冲突后如何处理?
(6)如何保证线程操作被分配的Cell元素的原子性?
首先看下LongAdder的类图结构。
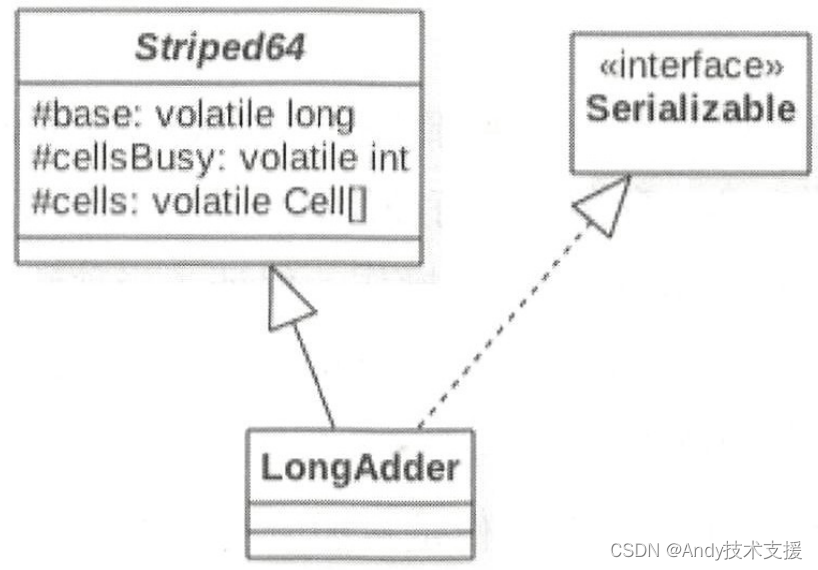
LongAdder类继承自Striped64类,在Striped64内部维护着三个变量。
LongAdder的真实值其实是base的值与Cell数组里面所有Cell元素中的value值的累加,base是个基础值,默认为0。
cellsBusy用来实现自旋锁,状态值只有0和1,当创建Cell元素,扩容Cell数组或者初始化Cell数组时,使用CAS操作该变量来保证同时只有一个线程可以进行其中之一的操作。
下面看Cell的构造。

可以看到,Cell的构造很简单,其内部维护一个被声明为volatile的变量,这里声明为volatile是因为线程操作value变量时没有使用锁,为了保证变量的内存可见性这里将其声明为volatile的。
另外cas函数通过CAS操作,保证了当前线程更新时被分配的Cell元素中value值的原子性。
另外,Cell类使用@sun.misc.Contended修饰是为了避免伪共享。到这里我们回答了问题1和问题6。
long sum()
返回当前的值,内部操作是累加所有Cell内部的value值后再累加base。
例如下面的代码,由于计算总和时没有对Cell数组进行加锁,所以在累加过程中可能有其他线程对Cell中的值进行了修改,也有可能对数组进行了扩容,所以sum返回的值并不是非常精确的,其返回值并不是一个调用sum方法时的原子快照值。

void reset()
为重置操作,如下代码把base置为0,如果Cell数组有元素,则元素值被重置为0。

long sumThenReset()
是sum的改造版本,如下代码在使用sum累加对应的Cell值后,把当前Cell的值重置为0,base重置为0。
这样,当多线程调用该方法时会有问题,
比如考虑第一个调用线程清空Cell的值,则后一个线程调用时累加的都是0值。

long longValue()
等价于sum()。
add()
下面主要看下add方法的实现,从这个方法里面就可以找到其他问题的答案。

代码(1)首先看cells是否为null,如果为null则当前在基础变量base上进行累加,这时候就类似AtomicLong的操作。
如果cells不为null或者线程执行代码(1)的CAS操作失败了,则会去执行代码(2)。
代码(2)(3)决定当前线程应该访问cells数组里面的哪一个Cell元素,如果当前线程映射的元素存在则执行代码(4),使用CAS操作去更新分配的Cell元素的value值,如果当前线程映射的元素不存在或者存在但是CAS操作失败则执行代码(5)。其实将代码(2)
(3)(4)合起来看就是获取当前线程应该访问的cells数组的Cell元素,然后进行CAS更新操作,只是在获取期间如果有些条件不满足则会跳转到代码(5)执行。
另外当前线程应该访问cells数组的哪一个Cell元素是通过getProbe() & m进行计算的,其中m是当前cells数组元素个数-1,getProbe()则用于获取当前线程中变量threadLocalRandomProbe的值,这个值一开始为0,在代码(5)里面会对其进行初始化。
并且当前线程通过分配的Cell元素的cas函数来保证对Cell元素value值更新的原子性,到这里我们回答了问题2
和问题6。
下面重点研究longAccumulate的代码逻辑,这是cells数组被初始化和扩容的地方。

当每个线程第一次执行到代码(6)时,会初始化当前线程变量threadLocalRandomProbe的值,上面也说了,这个变量在计算当前线程应该被分配到cells数组的哪一个Cell元素时会用到。
cells数组的初始化是在代码(14)中进行的,其中cellsBusy是一个标示,为0说明当前cells数组没有在被初始化或者扩容,也没有在新建Cell元素,为1则说明cells数组在被初始化或者扩容,或者当前在创建新的Cell元素、通过CAS操作来进行0或1状态的切换,这里使用casCellsBusy函数。
假设当前线程通过CAS设置cellsBusy为1,则当前线程开始初始化操作,那么这时候其他线程就不能进行扩容了。
如代码(14.1)初始化cells数组元素个数为2,然后使用h&1计算当前线程应该访问celll数组的哪个位置,也就是使用当前线程的threadLocalRandomProbe变量值&(cells数组元素个数-1),然后标示cells数组已经被初始化,最后代码(14.3)重置了cellsBusy标记。
显然这里没有使用CAS操作,却是线程安全的,原因是cellsBusy是volatile类型的,这保证了变量的内存可见性,另外此时其他地方的代码没有机会修改cellsBusy的值。
在这里初始化的cells数组里面的两个元素的值目前还是null。
这里回答了问题3,知道了cells数组如何被初始化。
cells数组的扩容是在代码(12)中进行的,对cells扩容是有条件的,也就是代码(10)(11)的条件都不满足的时候。
具体就是当前cells的元素个数小于当前机器CPU个数并且当前多个线程访问了cells中同一个元素,从而导致冲突使其中一个线程CAS失败时才会进行扩容操作。
这里为何要涉及CPU个数呢?其实在基础篇中已经讲过,只有当每个CPU都运行一个线程时才会使多线程的效果最佳,也就是当cells数组元素个数与CPU个数一致时,每个Cell都使用一个CPU进行处理,这时性能才是最佳的。
代码(12)中的扩容操作也是先通过CAS设置cellsBusy为1,然后才能进行扩容。
假设CAS成功则执行代码(12.1)将容量扩充为之前的2倍,并复制Cell元素到扩容后数组。
另外,扩容后cells数组里面除了包含复制过来的元素外,还包含其他新元素,这些元素的值目前还是null。
这里回答了问题4。
在代码(7)(8)中,当前线程调用add方法并根据当前线程的随机数threadLocalRandomProbe和cells元素个数计算要访问的Cell元素下标,然后如果发现对应下标元素的值为null,则新增一个Cell元素到cells数组,并且在将其添加到cells数组之前要竞争设置cellsBusy为1。
代码(13)对CAS失败的线程重新计算当前线程的随机值threadLocalRandomProbe,以减少下次访问cells元素时的冲突机会。这里回答了问题5。
LongAccumulator类原理探究
LongAdder类是LongAccumulator的一个特例,LongAccumulator比LongAdder的功能更强大。
例如下面的构造函数,其中accumulatorFunction是一个双目运算器接口,其根据输入的两个参数返回一个计算值,identity则是LongAccumulator累加器的初始值。

上面提到,LongAdder其实是LongAccumulator的一个特例,调用LongAdder就相当于使用下面的方式调用LongAccumulator:

LongAccumulator相比于LongAdder,可以为累加器提供非0的初始值,后者只能提供默认的0值。
另外,前者还可以指定累加规则,比如不进行累加而进行相乘,只需要在构造LongAccumulator时传入自定义的双目运算器即可,后者则内置累加的规则。
LongAccumulator相比于LongAdder的不同在于,在调用casBase时后者传递的是b+x,前者则使用了r=function.applyAsLong(b=base,x)来计算。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!