RocketMQ-RocketMQ高性能核心原理--(零拷贝)
五、关于零拷贝与顺序写
1、刷盘机制保证消息不丢失
? 在操作系统层面,当应用程序写入一个文件时,文件内容并不会直接写入到硬件当中,而是会先写入到操作系统中的一个缓存PageCache中。PageCache缓存以4K大小为单位,缓存文件的具体内容。这些写入到PageCache中的文件,在应用程序看来,是已经完全落盘保存好了的,可以正常修改、复制等等。但是,本质上,PageCache依然是内存状态,所以一断电就会丢失。因此,需要将内存状态的数据写入到磁盘当中,这样数据才能真正完成持久化,断电也不会丢失。这个过程就称为刷盘。
Java当中使用FileOutputStream类或者BufferedWriter类,进行write操作,就是写入的Pagecache。
RocketMQ中通过fileChannel.commit方法写入消息,也是写入到Pagecache。
? PageCache是源源不断产生的,而Linux操作系统显然不可能时时刻刻往硬盘写文件。所以,操作系统只会在某些特定的时刻将PageCache写入到磁盘。例如当我们正常关机时,就会完成PageCache刷盘。另外,在Linux中,对于有数据修改的PageCache,会标记为Dirty(脏页)状态。当Dirty Page的比例达到一定的阈值时,就会触发一次刷盘操作。例如在Linux操作系统中,可以通过/proc/meminfo文件查看到Page Cache的状态。
[root@192-168-65-174 ~]# cat /proc/meminfo?
MemTotal: 16266172 kB
.....
Cached: 923724 kB
.....
Dirty: 32 kB
Writeback: 0 kB
.....
Mapped: 133032 kB
.....
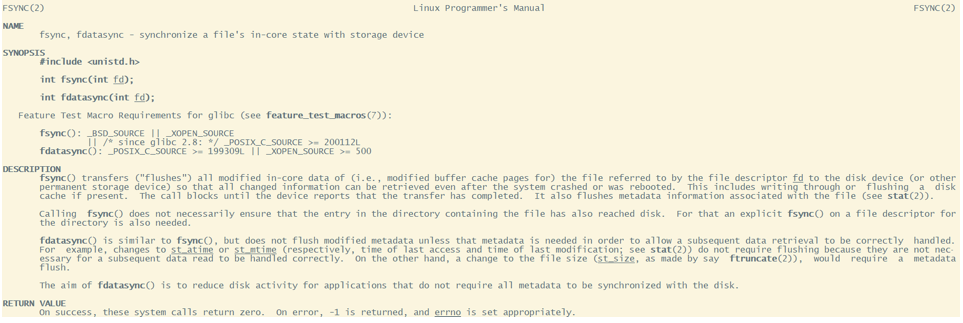
? 但是,只要操作系统的刷盘操作不是时时刻刻执行的,那么对于用户态的应用程序来说,那就避免不了非正常宕机时的数据丢失问题。因此,操作系统也提供了一个系统调用,应用程序可以自行调用这个系统调用,完成PageCache的强制刷盘。在Linux中是fsync,同样我们可以用man 2 fsync 指令查看。
RocketMQ对于何时进行刷盘,也设计了两种刷盘机制,同步刷盘和异步刷盘。只需要在broker.conf中进行配置就行。

? RocketMQ到底是怎么实现同步刷盘和异步刷盘的,还记得吗?
2、零拷贝加速文件读写
? 零拷贝(zero-copy)是操作系统层面提供的一种加速文件读写的操作机制,非常多的开源软件都在大量使用零拷贝,来提升IO操作的性能。对于Java应用层,对应着mmap和sendFile两种方式。接下来,咱们深入操作系统来详细理解一下零拷贝。
1:理解CPU拷贝和DMA拷贝
? 我们知道,操作系统对于内存空间,是分为用户态和内核态的。用户态的应用程序无法直接操作硬件,需要通过内核空间进行操作转换,才能真正操作硬件。这其实是为了保护操作系统的安全。正因为如此,应用程序需要与网卡、磁盘等硬件进行数据交互时,就需要在用户态和内核态之间来回的复制数据。而这些操作,原本都是需要由CPU来进行任务的分配、调度等管理步骤的,早先这些IO接口都是由CPU独立负责,所以当发生大规模的数据读写操作时,CPU的占用率会非常高。
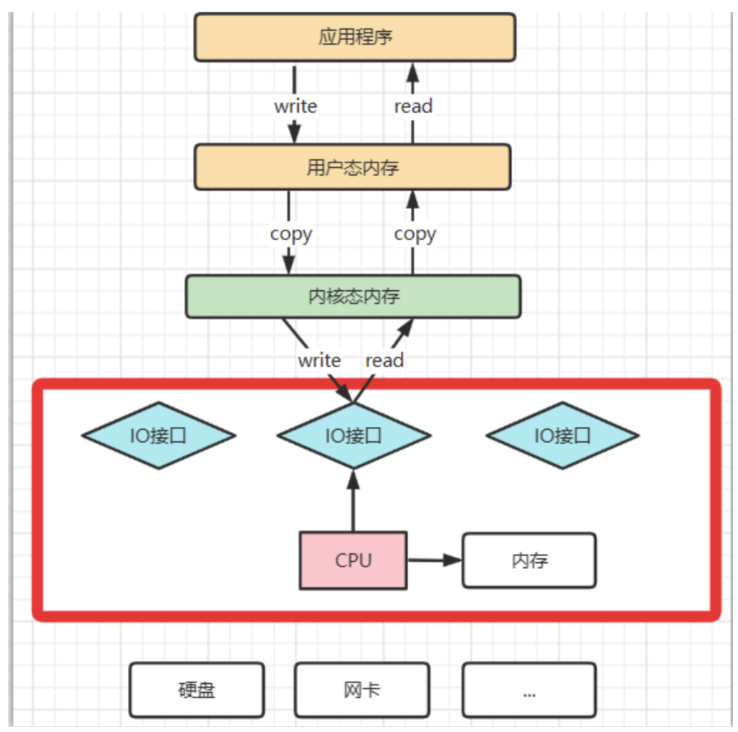
之后,操作系统为了避免CPU完全被各种IO调用给占用,引入了DMA(直接存储器存储)。由DMA来负责这些频繁的IO操作。DMA是一套独立的指令集,不会占用CPU的计算资源。这样,CPU就不需要参与具体的数据复制的工作,只需要管理DMA的权限即可。
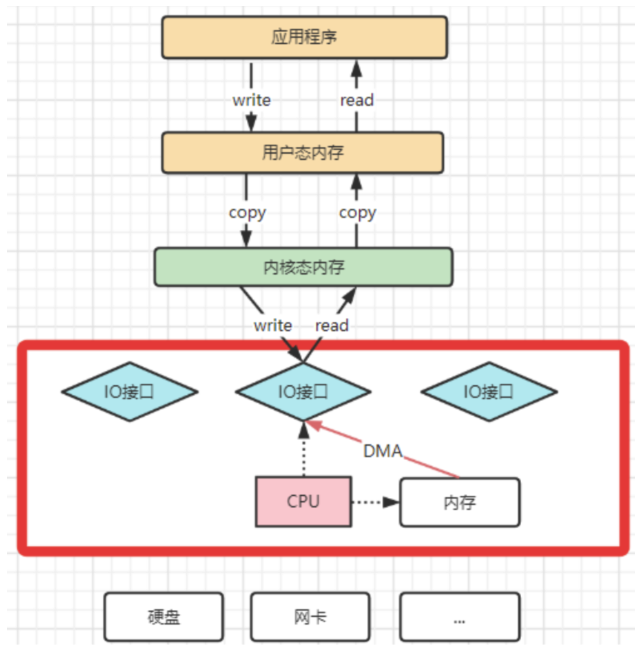
? DMA拷贝极大的释放了CPU的性能,因此他的拷贝速度会比CPU拷贝要快很多。但是,其实DMA拷贝本身,也在不断优化。
? 引入DMA拷贝之后,在读写请求的过程中,CPU不再需要参与具体的工作,DMA可以独立完成数据在系统内部的复制。但是,数据复制过程中,依然需要借助数据总进线。当系统内的IO操作过多时,还是会占用过多的数据总线,造成总线冲突,最终还是会影响数据读写性能。
? 为了避免DMA总线冲突对性能的影响,后来又引入了Channel通道的方式。Channel,是一个完全独立的处理器,专门负责IO操作。既然是处理器,Channel就有自己的IO指令,与CPU无关,他也更适合大型的IO操作,性能更高。
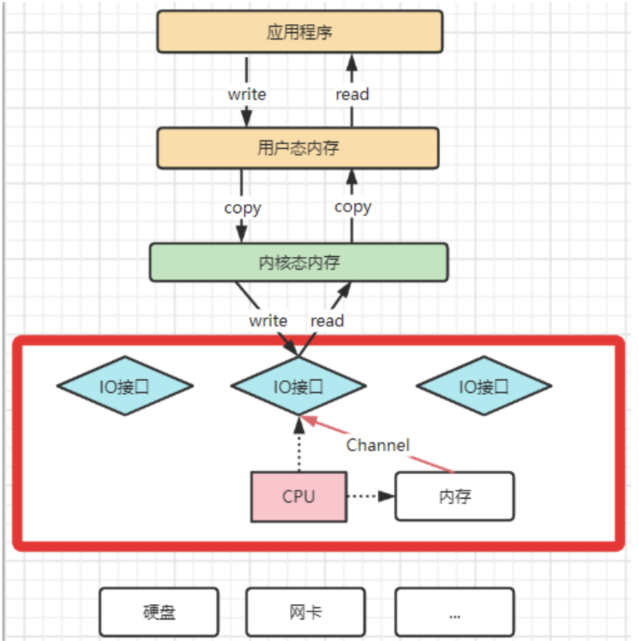
? 这也解释了,为什么Java应用层与零拷贝相关的操作都是通过Channel的子类实现的。这其实是借鉴了操作系统中的概念。
? 而所谓的零拷贝技术,其实并不是不拷贝,而是要尽量减少CPU拷贝。
2:再来理解下mmap文件映射机制是怎么回事。
? mmap机制的具体实现参见配套示例代码。主要是通过java.nio.channels.FileChannel的map方法完成映射。
? 以一次文件的读写操作为例,应用程序对磁盘文件的读与写,都需要经过内核态与用户态之间的状态切换,每次状态切换的过程中,就需要有大量的数据复制。
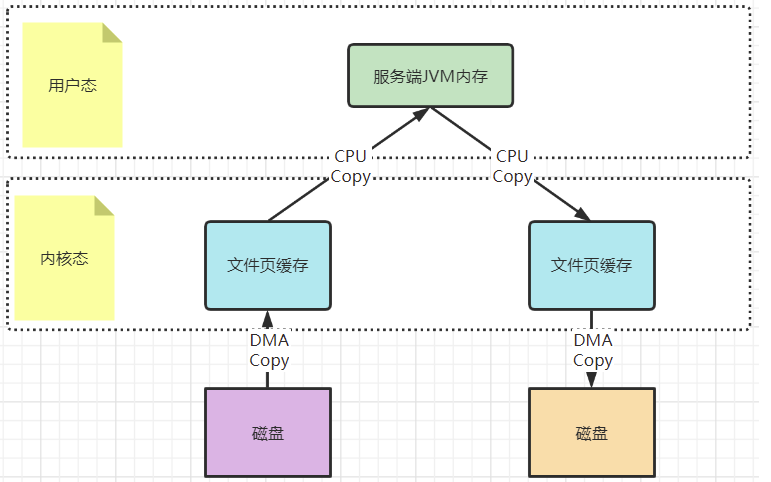
? 在这个过程中,总共需要进行四次数据拷贝。而磁盘与内核态之间的数据拷贝,在操作系统层面已经由CPU拷贝优化成了DMA拷贝。而内核态与用户态之间的拷贝依然是CPU拷贝。所以,在这个场景下,零拷贝技术优化的重点,就是内核态与用户态之间的这两次拷贝。
? 而mmap文件映射的方式,就是在用户态不再保存文件的内容,而只保存文件的映射,包括文件的内存起始地址,文件大小等。真实的数据,也不需要在用户态留存,可以直接通过操作映射,在内核态完成数据复制。
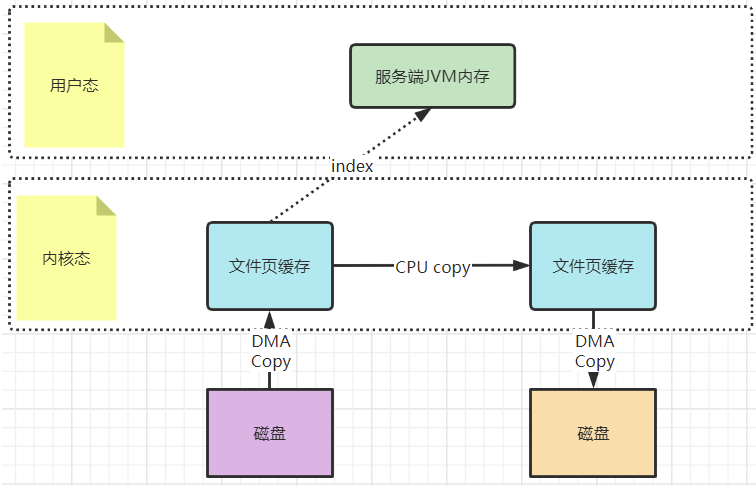
? 这个拷贝过程都是在操作系统的系统调用层面完成的,在Java应用层,其实是无法直接观测到的,但是我们可以去JDK源码当中进行间接验证。在JDK的NIO包中,java.nio.HeapByteBuffer映射的就是JVM的一块堆内内存,在HeapByteBuffer中,会由一个byte数组来缓存数据内容,所有的读写操作也是先操作这个byte数组。这其实就是没有使用零拷贝的普通文件读写机制。
HeapByteBuffer(int?cap,?int?lim) {????????????// package-private
????????super(-1,?0, lim, cap,?new?byte[cap],?0);
????????/*
????????hb = new byte[cap];
????????offset = 0;
????????*/
????}
? 而NIO把包中的另一个实现类java.nio.DirectByteBuffer则映射的是一块堆外内存。在DirectByteBuffer中,并没有一个数据结构来保存数据内容,只保存了一个内存地址。所有对数据的读写操作,都通过unsafe魔法类直接交由内核完成,这其实就是mmap的读写机制。
? mmap文件映射机制,其实并不神秘,我们启动任何一个Java程序时,其实都大量用到了mmap文件映射。例如,我们可以在Linux机器上,运行一下下面这个最简单不过的应用程序:
import?java.util.Scanner;
public?class?BlockDemo?{
????public?static?void?main(String[] args)?{
????????Scanner?scanner?=?new?Scanner(System.in);
????????final?String?s?=?scanner.nextLine();
????????System.out.println(s);
????}
}
? 通过Java指令运行起来后,可以用jps查看到运行的进程ID。然后,就可以使用lsof -p {PID}的方式查看文件的映射情况。
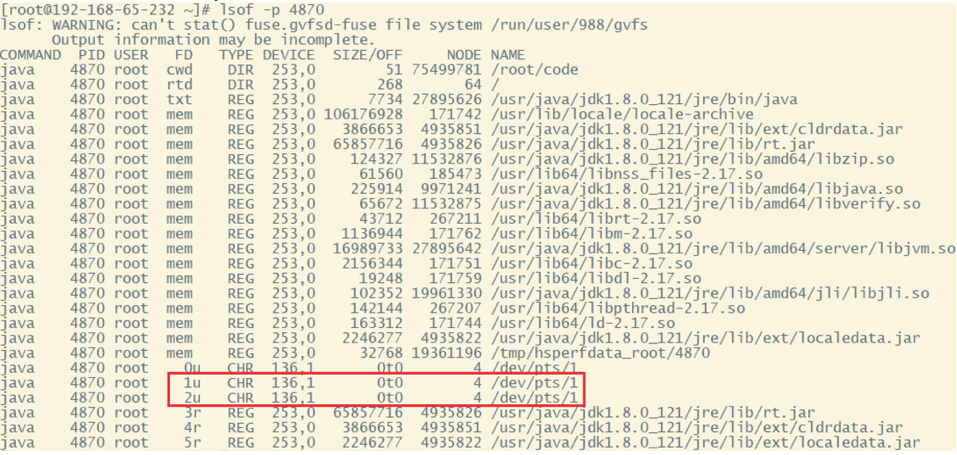
这里面看到的mem类型的FD其实就是文件映射。
cwd 表示程序的工作目录。rtd 表示用户的根目录。 txt表示运行程序的指令。下面的1u表示Java应用的标准输出,2u表示Java应用的标准错误输出,默认的/dev/pts/1是linux当中的伪终端。通常服务器上会写 java xxx 1>text.txt 2>&1 这样的脚本,就是指定这里的1u,2u。
? 最后,这种mmap的映射机制由于还是需要用户态保存文件的映射信息,数据复制的过程也需要用户态的参与,这其中的变数还是非常多的。所以,mmap机制适合操作小文件,如果文件太大,映射信息也会过大,容易造成很多问题。通常mmap机制建议的映射文件大小不要超过2G 。而RocketMQ做大的CommitLog文件保持在1G固定大小,也是为了方便文件映射。
3:梳理下sendFile机制是怎么运行的。
? sendFile机制的具体实现参见配套示例代码。主要是通过java.nio.channels.FileChannel的transferTo方法完成。
sourceReadChannel.transferTo(0,sourceFile.length(),targetWriteChannel);
? 还记得Kafka当中是如何使用零拷贝的吗?你应该看到过这样的例子,就是Kafka将文件从磁盘复制到网卡时,就大量的使用了零拷贝。百度去搜索一下零拷贝,铺天盖地的也都是拿这个场景在举例。
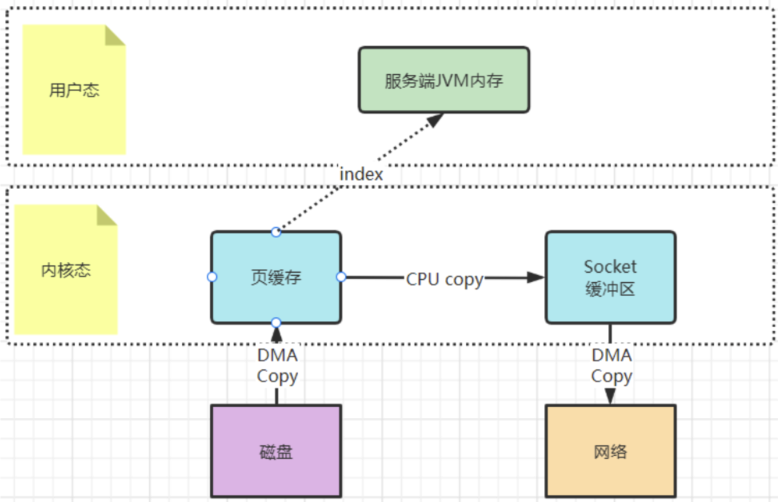
? 早期的sendfile实现机制其实还是依靠CPU进行页缓存与socket缓存区之间的数据拷贝。但是,在后期的不断改进过程中,sendfile优化了实现机制,在拷贝过程中,并不直接拷贝文件的内容,而是只拷贝一个带有文件位置和长度等信息的文件描述符FD,这样就大大减少了需要传递的数据。而真实的数据内容,会交由DMA控制器,从页缓存中打包异步发送到socket中。
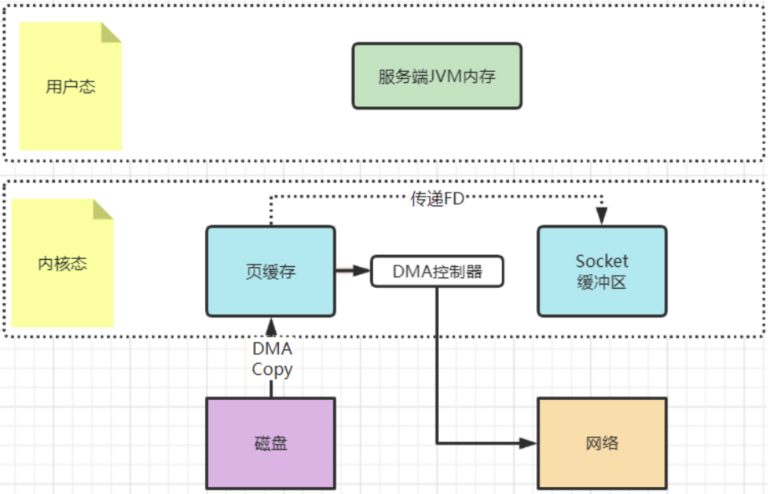
? 为什么大家都喜欢用这个场景来举例呢?其实我们去看下Linux操作系统的man帮助手册就能看到一部分答案。使用指令man 2 sendfile就能看到Linux操作系统对于sendfile这个系统调用的手册。
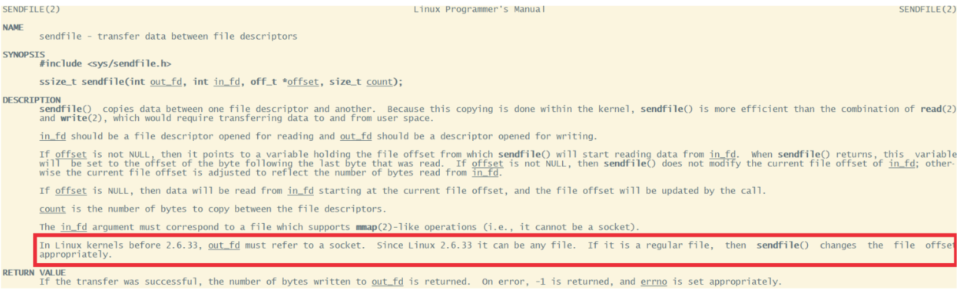
? 2.6.33版本以前的Linux内核中,out_fd只能是一个socket,所以网上铺天盖地的老资料都是拿网卡来举例。但是现在版本已经没有了这个限制。
? 最后,sendfile机制在内核态直接完成了数据的复制,不需要用户态的参与,所以这种机制的传输效率是非常稳定的。sendfile机制非常适合大数据的复制转移。
3、顺序写加速文件写入磁盘
? 通常应用程序往磁盘写文件时,由于磁盘空间不是连续的,会有很多碎片。所以我们去写一个文件时,也就无法把一个文件写在一块连续的磁盘空间中,而需要在磁盘多个扇区之间进行大量的随机写。这个过程中有大量的寻址操作,会严重影响写数据的性能。而顺序写机制是在磁盘中提前申请一块连续的磁盘空间,每次写数据时,就可以避免这些寻址操作,直接在之前写入的地址后面接着写就行。
? Kafka官方详细分析过顺序写的性能提升问题。Kafka官方曾说明,顺序写的性能基本能够达到内存级别。而如果配备固态硬盘,顺序写的性能甚至有可能超过写内存。而RocketMQ很大程度上借鉴了Kafka的这种思想。
? 例如可以看下org.apache.rocketmq.store.CommitLog#DefaultAppendMessageCallback中的doAppend方法。在这个方法中,会以追加的方式将消息先写入到一个堆外内存byteBuffer中,然后再通过fileChannel写入到磁盘。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!