工具系列:TensorFlow决策森林_(9)自动超参数调整
文章目录
欢迎来到TensorFlow决策森林 自动超参数调整教程。在本文中,您将学习如何使用TensorFlow Decision Forests进行自动超参数调整来改进您的模型。
更具体地说,我们将:
- 训练一个没有超参数调整的模型。这个模型将用于衡量超参数调整的质量改进。
- 使用TF-DF的调谐器训练一个有超参数调整的模型。要优化的超参数将被手动定义。
- 使用TF-DF的调谐器训练另一个有超参数调整的模型。但是这次,要优化的超参数将被自动设置。这是使用超参数调整时推荐尝试的第一种方法。
- 最后,我们将使用Keras的调谐器训练一个有超参数调整的模型。
介绍
学习算法在训练数据集上训练机器学习模型。学习算法的参数,称为“超参数”,控制模型的训练方式并影响其质量。因此,找到最佳超参数是建模的重要阶段。
有些超参数很容易配置。例如,增加随机森林中的树的数量(num_trees)可以提高模型的质量,直到达到一个平台。因此,设置与服务约束兼容的最大值(更多的树意味着更大的模型)是一个有效的经验法则。然而,其他超参数与模型有更复杂的交互,并不能用这样简单的规则来选择。例如,增加梯度提升树模型的最大树深度(max_depth)既可以提高模型的质量,也可以降低模型的质量。此外,超参数之间可以相互作用,超参数的最佳值不能孤立地找到。
选择超参数值有三种主要方法:
-
默认方法:学习算法带有默认值。虽然在所有情况下都不理想,但这些值在大多数情况下产生合理的结果。这种方法被推荐作为任何建模中使用的第一种方法。
此页面列出了TF Decision Forests的默认值。 -
模板超参数方法:除了默认值之外,TF Decision Forests还公开了超参数模板。这些是经过基准调整的超参数值,具有出色的性能,但训练成本很高(例如,
hyperparameter_template="benchmark_rank1")。 -
手动调整方法:您可以手动测试不同的超参数值,并选择表现最好的那个。
本指南提供了一些建议。 -
自动调整方法:可以使用调整算法自动找到最佳的超参数值。这种方法通常可以获得最佳结果,并且不需要专业知识。这种方法的主要缺点是对于大型数据集需要花费的时间。
在这个colab中,我们将展示TensorFlow Decision Forests库中的默认和自动调整方法。
超参数调整算法
自动调整算法通过生成和评估大量的超参数值来工作。其中每个迭代被称为一个“试验”。试验的评估是昂贵的,因为它需要每次训练一个新模型。在调整结束时,使用评估最佳的超参数。
调整算法的配置如下:
搜索空间
搜索空间是要优化的超参数列表及其可以取的值。例如,树的最大深度可以优化为1到32之间的值。探索更多的超参数和更多的可能值通常会导致更好的模型,但也需要更多的时间。超参数在文档中列出。
当一个超参数的可能值取决于另一个超参数的值时,搜索空间被称为条件空间。
试验的数量
试验的数量定义了将要训练和评估的模型数量。更多的试验数量通常会导致更好的模型,但需要更多的时间。
优化器
优化器选择要评估过去试验评估的下一个超参数。最简单且通常合理的优化器是随机选择超参数。
目标/试验分数
目标是调谐器优化的度量标准。通常,这个度量标准是模型在验证数据集上评估的质量的度量(例如准确性、对数损失)。
训练-验证-测试
验证数据集应该与训练数据集不同:如果训练和验证数据集相同,选择的超参数将是无关紧要的。验证数据集也应该与测试数据集(也称为留出数据集)不同:因为超参数调整是一种训练形式,如果测试和验证数据集相同,您实际上是在测试数据集上进行训练。在这种情况下,您可能会在测试数据集上过度拟合而没有办法进行测量。
交叉验证
在小数据集的情况下,例如包含少于100k个示例的数据集,超参数调整可以与交叉验证相结合:目标/分数的评估不是从单个训练-测试轮回中进行的,而是作为多个交叉验证轮回中指标的平均值进行评估。
与训练-验证-测试数据集类似,用于评估超参数调整期间的目标/分数的交叉验证应该与用于评估模型质量的交叉验证不同。
袋外评估
一些模型,如随机森林,可以使用“袋外评估”方法在训练数据集上进行评估。虽然不如交叉验证准确,但“袋外评估”比交叉验证快得多,并且不需要单独的验证数据集。
在TensorFlow决策森林中
在TF-DF中,模型的"自我"评估始终是一种公平的评估模型的方法。例如,随机森林模型使用袋外评估,而梯度提升模型使用验证数据集。
使用TF Decision Forests进行超参数调整
TF-DF支持最小配置的自动超参数调整。在下一个示例中,我们将训练和比较两个模型:一个使用默认超参数训练,一个使用超参数调整训练。
注意: 在大型数据集的情况下,超参数调整可能需要很长时间。在这种情况下,建议使用TF-DF进行分布式训练,以大大加快超参数调整的速度。
设置
# 安装TensorFlow Decision Forests库
!pip install tensorflow_decision_forests -U -qq
安装Wurlitzer。在colabs中显示详细的训练日志需要使用Wurlitzer(使用verbose=2)。
# 安装wurlitzer库,用于在Jupyter Notebook中隐藏pip安装的输出信息
!pip install wurlitzer -U -qq
导入必要的库。
# 导入所需的库
import tensorflow_decision_forests as tfdf
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
import numpy as np
隐藏的代码单元格在colab中限制了输出的高度。
#@title 定义"set_cell_height"函数。
from IPython.core.magic import register_line_magic # 导入register_line_magic函数
from IPython.display import Javascript # 导入Javascript类
from IPython.display import display # 导入display函数
# 由于一些模型训练日志可能会覆盖整个屏幕,如果不将其压缩到较小的视口中,则会很难查看。
# 这个魔术函数允许设置单元格的最大高度。
@register_line_magic # 注册为魔术函数
def set_cell_height(size): # 定义set_cell_height函数,接受一个参数size
display( # 调用display函数
Javascript("google.colab.output.setIframeHeight(0, true, {maxHeight: " + # 调用Javascript类的方法设置iframe的最大高度
str(size) + "})")) # 将size转换为字符串并作为参数传递给Javascript方法
在没有自动超参数调整的情况下训练模型
我们将在UCI提供的Adult数据集上训练模型。让我们下载数据集。
# 下载成人数据集的副本。
!wget -q https://raw.githubusercontent.com/google/yggdrasil-decision-forests/main/yggdrasil_decision_forests/test_data/dataset/adult_train.csv -O /tmp/adult_train.csv
!wget -q https://raw.githubusercontent.com/google/yggdrasil-decision-forests/main/yggdrasil_decision_forests/test_data/dataset/adult_test.csv -O /tmp/adult_test.csv
# 上述代码使用wget命令从指定的URL下载成人数据集的训练集和测试集副本。-q选项用于静默下载,-O选项用于指定下载文件的保存路径和文件名。训练集保存在/tmp/adult_train.csv,测试集保存在/tmp/adult_test.csv。
请将数据集分割为训练集和测试集。
# 加载数据集到内存中
train_df = pd.read_csv("/tmp/adult_train.csv") # 从文件中读取训练数据集
test_df = pd.read_csv("/tmp/adult_test.csv") # 从文件中读取测试数据集
# 将数据集转换为 TensorFlow 数据集
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df, label="income") # 将训练数据集转换为 TensorFlow 数据集,并指定标签为 "income"
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df, label="income") # 将测试数据集转换为 TensorFlow 数据集,并指定标签为 "income"
首先,我们使用默认超参数训练和评估一个Gradient Boosted Trees模型的质量。
%%time
# 训练一个使用默认超参数的模型
# 创建一个梯度提升树模型对象
model = tfdf.keras.GradientBoostedTreesModel()
# 使用训练数据集对模型进行训练
model.fit(train_ds)
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmp8vxzd_gw as temporary training directory
Reading training dataset...
[WARNING 23-08-16 11:07:53.6383 UTC gradient_boosted_trees.cc:1818] "goss_alpha" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:07:53.6384 UTC gradient_boosted_trees.cc:1829] "goss_beta" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:07:53.6384 UTC gradient_boosted_trees.cc:1843] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB".
Training dataset read in 0:00:03.854321. Found 22792 examples.
Training model...
Model trained in 0:00:03.313284
Compiling model...
[INFO 23-08-16 11:08:00.8007 UTC kernel.cc:1243] Loading model from path /tmpfs/tmp/tmp8vxzd_gw/model/ with prefix 672884dfed9c4c02
[INFO 23-08-16 11:08:00.8244 UTC abstract_model.cc:1311] Engine "GradientBoostedTreesQuickScorerExtended" built
[INFO 23-08-16 11:08:00.8244 UTC kernel.cc:1075] Use fast generic engine
WARNING:tensorflow:AutoGraph could not transform <function simple_ml_inference_op_with_handle at 0x7f23da2a7ee0> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: could not get source code
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING:tensorflow:AutoGraph could not transform <function simple_ml_inference_op_with_handle at 0x7f23da2a7ee0> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: could not get source code
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
WARNING: AutoGraph could not transform <function simple_ml_inference_op_with_handle at 0x7f23da2a7ee0> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: could not get source code
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
Model compiled.
CPU times: user 12.7 s, sys: 1.1 s, total: 13.8 s
Wall time: 8.9 s
<keras.src.callbacks.History at 0x7f24cdc1f9a0>
# 评估模型
model.compile(["accuracy"]) # 编译模型,使用"accuracy"作为评估指标
# 使用测试数据集评估模型的准确率
test_accuracy = model.evaluate(test_ds, return_dict=True, verbose=0)["accuracy"]
# 打印没有超参数调整的测试准确率
print(f"没有超参数调整的测试准确率: {test_accuracy:.4f}")
Test accuracy without hyper-parameter tuning: 0.8744
默认模型的超参数可以通过learner_params函数获得。这些参数的定义可以在文档中找到。
# 打印模型的默认超参数
print("Default hyper-parameters of the model:\n", model.learner_params)
Default hyper-parameters of the model:
{'adapt_subsample_for_maximum_training_duration': False, 'allow_na_conditions': False, 'apply_link_function': True, 'categorical_algorithm': 'CART', 'categorical_set_split_greedy_sampling': 0.1, 'categorical_set_split_max_num_items': -1, 'categorical_set_split_min_item_frequency': 1, 'compute_permutation_variable_importance': False, 'dart_dropout': 0.01, 'early_stopping': 'LOSS_INCREASE', 'early_stopping_initial_iteration': 10, 'early_stopping_num_trees_look_ahead': 30, 'focal_loss_alpha': 0.5, 'focal_loss_gamma': 2.0, 'forest_extraction': 'MART', 'goss_alpha': 0.2, 'goss_beta': 0.1, 'growing_strategy': 'LOCAL', 'honest': False, 'honest_fixed_separation': False, 'honest_ratio_leaf_examples': 0.5, 'in_split_min_examples_check': True, 'keep_non_leaf_label_distribution': True, 'l1_regularization': 0.0, 'l2_categorical_regularization': 1.0, 'l2_regularization': 0.0, 'lambda_loss': 1.0, 'loss': 'DEFAULT', 'max_depth': 6, 'max_num_nodes': None, 'maximum_model_size_in_memory_in_bytes': -1.0, 'maximum_training_duration_seconds': -1.0, 'min_examples': 5, 'missing_value_policy': 'GLOBAL_IMPUTATION', 'num_candidate_attributes': -1, 'num_candidate_attributes_ratio': -1.0, 'num_trees': 300, 'pure_serving_model': False, 'random_seed': 123456, 'sampling_method': 'RANDOM', 'selective_gradient_boosting_ratio': 0.01, 'shrinkage': 0.1, 'sorting_strategy': 'PRESORT', 'sparse_oblique_normalization': None, 'sparse_oblique_num_projections_exponent': None, 'sparse_oblique_projection_density_factor': None, 'sparse_oblique_weights': None, 'split_axis': 'AXIS_ALIGNED', 'subsample': 1.0, 'uplift_min_examples_in_treatment': 5, 'uplift_split_score': 'KULLBACK_LEIBLER', 'use_hessian_gain': False, 'validation_interval_in_trees': 1, 'validation_ratio': 0.1}
使用自动化超参数调整和手动定义超参数训练模型
通过指定模型的tuner构造函数参数来启用超参数调整。调谐器对象包含了调谐器的所有配置(搜索空间、优化器、试验和目标)。
注意: 在下一节中,您将看到如何自动配置超参数值。然而,手动设置超参数如此处所示仍然是有价值的,可以帮助理解。
# 配置调参器。
# 创建一个有50次试验的随机搜索调参器。
tuner = tfdf.tuner.RandomSearch(num_trials=50)
# 定义搜索空间。
#
# 添加更多的参数通常会提高模型的质量,但会使调参时间更长。
tuner.choice("min_examples", [2, 5, 7, 10])
tuner.choice("categorical_algorithm", ["CART", "RANDOM"])
# 一些超参数只对其他超参数的特定值有效。例如,当"growing_strategy=LOCAL"时,"max_depth"参数大多数情况下是有用的,而当"growing_strategy=BEST_FIRST_GLOBAL"时,"max_num_nodes"更适用。
local_search_space = tuner.choice("growing_strategy", ["LOCAL"])
local_search_space.choice("max_depth", [3, 4, 5, 6, 8])
# merge=True表示参数(这里是"growing_strategy")已经定义,并且新的值将被添加到其中。
global_search_space = tuner.choice("growing_strategy", ["BEST_FIRST_GLOBAL"], merge=True)
global_search_space.choice("max_num_nodes", [16, 32, 64, 128, 256])
tuner.choice("use_hessian_gain", [True, False])
tuner.choice("shrinkage", [0.02, 0.05, 0.10, 0.15])
tuner.choice("num_candidate_attributes_ratio", [0.2, 0.5, 0.9, 1.0])
# 取消对以下超参数的注释(或全部取消注释)以提高搜索的质量。相应地应增加试验的次数。
# tuner.choice("split_axis", ["AXIS_ALIGNED"])
# oblique_space = tuner.choice("split_axis", ["SPARSE_OBLIQUE"], merge=True)
# oblique_space.choice("sparse_oblique_normalization",
# ["NONE", "STANDARD_DEVIATION", "MIN_MAX"])
# oblique_space.choice("sparse_oblique_weights", ["BINARY", "CONTINUOUS"])
# oblique_space.choice("sparse_oblique_num_projections_exponent", [1.0, 1.5])
<tensorflow_decision_forests.component.tuner.tuner.SearchSpace at 0x7f240c3b32b0>
%%time
%set_cell_height 300
# 使用tuner对象来训练模型
tuned_model = tfdf.keras.GradientBoostedTreesModel(tuner=tuner)
tuned_model.fit(train_ds, verbose=2)
# 在训练日志中,可以看到类似"[10/50] Score: -0.45 / -0.40 HParams: ..."的行。
# 这表示已经完成了50个试验中的10个。最后一个试验返回了得分"-0.45",而迄今为止最好的试验得分为"-0.40"。
# 在这个例子中,模型通过对数损失进行优化。由于得分是最大化的,而对数损失应该最小化,所以得分实际上是负对数损失。
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpzdzgno07 as temporary training directory
Reading training dataset...
Training tensor examples:
Features: {'age': <tf.Tensor 'data:0' shape=(None,) dtype=int64>, 'workclass': <tf.Tensor 'data_1:0' shape=(None,) dtype=string>, 'fnlwgt': <tf.Tensor 'data_2:0' shape=(None,) dtype=int64>, 'education': <tf.Tensor 'data_3:0' shape=(None,) dtype=string>, 'education_num': <tf.Tensor 'data_4:0' shape=(None,) dtype=int64>, 'marital_status': <tf.Tensor 'data_5:0' shape=(None,) dtype=string>, 'occupation': <tf.Tensor 'data_6:0' shape=(None,) dtype=string>, 'relationship': <tf.Tensor 'data_7:0' shape=(None,) dtype=string>, 'race': <tf.Tensor 'data_8:0' shape=(None,) dtype=string>, 'sex': <tf.Tensor 'data_9:0' shape=(None,) dtype=string>, 'capital_gain': <tf.Tensor 'data_10:0' shape=(None,) dtype=int64>, 'capital_loss': <tf.Tensor 'data_11:0' shape=(None,) dtype=int64>, 'hours_per_week': <tf.Tensor 'data_12:0' shape=(None,) dtype=int64>, 'native_country': <tf.Tensor 'data_13:0' shape=(None,) dtype=string>}
Label: Tensor("data_14:0", shape=(None,), dtype=int64)
Weights: None
Normalized tensor features:
{'age': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast:0' shape=(None,) dtype=float32>), 'workclass': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_1:0' shape=(None,) dtype=string>), 'fnlwgt': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_1:0' shape=(None,) dtype=float32>), 'education': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_3:0' shape=(None,) dtype=string>), 'education_num': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_2:0' shape=(None,) dtype=float32>), 'marital_status': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_5:0' shape=(None,) dtype=string>), 'occupation': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_6:0' shape=(None,) dtype=string>), 'relationship': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_7:0' shape=(None,) dtype=string>), 'race': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_8:0' shape=(None,) dtype=string>), 'sex': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_9:0' shape=(None,) dtype=string>), 'capital_gain': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_3:0' shape=(None,) dtype=float32>), 'capital_loss': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_4:0' shape=(None,) dtype=float32>), 'hours_per_week': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_5:0' shape=(None,) dtype=float32>), 'native_country': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_13:0' shape=(None,) dtype=string>)}
[WARNING 23-08-16 11:08:02.9532 UTC gradient_boosted_trees.cc:1818] "goss_alpha" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:08:02.9533 UTC gradient_boosted_trees.cc:1829] "goss_beta" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:08:02.9533 UTC gradient_boosted_trees.cc:1843] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB".
Training dataset read in 0:00:00.389683. Found 22792 examples.
Training model...
Standard output detected as not visible to the user e.g. running in a notebook. Creating a training log redirection. If training gets stuck, try calling tfdf.keras.set_training_logs_redirection(False).
[INFO 23-08-16 11:08:03.3555 UTC kernel.cc:773] Start Yggdrasil model training
[INFO 23-08-16 11:08:03.3555 UTC kernel.cc:774] Collect training examples
[INFO 23-08-16 11:08:03.3555 UTC kernel.cc:787] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
categorial {
min_vocab_frequency: 0
max_vocab_count: -1
}
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
[INFO 23-08-16 11:08:03.3556 UTC kernel.cc:393] Number of batches: 23
[INFO 23-08-16 11:08:03.3556 UTC kernel.cc:394] Number of examples: 22792
[INFO 23-08-16 11:08:03.3630 UTC data_spec_inference.cc:305] 1 item(s) have been pruned (i.e. they are considered out of dictionary) for the column native_country (40 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 23-08-16 11:08:03.3630 UTC data_spec_inference.cc:305] 1 item(s) have been pruned (i.e. they are considered out of dictionary) for the column occupation (13 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 23-08-16 11:08:03.3631 UTC data_spec_inference.cc:305] 1 item(s) have been pruned (i.e. they are considered out of dictionary) for the column workclass (7 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 23-08-16 11:08:03.3698 UTC kernel.cc:794] Training dataset:
Number of records: 22792
Number of columns: 15
Number of columns by type:
CATEGORICAL: 9 (60%)
NUMERICAL: 6 (40%)
Columns:
CATEGORICAL: 9 (60%)
0: "__LABEL" CATEGORICAL integerized vocab-size:3 no-ood-item
4: "education" CATEGORICAL has-dict vocab-size:17 zero-ood-items most-frequent:"HS-grad" 7340 (32.2043%)
8: "marital_status" CATEGORICAL has-dict vocab-size:8 zero-ood-items most-frequent:"Married-civ-spouse" 10431 (45.7661%)
9: "native_country" CATEGORICAL num-nas:407 (1.78571%) has-dict vocab-size:41 num-oods:1 (0.00446728%) most-frequent:"United-States" 20436 (91.2933%)
10: "occupation" CATEGORICAL num-nas:1260 (5.52826%) has-dict vocab-size:14 num-oods:1 (0.00464425%) most-frequent:"Prof-specialty" 2870 (13.329%)
11: "race" CATEGORICAL has-dict vocab-size:6 zero-ood-items most-frequent:"White" 19467 (85.4115%)
12: "relationship" CATEGORICAL has-dict vocab-size:7 zero-ood-items most-frequent:"Husband" 9191 (40.3256%)
13: "sex" CATEGORICAL has-dict vocab-size:3 zero-ood-items most-frequent:"Male" 15165 (66.5365%)
14: "workclass" CATEGORICAL num-nas:1257 (5.51509%) has-dict vocab-size:8 num-oods:1 (0.0046436%) most-frequent:"Private" 15879 (73.7358%)
NUMERICAL: 6 (40%)
1: "age" NUMERICAL mean:38.6153 min:17 max:90 sd:13.661
2: "capital_gain" NUMERICAL mean:1081.9 min:0 max:99999 sd:7509.48
3: "capital_loss" NUMERICAL mean:87.2806 min:0 max:4356 sd:403.01
5: "education_num" NUMERICAL mean:10.0927 min:1 max:16 sd:2.56427
6: "fnlwgt" NUMERICAL mean:189879 min:12285 max:1.4847e+06 sd:106423
7: "hours_per_week" NUMERICAL mean:40.3955 min:1 max:99 sd:12.249
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute which type is manually defined by the user i.e. the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
[INFO 23-08-16 11:08:03.3699 UTC kernel.cc:810] Configure learner
[WARNING 23-08-16 11:08:03.3702 UTC gradient_boosted_trees.cc:1818] "goss_alpha" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:08:03.3702 UTC gradient_boosted_trees.cc:1829] "goss_beta" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:08:03.3702 UTC gradient_boosted_trees.cc:1843] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB".
[INFO 23-08-16 11:08:03.3703 UTC kernel.cc:824] Training config:
learner: "HYPERPARAMETER_OPTIMIZER"
features: "^age$"
features: "^capital_gain$"
features: "^capital_loss$"
features: "^education$"
features: "^education_num$"
features: "^fnlwgt$"
features: "^hours_per_week$"
features: "^marital_status$"
features: "^native_country$"
features: "^occupation$"
features: "^race$"
features: "^relationship$"
features: "^sex$"
features: "^workclass$"
label: "^__LABEL$"
task: CLASSIFICATION
metadata {
framework: "TF Keras"
}
[yggdrasil_decision_forests.model.hyperparameters_optimizer_v2.proto.hyperparameters_optimizer_config] {
base_learner {
learner: "GRADIENT_BOOSTED_TREES"
features: "^age$"
features: "^capital_gain$"
features: "^capital_loss$"
features: "^education$"
features: "^education_num$"
features: "^fnlwgt$"
features: "^hours_per_week$"
features: "^marital_status$"
features: "^native_country$"
features: "^occupation$"
features: "^race$"
features: "^relationship$"
features: "^sex$"
features: "^workclass$"
label: "^__LABEL$"
task: CLASSIFICATION
random_seed: 123456
pure_serving_model: false
[yggdrasil_decision_forests.model.gradient_boosted_trees.proto.gradient_boosted_trees_config] {
num_trees: 300
decision_tree {
max_depth: 6
min_examples: 5
in_split_min_examples_check: true
keep_non_leaf_label_distribution: true
num_candidate_attributes: -1
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
uplift {
min_examples_in_treatment: 5
split_score: KULLBACK_LEIBLER
}
}
shrinkage: 0.1
loss: DEFAULT
validation_set_ratio: 0.1
validation_interval_in_trees: 1
early_stopping: VALIDATION_LOSS_INCREASE
early_stopping_num_trees_look_ahead: 30
l2_regularization: 0
lambda_loss: 1
mart {
}
adapt_subsample_for_maximum_training_duration: false
l1_regularization: 0
use_hessian_gain: false
l2_regularization_categorical: 1
stochastic_gradient_boosting {
ratio: 1
}
apply_link_function: true
compute_permutation_variable_importance: false
binary_focal_loss_options {
misprediction_exponent: 2
positive_sample_coefficient: 0.5
}
early_stopping_initial_iteration: 10
}
}
optimizer {
optimizer_key: "RANDOM"
[yggdrasil_decision_forests.model.hyperparameters_optimizer_v2.proto.random] {
num_trials: 50
}
}
search_space {
fields {
name: "min_examples"
discrete_candidates {
possible_values {
integer: 2
}
possible_values {
integer: 5
}
possible_values {
integer: 7
}
possible_values {
integer: 10
}
}
}
fields {
name: "categorical_algorithm"
discrete_candidates {
possible_values {
categorical: "CART"
}
possible_values {
categorical: "RANDOM"
}
}
}
fields {
name: "growing_strategy"
discrete_candidates {
possible_values {
categorical: "LOCAL"
}
possible_values {
categorical: "BEST_FIRST_GLOBAL"
}
}
children {
name: "max_depth"
discrete_candidates {
possible_values {
integer: 3
}
possible_values {
integer: 4
}
possible_values {
integer: 5
}
possible_values {
integer: 6
}
possible_values {
integer: 8
}
}
parent_discrete_values {
possible_values {
categorical: "LOCAL"
}
}
}
children {
name: "max_num_nodes"
discrete_candidates {
possible_values {
integer: 16
}
possible_values {
integer: 32
}
possible_values {
integer: 64
}
possible_values {
integer: 128
}
possible_values {
integer: 256
}
}
parent_discrete_values {
possible_values {
categorical: "BEST_FIRST_GLOBAL"
}
}
}
}
fields {
name: "use_hessian_gain"
discrete_candidates {
possible_values {
categorical: "true"
}
possible_values {
categorical: "false"
}
}
}
fields {
name: "shrinkage"
discrete_candidates {
possible_values {
real: 0.02
}
possible_values {
real: 0.05
}
possible_values {
real: 0.1
}
possible_values {
real: 0.15
}
}
}
fields {
name: "num_candidate_attributes_ratio"
discrete_candidates {
possible_values {
real: 0.2
}
possible_values {
real: 0.5
}
possible_values {
real: 0.9
}
possible_values {
real: 1
}
}
}
}
base_learner_deployment {
num_threads: 1
}
}
[INFO 23-08-16 11:08:03.3707 UTC kernel.cc:827] Deployment config:
cache_path: "/tmpfs/tmp/tmpzdzgno07/working_cache"
num_threads: 32
try_resume_training: true
[INFO 23-08-16 11:08:03.3709 UTC kernel.cc:889] Train model
[INFO 23-08-16 11:08:03.3711 UTC hyperparameters_optimizer.cc:209] Hyperparameter search space:
fields {
name: "min_examples"
discrete_candidates {
possible_values {
integer: 2
}
possible_values {
integer: 5
}
possible_values {
integer: 7
}
possible_values {
integer: 10
}
}
}
fields {
name: "categorical_algorithm"
discrete_candidates {
possible_values {
categorical: "CART"
}
possible_values {
categorical: "RANDOM"
}
}
}
fields {
name: "growing_strategy"
discrete_candidates {
possible_values {
categorical: "LOCAL"
}
possible_values {
categorical: "BEST_FIRST_GLOBAL"
}
}
children {
name: "max_depth"
discrete_candidates {
possible_values {
integer: 3
}
possible_values {
integer: 4
}
possible_values {
integer: 5
}
possible_values {
integer: 6
}
possible_values {
integer: 8
}
}
parent_discrete_values {
possible_values {
categorical: "LOCAL"
}
}
}
children {
name: "max_num_nodes"
discrete_candidates {
possible_values {
integer: 16
}
possible_values {
integer: 32
}
possible_values {
integer: 64
}
possible_values {
integer: 128
}
possible_values {
integer: 256
}
}
parent_discrete_values {
possible_values {
categorical: "BEST_FIRST_GLOBAL"
}
}
}
}
fields {
name: "use_hessian_gain"
discrete_candidates {
possible_values {
categorical: "true"
}
possible_values {
categorical: "false"
}
}
}
fields {
name: "shrinkage"
discrete_candidates {
possible_values {
real: 0.02
}
possible_values {
real: 0.05
}
possible_values {
real: 0.1
}
possible_values {
real: 0.15
}
}
}
fields {
name: "num_candidate_attributes_ratio"
discrete_candidates {
possible_values {
real: 0.2
}
possible_values {
real: 0.5
}
possible_values {
real: 0.9
}
possible_values {
real: 1
}
}
}
[INFO 23-08-16 11:08:03.3713 UTC hyperparameters_optimizer.cc:500] Start local tuner with 32 thread(s)
[INFO 23-08-16 11:08:03.3728 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3728 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:03.3729 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3729 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:03.3729 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3730 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and [INFO 23-08-16 11:08:03.3730 UTC gradient_boosted_trees.cc:14 feature(s).
459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3731 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO[INFO 23-08-16 11:08:03.3731 UTC 23-08-16 11:08:03.3732 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3732 UTC gradient_boosted_trees.cc[INFO 23-08-16 11:08:03.3732 UTC gradient_boosted_trees.cc:1085:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:03.3733 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3733 UTC gradient_boosted_trees.cc:459[[INFO 23-08-16 11:08:03.3733 UTC [INFOgradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).[ 23-08-16 11:08:03.3734 UTC
INFO] Default loss set to BINOMIAL_LOG_LIKELIHOOD[INFO 23-08-16 11:08:03.3734 UTC INFOgradient_boosted_trees.cc
23-08-16 11:08:03.3734 UTC [ 23-08-16 11:08:03.3734 UTC :[INFO[[INFOINFO 23-08-16 11:08:03.3735 UTC gradient_boosted_trees.cc 23-08-16 11:08:03.3735 UTC gradient_boosted_trees.ccgradient_boosted_trees.ccgradient_boosted_trees.cc:459] 459Default loss set to BINOMIAL_LOG_LIKELIHOOD
23-08-16 11:08:03.3735 UTC INFOgradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD:gradient_boosted_trees.cc
:] 459:] Default loss set to 459BINOMIAL_LOG_LIKELIHOOD
[459INFO] Default loss set to 23-08-16 11:08:03.3736 UTC 23-08-16 11:08:03.3736 UTC BINOMIAL_LOG_LIKELIHOODgradient_boosted_trees.cc:Default loss set to [] [INFO:4591085 23-08-16 11:08:03.3737 UTC gradient_boosted_trees.cc
:gradient_boosted_trees.cc:INFOBINOMIAL_LOG_LIKELIHOOD459] 23-08-16 11:08:03.3737 UTC ]
Default loss set to [BINOMIAL_LOG_LIKELIHOODINFO[Training gradient boosted tree on gradient_boosted_trees.ccINFO 23-08-16 11:08:03.3738 UTC :1085[] ] INFO22792 23-08-16 11:08:03.3738 UTC example(s) and gradient_boosted_trees.cc14Default loss set to feature(s).BINOMIAL_LOG_LIKELIHOODgradient_boosted_trees.cc
23-08-16 11:08:03.3738 UTC :[INFO1085gradient_boosted_trees.ccTraining gradient boosted tree on ]
:Default loss set to :227921085 23-08-16 11:08:03.3738 UTC [BINOMIAL_LOG_LIKELIHOOD10851085Training gradient boosted tree on ] [Training gradient boosted tree on INFOINFO22792
example(s) and ] 23-08-16 11:08:03.3739 UTC gradient_boosted_trees.cc[ example(s) and INFO1422792 23-08-16 11:08:03.3739 UTC gradient_boosted_trees.cc feature(s).
:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
23-08-16 11:08:03.3739 UTC gradient_boosted_trees.cc::10851085] ] Training gradient boosted tree on 14 example(s) and gradient_boosted_trees.cc feature(s).14 feature(s).Training gradient boosted tree on
22792[ example(s) and :Training gradient boosted tree on 2279222792 example(s) and example(s) and 1414INFO
[ 23-08-16 11:08:03.3741 UTC feature(s).gradient_boosted_trees.cc45914] Default loss set to ] feature(s).Training gradient boosted tree on
feature(s).
INFO 23-08-16 11:08:03.3742 UTC gradient_boosted_trees.cc:BINOMIAL_LOG_LIKELIHOOD1085
] [INFOTraining gradient boosted tree on 22792 example(s) and :[22792 23-08-16 11:08:03.3742 UTC 108514gradient_boosted_trees.cc feature(s).
:1085INFO] example(s) and 14] feature(s).Training gradient boosted tree on 22792
23-08-16 11:08:03.3743 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD[ example(s) and INFO14 feature(s).Training gradient boosted tree on
22792 example(s) and 14
feature(s).[ 23-08-16 11:08:03.3743 UTC INFOgradient_boosted_trees.cc[ 23-08-16 11:08:03.3744 UTC [
INFO: 23-08-16 11:08:03.3744 UTC gradient_boosted_trees.cc459:] Default loss set to INFOBINOMIAL_LOG_LIKELIHOOD[459INFO] Default loss set to BINOMIAL_LOG_LIKELIHOOD 23-08-16 11:08:03.3745 UTC gradient_boosted_trees.ccgradient_boosted_trees.cc:459
]
Default loss set to BINOMIAL_LOG_LIKELIHOOD:[459] INFO
Default loss set to [[INFO 23-08-16 11:08:03.3745 UTC 23-08-16 11:08:03.3745 UTC gradient_boosted_trees.ccBINOMIAL_LOG_LIKELIHOODgradient_boosted_trees.cc
:1085[[INFOINFO 23-08-16 11:08:03.3746 UTC 23-08-16 11:08:03.3746 UTC gradient_boosted_trees.cc: 23-08-16 11:08:03.3746 UTC [:INFO1085gradient_boosted_trees.cc1085] 23-08-16 11:08:03.3746 UTC gradient_boosted_trees.ccgradient_boosted_trees.cc:] Training gradient boosted tree on :] 1085Training gradient boosted tree on ] INFO22792: example(s) and 14Training gradient boosted tree on feature(s).
22792 example(s) and 141085 feature(s).22792
23-08-16 11:08:03.3747 UTC example(s) and gradient_boosted_trees.cc:14459459] ] Training gradient boosted tree on feature(s).22792 example(s) and
Training gradient boosted tree on 14] 22792 example(s) and 14 feature(s).
Default loss set to BINOMIAL_LOG_LIKELIHOOD feature(s).Default loss set to
BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3748 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14[INFO 23-08-16 11:08:03.3749 UTC gradient_boosted_trees.cc:1085] feature(s).
Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:03.3752 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3752 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:03.3754 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3754 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:03.3761 UTC gradient_boosted_trees.cc:459] Default loss set to [INFOBINOMIAL_LOG_LIKELIHOOD
23-08-16 11:08:03.3762 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO[INFO 23-08-16 11:08:03.3762 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 23-08-16 11:08:03.3762 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 1414 feature(s).
feature(s).
[INFO 23-08-16 11:08:03.3768 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3768 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:03.3772 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3772 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:03.3774 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:03.3775 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:03.3914 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4337 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4344 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4345 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4347 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4356 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4363 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO[INFO 23-08-16 11:08:03.4369 UTC gradient_boosted_trees.cc: 23-08-16 11:08:03.4369 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4370 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4374 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO[[[INFOINFO 23-08-16 11:08:03.4382 UTC gradient_boosted_trees.ccINFO 23-08-16 11:08:03.4382 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and [2259:INFO1128 23-08-16 11:08:03.4382 UTC [ 23-08-16 11:08:03.4382 UTC INFOgradient_boosted_trees.ccgradient_boosted_trees.cc: examples used for validation:]
205331128 23-08-16 11:08:03.4382 UTC ] 20533gradient_boosted_trees.cc examples used for training and 2259:1128 examples used for validation examples used for training and ] 23-08-16 11:08:03.4382 UTC 205332259gradient_boosted_trees.cc examples used for training and 2259 examples used for validation:
1128] 205331128 examples used for training and examples used for validation2259 examples used for validation
] 20533
examples used for training and 2259 examples used for validation
[INFO[INFO 23-08-16 11:08:03.4385 UTC gradient_boosted_trees.cc 23-08-16 11:08:03.4385 UTC gradient_boosted_trees.cc::1128[INFO] 20533 examples used for training and 22591128] 20533 examples used for training and 2259 examples used for validation examples used for validation
23-08-16 11:08:03.4386 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO[INFO 23-08-16 11:08:03.4403 UTC gradient_boosted_trees.cc:1128[[[INFO] 20533INFO examples used for training and 2259INFO examples used for validation
23-08-16 11:08:03.4404 UTC gradient_boosted_trees.cc 23-08-16 11:08:03.4404 UTC :gradient_boosted_trees.cc 23-08-16 11:08:03.4403 UTC :1128] 20533 examples used for training and gradient_boosted_trees.cc 23-08-16 11:08:03.4404 UTC 2259 examples used for validationgradient_boosted_trees.cc::1128] 20533 examples used for training and 11282259 examples used for validation1128
]
20533] 20533 examples used for training and 2259 examples used for validation
examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4409 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[[INFOINFO 23-08-16 11:08:03.4416 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259[ 23-08-16 11:08:03.4416 UTC gradient_boosted_trees.ccINFO examples used for validation
: 23-08-16 11:08:03.4416 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4447 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4462 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4490 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:03.4535 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.012352 train-accuracy:0.761895 valid-loss:1.067086 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4640 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.033944 train-accuracy:0.761895 valid-loss:1.087890 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4689 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.007318 train-accuracy:0.761895 valid-loss:1.063819 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4717 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.015585 train-accuracy:0.761895 valid-loss:1.068358 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4747 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:0.992466 train-accuracy:0.761895 valid-loss:1.048658 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4758 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080310 train-accuracy:0.761895 valid-loss:1.138544 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4762 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.024983 train-accuracy:0.761895 valid-loss:1.080660 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4800 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.013950 train-accuracy:0.761895 valid-loss:1.069965 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4803 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.035081 train-accuracy:0.761895 valid-loss:1.091865 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4826 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:0.974501 train-accuracy:0.761895 valid-loss:1.024211 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4855 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:0.992049 train-accuracy:0.761895 valid-loss:1.047210 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4868 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.021242 train-accuracy:0.761895 valid-loss:1.076859 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4882 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.056437 train-accuracy:0.761895 valid-loss:1.113420 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4903 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.057450 train-accuracy:0.761895 valid-loss:1.114456 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4920 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.054434 train-accuracy:0.761895 valid-loss:1.110703 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4927 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.022126 train-accuracy:0.761895 valid-loss:1.077863 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.4975 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:0.985785 train-accuracy:0.761895 valid-loss:1.041083 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5011 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.015975 train-accuracy:0.761895 valid-loss:1.071430 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5043 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.056455 train-accuracy:0.761895 valid-loss:1.113410 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5052 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080606 train-accuracy:0.761895 valid-loss:1.138615 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5098 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.055526 train-accuracy:0.761895 valid-loss:1.112339 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5126 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080606 train-accuracy:0.761895 valid-loss:1.138615 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5132 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080079 train-accuracy:0.761895 valid-loss:1.138475 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5158 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080017 train-accuracy:0.761895 valid-loss:1.137988 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5282 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.052474 train-accuracy:0.761895 valid-loss:1.109417 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5328 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:0.978408 train-accuracy:0.761895 valid-loss:1.031947 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5335 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.055966 train-accuracy:0.761895 valid-loss:1.113004 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5340 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080559 train-accuracy:0.761895 valid-loss:1.138519 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5397 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080851 train-accuracy:0.761895 valid-loss:1.138916 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5398 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.015861 train-accuracy:0.761895 valid-loss:1.071101 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5503 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.054509 train-accuracy:0.761895 valid-loss:1.111318 valid-accuracy:0.736609
[INFO 23-08-16 11:08:03.5527 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080203 train-accuracy:0.761895 valid-loss:1.138223 valid-accuracy:0.736609
[INFO 23-08-16 11:08:05.4509 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.553261 train-accuracy:0.875566 valid-loss:0.590388 valid-accuracy:0.865870
[INFO 23-08-16 11:08:05.4509 UTC gradient_boosted_trees.cc:247] Truncates the model to 299 tree(s) i.e. 299 iteration(s).
[INFO 23-08-16 11:08:05.4509 UTC gradient_boosted_trees.cc:310] Final model num-trees:299 valid-loss:0.590370 valid-accuracy:0.866313
[INFO 23-08-16 11:08:05.4520 UTC hyperparameters_optimizer.cc:582] [1/50] Score: -0.59037 / -0.59037 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.15 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:05.4525 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:05.4526 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:05.4580 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:05.4741 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.583674
[INFO 23-08-16 11:08:05.4742 UTC gradient_boosted_trees.cc:247] Truncates the model to 61 tree(s) i.e. 61 iteration(s).
[INFO 23-08-16 11:08:05.4753 UTC gradient_boosted_trees.cc:310] Final model num-trees:61 valid-loss:0.583674 valid-accuracy:0.866755
[INFO 23-08-16 11:08:05.4799 UTC hyperparameters_optimizer.cc:582] [2/50] Score: -0.583674 / -0.583674 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.15 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:05.4807 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:05.4807 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:05.4861 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:05.5125 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080487 train-accuracy:0.761895 valid-loss:1.138629 valid-accuracy:0.736609
[INFO 23-08-16 11:08:05.5642 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.010715 train-accuracy:0.761895 valid-loss:1.065719 valid-accuracy:0.736609
[INFO 23-08-16 11:08:06.6744 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.540563 train-accuracy:0.877271 valid-loss:0.581734 valid-accuracy:0.869854
[INFO 23-08-16 11:08:06.6744 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:06.6745 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.581734 valid-accuracy:0.869854
[INFO 23-08-16 11:08:06.6779 UTC hyperparameters_optimizer.cc:582] [3/50] Score: -0.581734 / -0.581734 HParams: fields { name: "min_examples" value { integer: 10 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.15 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:06.6786 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:06.6787 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:06.6844 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:06.7151 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.057450 train-accuracy:0.761895 valid-loss:1.114456 valid-accuracy:0.736609
[INFO 23-08-16 11:08:06.8117 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.537262 train-accuracy:0.878780 valid-loss:0.585214 valid-accuracy:0.869854
[INFO 23-08-16 11:08:06.8117 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:06.8117 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.585214 valid-accuracy:0.869854
[INFO 23-08-16 11:08:06.8126 UTC hyperparameters_optimizer.cc:582] [4/50] Score: -0.585214 / -0.581734 HParams: fields { name: "min_examples" value { integer: 10 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.15 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:06.8139 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:06.8140 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:06.8191 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:06.8574 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.016525 train-accuracy:0.761895 valid-loss:1.069784 valid-accuracy:0.736609
[INFO 23-08-16 11:08:07.2475 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.588227
[INFO 23-08-16 11:08:07.2476 UTC gradient_boosted_trees.cc:247] Truncates the model to 113 tree(s) i.e. 113 iteration(s).
[INFO 23-08-16 11:08:07.2487 UTC gradient_boosted_trees.cc:310] Final model num-trees:113 valid-loss:0.588227 valid-accuracy:0.868969
[INFO 23-08-16 11:08:07.2525 UTC hyperparameters_optimizer.cc:582] [5/50] Score: -0.588227 / -0.581734 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 64 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:07.2582 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:07.2583 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:07.2630 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:07.2844 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.053989 train-accuracy:0.761895 valid-loss:1.109535 valid-accuracy:0.736609
[INFO 23-08-16 11:08:07.6031 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.569154
[INFO 23-08-16 11:08:07.6031 UTC gradient_boosted_trees.cc:247] Truncates the model to 161 tree(s) i.e. 161 iteration(s).
[INFO 23-08-16 11:08:07.6034 UTC gradient_boosted_trees.cc:310] Final model num-trees:161 valid-loss:0.569154 valid-accuracy:0.873838
[INFO 23-08-16 11:08:07.6057 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:07.6058 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:07.6059 UTC hyperparameters_optimizer.cc:582] [6/50] Score: -0.569154 / -0.569154 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.15 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:07.6114 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:07.6632 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.578871
[INFO 23-08-16 11:08:07.6632 UTC gradient_boosted_trees.cc:247] Truncates the model to 130 tree(s) i.e. 130 iteration(s).
[INFO 23-08-16 11:08:07.6638 UTC gradient_boosted_trees.cc:310] Final model num-trees:130 valid-loss:0.578871 valid-accuracy:0.869854
[INFO 23-08-16 11:08:07.6667 UTC hyperparameters_optimizer.cc:582] [7/50] Score: -0.578871 / -0.569154 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:07.6677 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:07.6677 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:07.6714 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:0.981052 train-accuracy:0.761895 valid-loss:1.035441 valid-accuracy:0.736609
[INFO 23-08-16 11:08:07.6733 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:07.7146 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080688 train-accuracy:0.761895 valid-loss:1.138783 valid-accuracy:0.736609
[INFO 23-08-16 11:08:07.7908 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.574698
[INFO 23-08-16 11:08:07.7909 UTC gradient_boosted_trees.cc:247] Truncates the model to 242 tree(s) i.e. 242 iteration(s).
[INFO 23-08-16 11:08:07.7910 UTC gradient_boosted_trees.cc:310] Final model num-trees:242 valid-loss:0.574698 valid-accuracy:0.871625
[INFO 23-08-16 11:08:07.7922 UTC hyperparameters_optimizer.cc:582] [8/50] Score: -0.574698 / -0.569154 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 4 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.15 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:08:07.7931 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:07.7932 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:07.7991 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:07.8445 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.082622 train-accuracy:0.761895 valid-loss:1.140940 valid-accuracy:0.736609
[INFO 23-08-16 11:08:08.2101 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.488794 train-accuracy:0.890031 valid-loss:0.571949 valid-accuracy:0.873395
[INFO 23-08-16 11:08:08.2101 UTC gradient_boosted_trees.cc:247] Truncates the model to 284 tree(s) i.e. 284 iteration(s).
[INFO 23-08-16 11:08:08.2102 UTC gradient_boosted_trees.cc:310] Final model num-trees:284 valid-loss:0.571257 valid-accuracy:0.872953
[INFO 23-08-16 11:08:08.2127 UTC hyperparameters_optimizer.cc:582] [9/50] Score: -0.571257 / -0.569154 HParams: fields { name: "min_examples" value { integer: 10 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:08.2158 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:08.2158 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:08.2204 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:08.2651 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:0.991671 train-accuracy:0.761895 valid-loss:1.045193 valid-accuracy:0.736609
[INFO 23-08-16 11:08:09.2840 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.567582 train-accuracy:0.871475 valid-loss:0.596684 valid-accuracy:0.865870
[INFO 23-08-16 11:08:09.2840 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:09.2840 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.596684 valid-accuracy:0.865870
[INFO 23-08-16 11:08:09.2850 UTC hyperparameters_optimizer.cc:582] [10/50] Score: -0.596684 / -0.569154 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:09.2866 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:09.2867 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:09.2915 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:09.3449 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.015325 train-accuracy:0.761895 valid-loss:1.070753 valid-accuracy:0.736609
[INFO 23-08-16 11:08:09.6511 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.499704 train-accuracy:0.890712 valid-loss:0.584889 valid-accuracy:0.869854
[INFO 23-08-16 11:08:09.6511 UTC gradient_boosted_trees.cc:247] Truncates the model to 298 tree(s) i.e. 298 iteration(s).
[INFO 23-08-16 11:08:09.6512 UTC gradient_boosted_trees.cc:310] Final model num-trees:298 valid-loss:0.584790 valid-accuracy:0.869411
[INFO 23-08-16 11:08:09.6544 UTC hyperparameters_optimizer.cc:582] [11/50] Score: -0.58479 / -0.569154 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:09.6593 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:09.6594 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:09.6638 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:09.7372 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.056130 train-accuracy:0.761895 valid-loss:1.113107 valid-accuracy:0.736609
[INFO 23-08-16 11:08:09.7959 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.578549
[INFO 23-08-16 11:08:09.7959 UTC gradient_boosted_trees.cc:247] Truncates the model to 105 tree(s) i.e. 105 iteration(s).
[INFO 23-08-16 11:08:09.7971 UTC gradient_boosted_trees.cc:310] Final model num-trees:105 valid-loss:0.578549 valid-accuracy:0.871625
[INFO 23-08-16 11:08:09.8037 UTC hyperparameters_optimizer.cc:582] [12/50] Score: -0.578549 / -0.569154 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:09.8107 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:09.8107 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:09.8152 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:09.8803 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.081456 train-accuracy:0.761895 valid-loss:1.139474 valid-accuracy:0.736609
[INFO 23-08-16 11:08:10.0550 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.575113
[INFO 23-08-16 11:08:10.0551 UTC gradient_boosted_trees.cc:247] Truncates the model to 242 tree(s) i.e. 242 iteration(s).
[INFO 23-08-16 11:08:10.0553 UTC gradient_boosted_trees.cc:310] Final model num-trees:242 valid-loss:0.575113 valid-accuracy:0.870297
[INFO 23-08-16 11:08:10.0575 UTC hyperparameters_optimizer.cc:582] [13/50] Score: -0.575113 / -0.569154 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:10.0586 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:10.0586 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:10.0638 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:10.1122 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.010652 train-accuracy:0.761895 valid-loss:1.064824 valid-accuracy:0.736609
[INFO 23-08-16 11:08:10.3474 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.574784
[INFO 23-08-16 11:08:10.3474 UTC gradient_boosted_trees.cc:247] Truncates the model to 249 tree(s) i.e. 249 iteration(s).
[INFO 23-08-16 11:08:10.3476 UTC gradient_boosted_trees.cc:310] Final model num-trees:249 valid-loss:0.574784 valid-accuracy:0.867641
[INFO 23-08-16 11:08:10.3491 UTC hyperparameters_optimizer.cc:582] [14/50] Score: -0.574784 / -0.569154 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 4 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.15 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:08:10.3509 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:10.3510 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:10.3566 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:10.4110 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.013729 train-accuracy:0.761895 valid-loss:1.069266 valid-accuracy:0.736609
[INFO 23-08-16 11:08:10.8116 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.577748
[INFO 23-08-16 11:08:10.8117 UTC gradient_boosted_trees.cc:247] Truncates the model to 89 tree(s) i.e. 89 iteration(s).
[INFO 23-08-16 11:08:10.8120 UTC gradient_boosted_trees.cc:310] Final model num-trees:89 valid-loss:0.577748 valid-accuracy:0.871625
[INFO 23-08-16 11:08:10.8133 UTC hyperparameters_optimizer.cc:582] [15/50] Score: -0.577748 / -0.569154 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.15 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:10.8143 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:10.8143 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:10.8194 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:10.8644 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.009908 train-accuracy:0.761895 valid-loss:1.065147 valid-accuracy:0.736609
[INFO 23-08-16 11:08:11.2479 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.578216
[INFO 23-08-16 11:08:11.2480 UTC gradient_boosted_trees.cc:247] Truncates the model to 195 tree(s) i.e. 195 iteration(s).
[INFO 23-08-16 11:08:11.2489 UTC gradient_boosted_trees.cc:310] Final model num-trees:195 valid-loss:0.578216 valid-accuracy:0.869854
[INFO 23-08-16 11:08:11.2556 UTC hyperparameters_optimizer.cc:582] [16/50] Score: -0.578216 / -0.569154 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 256 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:11.2566 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:11.2566 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:11.2647 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:11.3506 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.079317 train-accuracy:0.761895 valid-loss:1.137114 valid-accuracy:0.736609
[INFO 23-08-16 11:08:11.3940 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.552215 train-accuracy:0.876248 valid-loss:0.594582 valid-accuracy:0.869411
[INFO 23-08-16 11:08:11.3940 UTC gradient_boosted_trees.cc:247] Truncates the model to 294 tree(s) i.e. 294 iteration(s).
[INFO 23-08-16 11:08:11.3941 UTC gradient_boosted_trees.cc:310] Final model num-trees:294 valid-loss:0.594392 valid-accuracy:0.868969
[INFO 23-08-16 11:08:11.3949 UTC hyperparameters_optimizer.cc:582] [17/50] Score: -0.594392 / -0.569154 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:08:11.3962 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:11.3963 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:11.4011 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:11.4157 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.515704 train-accuracy:0.886719 valid-loss:0.592440 valid-accuracy:0.868083
[INFO 23-08-16 11:08:11.4158 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:11.4158 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.592440 valid-accuracy:0.868083
[INFO 23-08-16 11:08:11.4257 UTC hyperparameters_optimizer.cc:582] [18/50] Score: -0.59244 / -0.569154 HParams: fields { name: "min_examples" value { integer: 10 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 64 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:11.4423 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:11.4423 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:11.4468 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:11.4613 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.579733
[INFO 23-08-16 11:08:11.4613 UTC gradient_boosted_trees.cc:247] Truncates the model to 78 tree(s) i.e. 78 iteration(s).
[INFO 23-08-16 11:08:11.4627 UTC gradient_boosted_trees.cc:310] Final model num-trees:78 valid-loss:0.579733 valid-accuracy:0.867641
[INFO 23-08-16 11:08:11.4684 UTC hyperparameters_optimizer.cc:582] [19/50] Score: -0.579733 / -0.569154 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:11.4914 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.055888 train-accuracy:0.761895 valid-loss:1.113012 valid-accuracy:0.736609
[INFO 23-08-16 11:08:11.4956 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.586668
[INFO 23-08-16 11:08:11.4956 UTC gradient_boosted_trees.cc:247] Truncates the model to 61 tree(s) i.e. 61 iteration(s).
[INFO 23-08-16 11:08:11.4962 UTC gradient_boosted_trees.cc:310] Final model num-trees:61 valid-loss:0.586668 valid-accuracy:0.868969
[INFO 23-08-16 11:08:11.4974 UTC hyperparameters_optimizer.cc:582] [20/50] Score: -0.586668 / -0.569154 HParams: fields { name: "min_examples" value { integer: 10 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.15 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:11.5397 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.012875 train-accuracy:0.761895 valid-loss:1.067941 valid-accuracy:0.736609
[INFO 23-08-16 11:08:12.4754 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.576467
[INFO 23-08-16 11:08:12.4754 UTC gradient_boosted_trees.cc:247] Truncates the model to 147 tree(s) i.e. 147 iteration(s).
[INFO 23-08-16 11:08:12.4757 UTC gradient_boosted_trees.cc:310] Final model num-trees:147 valid-loss:0.576467 valid-accuracy:0.870739
[INFO 23-08-16 11:08:12.4773 UTC hyperparameters_optimizer.cc:582] [21/50] Score: -0.576467 / -0.569154 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.15 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:12.8409 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.498302 train-accuracy:0.892222 valid-loss:0.585352 valid-accuracy:0.870297
[INFO 23-08-16 11:08:12.8409 UTC gradient_boosted_trees.cc:247] Truncates the model to 296 tree(s) i.e. 296 iteration(s).
[INFO 23-08-16 11:08:12.8410 UTC gradient_boosted_trees.cc:310] Final model num-trees:296 valid-loss:0.585279 valid-accuracy:0.870297
[INFO 23-08-16 11:08:12.8441 UTC hyperparameters_optimizer.cc:582] [22/50] Score: -0.585279 / -0.569154 HParams: fields { name: "min_examples" value { integer: 10 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:13.1007 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.579464
[INFO 23-08-16 11:08:13.1008 UTC gradient_boosted_trees.cc:247] Truncates the model to 129 tree(s) i.e. 129 iteration(s).
[INFO 23-08-16 11:08:13.1018 UTC gradient_boosted_trees.cc:310] Final model num-trees:129 valid-loss:0.579464 valid-accuracy:0.870297
[INFO 23-08-16 11:08:13.1084 UTC hyperparameters_optimizer.cc:582] [23/50] Score: -0.579464 / -0.569154 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 128 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:13.1165 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.511416 train-accuracy:0.884381 valid-loss:0.572223 valid-accuracy:0.874723
[INFO 23-08-16 11:08:13.1166 UTC gradient_boosted_trees.cc:247] Truncates the model to 291 tree(s) i.e. 291 iteration(s).
[INFO 23-08-16 11:08:13.1166 UTC gradient_boosted_trees.cc:310] Final model num-trees:291 valid-loss:0.572029 valid-accuracy:0.874723
[INFO 23-08-16 11:08:13.1187 UTC hyperparameters_optimizer.cc:582] [24/50] Score: -0.572029 / -0.569154 HParams: fields { name: "min_examples" value { integer: 10 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:13.2108 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.578696
[INFO 23-08-16 11:08:13.2108 UTC gradient_boosted_trees.cc:247] Truncates the model to 228 tree(s) i.e. 228 iteration(s).
[INFO 23-08-16 11:08:13.2115 UTC gradient_boosted_trees.cc:310] Final model num-trees:228 valid-loss:0.578696 valid-accuracy:0.870739
[INFO 23-08-16 11:08:13.2163 UTC hyperparameters_optimizer.cc:582] [25/50] Score: -0.578696 / -0.569154 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:13.4696 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.574801
[INFO 23-08-16 11:08:13.4696 UTC gradient_boosted_trees.cc:247] Truncates the model to 83 tree(s) i.e. 83 iteration(s).
[INFO 23-08-16 11:08:13.4702 UTC gradient_boosted_trees.cc:310] Final model num-trees:83 valid-loss:0.574801 valid-accuracy:0.870297
[INFO 23-08-16 11:08:13.4733 UTC hyperparameters_optimizer.cc:582] [26/50] Score: -0.574801 / -0.569154 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:13.8788 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.523350 train-accuracy:0.883992 valid-loss:0.583351 valid-accuracy:0.868526
[INFO 23-08-16 11:08:13.8788 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:13.8789 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.583351 valid-accuracy:0.868526
[INFO 23-08-16 11:08:13.8882 UTC hyperparameters_optimizer.cc:582] [27/50] Score: -0.583351 / -0.569154 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 128 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:13.9364 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.587919
[INFO 23-08-16 11:08:13.9365 UTC gradient_boosted_trees.cc:247] Truncates the model to 86 tree(s) i.e. 86 iteration(s).
[INFO 23-08-16 11:08:13.9380 UTC gradient_boosted_trees.cc:310] Final model num-trees:86 valid-loss:0.587919 valid-accuracy:0.866755
[INFO 23-08-16 11:08:13.9434 UTC hyperparameters_optimizer.cc:582] [28/50] Score: -0.587919 / -0.569154 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:14.2934 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.575133
[INFO 23-08-16 11:08:14.2934 UTC gradient_boosted_trees.cc:247] Truncates the model to 174 tree(s) i.e. 174 iteration(s).
[INFO 23-08-16 11:08:14.2941 UTC gradient_boosted_trees.cc:310] Final model num-trees:174 valid-loss:0.575133 valid-accuracy:0.872067
[INFO 23-08-16 11:08:14.3012 UTC hyperparameters_optimizer.cc:582] [29/50] Score: -0.575133 / -0.569154 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:14.4387 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.578764
[INFO 23-08-16 11:08:14.4388 UTC gradient_boosted_trees.cc:247] Truncates the model to 186 tree(s) i.e. 186 iteration(s).
[INFO 23-08-16 11:08:14.4393 UTC gradient_boosted_trees.cc:310] Final model num-trees:186 valid-loss:0.578764 valid-accuracy:0.873395
[INFO 23-08-16 11:08:14.4425 UTC hyperparameters_optimizer.cc:582] [30/50] Score: -0.578764 / -0.569154 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 6 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:14.5569 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.523150 train-accuracy:0.886135 valid-loss:0.593369 valid-accuracy:0.869411
[INFO 23-08-16 11:08:14.5569 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:14.5570 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.593369 valid-accuracy:0.869411
[INFO 23-08-16 11:08:14.5615 UTC hyperparameters_optimizer.cc:582] [31/50] Score: -0.593369 / -0.569154 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:14.6584 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.57629
[INFO 23-08-16 11:08:14.6584 UTC gradient_boosted_trees.cc:247] Truncates the model to 151 tree(s) i.e. 151 iteration(s).
[INFO 23-08-16 11:08:14.6587 UTC gradient_boosted_trees.cc:310] Final model num-trees:151 valid-loss:0.576290 valid-accuracy:0.869411
[INFO 23-08-16 11:08:14.6600 UTC hyperparameters_optimizer.cc:582] [32/50] Score: -0.57629 / -0.569154 HParams: fields { name: "min_examples" value { integer: 10 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:08:15.0826 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.568287
[INFO 23-08-16 11:08:15.0827 UTC gradient_boosted_trees.cc:247] Truncates the model to 117 tree(s) i.e. 117 iteration(s).
[INFO 23-08-16 11:08:15.0832 UTC gradient_boosted_trees.cc:310] Final model num-trees:117 valid-loss:0.568287 valid-accuracy:0.873395
[INFO 23-08-16 11:08:15.0872 UTC hyperparameters_optimizer.cc:582] [33/50] Score: -0.568287 / -0.568287 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 256 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:08:15.3037 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.571936
[INFO 23-08-16 11:08:15.3038 UTC gradient_boosted_trees.cc:247] Truncates the model to 159 tree(s) i.e. 159 iteration(s).
[INFO 23-08-16 11:08:15.3041 UTC gradient_boosted_trees.cc:310] Final model num-trees:159 valid-loss:0.571936 valid-accuracy:0.872067
[INFO 23-08-16 11:08:15.3064 UTC hyperparameters_optimizer.cc:582] [34/50] Score: -0.571936 / -0.568287 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:08:15.6233 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.481432 train-accuracy:0.895339 valid-loss:0.584104 valid-accuracy:0.869854
[INFO 23-08-16 11:08:15.6234 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:15.6234 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.584104 valid-accuracy:0.869854
[INFO 23-08-16 11:08:15.6356 UTC hyperparameters_optimizer.cc:582] [35/50] Score: -0.584104 / -0.568287 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:15.9841 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.581114
[INFO 23-08-16 11:08:15.9842 UTC gradient_boosted_trees.cc:247] Truncates the model to 242 tree(s) i.e. 242 iteration(s).
[INFO 23-08-16 11:08:15.9845 UTC gradient_boosted_trees.cc:310] Final model num-trees:242 valid-loss:0.581114 valid-accuracy:0.867198
[INFO 23-08-16 11:08:15.9866 UTC hyperparameters_optimizer.cc:582] [36/50] Score: -0.581114 / -0.568287 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:08:16.2511 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.542830 train-accuracy:0.881654 valid-loss:0.593285 valid-accuracy:0.867198
[INFO 23-08-16 11:08:16.2511 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:16.2511 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.593285 valid-accuracy:0.867198
[INFO 23-08-16 11:08:16.2534 UTC hyperparameters_optimizer.cc:582] [37/50] Score: -0.593285 / -0.568287 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:16.5678 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.588445 train-accuracy:0.867433 valid-loss:0.620650 valid-accuracy:0.862328
[INFO 23-08-16 11:08:16.5678 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:16.5678 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.620650 valid-accuracy:0.862328
[INFO 23-08-16 11:08:16.5688 UTC hyperparameters_optimizer.cc:582] [38/50] Score: -0.62065 / -0.568287 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 4 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:08:17.2407 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.542858 train-accuracy:0.881800 valid-loss:0.595354 valid-accuracy:0.866755
[INFO 23-08-16 11:08:17.2407 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:17.2408 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.595354 valid-accuracy:0.866755
[INFO 23-08-16 11:08:17.2429 UTC hyperparameters_optimizer.cc:582] [39/50] Score: -0.595354 / -0.568287 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:08:17.3207 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.519893 train-accuracy:0.882725 valid-loss:0.589835 valid-accuracy:0.868083
[INFO 23-08-16 11:08:17.3207 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:17.3207 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.589835 valid-accuracy:0.868083
[INFO 23-08-16 11:08:17.3268 UTC hyperparameters_optimizer.cc:582] [40/50] Score: -0.589835 / -0.568287 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 128 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:08:18.2298 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.510029 train-accuracy:0.890566 valid-loss:0.588633 valid-accuracy:0.866755
[INFO 23-08-16 11:08:18.2299 UTC gradient_boosted_trees.cc:247] Truncates the model to 299 tree(s) i.e. 299 iteration(s).
[INFO 23-08-16 11:08:18.2299 UTC gradient_boosted_trees.cc:310] Final model num-trees:299 valid-loss:0.588569 valid-accuracy:0.865870
[INFO 23-08-16 11:08:18.2339 UTC hyperparameters_optimizer.cc:582] [41/50] Score: -0.588569 / -0.568287 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:18.7000 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.566897
[INFO 23-08-16 11:08:18.7000 UTC gradient_boosted_trees.cc:247] Truncates the model to 112 tree(s) i.e. 112 iteration(s).
[INFO 23-08-16 11:08:18.7005 UTC gradient_boosted_trees.cc:310] Final model num-trees:112 valid-loss:0.566897 valid-accuracy:0.873395
[INFO 23-08-16 11:08:18.7053 UTC hyperparameters_optimizer.cc:582] [42/50] Score: -0.566897 / -0.566897 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 64 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:08:20.3548 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.466037 train-accuracy:0.896557 valid-loss:0.571031 valid-accuracy:0.869854
[INFO 23-08-16 11:08:20.3548 UTC gradient_boosted_trees.cc:247] Truncates the model to 294 tree(s) i.e. 294 iteration(s).
[INFO 23-08-16 11:08:20.3549 UTC gradient_boosted_trees.cc:310] Final model num-trees:294 valid-loss:0.570658 valid-accuracy:0.871625
[INFO 23-08-16 11:08:20.3583 UTC hyperparameters_optimizer.cc:582] [43/50] Score: -0.570658 / -0.566897 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 6 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:20.5117 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.466786 train-accuracy:0.898115 valid-loss:0.574857 valid-accuracy:0.870739
[INFO 23-08-16 11:08:20.5118 UTC gradient_boosted_trees.cc:247] Truncates the model to 293 tree(s) i.e. 293 iteration(s).
[INFO 23-08-16 11:08:20.5119 UTC gradient_boosted_trees.cc:310] Final model num-trees:293 valid-loss:0.574461 valid-accuracy:0.870739
[INFO 23-08-16 11:08:20.5151 UTC hyperparameters_optimizer.cc:582] [44/50] Score: -0.574461 / -0.566897 HParams: fields { name: "min_examples" value { integer: 10 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 6 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:20.7569 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.572158
[INFO 23-08-16 11:08:20.7569 UTC gradient_boosted_trees.cc:247] Truncates the model to 209 tree(s) i.e. 209 iteration(s).
[INFO 23-08-16 11:08:20.7574 UTC gradient_boosted_trees.cc:310] Final model num-trees:209 valid-loss:0.572158 valid-accuracy:0.872953
[INFO 23-08-16 11:08:20.7623 UTC hyperparameters_optimizer.cc:582] [45/50] Score: -0.572158 / -0.566897 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 64 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:21.3810 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.524785 train-accuracy:0.882871 valid-loss:0.586497 valid-accuracy:0.869411
[INFO 23-08-16 11:08:21.3810 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:21.3810 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.586497 valid-accuracy:0.869411
[INFO 23-08-16 11:08:21.3853 UTC hyperparameters_optimizer.cc:582] [46/50] Score: -0.586497 / -0.566897 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:21.8747 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.531623 train-accuracy:0.882871 valid-loss:0.586301 valid-accuracy:0.871625
[INFO 23-08-16 11:08:21.8748 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:21.8748 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.586301 valid-accuracy:0.871625
[INFO 23-08-16 11:08:21.8784 UTC hyperparameters_optimizer.cc:582] [47/50] Score: -0.586301 / -0.566897 HParams: fields { name: "min_examples" value { integer: 5 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 6 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:24.0003 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.479808 train-accuracy:0.892174 valid-loss:0.580708 valid-accuracy:0.871182
[INFO 23-08-16 11:08:24.0004 UTC gradient_boosted_trees.cc:247] Truncates the model to 299 tree(s) i.e. 299 iteration(s).
[INFO 23-08-16 11:08:24.0004 UTC gradient_boosted_trees.cc:310] Final model num-trees:299 valid-loss:0.580696 valid-accuracy:0.871625
[INFO 23-08-16 11:08:24.0105 UTC hyperparameters_optimizer.cc:582] [48/50] Score: -0.580696 / -0.566897 HParams: fields { name: "min_examples" value { integer: 7 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:08:24.6673 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.573524
[INFO 23-08-16 11:08:24.6673 UTC gradient_boosted_trees.cc:247] Truncates the model to 252 tree(s) i.e. 252 iteration(s).
[INFO 23-08-16 11:08:24.6678 UTC gradient_boosted_trees.cc:310] Final model num-trees:252 valid-loss:0.573524 valid-accuracy:0.868083
[INFO 23-08-16 11:08:24.6718 UTC hyperparameters_optimizer.cc:582] [49/50] Score: -0.573524 / -0.566897 HParams: fields { name: "min_examples" value { integer: 2 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 6 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:25.0729 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.503526 train-accuracy:0.890420 valid-loss:0.580347 valid-accuracy:0.870297
[INFO 23-08-16 11:08:25.0729 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:08:25.0730 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.580347 valid-accuracy:0.870297
[INFO 23-08-16 11:08:25.0785 UTC hyperparameters_optimizer.cc:582] [50/50] Score: -0.580347 / -0.566897 HParams: fields { name: "min_examples" value { integer: 10 } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 128 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:25.1012 UTC hyperparameters_optimizer.cc:219] Best hyperparameters:
fields {
name: "min_examples"
value {
integer: 2
}
}
fields {
name: "categorical_algorithm"
value {
categorical: "RANDOM"
}
}
fields {
name: "growing_strategy"
value {
categorical: "BEST_FIRST_GLOBAL"
}
}
fields {
name: "max_num_nodes"
value {
integer: 64
}
}
fields {
name: "use_hessian_gain"
value {
categorical: "true"
}
}
fields {
name: "shrinkage"
value {
real: 0.1
}
}
fields {
name: "num_candidate_attributes_ratio"
value {
real: 0.9
}
}
[INFO 23-08-16 11:08:25.1016 UTC kernel.cc:926] Export model in log directory: /tmpfs/tmp/tmpzdzgno07 with prefix 752bc47fe3694f88
[INFO 23-08-16 11:08:25.1108 UTC kernel.cc:944] Save model in resources
[INFO 23-08-16 11:08:25.1135 UTC abstract_model.cc:849] Model self evaluation:
Task: CLASSIFICATION
Label: __LABEL
Loss (BINOMIAL_LOG_LIKELIHOOD): 0.566897
Accuracy: 0.873395 CI95[W][0 1]
ErrorRate: : 0.126605
Confusion Table:
truth\prediction
0 1 2
0 0 0 0
1 0 1572 92
2 0 194 401
Total: 2259
One vs other classes:
[INFO 23-08-16 11:08:25.1327 UTC kernel.cc:1243] Loading model from path /tmpfs/tmp/tmpzdzgno07/model/ with prefix 752bc47fe3694f88
[INFO 23-08-16 11:08:25.1690 UTC abstract_model.cc:1311] Engine "GradientBoostedTreesQuickScorerExtended" built
[INFO 23-08-16 11:08:25.1691 UTC kernel.cc:1075] Use fast generic engine
Model trained in 0:00:21.820976
Compiling model...
Model compiled.
CPU times: user 7min 2s, sys: 576 ms, total: 7min 3s
Wall time: 22.4 s
<keras.src.callbacks.History at 0x7f2410cdc040>
# 评估模型
tuned_model.compile(["accuracy"]) # 编译模型,使用"accuracy"作为评估指标
# 使用测试数据集评估调整后的模型
tuned_test_accuracy = tuned_model.evaluate(test_ds, return_dict=True, verbose=0)["accuracy"] # 返回测试数据集的准确率print(f"Test accuracy with the TF-DF hyper-parameter tuner: {tuned_test_accuracy:.4f}") # 打印使用TF-DF超参数调整器得到的测试准确率
Test accuracy with the TF-DF hyper-parameter tuner: 0.8744
在模型检查器中,可以查看试验的超参数和目标分数。score值始终被最大化。在这个例子中,分数是验证数据集上的负对数损失(自动选择)。
# 显示调优日志。
# 调用tuned_model的make_inspector()方法,返回一个调优模型的检查器对象。
# 调用检查器对象的tuning_logs()方法,返回调优日志。
tuning_logs = tuned_model.make_inspector().tuning_logs()
tuning_logs.head()
| score | evaluation_time | best | min_examples | categorical_algorithm | growing_strategy | max_depth | use_hessian_gain | shrinkage | num_candidate_attributes_ratio | max_num_nodes | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.590370 | 2.080748 | False | 7 | CART | LOCAL | 3.0 | true | 0.15 | 0.2 | NaN |
| 1 | -0.583674 | 2.107974 | False | 5 | CART | LOCAL | 8.0 | true | 0.15 | 0.2 | NaN |
| 2 | -0.581734 | 3.304178 | False | 10 | CART | LOCAL | 3.0 | true | 0.15 | 1.0 | NaN |
| 3 | -0.585214 | 3.441370 | False | 10 | RANDOM | LOCAL | 3.0 | true | 0.15 | 0.5 | NaN |
| 4 | -0.588227 | 3.881257 | False | 7 | CART | BEST_FIRST_GLOBAL | NaN | false | 0.10 | 0.2 | 64.0 |
单行中的 best=True 是在最终模型中使用的行。
# 获取最佳超参数的日志记录
best_hyperparameters = tuning_logs[tuning_logs.best]
# 获取第一条最佳超参数的日志记录
first_best_hyperparameters = best_hyperparameters.iloc[0]
score -0.566897
evaluation_time 15.33206
best True
min_examples 2
categorical_algorithm RANDOM
growing_strategy BEST_FIRST_GLOBAL
max_depth NaN
use_hessian_gain true
shrinkage 0.1
num_candidate_attributes_ratio 0.9
max_num_nodes 64.0
Name: 41, dtype: object
注意: 值为NaN的参数是未设置的条件参数。
接下来,我们绘制调整过程中最佳分数的评估结果。
# 设置图形的大小
plt.figure(figsize=(10, 5))
# 绘制当前试验的得分曲线
plt.plot(tuning_logs["score"], label="current trial")
# 绘制历史最佳试验的得分曲线
plt.plot(tuning_logs["score"].cummax(), label="best trial")
# 设置x轴标签
plt.xlabel("Tuning step")
# 设置y轴标签
plt.ylabel("Tuning score")
# 添加图例
plt.legend()
# 显示图形
plt.show()
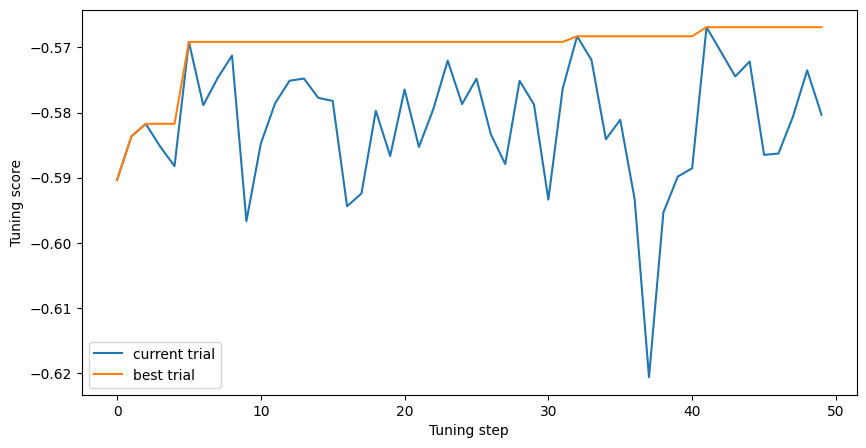
使用自动化超参数调整和自动定义超参数的模型训练(推荐方法)
与之前一样,通过指定模型的tuner构造函数参数来启用超参数调整。设置use_predefined_hps=True以自动配置超参数的搜索空间。
**注意:**自动超参数配置会探索一些强大但训练速度较慢的超参数。例如,斜分割(在上一节中被注释/禁用;参见SPARSE_OBLIQUE)会被测试。这意味着调整过程会更慢,但希望能得到质量更高的结果。
# 设置代码运行时间和单元格高度
%%time
%set_cell_height 300
# 创建一个随机搜索调谐器,进行50次试验,并使用自动化的超参数配置。
tuner = tfdf.tuner.RandomSearch(num_trials=50, use_predefined_hps=True)
# 定义并训练模型
tuned_model = tfdf.keras.GradientBoostedTreesModel(tuner=tuner)
tuned_model.fit(train_ds, verbose=2)
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpfhjg70bi as temporary training directory
Reading training dataset...
Training tensor examples:
Features: {'age': <tf.Tensor 'data:0' shape=(None,) dtype=int64>, 'workclass': <tf.Tensor 'data_1:0' shape=(None,) dtype=string>, 'fnlwgt': <tf.Tensor 'data_2:0' shape=(None,) dtype=int64>, 'education': <tf.Tensor 'data_3:0' shape=(None,) dtype=string>, 'education_num': <tf.Tensor 'data_4:0' shape=(None,) dtype=int64>, 'marital_status': <tf.Tensor 'data_5:0' shape=(None,) dtype=string>, 'occupation': <tf.Tensor 'data_6:0' shape=(None,) dtype=string>, 'relationship': <tf.Tensor 'data_7:0' shape=(None,) dtype=string>, 'race': <tf.Tensor 'data_8:0' shape=(None,) dtype=string>, 'sex': <tf.Tensor 'data_9:0' shape=(None,) dtype=string>, 'capital_gain': <tf.Tensor 'data_10:0' shape=(None,) dtype=int64>, 'capital_loss': <tf.Tensor 'data_11:0' shape=(None,) dtype=int64>, 'hours_per_week': <tf.Tensor 'data_12:0' shape=(None,) dtype=int64>, 'native_country': <tf.Tensor 'data_13:0' shape=(None,) dtype=string>}
Label: Tensor("data_14:0", shape=(None,), dtype=int64)
Weights: None
Normalized tensor features:
{'age': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast:0' shape=(None,) dtype=float32>), 'workclass': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_1:0' shape=(None,) dtype=string>), 'fnlwgt': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_1:0' shape=(None,) dtype=float32>), 'education': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_3:0' shape=(None,) dtype=string>), 'education_num': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_2:0' shape=(None,) dtype=float32>), 'marital_status': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_5:0' shape=(None,) dtype=string>), 'occupation': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_6:0' shape=(None,) dtype=string>), 'relationship': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_7:0' shape=(None,) dtype=string>), 'race': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_8:0' shape=(None,) dtype=string>), 'sex': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_9:0' shape=(None,) dtype=string>), 'capital_gain': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_3:0' shape=(None,) dtype=float32>), 'capital_loss': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_4:0' shape=(None,) dtype=float32>), 'hours_per_week': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_5:0' shape=(None,) dtype=float32>), 'native_country': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_13:0' shape=(None,) dtype=string>)}
[WARNING 23-08-16 11:08:25.8988 UTC gradient_boosted_trees.cc:1818] "goss_alpha" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:08:25.8988 UTC gradient_boosted_trees.cc:1829] "goss_beta" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:08:25.8988 UTC gradient_boosted_trees.cc:1843] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB".
Training dataset read in 0:00:00.378785. Found 22792 examples.
Training model...
[INFO 23-08-16 11:08:26.2894 UTC kernel.cc:773] Start Yggdrasil model training
[INFO 23-08-16 11:08:26.2895 UTC kernel.cc:774] Collect training examples
[INFO 23-08-16 11:08:26.2895 UTC kernel.cc:787] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
categorial {
min_vocab_frequency: 0
max_vocab_count: -1
}
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
[INFO 23-08-16 11:08:26.2896 UTC kernel.cc:393] Number of batches: 23
[INFO 23-08-16 11:08:26.2896 UTC kernel.cc:394] Number of examples: 22792
[INFO 23-08-16 11:08:26.2970 UTC data_spec_inference.cc:305] 1 item(s) have been pruned (i.e. they are considered out of dictionary) for the column native_country (40 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 23-08-16 11:08:26.2970 UTC data_spec_inference.cc:305] 1 item(s) have been pruned (i.e. they are considered out of dictionary) for the column occupation (13 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 23-08-16 11:08:26.2971 UTC data_spec_inference.cc:305] 1 item(s) have been pruned (i.e. they are considered out of dictionary) for the column workclass (7 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 23-08-16 11:08:26.3035 UTC kernel.cc:794] Training dataset:
Number of records: 22792
Number of columns: 15
Number of columns by type:
CATEGORICAL: 9 (60%)
NUMERICAL: 6 (40%)
Columns:
CATEGORICAL: 9 (60%)
0: "__LABEL" CATEGORICAL integerized vocab-size:3 no-ood-item
4: "education" CATEGORICAL has-dict vocab-size:17 zero-ood-items most-frequent:"HS-grad" 7340 (32.2043%)
8: "marital_status" CATEGORICAL has-dict vocab-size:8 zero-ood-items most-frequent:"Married-civ-spouse" 10431 (45.7661%)
9: "native_country" CATEGORICAL num-nas:407 (1.78571%) has-dict vocab-size:41 num-oods:1 (0.00446728%) most-frequent:"United-States" 20436 (91.2933%)
10: "occupation" CATEGORICAL num-nas:1260 (5.52826%) has-dict vocab-size:14 num-oods:1 (0.00464425%) most-frequent:"Prof-specialty" 2870 (13.329%)
11: "race" CATEGORICAL has-dict vocab-size:6 zero-ood-items most-frequent:"White" 19467 (85.4115%)
12: "relationship" CATEGORICAL has-dict vocab-size:7 zero-ood-items most-frequent:"Husband" 9191 (40.3256%)
13: "sex" CATEGORICAL has-dict vocab-size:3 zero-ood-items most-frequent:"Male" 15165 (66.5365%)
14: "workclass" CATEGORICAL num-nas:1257 (5.51509%) has-dict vocab-size:8 num-oods:1 (0.0046436%) most-frequent:"Private" 15879 (73.7358%)
NUMERICAL: 6 (40%)
1: "age" NUMERICAL mean:38.6153 min:17 max:90 sd:13.661
2: "capital_gain" NUMERICAL mean:1081.9 min:0 max:99999 sd:7509.48
3: "capital_loss" NUMERICAL mean:87.2806 min:0 max:4356 sd:403.01
5: "education_num" NUMERICAL mean:10.0927 min:1 max:16 sd:2.56427
6: "fnlwgt" NUMERICAL mean:189879 min:12285 max:1.4847e+06 sd:106423
7: "hours_per_week" NUMERICAL mean:40.3955 min:1 max:99 sd:12.249
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute which type is manually defined by the user i.e. the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
[INFO 23-08-16 11:08:26.3035 UTC kernel.cc:810] Configure learner
[WARNING 23-08-16 11:08:26.3038 UTC gradient_boosted_trees.cc:1818] "goss_alpha" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:08:26.3038 UTC gradient_boosted_trees.cc:1829] "goss_beta" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:08:26.3038 UTC gradient_boosted_trees.cc:1843] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB".
[INFO 23-08-16 11:08:26.3039 UTC kernel.cc:824] Training config:
learner: "HYPERPARAMETER_OPTIMIZER"
features: "^age$"
features: "^capital_gain$"
features: "^capital_loss$"
features: "^education$"
features: "^education_num$"
features: "^fnlwgt$"
features: "^hours_per_week$"
features: "^marital_status$"
features: "^native_country$"
features: "^occupation$"
features: "^race$"
features: "^relationship$"
features: "^sex$"
features: "^workclass$"
label: "^__LABEL$"
task: CLASSIFICATION
metadata {
framework: "TF Keras"
}
[yggdrasil_decision_forests.model.hyperparameters_optimizer_v2.proto.hyperparameters_optimizer_config] {
base_learner {
learner: "GRADIENT_BOOSTED_TREES"
features: "^age$"
features: "^capital_gain$"
features: "^capital_loss$"
features: "^education$"
features: "^education_num$"
features: "^fnlwgt$"
features: "^hours_per_week$"
features: "^marital_status$"
features: "^native_country$"
features: "^occupation$"
features: "^race$"
features: "^relationship$"
features: "^sex$"
features: "^workclass$"
label: "^__LABEL$"
task: CLASSIFICATION
random_seed: 123456
pure_serving_model: false
[yggdrasil_decision_forests.model.gradient_boosted_trees.proto.gradient_boosted_trees_config] {
num_trees: 300
decision_tree {
max_depth: 6
min_examples: 5
in_split_min_examples_check: true
keep_non_leaf_label_distribution: true
num_candidate_attributes: -1
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
uplift {
min_examples_in_treatment: 5
split_score: KULLBACK_LEIBLER
}
}
shrinkage: 0.1
loss: DEFAULT
validation_set_ratio: 0.1
validation_interval_in_trees: 1
early_stopping: VALIDATION_LOSS_INCREASE
early_stopping_num_trees_look_ahead: 30
l2_regularization: 0
lambda_loss: 1
mart {
}
adapt_subsample_for_maximum_training_duration: false
l1_regularization: 0
use_hessian_gain: false
l2_regularization_categorical: 1
stochastic_gradient_boosting {
ratio: 1
}
apply_link_function: true
compute_permutation_variable_importance: false
binary_focal_loss_options {
misprediction_exponent: 2
positive_sample_coefficient: 0.5
}
early_stopping_initial_iteration: 10
}
}
optimizer {
optimizer_key: "RANDOM"
[yggdrasil_decision_forests.model.hyperparameters_optimizer_v2.proto.random] {
num_trials: 50
}
}
base_learner_deployment {
num_threads: 1
}
predefined_search_space {
}
}
[INFO 23-08-16 11:08:26.3040 UTC kernel.cc:827] Deployment config:
cache_path: "/tmpfs/tmp/tmpfhjg70bi/working_cache"
num_threads: 32
try_resume_training: true
[INFO 23-08-16 11:08:26.3042 UTC kernel.cc:889] Train model
[INFO 23-08-16 11:08:26.3045 UTC hyperparameters_optimizer.cc:209] Hyperparameter search space:
fields {
name: "split_axis"
discrete_candidates {
possible_values {
categorical: "AXIS_ALIGNED"
}
possible_values {
categorical: "SPARSE_OBLIQUE"
}
}
children {
name: "sparse_oblique_projection_density_factor"
discrete_candidates {
possible_values {
real: 1
}
possible_values {
real: 2
}
possible_values {
real: 3
}
possible_values {
real: 4
}
possible_values {
real: 5
}
}
parent_discrete_values {
possible_values {
categorical: "SPARSE_OBLIQUE"
}
}
}
children {
name: "sparse_oblique_normalization"
discrete_candidates {
possible_values {
categorical: "NONE"
}
possible_values {
categorical: "STANDARD_DEVIATION"
}
possible_values {
categorical: "MIN_MAX"
}
}
parent_discrete_values {
possible_values {
categorical: "SPARSE_OBLIQUE"
}
}
}
children {
name: "sparse_oblique_weights"
discrete_candidates {
possible_values {
categorical: "BINARY"
}
possible_values {
categorical: "CONTINUOUS"
}
}
parent_discrete_values {
possible_values {
categorical: "SPARSE_OBLIQUE"
}
}
}
}
fields {
name: "categorical_algorithm"
discrete_candidates {
possible_values {
categorical: "CART"
}
possible_values {
categorical: "RANDOM"
}
}
}
fields {
name: "growing_strategy"
discrete_candidates {
possible_values {
categorical: "LOCAL"
}
possible_values {
categorical: "BEST_FIRST_GLOBAL"
}
}
children {
name: "max_num_nodes"
discrete_candidates {
possible_values {
integer: 16
}
possible_values {
integer: 32
}
possible_values {
integer: 64
}
possible_values {
integer: 128
}
possible_values {
integer: 256
}
possible_values {
integer: 512
}
}
parent_discrete_values {
possible_values {
categorical: "BEST_FIRST_GLOBAL"
}
}
}
children {
name: "max_depth"
discrete_candidates {
possible_values {
integer: 3
}
possible_values {
integer: 4
}
possible_values {
integer: 6
}
possible_values {
integer: 8
}
}
parent_discrete_values {
possible_values {
categorical: "LOCAL"
}
}
}
}
fields {
name: "sampling_method"
discrete_candidates {
possible_values {
categorical: "RANDOM"
}
}
children {
name: "subsample"
discrete_candidates {
possible_values {
real: 0.6
}
possible_values {
real: 0.8
}
possible_values {
real: 0.9
}
possible_values {
real: 1
}
}
parent_discrete_values {
possible_values {
categorical: "RANDOM"
}
}
}
}
fields {
name: "shrinkage"
discrete_candidates {
possible_values {
real: 0.02
}
possible_values {
real: 0.05
}
possible_values {
real: 0.1
}
}
}
fields {
name: "min_examples"
discrete_candidates {
possible_values {
integer: 5
}
possible_values {
integer: 7
}
possible_values {
integer: 10
}
possible_values {
integer: 20
}
}
}
fields {
name: "use_hessian_gain"
discrete_candidates {
possible_values {
categorical: "true"
}
possible_values {
categorical: "false"
}
}
}
fields {
name: "num_candidate_attributes_ratio"
discrete_candidates {
possible_values {
real: 0.2
}
possible_values {
real: 0.5
}
possible_values {
real: 0.9
}
possible_values {
real: 1
}
}
}
[INFO 23-08-16 11:08:26.3046 UTC hyperparameters_optimizer.cc:500] Start local tuner with 32 thread(s)
[INFO[INFO 23-08-16 11:08:26.3062 UTC 23-08-16 11:08:26.3062 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
gradient_boosted_trees.cc:[INFO 23-08-16 11:08:26.3062 UTC gradient_boosted_trees.cc459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).[INFO[INFO 23-08-16 11:08:26.3063 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3063 UTC gradient_boosted_trees.cc:1085]
[INFO 23-08-16 11:08:26.3063 UTC gradient_boosted_trees.cc:459 23-08-16 11:08:26.3063 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
Training gradient boosted tree on 22792 example(s) and 14 feature(s).
] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3064 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3065 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3065 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3065 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3066 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3066 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3067 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3067 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3068 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO[INFO 23-08-16 11:08:26.3070 UTC 23-08-16 11:08:26.3069 UTC gradient_boosted_trees.cc:459gradient_boosted_trees.cc:459] ] Default loss set to BINOMIAL_LOG_LIKELIHOOD
Default loss set to [INFOBINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3070 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 23-08-16 11:08:26.3070 UTC gradient_boosted_trees.cc:108514 feature(s).
] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[[INFOINFO 23-08-16 11:08:26.3072 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
23-08-16 11:08:26.3072 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD[INFO 23-08-16 11:08:26.3072 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and
14[INFO 23-08-16 11:08:26.3073 UTC gradient_boosted_trees.cc: feature(s).
1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3074 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3074 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3075 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3076 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3077 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3077 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3082 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3082 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792[INFO example(s) and 14 feature(s).
23-08-16 11:08:26.3082 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3083 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3090 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3090 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3091 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3091 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO[ 23-08-16 11:08:26.3099 UTC gradient_boosted_trees.cc:459INFO 23-08-16 11:08:26.3099 UTC gradient_boosted_trees.cc:] Default loss set to BINOMIAL_LOG_LIKELIHOOD
459] Default loss set to [INFO 23-08-16 11:08:26.3099 UTC gradient_boosted_trees.cc:1085BINOMIAL_LOG_LIKELIHOOD
] [Training gradient boosted tree on 22792 example(s) and 14 feature(s).
INFO 23-08-16 11:08:26.3100 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO[INFO 23-08-16 11:08:26.3102 UTC gradient_boosted_trees.cc 23-08-16 11:08:26.3102 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3102 UTC gradient_boosted_trees.cc:1085:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
] Training gradient boosted tree on 22792 example(s) and 14 feature(s).[INFO[ 23-08-16 11:08:26.3103 UTC INFOgradient_boosted_trees.cc:459] 23-08-16 11:08:26.3103 UTC [INFOgradient_boosted_trees.ccDefault loss set to BINOMIAL_LOG_LIKELIHOOD
:[INFO459 23-08-16 11:08:26.3104 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3105 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 23-08-16 11:08:26.3104 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
feature(s).
[INFO 23-08-16 11:08:26.3107 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3107 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3109 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3109 UTC gradient_boosted_trees.cc[INFO:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[ 23-08-16 11:08:26.3110 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
INFO 23-08-16 11:08:26.3110 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3116 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3116 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3117 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3118 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3123 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3124 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3125 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:26.3125 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:26.3150 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3160 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO[INFO 23-08-16 11:08:26.3404 UTC gradient_boosted_trees.cc: 23-08-16 11:08:26.3404 UTC 1128] 20533 examples used for training and 2259 examples used for validation
gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3589 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3593 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3597 UTC gradient_boosted_trees.cc:[INFO1128] 20533 examples used for training and 2259 examples used for validation
23-08-16 11:08:26.3597 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3607 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3614 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3617 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3618 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3628 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3629 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation[INFO
23-08-16 11:08:26.3629 UTC gradient_boosted_trees.cc[[INFOINFO:1128] 23-08-16 11:08:26.3630 UTC gradient_boosted_trees.cc20533 examples used for training and 2259 examples used for validation
:1128] 20533 examples used for training and 2259 examples used for validation 23-08-16 11:08:26.3630 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO[ 23-08-16 11:08:26.3631 UTC gradient_boosted_trees.ccINFO[INFO: 23-08-16 11:08:26.3632 UTC gradient_boosted_trees.cc:11281128] 20533 examples used for training and 2259 examples used for validation
23-08-16 11:08:26.3632 UTC gradient_boosted_trees.cc:] 20533 examples used for training and 2259 examples used for validation
1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3633 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3640 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3644 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3653 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3659 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation[INFO 23-08-16 11:08:26.3660 UTC gradient_boosted_trees.cc:1128]
20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3685 UTC gradient_boosted_trees.cc:1128] 20533[INFO examples used for training and 2259 examples used for validation 23-08-16 11:08:26.3685 UTC gradient_boosted_trees.cc:1128
] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3805 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259[[INFO examples used for validationINFO 23-08-16 11:08:26.3805 UTC gradient_boosted_trees.cc
23-08-16 11:08:26.3805 UTC gradient_boosted_trees.cc::1128] 205331128] 20533 examples used for training and 2259 examples used for validation
examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.3807 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:08:26.4823 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.060520 train-accuracy:0.761895 valid-loss:1.117708 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.5109 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.034401 train-accuracy:0.761895 valid-loss:1.090277 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.5224 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.082692 train-accuracy:0.761895 valid-loss:1.140741 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.5375 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.024398 train-accuracy:0.761895 valid-loss:1.080875 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.5471 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080233 train-accuracy:0.761895 valid-loss:1.138164 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.5489 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.060070 train-accuracy:0.761895 valid-loss:1.117365 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.5523 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.016328 train-accuracy:0.761895 valid-loss:1.070658 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.5628 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.085297 train-accuracy:0.761895 valid-loss:1.143266 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.6032 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.053581 train-accuracy:0.761895 valid-loss:1.110675 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.6160 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.009800 train-accuracy:0.761895 valid-loss:1.063156 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.6367 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.053989 train-accuracy:0.761895 valid-loss:1.111597 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.6621 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.079152 train-accuracy:0.761895 valid-loss:1.137115 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.6675 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080746 train-accuracy:0.761895 valid-loss:1.138830 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.6724 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.016576 train-accuracy:0.761895 valid-loss:1.072904 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.6797 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.017781 train-accuracy:0.761895 valid-loss:1.072645 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.6858 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.079625 train-accuracy:0.761895 valid-loss:1.137371 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.7092 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.014103 train-accuracy:0.761895 valid-loss:1.069569 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.7182 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.019006 train-accuracy:0.761895 valid-loss:1.073190 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.7315 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.079718 train-accuracy:0.761895 valid-loss:1.137516 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.7553 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.052418 train-accuracy:0.761895 valid-loss:1.109157 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.7691 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.050215 train-accuracy:0.761895 valid-loss:1.106337 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.7820 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.052939 train-accuracy:0.761895 valid-loss:1.109668 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.7999 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080744 train-accuracy:0.761895 valid-loss:1.138851 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.8126 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.017080 train-accuracy:0.761895 valid-loss:1.072045 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.8227 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080979 train-accuracy:0.761895 valid-loss:1.138389 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.8270 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.078470 train-accuracy:0.761895 valid-loss:1.135989 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.8476 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.079121 train-accuracy:0.761895 valid-loss:1.136935 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.8502 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.011469 train-accuracy:0.761895 valid-loss:1.065462 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.8557 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.054467 train-accuracy:0.761895 valid-loss:1.111421 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.8624 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.007886 train-accuracy:0.761895 valid-loss:1.061560 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.8796 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.079504 train-accuracy:0.761895 valid-loss:1.137702 valid-accuracy:0.736609
[INFO 23-08-16 11:08:26.9287 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.052843 train-accuracy:0.761895 valid-loss:1.111456 valid-accuracy:0.736609
[INFO 23-08-16 11:08:27.5955 UTC gradient_boosted_trees.cc:1544] num-trees:3 train-loss:0.978275 train-accuracy:0.761895 valid-loss:1.030907 valid-accuracy:0.736609
[INFO 23-08-16 11:08:57.6001 UTC gradient_boosted_trees.cc:1544] num-trees:71 train-loss:0.645856 train-accuracy:0.864511 valid-loss:0.712521 valid-accuracy:0.838424
[INFO 23-08-16 11:08:59.8972 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.621505
[INFO 23-08-16 11:08:59.8972 UTC gradient_boosted_trees.cc:247] Truncates the model to 72 tree(s) i.e. 72 iteration(s).
[INFO 23-08-16 11:08:59.8981 UTC gradient_boosted_trees.cc:310] Final model num-trees:72 valid-loss:0.621505 valid-accuracy:0.858344
[INFO 23-08-16 11:08:59.9002 UTC hyperparameters_optimizer.cc:582] [1/50] Score: -0.621505 / -0.621505 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.6 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:08:59.9008 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:08:59.9009 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:08:59.9064 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:00.2983 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.082344 train-accuracy:0.761895 valid-loss:1.140383 valid-accuracy:0.736609
[INFO 23-08-16 11:09:00.5775 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.587795
[INFO 23-08-16 11:09:00.5775 UTC gradient_boosted_trees.cc:247] Truncates the model to 150 tree(s) i.e. 150 iteration(s).
[INFO 23-08-16 11:09:00.5779 UTC gradient_boosted_trees.cc:310] Final model num-trees:150 valid-loss:0.587795 valid-accuracy:0.864099
[INFO 23-08-16 11:09:00.5802 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:00.5802 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:00.5813 UTC hyperparameters_optimizer.cc:582] [2/50] Score: -0.587795 / -0.587795 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 1 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.6 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:09:00.5852 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:01.0792 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.056010 train-accuracy:0.761895 valid-loss:1.115039 valid-accuracy:0.736609
[INFO 23-08-16 11:09:03.1408 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.540863 train-accuracy:0.879268 valid-loss:0.593033 valid-accuracy:0.868969
[INFO 23-08-16 11:09:03.1408 UTC gradient_boosted_trees.cc:247] Truncates the model to 294 tree(s) i.e. 294 iteration(s).
[INFO 23-08-16 11:09:03.1409 UTC gradient_boosted_trees.cc:310] Final model num-trees:294 valid-loss:0.592873 valid-accuracy:0.868526
[INFO 23-08-16 11:09:03.1425 UTC hyperparameters_optimizer.cc:582] [3/50] Score: -0.592873 / -0.587795 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 2 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 4 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.6 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:09:03.1457 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:03.1457 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:03.1505 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:03.5161 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080643 train-accuracy:0.761895 valid-loss:1.138458 valid-accuracy:0.736609
[INFO 23-08-16 11:09:04.0248 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.579144
[INFO 23-08-16 11:09:04.0248 UTC gradient_boosted_trees.cc:247] Truncates the model to 87 tree(s) i.e. 87 iteration(s).
[INFO 23-08-16 11:09:04.0259 UTC gradient_boosted_trees.cc:310] Final model num-trees:87 valid-loss:0.579144 valid-accuracy:0.868969
[INFO 23-08-16 11:09:04.0310 UTC hyperparameters_optimizer.cc:582] [4/50] Score: -0.579144 / -0.579144 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 1 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 512 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:09:04.0316 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:04.0317 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:04.0367 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:04.4008 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.008621 train-accuracy:0.761895 valid-loss:1.061219 valid-accuracy:0.736609
[INFO 23-08-16 11:09:07.4914 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.604322
[INFO 23-08-16 11:09:07.4914 UTC gradient_boosted_trees.cc:247] Truncates the model to 97 tree(s) i.e. 97 iteration(s).
[INFO 23-08-16 11:09:07.4921 UTC gradient_boosted_trees.cc:310] Final model num-trees:97 valid-loss:0.604322 valid-accuracy:0.860115
[INFO 23-08-16 11:09:07.4942 UTC hyperparameters_optimizer.cc:582] [5/50] Score: -0.604322 / -0.579144 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 6 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:09:07.4955 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:07.4955 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:07.5006 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:07.9368 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.022495 train-accuracy:0.761895 valid-loss:1.078056 valid-accuracy:0.736609
[INFO 23-08-16 11:09:11.4269 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.558511 train-accuracy:0.874446 valid-loss:0.616054 valid-accuracy:0.861000
[INFO 23-08-16 11:09:11.4270 UTC gradient_boosted_trees.cc:247] Truncates the model to 299 tree(s) i.e. 299 iteration(s).
[INFO 23-08-16 11:09:11.4270 UTC gradient_boosted_trees.cc:310] Final model num-trees:299 valid-loss:0.616025 valid-accuracy:0.861000
[INFO 23-08-16 11:09:11.4279 UTC hyperparameters_optimizer.cc:582] [6/50] Score: -0.616025 / -0.579144 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:09:11.4297 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:11.4297 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:11.4346 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:11.5118 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080831 train-accuracy:0.761895 valid-loss:1.138862 valid-accuracy:0.736609
[INFO 23-08-16 11:09:13.3635 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.588981 train-accuracy:0.865972 valid-loss:0.618730 valid-accuracy:0.857459
[INFO 23-08-16 11:09:13.3636 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:09:13.3636 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.618730 valid-accuracy:0.857459
[INFO 23-08-16 11:09:13.3652 UTC hyperparameters_optimizer.cc:582] [7/50] Score: -0.61873 / -0.579144 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 4 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.6 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:09:13.3679 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:13.3679 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:13.3727 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:13.5048 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.035720 train-accuracy:0.761895 valid-loss:1.091776 valid-accuracy:0.736609
[INFO 23-08-16 11:09:14.7979 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.594984
[INFO 23-08-16 11:09:14.7979 UTC gradient_boosted_trees.cc:247] Truncates the model to 67 tree(s) i.e. 67 iteration(s).
[INFO 23-08-16 11:09:14.7988 UTC gradient_boosted_trees.cc:310] Final model num-trees:67 valid-loss:0.594984 valid-accuracy:0.862328
[INFO 23-08-16 11:09:14.8013 UTC hyperparameters_optimizer.cc:582] [8/50] Score: -0.594984 / -0.579144 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 256 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:09:14.8046 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:14.8046 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:14.8094 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:14.8846 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.601315
[INFO 23-08-16 11:09:14.8847 UTC gradient_boosted_trees.cc:247] Truncates the model to 240 tree(s) i.e. 240 iteration(s).
[INFO 23-08-16 11:09:14.8849 UTC gradient_boosted_trees.cc:310] Final model num-trees:240 valid-loss:0.601315 valid-accuracy:0.865427
[INFO 23-08-16 11:09:14.8861 UTC hyperparameters_optimizer.cc:582] [9/50] Score: -0.601315 / -0.579144 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 3 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 4 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:09:14.8885 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:14.8886 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:14.8931 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:15.0170 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.033852 train-accuracy:0.761895 valid-loss:1.089140 valid-accuracy:0.736609
[INFO 23-08-16 11:09:15.2405 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.080070 train-accuracy:0.761895 valid-loss:1.138312 valid-accuracy:0.736609
[INFO 23-08-16 11:09:17.3329 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.609047
[INFO 23-08-16 11:09:17.3330 UTC gradient_boosted_trees.cc:247] Truncates the model to 151 tree(s) i.e. 151 iteration(s).
[INFO 23-08-16 11:09:17.3341 UTC gradient_boosted_trees.cc:310] Final model num-trees:151 valid-loss:0.609047 valid-accuracy:0.864542
[INFO 23-08-16 11:09:17.3392 UTC hyperparameters_optimizer.cc:582] [10/50] Score: -0.609047 / -0.579144 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 256 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.6 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:09:17.3474 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:17.3474 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:17.3521 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:17.6767 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.055057 train-accuracy:0.761895 valid-loss:1.112117 valid-accuracy:0.736609
[INFO 23-08-16 11:09:18.1050 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.585247
[INFO 23-08-16 11:09:18.1051 UTC gradient_boosted_trees.cc:247] Truncates the model to 180 tree(s) i.e. 180 iteration(s).
[INFO 23-08-16 11:09:18.1061 UTC gradient_boosted_trees.cc:310] Final model num-trees:180 valid-loss:0.585247 valid-accuracy:0.865870
[INFO 23-08-16 11:09:18.1116 UTC hyperparameters_optimizer.cc:582] [11/50] Score: -0.585247 / -0.579144 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 3 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 256 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.6 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:09:18.1204 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:18.1205 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:18.1250 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:18.2802 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.576761
[INFO 23-08-16 11:09:18.2802 UTC gradient_boosted_trees.cc:247] Truncates the model to 104 tree(s) i.e. 104 iteration(s).
[INFO 23-08-16 11:09:18.2819 UTC gradient_boosted_trees.cc:310] Final model num-trees:104 valid-loss:0.576761 valid-accuracy:0.871182
[INFO 23-08-16 11:09:18.2890 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:18.2890 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:18.2920 UTC hyperparameters_optimizer.cc:582] [12/50] Score: -0.576761 / -0.576761 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 2 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:09:18.2944 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:18.4524 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.011378 train-accuracy:0.761895 valid-loss:1.065565 valid-accuracy:0.736609
[INFO 23-08-16 11:09:18.7125 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.007702 train-accuracy:0.761895 valid-loss:1.061728 valid-accuracy:0.736609
[INFO 23-08-16 11:09:19.1543 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.574235
[INFO 23-08-16 11:09:19.1543 UTC gradient_boosted_trees.cc:247] Truncates the model to 135 tree(s) i.e. 135 iteration(s).
[INFO 23-08-16 11:09:19.1551 UTC gradient_boosted_trees.cc:310] Final model num-trees:135 valid-loss:0.574235 valid-accuracy:0.868969
[INFO 23-08-16 11:09:19.1589 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:19.1590 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:19.1635 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:19.1649 UTC hyperparameters_optimizer.cc:582] [13/50] Score: -0.574235 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 1 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 64 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:09:19.6725 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.054670 train-accuracy:0.761895 valid-loss:1.111134 valid-accuracy:0.736609
[INFO 23-08-16 11:09:19.8336 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.616186 train-accuracy:0.859787 valid-loss:0.644742 valid-accuracy:0.851262
[INFO 23-08-16 11:09:19.8336 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:09:19.8336 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.644742 valid-accuracy:0.851262
[INFO 23-08-16 11:09:19.8346 UTC hyperparameters_optimizer.cc:582] [14/50] Score: -0.644742 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:09:19.8361 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:19.8361 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:19.8411 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:19.9495 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.575853
[INFO 23-08-16 11:09:19.9496 UTC gradient_boosted_trees.cc:247] Truncates the model to 75 tree(s) i.e. 75 iteration(s).
[INFO 23-08-16 11:09:19.9511 UTC gradient_boosted_trees.cc:310] Final model num-trees:75 valid-loss:0.575853 valid-accuracy:0.868083
[INFO 23-08-16 11:09:19.9560 UTC hyperparameters_optimizer.cc:582] [15/50] Score: -0.575853 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 3 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:09:19.9631 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:19.9631 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:19.9678 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:20.0111 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.034381 train-accuracy:0.761895 valid-loss:1.090479 valid-accuracy:0.736609
[INFO 23-08-16 11:09:20.1262 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.084782 train-accuracy:0.761895 valid-loss:1.143113 valid-accuracy:0.736609
[INFO 23-08-16 11:09:24.1281 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.634505
[INFO 23-08-16 11:09:24.1282 UTC gradient_boosted_trees.cc:247] Truncates the model to 91 tree(s) i.e. 91 iteration(s).
[INFO 23-08-16 11:09:24.1289 UTC gradient_boosted_trees.cc:310] Final model num-trees:91 valid-loss:0.634505 valid-accuracy:0.852147
[INFO 23-08-16 11:09:24.1312 UTC hyperparameters_optimizer.cc:582] [16/50] Score: -0.634505 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:09:24.1345 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:24.1346 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:24.1391 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:24.4314 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.078871 train-accuracy:0.761895 valid-loss:1.137038 valid-accuracy:0.736609
[INFO 23-08-16 11:09:27.6264 UTC gradient_boosted_trees.cc:1544] num-trees:110 train-loss:0.590722 train-accuracy:0.866848 valid-loss:0.629717 valid-accuracy:0.856131
[INFO 23-08-16 11:09:29.2415 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.511615 train-accuracy:0.890712 valid-loss:0.592446 valid-accuracy:0.867641
[INFO 23-08-16 11:09:29.2416 UTC gradient_boosted_trees.cc:247] Truncates the model to 289 tree(s) i.e. 289 iteration(s).
[INFO 23-08-16 11:09:29.2420 UTC gradient_boosted_trees.cc:310] Final model num-trees:289 valid-loss:0.592294 valid-accuracy:0.867641
[INFO 23-08-16 11:09:29.2483 UTC hyperparameters_optimizer.cc:582] [17/50] Score: -0.592294 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 1 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.6 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:09:29.2589 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:29.2589 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:29.2645 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:29.6504 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.059373 train-accuracy:0.761895 valid-loss:1.116517 valid-accuracy:0.736609
[INFO 23-08-16 11:09:30.1993 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.530666 train-accuracy:0.884235 valid-loss:0.586935 valid-accuracy:0.869411
[INFO 23-08-16 11:09:30.1994 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:09:30.1994 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.586935 valid-accuracy:0.869411
[INFO 23-08-16 11:09:30.2058 UTC hyperparameters_optimizer.cc:582] [18/50] Score: -0.586935 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "AXIS_ALIGNED" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 6 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:09:30.2064 UTC gradient_boosted_trees.cc:459] Default loss set to BINOMIAL_LOG_LIKELIHOOD
[INFO 23-08-16 11:09:30.2064 UTC gradient_boosted_trees.cc:1085] Training gradient boosted tree on 22792 example(s) and 14 feature(s).
[INFO 23-08-16 11:09:30.2130 UTC gradient_boosted_trees.cc:1128] 20533 examples used for training and 2259 examples used for validation
[INFO 23-08-16 11:09:30.4667 UTC gradient_boosted_trees.cc:1542] num-trees:1 train-loss:1.055494 train-accuracy:0.761895 valid-loss:1.112262 valid-accuracy:0.736609
[INFO 23-08-16 11:09:39.1713 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.57462
[INFO 23-08-16 11:09:39.1713 UTC gradient_boosted_trees.cc:247] Truncates the model to 68 tree(s) i.e. 68 iteration(s).
[INFO 23-08-16 11:09:39.1726 UTC gradient_boosted_trees.cc:310] Final model num-trees:68 valid-loss:0.574620 valid-accuracy:0.869411
[INFO 23-08-16 11:09:39.1758 UTC hyperparameters_optimizer.cc:582] [19/50] Score: -0.57462 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 2 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 64 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:09:42.3542 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.534859 train-accuracy:0.880047 valid-loss:0.592023 valid-accuracy:0.870297
[INFO 23-08-16 11:09:42.3542 UTC gradient_boosted_trees.cc:247] Truncates the model to 297 tree(s) i.e. 297 iteration(s).
[INFO 23-08-16 11:09:42.3543 UTC gradient_boosted_trees.cc:310] Final model num-trees:297 valid-loss:0.591875 valid-accuracy:0.871182
[INFO 23-08-16 11:09:42.3557 UTC hyperparameters_optimizer.cc:582] [20/50] Score: -0.591875 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 4 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:09:45.1013 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.575868
[INFO 23-08-16 11:09:45.1013 UTC gradient_boosted_trees.cc:247] Truncates the model to 156 tree(s) i.e. 156 iteration(s).
[INFO 23-08-16 11:09:45.1024 UTC gradient_boosted_trees.cc:310] Final model num-trees:156 valid-loss:0.575868 valid-accuracy:0.870297
[INFO 23-08-16 11:09:45.1083 UTC hyperparameters_optimizer.cc:582] [21/50] Score: -0.575868 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 256 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:09:45.5594 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.585791
[INFO 23-08-16 11:09:45.5594 UTC gradient_boosted_trees.cc:247] Truncates the model to 158 tree(s) i.e. 158 iteration(s).
[INFO 23-08-16 11:09:45.5602 UTC gradient_boosted_trees.cc:310] Final model num-trees:158 valid-loss:0.585791 valid-accuracy:0.869854
[INFO 23-08-16 11:09:45.5651 UTC hyperparameters_optimizer.cc:582] [22/50] Score: -0.585791 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 3 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 256 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:09:48.8690 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.575102
[INFO 23-08-16 11:09:48.8690 UTC gradient_boosted_trees.cc:247] Truncates the model to 182 tree(s) i.e. 182 iteration(s).
[INFO 23-08-16 11:09:48.8694 UTC gradient_boosted_trees.cc:310] Final model num-trees:182 valid-loss:0.575102 valid-accuracy:0.870739
[INFO 23-08-16 11:09:48.8715 UTC hyperparameters_optimizer.cc:582] [23/50] Score: -0.575102 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 2 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:09:49.2709 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.522460 train-accuracy:0.884040 valid-loss:0.588174 valid-accuracy:0.871625
[INFO 23-08-16 11:09:49.2709 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:09:49.2709 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.588174 valid-accuracy:0.871625
[INFO 23-08-16 11:09:49.2758 UTC hyperparameters_optimizer.cc:582] [24/50] Score: -0.588174 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 1 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 6 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:09:52.4145 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.549486 train-accuracy:0.876881 valid-loss:0.608020 valid-accuracy:0.867198
[INFO 23-08-16 11:09:52.4145 UTC gradient_boosted_trees.cc:247] Truncates the model to 296 tree(s) i.e. 296 iteration(s).
[INFO 23-08-16 11:09:52.4146 UTC gradient_boosted_trees.cc:310] Final model num-trees:296 valid-loss:0.607491 valid-accuracy:0.867198
[INFO 23-08-16 11:09:52.4154 UTC hyperparameters_optimizer.cc:582] [25/50] Score: -0.607491 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:09:52.6914 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.547628 train-accuracy:0.878001 valid-loss:0.597969 valid-accuracy:0.867198
[INFO 23-08-16 11:09:52.6914 UTC gradient_boosted_trees.cc:247] Truncates the model to 296 tree(s) i.e. 296 iteration(s).
[INFO 23-08-16 11:09:52.6915 UTC gradient_boosted_trees.cc:310] Final model num-trees:296 valid-loss:0.597909 valid-accuracy:0.867641
[INFO 23-08-16 11:09:52.6923 UTC hyperparameters_optimizer.cc:582] [26/50] Score: -0.597909 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 3 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:09:57.1849 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.465381 train-accuracy:0.898115 valid-loss:0.597106 valid-accuracy:0.864542
[INFO 23-08-16 11:09:57.1850 UTC gradient_boosted_trees.cc:247] Truncates the model to 292 tree(s) i.e. 292 iteration(s).
[INFO 23-08-16 11:09:57.1853 UTC gradient_boosted_trees.cc:310] Final model num-trees:292 valid-loss:0.596803 valid-accuracy:0.864985
[INFO 23-08-16 11:09:57.1977 UTC hyperparameters_optimizer.cc:582] [27/50] Score: -0.596803 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 3 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.6 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:09:57.6505 UTC gradient_boosted_trees.cc:1544] num-trees:199 train-loss:0.489932 train-accuracy:0.891833 valid-loss:0.590156 valid-accuracy:0.865427
[INFO 23-08-16 11:10:00.7773 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.626160 train-accuracy:0.856962 valid-loss:0.657957 valid-accuracy:0.841080
[INFO 23-08-16 11:10:00.7773 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:10:00.7773 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.657957 valid-accuracy:0.841080
[INFO 23-08-16 11:10:00.7779 UTC hyperparameters_optimizer.cc:582] [28/50] Score: -0.657957 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:10:01.8466 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.582612
[INFO 23-08-16 11:10:01.8467 UTC gradient_boosted_trees.cc:247] Truncates the model to 119 tree(s) i.e. 119 iteration(s).
[INFO 23-08-16 11:10:01.8472 UTC gradient_boosted_trees.cc:310] Final model num-trees:119 valid-loss:0.582612 valid-accuracy:0.865870
[INFO 23-08-16 11:10:01.8493 UTC hyperparameters_optimizer.cc:582] [29/50] Score: -0.582612 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 2 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:10:02.3571 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.493647 train-accuracy:0.890761 valid-loss:0.580171 valid-accuracy:0.870297
[INFO 23-08-16 11:10:02.3571 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:10:02.3572 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.580171 valid-accuracy:0.870297
[INFO 23-08-16 11:10:02.3632 UTC hyperparameters_optimizer.cc:582] [30/50] Score: -0.580171 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 2 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 128 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:10:05.8787 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.580436
[INFO 23-08-16 11:10:05.8788 UTC gradient_boosted_trees.cc:247] Truncates the model to 87 tree(s) i.e. 87 iteration(s).
[INFO 23-08-16 11:10:05.8794 UTC gradient_boosted_trees.cc:310] Final model num-trees:87 valid-loss:0.580436 valid-accuracy:0.861443
[INFO 23-08-16 11:10:05.8818 UTC hyperparameters_optimizer.cc:582] [31/50] Score: -0.580436 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 64 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:10:07.7309 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.552857 train-accuracy:0.875225 valid-loss:0.611411 valid-accuracy:0.861443
[INFO 23-08-16 11:10:07.7309 UTC gradient_boosted_trees.cc:247] Truncates the model to 299 tree(s) i.e. 299 iteration(s).
[INFO 23-08-16 11:10:07.7309 UTC gradient_boosted_trees.cc:310] Final model num-trees:299 valid-loss:0.611399 valid-accuracy:0.861443
[INFO 23-08-16 11:10:07.7315 UTC hyperparameters_optimizer.cc:582] [32/50] Score: -0.611399 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 3 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:10:10.5852 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.593538
[INFO 23-08-16 11:10:10.5853 UTC gradient_boosted_trees.cc:247] Truncates the model to 215 tree(s) i.e. 215 iteration(s).
[INFO 23-08-16 11:10:10.5859 UTC gradient_boosted_trees.cc:310] Final model num-trees:215 valid-loss:0.593538 valid-accuracy:0.860558
[INFO 23-08-16 11:10:10.5908 UTC hyperparameters_optimizer.cc:582] [33/50] Score: -0.593538 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 512 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:10:12.5319 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.623461
[INFO 23-08-16 11:10:12.5320 UTC gradient_boosted_trees.cc:247] Truncates the model to 126 tree(s) i.e. 126 iteration(s).
[INFO 23-08-16 11:10:12.5323 UTC gradient_boosted_trees.cc:310] Final model num-trees:126 valid-loss:0.623461 valid-accuracy:0.852147
[INFO 23-08-16 11:10:12.5342 UTC hyperparameters_optimizer.cc:582] [34/50] Score: -0.623461 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.1 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:10:13.0852 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.642896
[INFO 23-08-16 11:10:13.0853 UTC gradient_boosted_trees.cc:247] Truncates the model to 143 tree(s) i.e. 143 iteration(s).
[INFO 23-08-16 11:10:13.0859 UTC gradient_boosted_trees.cc:310] Final model num-trees:143 valid-loss:0.642896 valid-accuracy:0.849048
[INFO 23-08-16 11:10:13.0893 UTC hyperparameters_optimizer.cc:582] [35/50] Score: -0.642896 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 512 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.6 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:10:13.7497 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.514136 train-accuracy:0.886719 valid-loss:0.582222 valid-accuracy:0.868969
[INFO 23-08-16 11:10:13.7498 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:10:13.7498 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.582222 valid-accuracy:0.868969
[INFO 23-08-16 11:10:13.7551 UTC hyperparameters_optimizer.cc:582] [36/50] Score: -0.582222 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 256 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:10:14.7675 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.625355
[INFO 23-08-16 11:10:14.7676 UTC gradient_boosted_trees.cc:247] Truncates the model to 182 tree(s) i.e. 182 iteration(s).
[INFO 23-08-16 11:10:14.7683 UTC gradient_boosted_trees.cc:310] Final model num-trees:182 valid-loss:0.625355 valid-accuracy:0.853032
[INFO 23-08-16 11:10:14.7741 UTC hyperparameters_optimizer.cc:582] [37/50] Score: -0.625355 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:10:14.9745 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.500521 train-accuracy:0.890128 valid-loss:0.587961 valid-accuracy:0.861886
[INFO 23-08-16 11:10:14.9745 UTC gradient_boosted_trees.cc:247] Truncates the model to 299 tree(s) i.e. 299 iteration(s).
[INFO 23-08-16 11:10:14.9745 UTC gradient_boosted_trees.cc:310] Final model num-trees:299 valid-loss:0.587948 valid-accuracy:0.861886
[INFO 23-08-16 11:10:14.9808 UTC hyperparameters_optimizer.cc:582] [38/50] Score: -0.587948 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 2 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 256 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:10:24.0655 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.481010 train-accuracy:0.894414 valid-loss:0.628041 valid-accuracy:0.853475
[INFO 23-08-16 11:10:24.0655 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:10:24.0656 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.628041 valid-accuracy:0.853475
[INFO 23-08-16 11:10:24.0721 UTC hyperparameters_optimizer.cc:582] [39/50] Score: -0.628041 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 64 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:10:27.6515 UTC gradient_boosted_trees.cc:1544] num-trees:281 train-loss:0.528716 train-accuracy:0.881995 valid-loss:0.589776 valid-accuracy:0.867641
[INFO 23-08-16 11:10:30.0631 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.492458 train-accuracy:0.890469 valid-loss:0.577581 valid-accuracy:0.868083
[INFO 23-08-16 11:10:30.0631 UTC gradient_boosted_trees.cc:247] Truncates the model to 287 tree(s) i.e. 287 iteration(s).
[INFO 23-08-16 11:10:30.0632 UTC gradient_boosted_trees.cc:310] Final model num-trees:287 valid-loss:0.576924 valid-accuracy:0.868969
[INFO 23-08-16 11:10:30.0655 UTC hyperparameters_optimizer.cc:582] [40/50] Score: -0.576924 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 1 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.9 } }
[INFO 23-08-16 11:10:32.0797 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.435926 train-accuracy:0.912775 valid-loss:0.599424 valid-accuracy:0.863656
[INFO 23-08-16 11:10:32.0797 UTC gradient_boosted_trees.cc:247] Truncates the model to 299 tree(s) i.e. 299 iteration(s).
[INFO 23-08-16 11:10:32.0798 UTC gradient_boosted_trees.cc:310] Final model num-trees:299 valid-loss:0.599401 valid-accuracy:0.863656
[INFO 23-08-16 11:10:32.0900 UTC hyperparameters_optimizer.cc:582] [41/50] Score: -0.599401 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 3 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.6 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:10:32.3847 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.523727 train-accuracy:0.883456 valid-loss:0.587662 valid-accuracy:0.867198
[INFO 23-08-16 11:10:32.3848 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:10:32.3848 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.587662 valid-accuracy:0.867198
[INFO 23-08-16 11:10:32.3886 UTC hyperparameters_optimizer.cc:582] [42/50] Score: -0.587662 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 6 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:10:33.0908 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.448174 train-accuracy:0.901719 valid-loss:0.584032 valid-accuracy:0.870297
[INFO 23-08-16 11:10:33.0908 UTC gradient_boosted_trees.cc:247] Truncates the model to 283 tree(s) i.e. 283 iteration(s).
[INFO 23-08-16 11:10:33.0914 UTC gradient_boosted_trees.cc:310] Final model num-trees:283 valid-loss:0.583289 valid-accuracy:0.870297
[INFO 23-08-16 11:10:33.1016 UTC hyperparameters_optimizer.cc:582] [43/50] Score: -0.583289 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 2 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:10:34.3194 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.636921
[INFO 23-08-16 11:10:34.3195 UTC gradient_boosted_trees.cc:247] Truncates the model to 181 tree(s) i.e. 181 iteration(s).
[INFO 23-08-16 11:10:34.3200 UTC gradient_boosted_trees.cc:310] Final model num-trees:181 valid-loss:0.636921 valid-accuracy:0.853032
[INFO 23-08-16 11:10:34.3236 UTC hyperparameters_optimizer.cc:582] [44/50] Score: -0.636921 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 64 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:10:36.1570 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.435564 train-accuracy:0.914236 valid-loss:0.600726 valid-accuracy:0.862771
[INFO 23-08-16 11:10:36.1571 UTC gradient_boosted_trees.cc:247] Truncates the model to 299 tree(s) i.e. 299 iteration(s).
[INFO 23-08-16 11:10:36.1571 UTC gradient_boosted_trees.cc:310] Final model num-trees:299 valid-loss:0.600701 valid-accuracy:0.862328
[INFO 23-08-16 11:10:36.1679 UTC hyperparameters_optimizer.cc:582] [45/50] Score: -0.600701 / -0.574235 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.5 } }
[INFO 23-08-16 11:10:37.1114 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.456672 train-accuracy:0.898067 valid-loss:0.573701 valid-accuracy:0.867641
[INFO 23-08-16 11:10:37.1115 UTC gradient_boosted_trees.cc:247] Truncates the model to 284 tree(s) i.e. 284 iteration(s).
[INFO 23-08-16 11:10:37.1120 UTC gradient_boosted_trees.cc:310] Final model num-trees:284 valid-loss:0.573333 valid-accuracy:0.867198
[INFO 23-08-16 11:10:37.1261 UTC hyperparameters_optimizer.cc:582] [46/50] Score: -0.573333 / -0.573333 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "LOCAL" } } fields { name: "max_depth" value { integer: 8 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 5 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:10:41.5204 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.562199 train-accuracy:0.873326 valid-loss:0.617909 valid-accuracy:0.855246
[INFO 23-08-16 11:10:41.5204 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:10:41.5205 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.617909 valid-accuracy:0.855246
[INFO 23-08-16 11:10:41.5229 UTC hyperparameters_optimizer.cc:582] [47/50] Score: -0.617909 / -0.573333 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 4 } } fields { name: "sparse_oblique_normalization" value { categorical: "MIN_MAX" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.9 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 0.2 } }
[INFO 23-08-16 11:10:50.2502 UTC early_stopping.cc:53] Early stop of the training because the validation loss does not decrease anymore. Best valid-loss: 0.575538
[INFO 23-08-16 11:10:50.2503 UTC gradient_boosted_trees.cc:247] Truncates the model to 193 tree(s) i.e. 193 iteration(s).
[INFO 23-08-16 11:10:50.2507 UTC gradient_boosted_trees.cc:310] Final model num-trees:193 valid-loss:0.575538 valid-accuracy:0.866313
[INFO 23-08-16 11:10:50.2539 UTC hyperparameters_optimizer.cc:582] [48/50] Score: -0.575538 / -0.573333 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "BINARY" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 32 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 7 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:10:57.7539 UTC gradient_boosted_trees.cc:1544] num-trees:275 train-loss:0.494402 train-accuracy:0.890907 valid-loss:0.583064 valid-accuracy:0.868083
[INFO 23-08-16 11:11:00.3725 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.490348 train-accuracy:0.894998 valid-loss:0.577486 valid-accuracy:0.872510
[INFO 23-08-16 11:11:00.3726 UTC gradient_boosted_trees.cc:247] Truncates the model to 300 tree(s) i.e. 300 iteration(s).
[INFO 23-08-16 11:11:00.3726 UTC gradient_boosted_trees.cc:310] Final model num-trees:300 valid-loss:0.577486 valid-accuracy:0.872510
[INFO 23-08-16 11:11:00.3779 UTC hyperparameters_optimizer.cc:582] [49/50] Score: -0.577486 / -0.573333 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 5 } } fields { name: "sparse_oblique_normalization" value { categorical: "NONE" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "RANDOM" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 256 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 0.8 } } fields { name: "shrinkage" value { real: 0.02 } } fields { name: "min_examples" value { integer: 20 } } fields { name: "use_hessian_gain" value { categorical: "false" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:11:04.5224 UTC gradient_boosted_trees.cc:1542] num-trees:300 train-loss:0.487159 train-accuracy:0.892320 valid-loss:0.581956 valid-accuracy:0.868083
[INFO 23-08-16 11:11:04.5224 UTC gradient_boosted_trees.cc:247] Truncates the model to 299 tree(s) i.e. 299 iteration(s).
[INFO 23-08-16 11:11:04.5225 UTC gradient_boosted_trees.cc:310] Final model num-trees:299 valid-loss:0.581786 valid-accuracy:0.868083
[INFO 23-08-16 11:11:04.5248 UTC hyperparameters_optimizer.cc:582] [50/50] Score: -0.581786 / -0.573333 HParams: fields { name: "split_axis" value { categorical: "SPARSE_OBLIQUE" } } fields { name: "sparse_oblique_projection_density_factor" value { real: 3 } } fields { name: "sparse_oblique_normalization" value { categorical: "STANDARD_DEVIATION" } } fields { name: "sparse_oblique_weights" value { categorical: "CONTINUOUS" } } fields { name: "categorical_algorithm" value { categorical: "CART" } } fields { name: "growing_strategy" value { categorical: "BEST_FIRST_GLOBAL" } } fields { name: "max_num_nodes" value { integer: 16 } } fields { name: "sampling_method" value { categorical: "RANDOM" } } fields { name: "subsample" value { real: 1 } } fields { name: "shrinkage" value { real: 0.05 } } fields { name: "min_examples" value { integer: 10 } } fields { name: "use_hessian_gain" value { categorical: "true" } } fields { name: "num_candidate_attributes_ratio" value { real: 1 } }
[INFO 23-08-16 11:11:04.5502 UTC hyperparameters_optimizer.cc:219] Best hyperparameters:
fields {
name: "split_axis"
value {
categorical: "SPARSE_OBLIQUE"
}
}
fields {
name: "sparse_oblique_projection_density_factor"
value {
real: 4
}
}
fields {
name: "sparse_oblique_normalization"
value {
categorical: "NONE"
}
}
fields {
name: "sparse_oblique_weights"
value {
categorical: "CONTINUOUS"
}
}
fields {
name: "categorical_algorithm"
value {
categorical: "CART"
}
}
fields {
name: "growing_strategy"
value {
categorical: "LOCAL"
}
}
fields {
name: "max_depth"
value {
integer: 8
}
}
fields {
name: "sampling_method"
value {
categorical: "RANDOM"
}
}
fields {
name: "subsample"
value {
real: 0.9
}
}
fields {
name: "shrinkage"
value {
real: 0.02
}
}
fields {
name: "min_examples"
value {
integer: 5
}
}
fields {
name: "use_hessian_gain"
value {
categorical: "true"
}
}
fields {
name: "num_candidate_attributes_ratio"
value {
real: 0.2
}
}
[INFO 23-08-16 11:11:04.5509 UTC kernel.cc:926] Export model in log directory: /tmpfs/tmp/tmpfhjg70bi with prefix 2362b151e27349f1
[INFO 23-08-16 11:11:04.5900 UTC kernel.cc:944] Save model in resources
[INFO 23-08-16 11:11:04.5945 UTC abstract_model.cc:849] Model self evaluation:
Task: CLASSIFICATION
Label: __LABEL
Loss (BINOMIAL_LOG_LIKELIHOOD): 0.573333
Accuracy: 0.867198 CI95[W][0 1]
ErrorRate: : 0.132802
Confusion Table:
truth\prediction
0 1 2
0 0 0 0
1 0 1578 86
2 0 214 381
Total: 2259
One vs other classes:
[INFO 23-08-16 11:11:04.6200 UTC kernel.cc:1243] Loading model from path /tmpfs/tmp/tmpfhjg70bi/model/ with prefix 2362b151e27349f1
[INFO 23-08-16 11:11:04.7821 UTC decision_forest.cc:660] Model loaded with 284 root(s), 48262 node(s), and 14 input feature(s).
[INFO 23-08-16 11:11:04.7822 UTC abstract_model.cc:1311] Engine "GradientBoostedTreesGeneric" built
[INFO 23-08-16 11:11:04.7822 UTC kernel.cc:1075] Use fast generic engine
Model trained in 0:02:38.504656
Compiling model...
Model compiled.
CPU times: user 57min 43s, sys: 1.03 s, total: 57min 44s
Wall time: 2min 39s
<keras.src.callbacks.History at 0x7f240c3141c0>
# 评估模型
tuned_model.compile(["accuracy"]) # 编译模型,使用"accuracy"作为评估指标
# 使用测试数据集评估调整后的模型
tuned_test_accuracy = tuned_model.evaluate(test_ds, return_dict=True, verbose=0)["accuracy"]
# 打印使用TF-DF超参数调整器得到的测试准确率
print(f"Test accuracy with the TF-DF hyper-parameter tuner: {tuned_test_accuracy:.4f}")
Test accuracy with the TF-DF hyper-parameter tuner: 0.8741
同之前一样,显示调优日志。
# 显示调优日志。
# 调用tuned_model对象的make_inspector()方法,返回一个Inspector对象,然后调用其tuning_logs()方法,返回调优日志。
tuning_logs = tuned_model.make_inspector().tuning_logs()
# 调用tuning_logs对象的head()方法,显示调优日志的前几行。
tuning_logs.head()
| score | evaluation_time | best | split_axis | sparse_oblique_projection_density_factor | sparse_oblique_normalization | sparse_oblique_weights | categorical_algorithm | growing_strategy | max_num_nodes | sampling_method | subsample | shrinkage | min_examples | use_hessian_gain | num_candidate_attributes_ratio | max_depth | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.621505 | 33.595553 | False | SPARSE_OBLIQUE | 5.0 | STANDARD_DEVIATION | CONTINUOUS | RANDOM | BEST_FIRST_GLOBAL | 32.0 | RANDOM | 0.6 | 0.10 | 5 | true | 1.0 | NaN |
| 1 | -0.587795 | 34.275111 | False | SPARSE_OBLIQUE | 1.0 | MIN_MAX | BINARY | CART | BEST_FIRST_GLOBAL | 16.0 | RANDOM | 0.6 | 0.10 | 10 | true | 0.2 | NaN |
| 2 | -0.592873 | 36.837887 | False | SPARSE_OBLIQUE | 2.0 | NONE | BINARY | RANDOM | LOCAL | NaN | RANDOM | 0.6 | 0.05 | 20 | false | 1.0 | 4.0 |
| 3 | -0.579144 | 37.724828 | False | SPARSE_OBLIQUE | 1.0 | MIN_MAX | CONTINUOUS | CART | BEST_FIRST_GLOBAL | 512.0 | RANDOM | 1.0 | 0.10 | 5 | false | 0.5 | NaN |
| 4 | -0.604322 | 41.189555 | False | SPARSE_OBLIQUE | 4.0 | STANDARD_DEVIATION | CONTINUOUS | CART | LOCAL | NaN | RANDOM | 0.8 | 0.10 | 5 | false | 0.5 | 6.0 |
同之前一样,显示最佳超参数。
# 从tuning_logs中选择最佳的超参数
tuning_logs[tuning_logs.best].iloc[0]
score -0.573333
evaluation_time 130.817537
best True
split_axis SPARSE_OBLIQUE
sparse_oblique_projection_density_factor 4.0
sparse_oblique_normalization NONE
sparse_oblique_weights CONTINUOUS
categorical_algorithm CART
growing_strategy LOCAL
max_num_nodes NaN
sampling_method RANDOM
subsample 0.9
shrinkage 0.02
min_examples 5
use_hessian_gain true
num_candidate_attributes_ratio 0.2
max_depth 8.0
Name: 45, dtype: object
最后,绘制模型在调整过程中的质量演变情况:
# 设置图形的大小为10x5
plt.figure(figsize=(10, 5))
# 绘制当前试验的得分曲线
plt.plot(tuning_logs["score"], label="current trial")
# 绘制历史最佳试验的得分曲线
plt.plot(tuning_logs["score"].cummax(), label="best trial")
# 设置x轴标签为"调参步骤"
plt.xlabel("Tuning step")
# 设置y轴标签为"调参得分"
plt.ylabel("Tuning score")
# 添加图例
plt.legend()
# 显示图形
plt.show()
使用Keras Tuner训练模型 (替代方法)
TensorFlow Decision Forests基于Keras框架,与Keras tuner兼容。
目前,TF-DF Tuner和Keras Tuner是互补的。
TF-DF Tuner
- 自动配置目标。
- 自动提取验证数据集(如果需要)。
- 支持模型自我评估(例如,out-of-bag评估)。
- 分布式超参数调整。
- 试验之间共享数据集访问:TensorFlow数据集只读取一次,在小数据集上显著加速调整。
Keras Tuner
- 支持调整预处理参数。
- 支持超带优化器。
- 支持自定义目标。
让我们使用Keras tuner来调整TF-DF模型。
# 安装Keras调参器
!pip install keras-tuner -U -qq
# 导入Keras调参器
import keras_tuner as kt
%%time
# 定义一个构建模型的函数,接受一个hp参数
def build_model(hp):
"""创建一个模型。"""
# 使用tfdf.keras.GradientBoostedTreesModel创建一个梯度提升树模型
# 设置模型的各种参数,如最小样本数、分类算法、最大深度、是否使用hessian增益、学习率等
model = tfdf.keras.GradientBoostedTreesModel(
min_examples=hp.Choice("min_examples", [2, 5, 7, 10]),
categorical_algorithm=hp.Choice("categorical_algorithm", ["CART", "RANDOM"]),
max_depth=hp.Choice("max_depth", [4, 5, 6, 7]),
# The keras tuner convert automaticall boolean parameters to integers.
use_hessian_gain=bool(hp.Choice("use_hessian_gain", [True, False])),
shrinkage=hp.Choice("shrinkage", [0.02, 0.05, 0.10, 0.15]),
num_candidate_attributes_ratio=hp.Choice("num_candidate_attributes_ratio", [0.2, 0.5, 0.9, 1.0]),
)
# 编译模型,设置评估指标为准确率
model.compile(metrics=["accuracy"])
return model
# 创建一个随机搜索对象,传入构建模型的函数、优化目标、最大尝试次数、保存路径等参数
keras_tuner = kt.RandomSearch(
build_model,
objective="val_accuracy",
max_trials=50,
overwrite=True,
directory="/tmp/keras_tuning")
# 重要提示:调参不应该在测试数据集上进行。
# 从训练数据集中提取一个验证数据集,新的训练数据集称为“子训练数据集”。
# 定义一个函数,用于将panda dataframe分割成两部分
def split_dataset(dataset, test_ratio=0.30):
"""将panda dataframe分割成两部分。"""
# 随机选择一部分数据作为测试数据集
test_indices = np.random.rand(len(dataset)) < test_ratio
# 返回分割后的训练数据集和测试数据集
return dataset[~test_indices], dataset[test_indices]
# 将训练数据集分割成子训练数据集和子验证数据集
sub_train_df, sub_valid_df = split_dataset(train_df)
# 将子训练数据集转换为tf数据集,设置标签为"income"
sub_train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(sub_train_df, label="income")
# 将子验证数据集转换为tf数据集,设置标签为"income"
sub_valid_ds = tfdf.keras.pd_dataframe_to_tf_dataset(sub_valid_df, label="income")
# 开始调参
keras_tuner.search(sub_train_ds, validation_data=sub_valid_ds)
Trial 50 Complete [00h 00m 09s]
val_accuracy: 0.8768961429595947
Best val_accuracy So Far: 0.8815636038780212
Total elapsed time: 00h 03m 58s
INFO:tensorflow:Oracle triggered exit
INFO:tensorflow:Oracle triggered exit
CPU times: user 6min 39s, sys: 1min 8s, total: 7min 47s
Wall time: 3min 57s
最佳超参数可以通过get_best_hyperparameters获得:
# 获取最佳超参数
best_hyper_parameters = keras_tuner.get_best_hyperparameters()[0].values
# 打印最佳超参数
print("最佳超参数:", keras_tuner.get_best_hyperparameters()[0].values)
Best hyper-parameters: {'min_examples': 10, 'categorical_algorithm': 'CART', 'max_depth': 6, 'use_hessian_gain': 1, 'shrinkage': 0.1, 'num_candidate_attributes_ratio': 0.9}
模型应该使用最佳超参数进行重新训练:
# 训练模型
# 在训练模型之前,我们需要设置单元格的高度为300,以便在显示模型训练过程中的输出时,能够完整显示所有内容。
%set_cell_height 300
# 训练模型
# Keras Tuner会自动将布尔参数转换为整数。
# 在这里,我们将best_hyper_parameters字典中的"use_hessian_gain"参数的值转换为布尔类型。
best_hyper_parameters["use_hessian_gain"] = bool(best_hyper_parameters["use_hessian_gain"])
# 创建一个GradientBoostedTreesModel对象,使用best_hyper_parameters中的参数
best_model = tfdf.keras.GradientBoostedTreesModel(**best_hyper_parameters)
# 使用训练数据集train_ds来训练模型
# verbose=2表示输出详细的训练过程信息
best_model.fit(train_ds, verbose=2)
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpewzhl309 as temporary training directory
Reading training dataset...
Training tensor examples:
Features: {'age': <tf.Tensor 'data:0' shape=(None,) dtype=int64>, 'workclass': <tf.Tensor 'data_1:0' shape=(None,) dtype=string>, 'fnlwgt': <tf.Tensor 'data_2:0' shape=(None,) dtype=int64>, 'education': <tf.Tensor 'data_3:0' shape=(None,) dtype=string>, 'education_num': <tf.Tensor 'data_4:0' shape=(None,) dtype=int64>, 'marital_status': <tf.Tensor 'data_5:0' shape=(None,) dtype=string>, 'occupation': <tf.Tensor 'data_6:0' shape=(None,) dtype=string>, 'relationship': <tf.Tensor 'data_7:0' shape=(None,) dtype=string>, 'race': <tf.Tensor 'data_8:0' shape=(None,) dtype=string>, 'sex': <tf.Tensor 'data_9:0' shape=(None,) dtype=string>, 'capital_gain': <tf.Tensor 'data_10:0' shape=(None,) dtype=int64>, 'capital_loss': <tf.Tensor 'data_11:0' shape=(None,) dtype=int64>, 'hours_per_week': <tf.Tensor 'data_12:0' shape=(None,) dtype=int64>, 'native_country': <tf.Tensor 'data_13:0' shape=(None,) dtype=string>}
Label: Tensor("data_14:0", shape=(None,), dtype=int64)
Weights: None
Normalized tensor features:
{'age': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast:0' shape=(None,) dtype=float32>), 'workclass': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_1:0' shape=(None,) dtype=string>), 'fnlwgt': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_1:0' shape=(None,) dtype=float32>), 'education': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_3:0' shape=(None,) dtype=string>), 'education_num': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_2:0' shape=(None,) dtype=float32>), 'marital_status': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_5:0' shape=(None,) dtype=string>), 'occupation': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_6:0' shape=(None,) dtype=string>), 'relationship': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_7:0' shape=(None,) dtype=string>), 'race': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_8:0' shape=(None,) dtype=string>), 'sex': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_9:0' shape=(None,) dtype=string>), 'capital_gain': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_3:0' shape=(None,) dtype=float32>), 'capital_loss': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_4:0' shape=(None,) dtype=float32>), 'hours_per_week': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_5:0' shape=(None,) dtype=float32>), 'native_country': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_13:0' shape=(None,) dtype=string>)}
[WARNING 23-08-16 11:15:06.4338 UTC gradient_boosted_trees.cc:1818] "goss_alpha" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:15:06.4338 UTC gradient_boosted_trees.cc:1829] "goss_beta" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:15:06.4338 UTC gradient_boosted_trees.cc:1843] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB".
Training dataset read in 0:00:00.389690. Found 22792 examples.
Training model...
[INFO 23-08-16 11:15:06.8353 UTC kernel.cc:773] Start Yggdrasil model training
[INFO 23-08-16 11:15:06.8353 UTC kernel.cc:774] Collect training examples
[INFO 23-08-16 11:15:06.8354 UTC kernel.cc:787] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
categorial {
min_vocab_frequency: 0
max_vocab_count: -1
}
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
[INFO 23-08-16 11:15:06.8355 UTC kernel.cc:393] Number of batches: 23
[INFO 23-08-16 11:15:06.8355 UTC kernel.cc:394] Number of examples: 22792
[INFO 23-08-16 11:15:06.8429 UTC data_spec_inference.cc:305] 1 item(s) have been pruned (i.e. they are considered out of dictionary) for the column native_country (40 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 23-08-16 11:15:06.8429 UTC data_spec_inference.cc:305] 1 item(s) have been pruned (i.e. they are considered out of dictionary) for the column occupation (13 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 23-08-16 11:15:06.8430 UTC data_spec_inference.cc:305] 1 item(s) have been pruned (i.e. they are considered out of dictionary) for the column workclass (7 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 23-08-16 11:15:06.8491 UTC kernel.cc:794] Training dataset:
Number of records: 22792
Number of columns: 15
Number of columns by type:
CATEGORICAL: 9 (60%)
NUMERICAL: 6 (40%)
Columns:
CATEGORICAL: 9 (60%)
0: "__LABEL" CATEGORICAL integerized vocab-size:3 no-ood-item
4: "education" CATEGORICAL has-dict vocab-size:17 zero-ood-items most-frequent:"HS-grad" 7340 (32.2043%)
8: "marital_status" CATEGORICAL has-dict vocab-size:8 zero-ood-items most-frequent:"Married-civ-spouse" 10431 (45.7661%)
9: "native_country" CATEGORICAL num-nas:407 (1.78571%) has-dict vocab-size:41 num-oods:1 (0.00446728%) most-frequent:"United-States" 20436 (91.2933%)
10: "occupation" CATEGORICAL num-nas:1260 (5.52826%) has-dict vocab-size:14 num-oods:1 (0.00464425%) most-frequent:"Prof-specialty" 2870 (13.329%)
11: "race" CATEGORICAL has-dict vocab-size:6 zero-ood-items most-frequent:"White" 19467 (85.4115%)
12: "relationship" CATEGORICAL has-dict vocab-size:7 zero-ood-items most-frequent:"Husband" 9191 (40.3256%)
13: "sex" CATEGORICAL has-dict vocab-size:3 zero-ood-items most-frequent:"Male" 15165 (66.5365%)
14: "workclass" CATEGORICAL num-nas:1257 (5.51509%) has-dict vocab-size:8 num-oods:1 (0.0046436%) most-frequent:"Private" 15879 (73.7358%)
NUMERICAL: 6 (40%)
1: "age" NUMERICAL mean:38.6153 min:17 max:90 sd:13.661
2: "capital_gain" NUMERICAL mean:1081.9 min:0 max:99999 sd:7509.48
3: "capital_loss" NUMERICAL mean:87.2806 min:0 max:4356 sd:403.01
5: "education_num" NUMERICAL mean:10.0927 min:1 max:16 sd:2.56427
6: "fnlwgt" NUMERICAL mean:189879 min:12285 max:1.4847e+06 sd:106423
7: "hours_per_week" NUMERICAL mean:40.3955 min:1 max:99 sd:12.249
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute which type is manually defined by the user i.e. the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
[INFO 23-08-16 11:15:06.8492 UTC kernel.cc:810] Configure learner
[WARNING 23-08-16 11:15:06.8494 UTC gradient_boosted_trees.cc:1818] "goss_alpha" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:15:06.8494 UTC gradient_boosted_trees.cc:1829] "goss_beta" set but "sampling_method" not equal to "GOSS".
[WARNING 23-08-16 11:15:06.8494 UTC gradient_boosted_trees.cc:1843] "selective_gradient_boosting_ratio" set but "sampling_method" not equal to "SELGB".
[INFO 23-08-16 11:15:06.8495
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!