【Python篇】python库讲解(pickle | random | numpy)

🎄pickle模块
pickle模块是Python标准库中的一个模块,用于序列化和反序列化Python对象。它可以将Python对象转化为字节流形式,以便于存储或传输,然后在需要时将其还原为原始对象。
pickle模块提供了以下两个主要的函数:
- pickle.dump(obj, file):将Python对象
序列化并写入文件。
obj:要序列化的Python对象。
file:要写入的文件对象。 - pickle.load(file):从文件中
读取序列化的Python对象并反序列化l1 mm。
file:要读取的文件对象。
使用pickle模块可以方便地实现对象的持久化存储,或者在进程间传递复杂的数据结构。
🛸样例
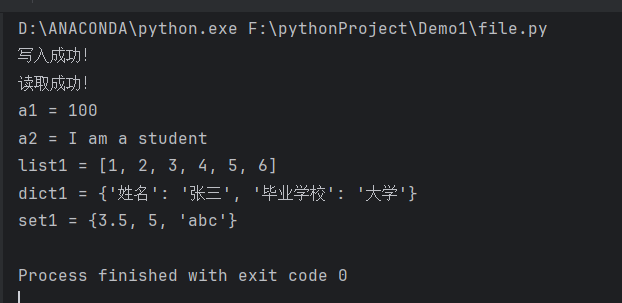
编写一个程序,分别将整数a1=100,字符串a2=“I am a student”,列表list1 = [1,2,3,4,5,6],字典dict1 = {“姓名”:“张三”,“毕业学校”:“大学”},集合set1 = {3.5,5,“abc”}用pickle模块写入一个二进制文件中。写入成功后,再次打开文件,读取二进制文件中的数据。
要求:
用try-except语句对写入的过程进行可能出现的异常进行处理。显示写入成功,还是写入失败。
import pickle
# 写入数据到二进制文件
try:
a1 = 100
a2 = "I am a student"
list1 = [1, 2, 3, 4, 5, 6]
dict1 = {"姓名": "张三", "毕业学校": "河南科技大学"}
set1 = {3.5, 5, "abc"}
with open("data.pkl", "wb") as f:
pickle.dump(a1, f)
pickle.dump(a2, f)
pickle.dump(list1, f)
pickle.dump(dict1, f)
pickle.dump(set1, f)
print("写入成功!")
except Exception as e:
print("写入失败:", e)
# 从二进制文件中读取数据
try:
with open("data.pkl", "rb") as f:
a1 = pickle.load(f)
a2 = pickle.load(f)
list1 = pickle.load(f)
dict1 = pickle.load(f)
set1 = pickle.load(f)
print("读取成功!")
print("a1 =", a1)
print("a2 =", a2)
print("list1 =", list1)
print("dict1 =", dict1)
print("set1 =", set1)
except Exception as e:
print("读取失败:", e)
wb和rb是Python中文件打开模式的一部分,用于指定
以二进制模式进行文件读写操作。
- wb:以二进制模式写入文件。在这种模式下,可以将二进制数据(如字节流、图片、音频等)写入文件。如果文件不存在,则会创建一个新文件;如果文件已存在,则会清空文件内容并重新写入数据。
- rb:以二进制模式读取文件。在这种模式下,可以从文件中读取二进制数据。通常用于读取二进制文件、序列化对象等。
🎄random
random是Python提供的一个用于生成伪随机数的标准库。它可以用于模拟、游戏、密码学等多种应用场景。
下面是一些random库提供的常用函数:
- random.random():返回一个0到1之间的随机浮点数。
- random.randint(a, b):返回一个a到b之间的随机整数。
- random.choice(seq):从序列seq中返回一个随机元素。
- random.shuffle(seq):将序列seq中的元素随机排列。
- random.sample(pop, k):从序列pop中随机选择k个元素并返回一个新序列。
import random
# 生成随机整数
random_int = random.randint(1, 100)
# 生成随机浮点数
random_float = random.random()
# 从列表中选择一个随机元素
fruits = ['apple', 'banana', 'orange']
random_fruit = random.choice(fruits)
# 将列表中的元素随机排列
random.shuffle(fruits)
# 从列表中随机选择2个元素
two_fruits = random.sample(fruits, 2)
🛸样例
编写一个程序实现如下功能:
随机产生20个1~100之间的随机整数,写入文本文件中。
import random
# 生成20个1~100之间的随机整数并写入文件
random_numbers = []
for _ in range(20):
random_number = random.randint(1, 100)
random_numbers.append(random_number)
with open("E:/a.txt", "w", encoding="utf-8") as file:
file.write(' '.join(map(str, random_numbers)))
🎄numpy库
numpy库在科学计算和数据分析领域有着广泛的应用,它提供了高效的多维数组对象(ndarray)以及对这些数组进行操作的函数。以下是numpy库的一些主要用途:
- 数组操作:numpy的核心功能是处理数组。它提供了丰富的数组操作函数,例如创建数组、重塑数组形状、索引和切片数组、数组的数学运算(加法、减法、乘法、除法)、逻辑运算等。
- 数学函数:numpy提供了大量的数学函数,包括三角函数、指数函数、对数函数、幂函数、取整函数、统计函数等。这些函数对于科学计算和数据分析非常有用。
- 线性代数运算:numpy提供了矩阵和向量的运算功能,包括矩阵乘法、求逆、解线性方程组、特征值和特征向量计算等。这些功能对于线性代数相关的问题非常重要。
- 随机数生成:numpy可以生成各种分布的随机数,如均匀分布、正态分布、泊松分布等。这对于模拟实验和随机抽样非常有用。
- 文件输入输出:numpy能够读写数组数据到硬盘,支持多种文件格式,如文本文件、二进制文件、CSV文件等。这样可以方便地保存和加载数据。
总的来说,numpy库为Python提供了高性能、便捷的数组操作和数学函数,使得科学计算和数据分析更加高效和简洁。它是许多其他科学计算库的基础,例如pandas、scikit-learn等都建立在numpy库的基础之上。
import numpy as np
# 创建一个一维数组
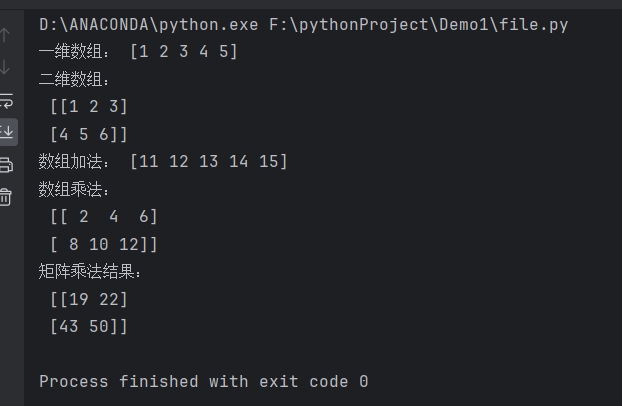
arr1 = np.array([1, 2, 3, 4, 5])
print("一维数组:", arr1)
# 创建一个二维数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print("二维数组:\n", arr2)
# 数组加法
arr3 = arr1 + 10
print("数组加法:", arr3)
# 数组乘法
arr4 = arr2 * 2
print("数组乘法:\n", arr4)
# 矩阵乘法
mat1 = np.array([[1, 2], [3, 4]])
mat2 = np.array([[5, 6], [7, 8]])
result_mat = np.dot(mat1, mat2)
print("矩阵乘法结果:\n", result_mat)
🛸例子
利用numpy库求解下列线性方程组的解
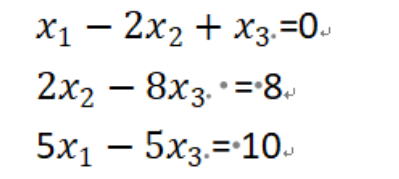
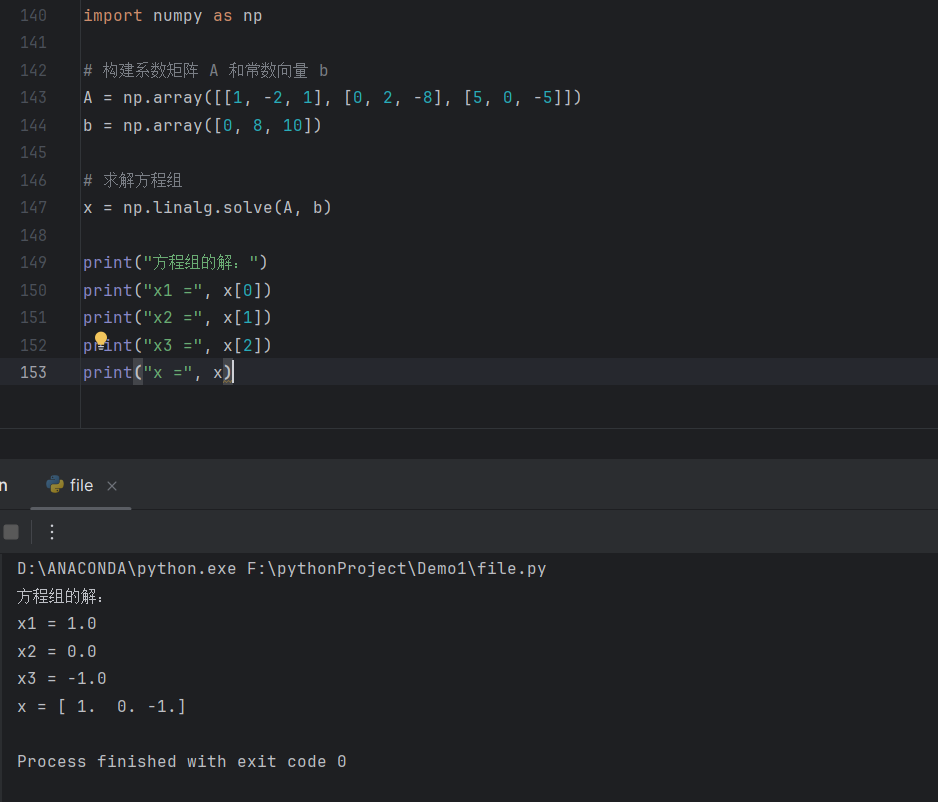
x = np.linalg.solve(A, b)
这段代码有什么用
这段代码使用了numpy库中的linalg.solve()函数,它用于求解线性方程组。
具体来说,假设有一个线性方程组:A * x = b,其中 A 是一个给定的矩阵,b 是一个给定的向量,x 是要求解的未知向量。
np.linalg.solve(A, b)的作用就是解决这个线性方程组,求出未知向量 x 的值。它使用了数值线性代数的方法,在数学上可以表示为:x = A?1 * b,其中 A?1 是矩阵 A 的逆矩阵。
在技术的道路上,我们不断探索、不断前行,不断面对挑战、不断突破自我。科技的发展改变着世界,而我们作为技术人员,也在这个过程中书写着自己的篇章。让我们携手并进,共同努力,开创美好的未来!愿我们在科技的征途上不断奋进,创造出更加美好、更加智能的明天!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!