[论文阅读]DETR
DETR
End-to-End Object Detection with Transformers
使用 Transformer 进行端到端物体检测
论文网址:DETR
论文代码:DETR
简读论文
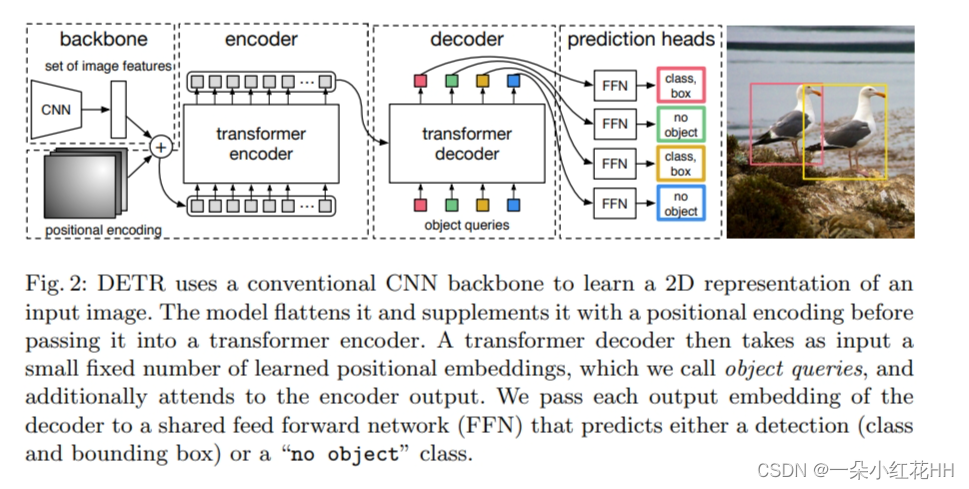
这篇论文提出了一个新的端到端目标检测模型DETR(Detection Transformer)。主要的贡献和创新点包括:
-
将目标检测视为一个直接的集合预测问题,不需要手工设计的组件如锚框或非最大抑制。
-
提出了基于变压器Encoder-Decoder结构的新模型。利用自注意力机制建模预测框之间的关系,并行预测所有对象。
-
使用匈牙利匹配算法的匹配损失函数,将预测框与真值框唯一匹配,保证预测结果无重复。
这部分负责将预测框和真值框匹配成对。具体来说: 使用匈牙利算法在预测框集合和真值框集合间找到一个最佳的匹配方案,使匹配代价最小。根据匹配结果,计算每一对匹配框之间的回归损失(包括置信度损失、L1框坐标损失和GIoU损失)。对所有匹配对的损失求和得到最终的匹配损失。这种匹配+损失计算的方式保证了预测结果之间无重复,并且能区分预测与真值之间的差异。 -
在COCO检测数据集上取得了与优化的Faster R-CNN基线可比的结果。特别在大目标的性能上有明显提升。
-
模型结构简单易扩展。文章中还在固定的检测模型上添加了分割头,在全景分割任务上也取得了很好的结果。
-
实现代码简洁,只需要标准的CNN和Transformer模块即可重现。
总的来说,这篇文章开创了目标检测领域基于Transformer的新方向,提供了一个简洁高效的检测框架,值得学习和参考。主要的不足是小目标的检测性能较弱,后续研究可在此继续优化。
摘要
本文提出了一种新方法,将目标检测视为直接集合预测问题。本文的方法简化了检测流程,有效地消除了对许多手工设计组件的需求,例如非极大值抑制过程或锚点生成,这些组件显式地编码了关于任务的先验知识。新框架的主要成分称为 DEtection TRansformer 或 DETR,是基于集合的全局损失,通过二分匹配强制进行独特的预测,以及 Transformer 编码器-解码器架构。给定一小组固定的学习对象查询集,DETR 会推理对象与全局图像上下文的关系,以直接并行输出最终的预测集。与许多其他现代检测器不同,新模型概念上很简单,不需要专门的库。 DETR 在具有挑战性的 COCO 对象检测数据集上展示了与成熟且高度优化的 Faster RCNN 基线相当的准确性和运行时性能。此外,DETR 可以很容易地推广,以统一的方式产生全景分割。本文证明它的性能显着优于竞争基准。
引言
目标检测的目标是预测每个感兴趣对象的一组边界框和类别标签。现代检测器通过在大量提案 、锚点或窗口中心上定义代理回归和分类问题,以间接的方式解决这组预测任务。它们的性能受到近似重复预测的后处理步骤、锚点集的设计以及将目标框分配给锚点的启发式方法的显着影响。为了简化这些pipeline,本文提出了一种直接集预测方法来绕过代理任务。这种端到端的理念已经在机器翻译或语音识别等复杂的结构化预测任务中带来了显着的进步,但在目标检测方面尚未取得进展:之前的尝试要么添加其他形式的先验知识,或者尚未证明在具有挑战性的基准上具有强大的竞争力。本文旨在弥合这一差距。
本文通过将目标检测视为直接集合预测问题来简化训练流程。采用基于 Transformer 的编码器-解码器架构,这是一种流行的序列预测架构。 Transformer 的自注意力机制明确地模拟了序列中元素之间的所有成对交互,使这些架构特别适合集合预测的特定约束,例如删除重复的预测。
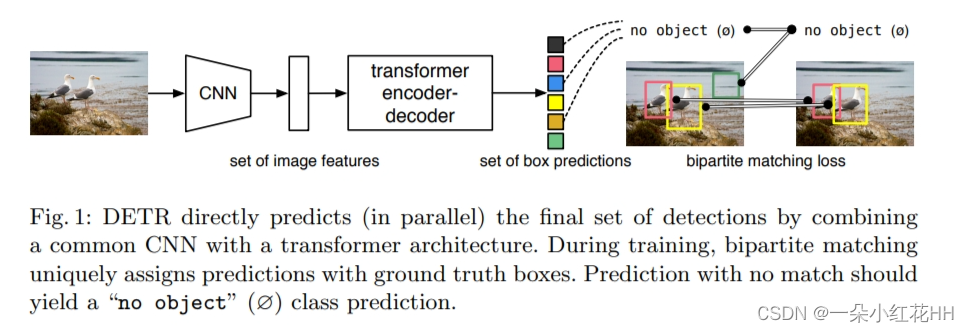
本文的 DEtection TRansformer(DETR,参见图 1)会同时预测所有对象,并使用一组损失函数进行端到端训练,该函数在预测目标和真实目标之间执行二分匹配。 DETR 通过删除多个手工设计的编码先验知识的组件(例如空间锚点或非极大值抑制)来简化检测流程。与大多数现有的检测方法不同,DETR 不需要任何自定义层,因此可以在包含标准 CNN 和 Transformer 类的任何框架中轻松重现。
与大多数先前的直接集预测工作相比,DETR 的主要特征是将二分匹配损失和Transformers与(非自回归)并行解码相结合。相比之下,之前的工作主要集中在 RNN 的自回归解码上 。本文的匹配损失函数唯一地将预测分配给地面实况目标,并且对于预测目标的排列是不变的,因此可以并行发出它们。
本文在最流行的目标检测数据集之一 COCO 上针对极具竞争力的 Faster R-CNN 基线评估 DETR。 Faster RCNN自最初发布以来经历了多次设计迭代,其性能得到了极大的提高。本文的实验表明,本文的新模型实现了可比的性能。更准确地说,DETR 在大型对象上表现出明显更好的性能,这一结果可能是由Transformer的非局部计算实现的。然而,它在小物体上的性能较低。本文预计未来的工作将像 FPN 的开发对 Faster R-CNN 所做的那样改进这方面。
DETR 的训练设置在多个方面与标准目标检测器不同。新模型需要超长的训练计划,并受益于Transformer中的辅助解码损失。本文深入探讨了哪些组件对于所展示的性能至关重要。
DETR 的设计理念可以轻松扩展到更复杂的任务。在本文的实验中表明,在预训练的 DETR 之上训练的简单分割头优于全景分割的竞争基线,全景分割是一项最近流行的具有挑战性的像素级识别任务。
相关工作
本文的工作建立在多个领域的先前工作的基础上:集合预测的二分匹配损失、基于Transformer的编码器-解码器架构、并行解码和目标检测方法。
集合预测
目前还没有直接预测集合的典型深度学习模型。基本的集合预测任务是多标签分类,对于这种任务,基线方法one-vs-rest,不适用于元素之间存在潜在结构(即近乎相同的方框)的检测等问题。这些任务的第一个难点是避免近似重复。目前大多数检测器都使用非最大抑制等后处理方法来解决这个问题,但直接集合预测则不需要后处理。它们需要全局推理方案来模拟所有预测元素之间的相互作用,以避免冗余。对于恒定大小的集合预测,密集的全连接网络已经足够,但成本很高。一般的方法是使用自动回归序列模型,如递归神经网络。在所有情况下,损失函数都应与预测的排列保持不变。通常的解决方案是根据匈牙利算法设计损失函数,在地面实况和预测之间找到两端匹配。这就强制实现了包络不变性,并保证每个目标元素都有唯一的匹配。本文采用的是双匹配损失法。不过,与之前的大多数工作不同,本文不再使用自回归模型,而是使用具有并行解码功能的Transformer。
Transformers和并行解码
Transformer是由 Vaswani 等人提出的。 Transformer作为机器翻译的新的基于注意力的构建块。注意力机制是聚合来自整个输入序列的信息的神经网络层。 Transformer 引入了自注意力层,与非局部神经网络类似,它扫描序列的每个元素,并通过聚合整个序列的信息来更新它。基于注意力的模型的主要优点之一是它们的全局计算和完美的记忆,这使得它们比 RNN 更适合长序列。 Transformer 现在正在自然语言处理、语音处理和计算机视觉的许多问题中取代 RNN。
Transformer 最初用于自回归模型,遵循早期的序列到序列模型 ,生成输出标记。然而,令人望而却步的推理成本(与输出长度成正比,并且难以批处理)导致了音频、机器翻译、单词表示学习领域中并行序列生成的发展,以及最近的语音识别。本文还结合了Transformer和并行解码,以在计算成本和执行集合预测所需的全局计算的能力之间进行适当的权衡。
目标检测
大多数现代目标检测方法都会根据一些初始猜测进行预测。两阶段检测器根据预测框提议,而单阶段方法则通过锚点或可能的对象中心网格进行预测。最近的工作表明,这些系统的最终性能在很大程度上取决于这些初始猜测设置的确切方式。在本文的模型中,能够消除这种手工制作的过程,并通过输入图像而不是锚点,使用绝对框预测直接预测检测集来简化检测过程。
基于集合的损失。 : 一些目标检测器使用了二分匹配损失。然而,在这些早期的深度学习模型中,不同预测之间的关系仅使用卷积层或全连接层进行建模,并且手工设计的 NMS 后处理可以提高其性能。最近的检测器使用地面实况和预测之间的非唯一分配规则以及 NMS。
可学习的 NMS 方法和关系网络通过注意力显式地建模不同预测之间的关系。使用直接设置损失,它们不需要任何后处理步骤。然而,这些方法采用额外的手工制作的上下文特征(如提案框坐标)来有效地建模检测之间的关系,同时本文寻找减少模型中编码的先验知识的解决方案。
循环检测器。 : 最接近本文的方法的是目标检测[End-to-end people detection in crowded scenes]和实例分割[Recurrent instance segmentation, Learning to decompose for object detection and instance segmentation, End-to-end instance segmentation with recurrent attention, Recurrent neural networks for semantic instance segmentation]的端到端集合预测。与本文类似,他们使用基于 CNN 激活的编码器-解码器架构的二分匹配损失来直接生成一组边界框。然而,这些方法仅在小型数据集上进行评估,而不是根据现代基线进行评估。特别是,它们基于自回归模型(更准确地说是 RNN),因此它们没有利用最新的并行解码转换器。
DETR
对于检测中的直接集合预测来说,有两个要素至关重要:(1)集合预测损失,强制预测框和真实框之间进行唯一匹配; (2) 一种能够(在一次传递中)预测一组目标并对其关系进行建模的架构。本文在图 2 中详细描述了本文的架构。
Object detection set prediction loss
DETR 在通过解码器的单次传递中推断出一组固定大小的 N 个预测,其中 N 设置为明显大于图像中目标的典型数量。训练的主要困难之一是根据真实情况对预测目标(类别、位置、大小)进行评分。本文的损失在预测目标和地面真实目标之间产生最佳二分匹配,然后优化特定于目标(边界框)的损失。
用 y 表示目标的真实集,并且 ?y = {?yi}N i=1 表示 N 个预测的集合。假设 N 大于图像中的目标数量,也将 y 视为用 ?(无对象)填充的大小为 N 的集合。为了找到这两个集合之间的二分匹配,本文以最低成本搜索 N 个元素 σ ∈ SN 的排列:
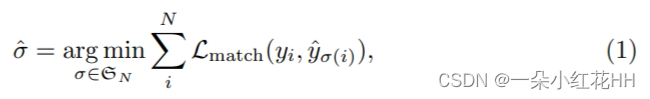
其中 Lmatch(yi, ?yσ(i)) 是真实值 yi 和索引为 σ(i) 的预测之间的成对匹配成本。根据先前的工作,可以使用匈牙利算法有效地计算出这种最佳分配。
匹配成本考虑了类别预测以及预测框和地面实况框的相似性。地面真值集的每个元素 i 可以看作是 yi = (ci, bi),其中 ci 是目标类标签(可能是 ?),bi ∈ [0, 1]4 是定义地面真值框的向量中心坐标及其相对于图像尺寸的高度和宽度。对于索引为 σ(i) 的预测,本文将类别 ci 的概率定义为 ?pσ(i)(ci),将预测框定义为 ?bσ(i)。利用这些符号,将 Lmatch(yi, ?yσ(i)) 定义为 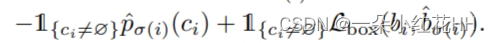 。
。
这种寻找匹配的过程与现代检测器中用于将提案或锚点与地面真实对象相匹配的启发式分配规则起着相同的作用。主要区别在于,本文需要找到一对一的匹配来进行直接集预测,而无需重复。
第二步是计算损失函数,即上一步中匹配的所有对的匈牙利损失。本文定义的损失与常见目标检测器的损失类似,即类预测的负对数似然和稍后定义的框损失的线性组合:
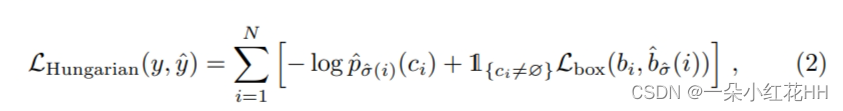
其中 ^σ 是第一步 (1) 中计算的最优分配。在实践中,当 ci = ? 时,将对数概率项的权重降低 10 倍,以解决类别不平衡的问题。这类似于 Faster R-CNN 训练过程如何通过子采样来平衡正/负提案。请注意,对象和 ? 之间的匹配成本不取决于预测,这意味着在这种情况下成本是一个常数。在匹配成本中,使用概率 ?p?σ(i)(ci) 而不是对数概率。这使得类别预测项与 Lbox(·,·)(如下所述)相当,并且本文观察到更好的经验性能。
Bounding box loss. : 匹配成本和匈牙利损失的第二部分是对边界框进行评分的 Lbox(·)。与许多将框预测作为 Δ w.r.t 的检测器不同。一些初步的猜测,直接进行框预测。虽然这种方法简化了实现,但它带来了损失相对缩放的问题。最常用的 L1 损失对于小框和大框会有不同的尺度,即使它们的相对误差相似。为了缓解这个问题,本文使用 L1 损失和尺度不变的广义 IoU 损失 Liou(·,·) 的线性组合。总体而言,本文的框损失为 Lbox(bi, ?bσ(i)) ,定义为 λiouLiou(bi, ?bσ(i)) + λL1||bi ? ?bσ(i)||1,其中 λiou、λL1 ∈ R 是超参数。这两个损失通过批次内的对象数量进行归一化。
DETR架构
整体 DETR 架构非常简单,如图 2 所示。它包含三个主要组件,帮我在下面进行描述:一个用于提取紧凑特征表示的 CNN 主干、一个编码器-解码器Transformer以及一个简单的前馈网络 (FFN),该网络用于提取紧凑的特征表示。做出最终的检测预测。
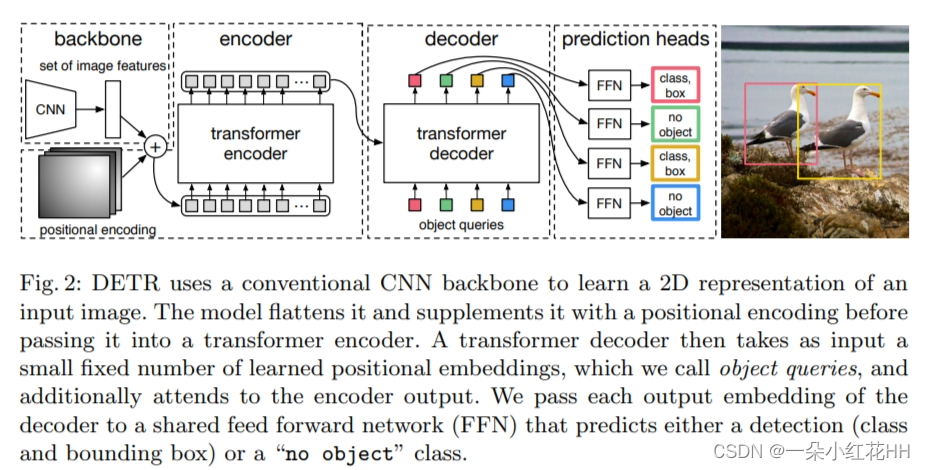
与许多现代检测器不同,DETR 可以在任何提供通用 CNN 主干和Transformer架构实现的深度学习框架中实现,只需几百行。 DETR 的推理代码可以在 PyTorch 中用不到 50 行来实现。本文希望本文方法的简单性能够吸引新的研究人员加入检测社区。
Backbone. 从初始图像 ximg ∈ R3×H0×W0 (具有 3 个颜色通道)开始,传统的 CNN 主干生成一个较低分辨率的激活图 f ∈ RC×H×W。本文使用的典型值是 C = 2048 和 H,W = H0/32 , W0/32 。
class ResNet(BaseModule):
"""ResNet backbone.
Args:
depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
"""
arch_settings = {
18: (BasicBlock, (2, 2, 2, 2)),
34: (BasicBlock, (3, 4, 6, 3)),
50: (Bottleneck, (3, 4, 6, 3)),
101: (Bottleneck, (3, 4, 23, 3)),
152: (Bottleneck, (3, 8, 36, 3))
}
def __init__(self,
depth,
in_channels=3,
stem_channels=None,
base_channels=64,
num_stages=4,
strides=(1, 2, 2, 2),
dilations=(1, 1, 1, 1),
out_indices=(0, 1, 2, 3),
style='pytorch',
deep_stem=False,
avg_down=False,
frozen_stages=-1,
conv_cfg=None,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
dcn=None,
stage_with_dcn=(False, False, False, False),
plugins=None,
with_cp=False,
zero_init_residual=True,
pretrained=None,
init_cfg=None):
super(ResNet, self).__init__(init_cfg)
self.zero_init_residual = zero_init_residual
if depth not in self.arch_settings:
raise KeyError(f'invalid depth {depth} for resnet')
block_init_cfg = None
assert not (init_cfg and pretrained), \
'init_cfg and pretrained cannot be specified at the same time'
if isinstance(pretrained, str):
warnings.warn('DeprecationWarning: pretrained is deprecated, '
'please use "init_cfg" instead')
self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
elif pretrained is None:
if init_cfg is None:
self.init_cfg = [
dict(type='Kaiming', layer='Conv2d'),
dict(
type='Constant',
val=1,
layer=['_BatchNorm', 'GroupNorm'])
]
block = self.arch_settings[depth][0]
if self.zero_init_residual:
if block is BasicBlock:
block_init_cfg = dict(
type='Constant',
val=0,
override=dict(name='norm2'))
elif block is Bottleneck:
block_init_cfg = dict(
type='Constant',
val=0,
override=dict(name='norm3'))
else:
raise TypeError('pretrained must be a str or None')
self.depth = depth
if stem_channels is None:
stem_channels = base_channels
self.stem_channels = stem_channels
self.base_channels = base_channels
self.num_stages = num_stages
assert num_stages >= 1 and num_stages <= 4
self.strides = strides
self.dilations = dilations
assert len(strides) == len(dilations) == num_stages
self.out_indices = out_indices
assert max(out_indices) < num_stages
self.style = style
self.deep_stem = deep_stem
self.avg_down = avg_down
self.frozen_stages = frozen_stages
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.with_cp = with_cp
self.norm_eval = norm_eval
self.dcn = dcn
self.stage_with_dcn = stage_with_dcn
if dcn is not None:
assert len(stage_with_dcn) == num_stages
self.plugins = plugins
self.block, stage_blocks = self.arch_settings[depth]
self.stage_blocks = stage_blocks[:num_stages]
self.inplanes = stem_channels
self._make_stem_layer(in_channels, stem_channels)
self.res_layers = []
for i, num_blocks in enumerate(self.stage_blocks):
stride = strides[i]
dilation = dilations[i]
dcn = self.dcn if self.stage_with_dcn[i] else None
if plugins is not None:
stage_plugins = self.make_stage_plugins(plugins, i)
else:
stage_plugins = None
planes = base_channels * 2**i
res_layer = self.make_res_layer(
block=self.block,
inplanes=self.inplanes,
planes=planes,
num_blocks=num_blocks,
stride=stride,
dilation=dilation,
style=self.style,
avg_down=self.avg_down,
with_cp=with_cp,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
dcn=dcn,
plugins=stage_plugins,
init_cfg=block_init_cfg)
self.inplanes = planes * self.block.expansion
layer_name = f'layer{i + 1}'
self.add_module(layer_name, res_layer)
self.res_layers.append(layer_name)
self._freeze_stages()
self.feat_dim = self.block.expansion * base_channels * 2**(
len(self.stage_blocks) - 1)
def make_stage_plugins(self, plugins, stage_idx):
stage_plugins = []
for plugin in plugins:
plugin = plugin.copy()
stages = plugin.pop('stages', None)
assert stages is None or len(stages) == self.num_stages
# whether to insert plugin into current stage
if stages is None or stages[stage_idx]:
stage_plugins.append(plugin)
return stage_plugins
def make_res_layer(self, **kwargs):
"""Pack all blocks in a stage into a ``ResLayer``."""
return ResLayer(**kwargs)
@property
def norm1(self):
"""nn.Module: the normalization layer named "norm1" """
return getattr(self, self.norm1_name)
def _make_stem_layer(self, in_channels, stem_channels):
if self.deep_stem:
self.stem = nn.Sequential(
build_conv_layer(
self.conv_cfg,
in_channels,
stem_channels // 2,
kernel_size=3,
stride=2,
padding=1,
bias=False),
build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
nn.ReLU(inplace=True),
build_conv_layer(
self.conv_cfg,
stem_channels // 2,
stem_channels // 2,
kernel_size=3,
stride=1,
padding=1,
bias=False),
build_norm_layer(self.norm_cfg, stem_channels // 2)[1],
nn.ReLU(inplace=True),
build_conv_layer(
self.conv_cfg,
stem_channels // 2,
stem_channels,
kernel_size=3,
stride=1,
padding=1,
bias=False),
build_norm_layer(self.norm_cfg, stem_channels)[1],
nn.ReLU(inplace=True))
else:
self.conv1 = build_conv_layer(
self.conv_cfg,
in_channels,
stem_channels,
kernel_size=7,
stride=2,
padding=3,
bias=False)
self.norm1_name, norm1 = build_norm_layer(
self.norm_cfg, stem_channels, postfix=1)
self.add_module(self.norm1_name, norm1)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
def _freeze_stages(self):
if self.frozen_stages >= 0:
if self.deep_stem:
self.stem.eval()
for param in self.stem.parameters():
param.requires_grad = False
else:
self.norm1.eval()
for m in [self.conv1, self.norm1]:
for param in m.parameters():
param.requires_grad = False
for i in range(1, self.frozen_stages + 1):
m = getattr(self, f'layer{i}')
m.eval()
for param in m.parameters():
param.requires_grad = False
def forward(self, x):
"""Forward function."""
if self.deep_stem:
x = self.stem(x)
else:
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
x = self.maxpool(x)
outs = []
for i, layer_name in enumerate(self.res_layers):
res_layer = getattr(self, layer_name)
x = res_layer(x)
if i in self.out_indices:
outs.append(x)
return tuple(outs)
def train(self, mode=True):
super(ResNet, self).train(mode)
self._freeze_stages()
if mode and self.norm_eval:
for m in self.modules():
# trick: eval have effect on BatchNorm only
if isinstance(m, _BatchNorm):
m.eval()
Transformer encoder. 首先,1x1 卷积将高级激活图 f 的通道维度从 C 减少到更小的维度 d。创建一个新的特征图 z0 ∈ Rd×H×W。
class ChannelMapper(BaseModule):
"""Channel Mapper to reduce/increase channels of backbone features.
This is used to reduce/increase channels of backbone features.
Args:
in_channels (List[int]): Number of input channels per scale.
out_channels (int): Number of output channels (used at each scale).
"""
def __init__(
self,
in_channels: List[int],
out_channels: int,
kernel_size: int = 3,
conv_cfg: OptConfigType = None,
norm_cfg: OptConfigType = None,
act_cfg: OptConfigType = dict(type='ReLU'),
num_outs: int = None,
init_cfg: OptMultiConfig = dict(
type='Xavier', layer='Conv2d', distribution='uniform')
) -> None:
super().__init__(init_cfg=init_cfg)
assert isinstance(in_channels, list)
self.extra_convs = None
if num_outs is None:
num_outs = len(in_channels)
self.convs = nn.ModuleList()
for in_channel in in_channels:
self.convs.append(
ConvModule(
in_channel,
out_channels,
kernel_size,
padding=(kernel_size - 1) // 2,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg))
if num_outs > len(in_channels):
self.extra_convs = nn.ModuleList()
for i in range(len(in_channels), num_outs):
if i == len(in_channels):
in_channel = in_channels[-1]
else:
in_channel = out_channels
self.extra_convs.append(
ConvModule(
in_channel,
out_channels,
3,
stride=2,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg))
def forward(self, inputs: Tuple[Tensor]) -> Tuple[Tensor]:
"""Forward function."""
assert len(inputs) == len(self.convs)
outs = [self.convs[i](inputs[i]) for i in range(len(inputs))]
if self.extra_convs:
for i in range(len(self.extra_convs)):
if i == 0:
outs.append(self.extra_convs[0](inputs[-1]))
else:
outs.append(self.extra_convs[i](outs[-1]))
return tuple(outs)
编码器期望一个序列作为输入,因此将 z0 的空间维度折叠为一维,从而产生 d×HW 特征图。每个编码器层都有一个标准架构,由多头自注意力模块和前馈网络(FFN)组成。由于 Transformer 架构是排列不变的,用固定位置编码对其进行补充,并将其添加到每个注意层的输入中。
class DetrTransformerEncoder(BaseModule):
def __init__(self,
num_layers: int,
layer_cfg: ConfigType,
init_cfg: OptConfigType = None) -> None:
super().__init__(init_cfg=init_cfg)
self.num_layers = num_layers
self.layer_cfg = layer_cfg
self._init_layers()
def _init_layers(self) -> None:
"""Initialize encoder layers."""
self.layers = ModuleList([
DetrTransformerEncoderLayer(**self.layer_cfg)
for _ in range(self.num_layers)
])
self.embed_dims = self.layers[0].embed_dims
def forward(self, query: Tensor, query_pos: Tensor,
key_padding_mask: Tensor, **kwargs) -> Tensor:
for layer in self.layers:
query = layer(query, query_pos, key_padding_mask, **kwargs)
return query
Transformer decoder. 解码器遵循 Transformer 的标准架构,使用多头自注意力机制和编码器-解码器注意力机制来转换大小为 d 的 N 个嵌入。与原始 Transformer 的区别在于,本文的模型在每个解码器层并行解码 N 个对象,而 Vaswani 等人使用一种自回归模型,一次预测一个元素的输出序列。由于解码器也是排列不变的,因此 N 个输入嵌入必须不同才能产生不同的结果。这些输入嵌入是学习的位置编码,本文将其称为对象查询,与编码器类似,本文将它们添加到每个注意层的输入中。 N 个对象查询被解码器转换为输出嵌入。然后通过前馈网络将它们独立解码为框坐标和类标签,从而产生 N 个最终预测。利用对这些嵌入的自注意力和编码器-解码器注意力,该模型使用它们之间的成对关系对所有对象进行全局推理,同时能够使用整个图像作为上下文。
class DetrTransformerDecoder(BaseModule):
def __init__(self,
num_layers: int,
layer_cfg: ConfigType,
post_norm_cfg: OptConfigType = dict(type='LN'),
return_intermediate: bool = True,
init_cfg: Union[dict, ConfigDict] = None) -> None:
super().__init__(init_cfg=init_cfg)
self.layer_cfg = layer_cfg
self.num_layers = num_layers
self.post_norm_cfg = post_norm_cfg
self.return_intermediate = return_intermediate
self._init_layers()
def _init_layers(self) -> None:
"""Initialize decoder layers."""
self.layers = ModuleList([
DetrTransformerDecoderLayer(**self.layer_cfg)
for _ in range(self.num_layers)
])
self.embed_dims = self.layers[0].embed_dims
self.post_norm = build_norm_layer(self.post_norm_cfg,
self.embed_dims)[1]
def forward(self, query: Tensor, key: Tensor, value: Tensor,
query_pos: Tensor, key_pos: Tensor, key_padding_mask: Tensor,
**kwargs) -> Tensor:
intermediate = []
for layer in self.layers:
query = layer(
query,
key=key,
value=value,
query_pos=query_pos,
key_pos=key_pos,
key_padding_mask=key_padding_mask,
**kwargs)
if self.return_intermediate:
intermediate.append(self.post_norm(query))
query = self.post_norm(query)
if self.return_intermediate:
return torch.stack(intermediate)
return query.unsqueeze(0)
Prediction feed-forward networks (FFNs). 最终预测由具有 ReLU 激活函数和隐藏维度 d 的 3 层感知器以及线性投影层计算。 FFN 预测框的标准化中心坐标、高度和宽度。输入图像,线性层使用 softmax 函数预测类标签。由于本文预测一组固定大小的 N 个边界框,其中 N 通常远大于图像中感兴趣对象的实际数量,因此使用额外的特殊类标签 ? 来表示在槽内未检测到对象。该类在标准对象检测方法中扮演着与“背景”类类似的角色。
class FFNLayer(nn.Module):
def __init__(self,
d_model,
dim_feedforward=2048,
dropout=0.0,
activation='relu',
normalize_before=False):
super().__init__()
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm = nn.LayerNorm(d_model)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
self._reset_parameters()
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt):
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout(tgt2)
tgt = self.norm(tgt)
return tgt
def forward_pre(self, tgt):
tgt2 = self.norm(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout(tgt2)
return tgt
def forward(self, tgt):
if self.normalize_before:
return self.forward_pre(tgt)
return self.forward_post(tgt)
Auxiliary decoding losses. (辅助解码损失) 本文发现在训练期间在解码器中使用辅助损失很有帮助,特别是有助于模型输出每个类别的正确数量的对象。本文在每个解码器层之后添加预测 FFN 和匈牙利损失。所有预测 FFN 共享其参数。使用额外的共享层范数来规范化来自不同解码器层的预测 FFN 的输入。
结论
本文提出了 DETR,一种基于Transformer和用于直接集预测的二分匹配损失的目标检测系统的新设计。该方法在具有挑战性的 COCO 数据集上取得了与优化的 Faster R-CNN 基线相当的结果。 DETR 实施起来很简单,并且具有灵活的架构,可以轻松扩展到全景分割,并具有具有竞争力的结果。此外,它在大型物体上取得了比 Faster R-CNN 更好的性能,这可能要归功于自注意力对全局信息的处理。
这种新的检测器设计也带来了新的挑战,特别是在小物体的训练、优化和性能方面。当前的检测器需要数年的改进才能应对类似的问题,本文期望未来的工作能够成功解决 DETR 的这些问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!