目标检测入门体验,技术选型,加载数据集、构建机器学习模型、训练并评估
Hi, I’m Shendi
1、目标检测入门体验,技术选型,加载数据集、构建机器学习模型、训练并评估
在最近有了个物体识别的需求,于是开始学习
在一番比较与询问后,最终选择 TensorFlow。
对于编程语言,我比较偏向Java或nodejs的,而TensorFlow这两者都是支持的,但是我看了下Java的API,标记了一个D…弃用的标识,而nodejs经过询问说不定有些功能可能没有,语言只是工具,所以最终还是选择了首选的Python
前置准备
因为使用python,在开始前,需要安装Python与pip
可以参考这篇文章 Python+pip下载与安装 https://sdpro.top/blog/html/article/1207.html
需要注意的是,对Python版本是有要求的,我因为版本过高无法安装TensorFlow,可以在下面链接查看版本要求
https://tensorflow.google.cn/install/pip?hl=zh-cn#system-install

否则会出现下面这样的问题:

这是 TensorFlow 官网:https://www.tensorflow.org/
官网的初学者快速入门教程:https://www.tensorflow.org/tutorials/quickstart/beginner
使用 pip 安装 TensorFlow
使用以下命令安装
pip3 install tensorflow
我使用了阿里云的镜像,需要增加额外参数信任此地址才能继续

等待下载完成就可以直接使用了
入门
这里通过官网的初学者 TensorFlow 2.0教程入门
对于啥也不懂的我来说确实有点难以…
主要是其中的代码,讲述的大概不够清晰,不知道结果是什么样。通过查阅资料以及询问 GPT,总算是ok了
就分那么几步
第一步,导入 TensorFlow
import tensorflow as tf
第二步,加载数据集
关于这个数据集,我是懵逼的,官网就三行代码,也没有什么描述,但是有个链接,点进去,全英文
标题翻译过来是这样的:MNIST数据库的手写数字
根据询问gpt,的确是这样的
官方的描述与代码:
加载并准备 MNIST 数据集。将样本数据从整数转换为浮点数:
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
这样不知道数据集到底是什么,所以我通过询问GPT,得知了显示数据集的方法,直接显示报错,所以保存成图片的方式来显示
需要安装 matplotlib 库
pip install matplotlib
然后在代码导入
import matplotlib.pyplot as plt
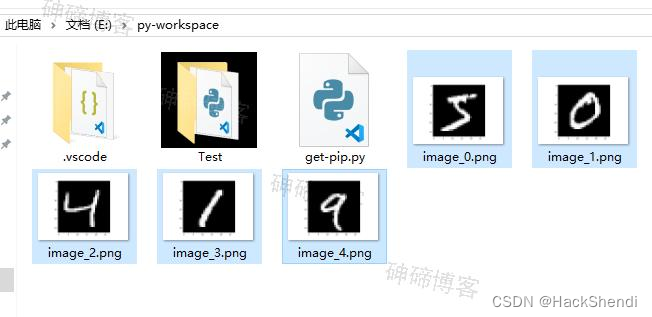
在加载完数据集后插入这样的代码,将数据集的几张图片保存
# 可视化前几个训练集样本的图像并保存为文件
for i in range(5): # 查看前五个样本
print("标签:", y_train[i])
plt.imshow(x_train[i], cmap='gray')
plt.savefig(f'image_{i}.png') # 将图像保存为文件
plt.close() # 关闭当前图像,准备绘制下一张图像
运行后,可以在当前文件的上级文件夹看到对应的图片了,是手写数字图
第三步,构建机器学习模型
这里直接复制官网的代码据可以了,毕竟刚学,重要的是体验
通过堆叠层来构建 tf.keras.Sequential 模型。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
对于每个样本,模型都会返回一个包含 logits 或 log-odds 分数的向量,每个类一个。
在深度学习的分类问题中,模型通常最后一层输出的是一个包含每个类别得分的向量,这些得分被称为 logits 或 log-odds 分数。Logits 不是直接的概率值,它们表示模型对每个类别的置信程度或分数。
举例来说,如果你的模型对手写数字进行分类,输出层可能会生成一个包含 10 个元素的向量,对应着数字 0 到 9。这个向量中的每个元素都代表了模型认为图像属于对应数字的得分,比如对于数字 3 的 logits 可能是 6.2,对于数字 7 可能是 3.1,而对于数字 1 可能是 1.5 等等。
predictions = model(x_train[:1]).numpy()
predictions
上面可以使用 print 将 predictions 打印查看,是一个数组
这行代码是在使用训练好的模型对输入数据进行预测,其中
x_train[:1]表示取训练集中的第一个样本(在 TensorFlow 中,通常使用的索引是从 0 开始的)。
model(x_train[:1])这部分代码是将训练好的模型应用在第一个训练样本上,得到模型的预测结果。预测结果是一个包含每个类别的 logits(或 log-odds 分数)的向量。通过
.numpy()方法,将 TensorFlow 的张量对象转换为 NumPy 数组,以便查看预测结果。这个操作对于初步了解模型在单个样本上的预测结果非常有用。这样可以看到模型对于这个特定样本的预测结果,了解模型的输出结构以及 logits 的分布情况。
tf.nn.softmax 函数将这些 logits 转换为每个类的概率:
tf.nn.softmax(predictions).numpy()
这行代码使用了 TensorFlow 中的
tf.nn.softmax()函数对模型的预测结果predictions进行 softmax 处理,将其转换为概率分布。具体来说,
tf.nn.softmax(predictions)将 logits(或 log-odds 分数)转换为对应的概率分布,这些概率表示模型对每个类别的预测概率。通过
.numpy()方法将 TensorFlow 的张量对象转换为 NumPy 数组,以便查看预测结果。这样处理后,你将得到每个类别的概率分布,可以看到模型对于这个特定样本,每个类别的预测概率值。
使用 losses.SparseCategoricalCrossentropy 为训练定义损失函数,它会接受 logits 向量和 True 索引,并为每个样本返回一个标量损失。
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
此损失等于 true 类的负对数概率:如果模型确定类正确,则损失为零。
这个未经训练的模型给出的概率接近随机(每个类为 1/10),因此初始损失应该接近 -tf.math.log(1/10) ~= 2.3。
loss_fn(y_train[:1], predictions).numpy()
可以通过 print 打印上面的执行结果
在开始训练之前,使用 Keras Model.compile 配置和编译模型。将 optimizer 类设置为 adam,将 loss 设置为您之前定义的 loss_fn 函数,并通过将 metrics 参数设置为 accuracy 来指定要为模型评估的指标。
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
第四步,训练并评估模型
使用 Model.fit 方法调整您的模型参数并最小化损失
model.fit(x_train, y_train, epochs=5)
Model.evaluate 方法通常在 “Validation-set” 或 “Test-set” 上检查模型性能。
model.evaluate(x_test, y_test, verbose=2)
可以将上面的结果通过 print 打印,是一个数组,有两个值
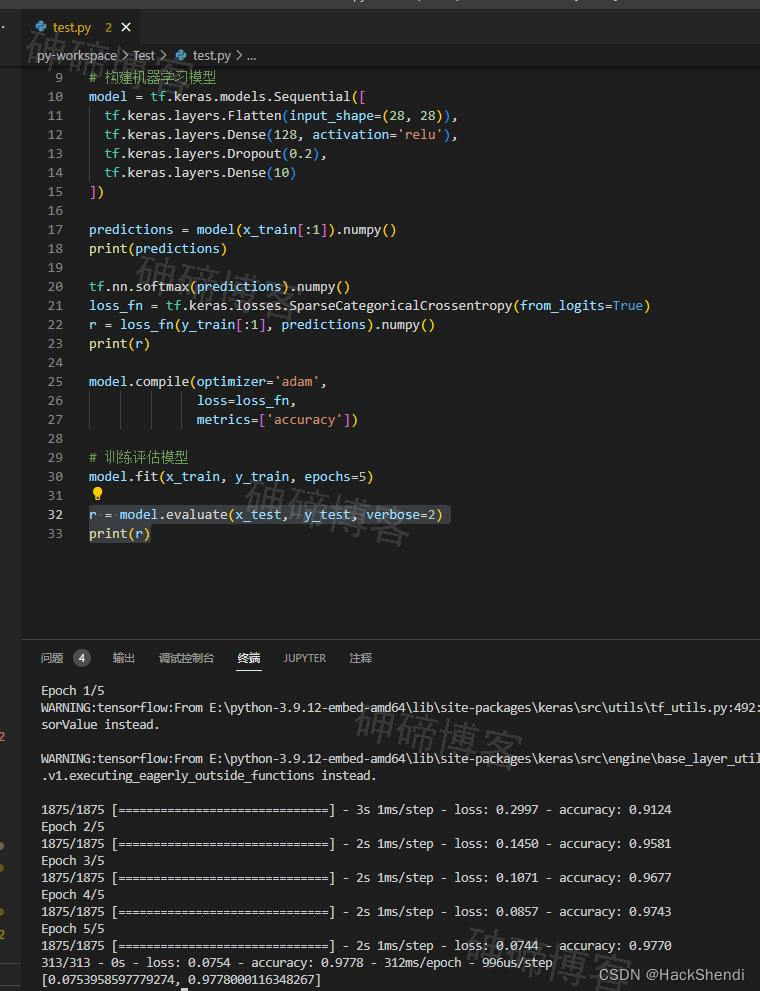
- 第一个值
0.0753958597779274是模型在测试集上的损失值。这个值表示模型在测试数据集上的平均损失程度,即模型在预测过程中与真实标签的差异程度。 - 第二个值
0.9778000116348267是模型在测试集上的准确率(或其他指定的评估指标)。在分类问题中,通常使用准确率来衡量模型的性能,它表示模型在测试集上正确预测的样本比例。
这两个值分别展示了模型在测试数据集上的损失程度和整体性能。较低的损失值和较高的准确率通常意味着模型在这个测试数据集上表现良好。
如果您想让模型返回概率,可以封装经过训练的模型,并将 softmax 附加到该模型:
probability_model = tf.keras.Sequential([
model,
tf.keras.layers.Softmax()
])
probability_model(x_test[:5])
到这里就算是体验了下吧,下节将这个模型尝试使用,看看能不能识别出数字
结论
恭喜!您已经利用 Keras API 借助预构建数据集训练了一个机器学习模型。
有关使用 Keras 的更多示例,请查阅教程。要详细了解如何使用 Keras 构建模型,请阅读指南。如果您想详细了解如何加载和准备数据,请参阅有关图像数据加载或 CSV 数据加载的教程。
END
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!