MySQL 事务的底层原理和 MVCC(一)
在事务的实现机制上,MySQL 采用的是 WAL(Write-ahead logging,预写式日志)机制来实现的。
在使用 WAL 的系统中,所有的修改都先被写入到日志中,然后再被应用到系统中。通常包含 redo 和 undo 两部分信息。
为什么需要使用 WAL,然后包含 redo 和 undo 信息呢?举个例子,如果一个系统直接将变更应用到系统状态中,那么在机器掉电重启之后系统需要知道操作是成功了,还是只有部分成功或者是失败了(为了恢复状态)。如果使用了WAL,那么在重启之后系统可以通过比较日志和系统状态来决定是继续完成操作还是撤销操作。
redo log 称为重做日志,每当有操作时,在数据变更之前将操作写入 redo log,这样当发生掉电之类的情况时系统可以在重启后继续操作。
undo log 称为撤销日志,当一些变更执行到一半无法完成时,可以根据撤销日志恢复到变更之间的状态。
MySQL 中用 redo log 来在系统 Crash 重启之类的情况时修复数据(事务的持久性),而 undo log 来保证事务的原子性。
7.1. redo 日志
7.1.1. redo 日志的作用
InnoDB 存储引擎是以页为单位来管理存储空间的,我们进行的增删改查操作其实本质上都是在访问页面(包括读页面、写页面、创建新页面等操作)。在Buffer Pool 的时候说过,在真正访问页面之前,需要把在磁盘上的页缓存到内存中的 Buffer Pool 之后才可以访问。但是在事务的时候又强调过一个称之为持久性的特性,就是说对于一个已经提交的事务,在事务提交后即使系统发生了崩溃,这个事务对数据库中所做的更改也不能丢失。
如果我们只在内存的 Buffer Pool 中修改了页面,假设在事务提交后突然发生了某个故障,导致内存中的数据都失效了,那么这个已经提交了的事务对数据库中所做的更改也就跟着丢失了,这是我们所不能忍受的。那么如何保证这个持久性呢?一个很简单的做法就是在事务提交完成之前把该事务所修改的所有页面都刷新到磁盘,但是这个简单粗暴的做法有些问题:
刷新一个完整的数据页太浪费了
有时候我们仅仅修改了某个页面中的一个字节,但是我们知道在 InnoDB 中是以页为单位来进行磁盘 IO 的,也就是说我们在该事务提交时不得不将一个完整的页面从内存中刷新到磁盘,我们又知道一个页面默认是 16KB 大小,只修改一个字节就要刷新 16KB 的数据到磁盘上显然是太浪费了。
随机 IO 刷起来比较慢
一个事务可能包含很多语句,即使是一条语句也可能修改许多页面,该事务修改的这些页面可能并不相邻,这就意味着在将某个事务修改的 Buffer Pool 中的页面刷新到磁盘时,需要进行很多的随机 IO,随机 IO 比顺序 IO 要慢,尤其对于传统的机械硬盘来说。
怎么办呢?我们只是想让已经提交了的事务对数据库中数据所做的修改永
久生效,即使后来系统崩溃,在重启后也能把这种修改恢复出来。所以我们其实没有必要在每次事务提交时就把该事务在内存中修改过的全部页面刷新到磁盘,只需要把修改了哪些东西记录一下就好,比方说某个事务将系统表空间中的第100 号页面中偏移量为 1000 处的那个字节的值 1 改成 2 我们只需要记录一下:
将第 0 号表空间的 100 号页面的偏移量为 1000 处的值更新为 2。
这样我们在事务提交时,把上述内容刷新到磁盘中,即使之后系统崩溃了,重启之后只要按照上述内容所记录的步骤重新更新一下数据页,那么该事务对数据库中所做的修改又可以被恢复出来,也就意味着满足持久性的要求。因为在系统崩溃重启时需要按照上述内容所记录的步骤重新更新数据页,所以上述内容也被称之为重做日志,英文名为 redo log,也可以称之为 redo 日志。与在事务提交时将所有修改过的内存中的页面刷新到磁盘中相比,只将该事务执行过程中产生的 redo 日志刷新到磁盘的好处如下:
1、redo 日志占用的空间非常小
存储表空间 ID、页号、偏移量以及需要更新的值所需的存储空间是很小的。
2、redo 日志是顺序写入磁盘的
在执行事务的过程中,每执行一条语句,就可能产生若干条 redo 日志,这些日志是按照产生的顺序写入磁盘的,也就是使用顺序 IO。
7.1.2. redo 日志格式
通过上边的内容我们知道,redo 日志本质上只是记录了一下事务对数据库做了哪些修改。 InnoDB 们针对事务对数据库的不同修改场景定义了多种类型的redo 日志,但是绝大部分类型的 redo 日志都有下边这种通用的结构:

各个部分的详细释义如下:
type:该条 redo 日志的类型,redo 日志设计大约有 53 种不同的类型日志。
- space ID:表空间 ID。
- page number:页号。
- data:该条 redo 日志的具体内容。
7.1.2.1. 简单的 redo 日志类
我们用一个简单的例子来说明最基本的 redo 日志类型。我们前边介绍
InnoDB 的记录行格式的时候说过,如果我们没有为某个表显式的定义主键,并且表中也没有定义 Unique 键,那么 InnoDB 会自动的为表添加一个称之为 row_id的隐藏列作为主键。为这个 row_id 隐藏列赋值的方式如下:
服务器会在内存中维护一个全局变量,每当向某个包含隐藏的 row_id 列的表中插入一条记录时,就会把该变量的值当作新记录的 row_id 列的值,并且把该变量自增 1。
每当这个变量的值为 256 的倍数时,就会将该变量的值刷新到系统表空间的页号为 7 的页面中一个称之为 Max Row ID 的属性处。
当系统启动时,会将上边提到的 Max Row ID 属性加载到内存中,将该值加上 256 之后赋值给我们前边提到的全局变量。
这个 Max Row ID 属性占用的存储空间是 8 个字节,当某个事务向某个包含row_id 隐藏列的表插入一条记录,并且为该记录分配的 row_id 值为 256 的倍数时,就会向系统表空间页号为 7 的页面的相应偏移量处写入 8 个字节的值。但是我们要知道,这个写入实际上是在 Buffer Pool 中完成的,我们需要为这个页面的修改记录一条 redo 日志,以便在系统崩溃后能将已经提交的该事务对该页面所做的修改恢复出来。这种情况下对页面的修改是极其简单的,redo 日志中只需要记录一下在某个页面的某个偏移量处修改了几个字节的值,具体被修改的内容是啥就好了,InnoDB 把这种极其简单的 redo 日志称之为物理日志,并且根据在页面中写入数据的多少划分了几种不同的 redo 日志类型:
- MLOG_1BYTE(type 字段对应的十进制数字为 1):表示在页面的某个偏移量处写入 1 个字节的 redo 日志类型。
- MLOG_2BYTE(type 字段对应的十进制数字为 2):表示在页面的某个偏移量处写入 2 个字节的 redo 日志类型。
- MLOG_4BYTE(type 字段对应的十进制数字为 4):表示在页面的某个偏移量处写入 4 个字节的 redo 日志类型。
- MLOG_8BYTE(type 字段对应的十进制数字为 8):表示在页面的某个偏移量处写入 8 个字节的 redo 日志类型。
- MLOG_WRITE_STRING(type 字段对应的十进制数字为 30):表示在页面的某个偏移量处写入一串数据。
我们上边提到的 Max Row ID 属性实际占用 8 个字节的存储空间,所以在修改页面中的该属性时,会记录一条类型为MLOG_8BYTE的redo日志,MLOG_8BYTE的 redo 日志结构如下所示:
offset 代表在页面中的偏移量。

其余 MLOG_1BYTE、MLOG_2BYTE、MLOG_4BYTE 类型的 redo 日志结构和MLOG_8BYTE 的类似,只不过具体数据中包含对应个字节的数据罢了。
MLOG_WRITE_STRING 类型的 redo 日志表示写入一串数据,但是因为不能确定写入的具体数据占用多少字节,所以需要在日志结构中还会多一个 len 字段。
7.1.2.2. 复杂一些的 redo 日志类型
有时候执行一条语句会修改非常多的页面,包括系统数据页面和用户数据页面(用户数据指的就是聚簇索引和二级索引对应的 B+树)。以一条 INSERT 语句为例,它除了要向 B+树的页面中插入数据,也可能更新系统数据 Max Row ID 的值,不过对于我们用户来说,平时更关心的是语句对 B+树所做更新:
表中包含多少个索引,一条 INSERT 语句就可能更新多少棵 B+树。
针对某一棵 B+树来说,既可能更新叶子节点页面,也可能更新非叶子节点页面,也可能创建新的页面(在该记录插入的叶子节点的剩余空间比较少,不足以存放该记录时,会进行页面的分裂,在非叶子节点页面中添加目录项记录)。
在语句执行过程中,INSERT 语句对所有页面的修改都得保存到 redo 日志中去。实现起来是非常麻烦的,比方说将记录插入到聚簇索引中时,如果定位到的叶子节点的剩余空间足够存储该记录时,那么只更新该叶子节点页面就好,那么只记录一条 MLOG_WRITE_STRING 类型的 redo 日志,表明在页面的某个偏移量处增加了哪些数据就好了么?
别忘了一个数据页中除了存储实际的记录之后,还有什么 File Header、PageHeader、Page Directory 等等部分,所以每往叶子节点代表的数据页里插入一条记录时,还有其他很多地方会跟着更新,比如说:
可能更新 Page Directory 中的槽信息、Page Header 中的各种页面统计信息,比如槽数量可能会更改,还未使用的空间最小地址可能会更改,本页面中的记录数量可能会更改,各种信息都可能会被修改,同时数据页里的记录是按照索引列从小到大的顺序组成一个单向链表的,每插入一条记录,还需要更新上一条记录的记录头信息中的 next_record 属性来维护这个单向链表。
画一个简易的示意图就像是这样:
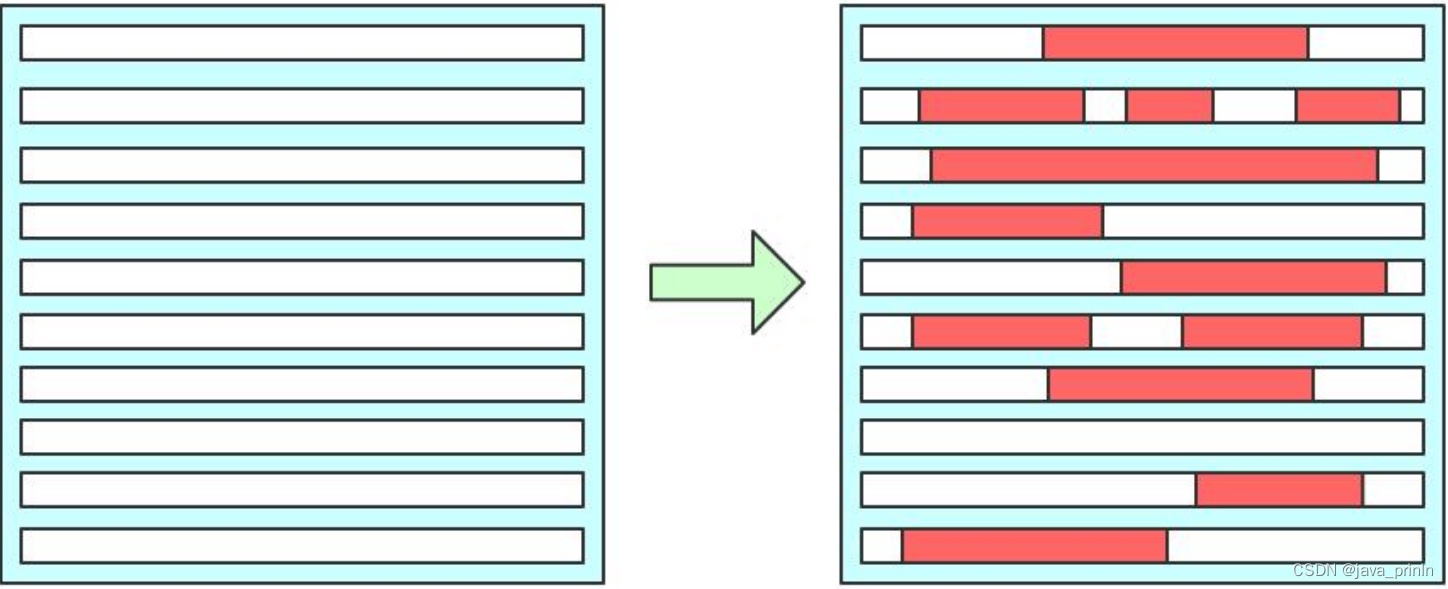
其实说到底,把一条记录插入到一个页面时需要更改的地方非常多。这时我们如果使用上边介绍的简单的物理 redo 日志来记录这些修改时,可以有两种解决方案:
- 方案一:在每个修改的地方都记录一条 redo 日志。
也就是如上图所示,有多少个加粗的块,就写多少条物理 redo 日志。这样子记录 redo 日志的缺点是显而易见的,因为被修改的地方是在太多了,可能记录的 redo 日志占用的空间都比整个页面占用的空间都多了。 - 方案二:将整个页面的第一个被修改的字节到最后一个修改的字节之间所有的数据当成是一条物理 redo 日志中的具体数据。
从图中也可以看出来,第一个被修改的字节到最后一个修改的字节之间仍然有许多没有修改过的数据,我们把这些没有修改的数据也加入到 redo 日志中去依然很浪费。
正因为上述两种使用物理 redo 日志的方式来记录某个页面中做了哪些修改比较浪费,InnoDB 中就有非常多的 redo 日志类型来做记录。
这些类型的 redo 日志既包含物理层面的意思,也包含逻辑层面的意思,具体指:
物理层面看,这些日志都指明了对哪个表空间的哪个页进行了修改。
逻辑层面看,在系统崩溃重启时,并不能直接根据这些日志里的记载,将页面内的某个偏移量处恢复成某个数据,而是需要调用一些事先准备好的函数,执行完这些函数后才可以将页面恢复成系统崩溃前的样子。
简单来说,一个 redo 日志类型而只是把在本页面中变动(比如插入、修改)一条记录所有必备的要素记了下来,之后系统崩溃重启时,服务器会调用相关向某个页面变动(比如插入、修改)一条记录的那个函数,而 redo 日志中的那些数据就可以被当成是调用这个函数所需的参数,在调用完该函数后,页面中的相关值也就都被恢复到系统崩溃前的样子了。这就是所谓的逻辑日志的意思。
当然,如果不是为了写一个解析 redo 日志的工具或者自己开发一套 redo 日志系统的话,那就不需要去研究 InnoDB 中的 redo 日志具体格式。
大家只要记住:redo 日志会把事务在执行过程中对数据库所做的所有修改都记录下来,在之后系统崩溃重启后可以把事务所做的任何修改都恢复出来。
7.1.3. Mini-Transaction
7.1.3.1. 以组的形式写入 redo 日志
语句在执行过程中可能修改若干个页面。比如我们前边说的一条 INSERT 语句可能修改系统表空间页号为 7 的页面的 Max Row ID 属性(当然也可能更新别的系统页面,只不过我们没有都列举出来而已),还会更新聚簇索引和二级索引对应 B+树中的页面。由于对这些页面的更改都发生在 Buffer Pool 中,所以在修改完页面之后,需要记录一下相应的 redo 日志。
在这个执行语句的过程中产生的 redo 日志被 InnoDB 人为的划分成了若干个不可分割的组,比如:
1、更新 Max Row ID 属性时产生的 redo 日志是不可分割的。
2、向聚簇索引对应 B+树的页面中插入一条记录时产生的 redo 日志是不可分割的。
3、向某个二级索引对应 B+树的页面中插入一条记录时产生的 redo 日志是不可分割的。
4、还有其他的一些对页面的访问操作时产生的 redo 日志是不可分割的….。
怎么理解这个不可分割的意思呢?我们以向某个索引对应的 B+树插入一条记录为例,在向 B+树中插入这条记录之前,需要先定位到这条记录应该被插入到哪个叶子节点代表的数据页中,定位到具体的数据页之后,有两种可能的情况:
情况二:该数据页剩余的空闲空间不足,那么事情就很麻烦了,遇到这种情况要进行所谓的页分裂操作:
1、新建一个叶子节点;
2、然后把原先数据页中的一部分记录复制到这个新的数据页中;
3、然后再把记录插入进去,把这个叶子节点插入到叶子节点链表中;
4、非叶子节点中添加一条目录项记录指向这个新创建的页面;
5、非叶子节点空间不足,继续分裂。
很显然,这个过程要对多个页面进行修改,也就意味着会产生很多条 redo日志,我们把这种情况称之为悲观插入。
另外,这个过程中,由于需要新申请数据页,还需要改动一些系统页面,比方说要修改各种段、区的统计信息信息,各种链表的统计信息,也会产生 redo日志。
当然在乐观插入时也可能产生多条 redo 日志。
InnoDB 认为向某个索引对应的 B+树中插入一条记录的这个过程必须是原子的,不能说插了一半之后就停止了。比方说在悲观插入过程中,新的页面已经分配好了,数据也复制过去了,新的记录也插入到页面中了,可是没有向非叶子节点中插入一条目录项记录,这个插入过程就是不完整的,这样会形成一棵不正确的 B+树。
我们知道 redo 日志是为了在系统崩溃重启时恢复崩溃前的状态,如果在悲观插入的过程中只记录了一部分 redo 日志,那么在系统崩溃重启时会将索引对应的 B+树恢复成一种不正确的状态。
所以规定在执行这些需要保证原子性的操作时必须以组的形式来记录的redo 日志,在进行系统崩溃重启恢复时,针对某个组中的 redo 日志,要么把全部的日志都恢复掉,要么一条也不恢复。在实现上,根据多个 redo 日志的不同,使用了特殊的 redo 日志类型作为组的结尾,来表示一组完整的 redo 日志。
7.1.3.2. Mini-Transaction 的概念
所以 MySQL 把对底层页面中的一次原子访问的过程称之为一个Mini-Transaction,比如上边所说的修改一次 Max Row ID 的值算是一个
Mini-Transaction,向某个索引对应的 B+树中插入一条记录的过程也算是一个Mini-Transaction。
一个所谓的 Mini-Transaction 可以包含一组 redo 日志,在进行崩溃恢复时这一组 redo 日志作为一个不可分割的整体。
一个事务可以包含若干条语句,每一条语句其实是由若干个 Mini-Transaction组成,每一个 Mini-Transaction 又可以包含若干条 redo 日志,最终形成了一个树形结构。
7.1.4. redo 日志的写入过程
7.1.4.1. redo log block 和日志缓冲区
InnoDB 为了更好的进行系统崩溃恢复,把通过 Mini-Transaction 生成的 redo日志都放在了大小为 512 字节的块(block)中。。
我们前边说过,为了解决磁盘速度过慢的问题而引入了 Buffer Pool。同理,写入 redo 日志时也不能直接直接写到磁盘上,实际上在服务器启动时就向操作系统申请了一大片称之为 redo log buffer 的连续内存空间,翻译成中文就是 redo日志缓冲区,我们也可以简称为 log buffer。这片内存空间被划分成若干个连续的 redo log block,我们可以通过启动参数 innodb_log_buffer_size 来指定 log buffer的大小,该启动参数的默认值为 16MB。
向 log buffer 中写入 redo 日志的过程是顺序的,也就是先往前边的 block 中写,当该 block 的空闲空间用完之后再往下一个 block 中写。
我们前边说过一个 Mini-Transaction 执行过程中可能产生若干条 redo 日志,这些 redo 日志是一个不可分割的组,所以其实并不是每生成一条 redo 日志,就将其插入到 log buffer 中,而是每个 Mini-Transaction 运行过程中产生的日志先暂时存到一个地方,当该 Mini-Transaction 结束的时候,将过程中产生的一组 redo日志再全部复制到 log buffer 中。
7.1.4.2. redo 日志刷盘时机
我们前边说 Mini-Transaction 运行过程中产生的一组 redo 日志在
Mini-Transaction 结束时会被复制到 log buffer 中,可是这些日志总在内存里呆着也不是个办法,在一些情况下它们会被刷新到磁盘里,比如:
1、log buffer 空间不足时,log buffer 的大小是有限的(通过系统变量
innodb_log_buffer_size 指定),如果不停的往这个有限大小的 log buffer 里塞入日志,很快它就会被填满。InnoDB 认为如果当前写入 log buffer 的 redo 日志量已经占满了 log buffer 总容量的大约一半左右,就需要把这些日志刷新到磁盘上。
2、事务提交时,我们前边说过之所以使用 redo 日志主要是因为它占用的空间少,还是顺序写,在事务提交时可以不把修改过的 Buffer Pool 页面刷新到磁盘,但是为了保证持久性,必须要把修改这些页面对应的 redo 日志刷新到磁盘。
3、后台有一个线程,大约每秒都会刷新一次 log buffer 中的 redo 日志到磁盘。
4、正常关闭服务器时等等。
7.1.4.3. redo 日志文件组
MySQL 的数据目录(使用 SHOW VARIABLES LIKE 'datadir’查看)下默认有两个名为 ib_logfile0 和 ib_logfile1 的文件,log buffer 中的日志默认情况下就是刷新到这两个磁盘文件中。如果我们对默认的 redo 日志文件不满意,可以通过下边几个启动参数来调节:
innodb_log_group_home_dir,该参数指定了 redo 日志文件所在的目录,默认值就是当前的数据目录。
- innodb_log_file_size,该参数指定了每个 redo 日志文件的大小,默认值为 48MB,
- innodb_log_files_in_group,该参数指定 redo 日志文件的个数,默认值为 2,最大值为 100。
所以磁盘上的 redo 日志文件可以不只一个,而是以一个日志文件组的形式出现的。这些文件以 ib_logfile[数字](数字可以是 0、1、2…)的形式进行命名。
在将 redo 日志写入日志文件组时,是从 ib_logfile0 开始写,如果 ib_logfile0 写满了,就接着 ib_logfile1 写,同理,ib_logfile1 写满了就去写 ib_logfile2,依此类推。
如果写到最后一个文件该咋办?那就重新转到 ib_logfile0 继续写。
7.1.4.4. redo 日志文件格式
我们前边说过 log buffer 本质上是一片连续的内存空间,被划分成了若干个512 字节大小的 block。将 log buffer 中的 redo 日志刷新到磁盘的本质就是把 block的镜像写入日志文件中,所以 redo 日志文件其实也是由若干个 512 字节大小的block 组成。
redo 日志文件组中的每个文件大小都一样,格式也一样,都是由两部分组成:前 2048 个字节,也就是前 4 个 block 是用来存储一些管理信息的。
从第 2048 字节往后是用来存储 log buffer 中的 block 镜像的。
7.1.5. Log Sequence Number
自系统开始运行,就不断的在修改页面,也就意味着会不断的生成 redo 日志。redo 日志的量在不断的递增,就像人的年龄一样,自打出生起就不断递增,永远不可能缩减了。
InnoDB 为记录已经写入的 redo 日志量,设计了一个称之为 Log Sequence Number 的全局变量,翻译过来就是:日志序列号,简称 LSN。规定初始的 lsn 值为 8704(也就是一条 redo 日志也没写入时,LSN 的值为 8704)。
我们知道在向 log buffer 中写入 redo 日志时不是一条一条写入的,而是以一个 Mini-Transaction 生成的一组 redo 日志为单位进行写入的。从上边的描述中可以看出来,每一组由 Mini-Transaction 生成的 redo 日志都有一个唯一的 LSN 值与其对应,LSN 值越小,说明 redo 日志产生的越早。
7.1.5.1. flushed_to_disk_lsn
redo 日志是首先写到 log buffer 中,之后才会被刷新到磁盘上的 redo 日志文件。InnoDB 中有一个称之为 buf_next_to_write 的全局变量,标记当前 log buffer中已经有哪些日志被刷新到磁盘中了。
我们前边说 lsn 是表示当前系统中写入的 redo 日志量,这包括了写到 logbuffer 而没有刷新到磁盘的日志,相应的,InnoDB 也有一个表示刷新到磁盘中的redo 日志量的全局变量,称之为flushed_to_disk_lsn。系统第一次启动时,该变量的值和初始的 lsn 值是相同的,都是 8704。随着系统的运行,redo 日志被不断写入 log buffer,但是并不会立即刷新到磁盘,lsn 的值就和 flushed_to_disk_lsn的值拉开了差距。我们演示一下:
系统第一次启动后,向 log buffer 中写入了 mtr_1、mtr_2、mtr_3 这三个 mtr产生的 redo 日志,假设这三个 mtr 开始和结束时对应的 lsn 值分别是:
- mtr_1:8716 ~ 8916
- mtr_2:8916 ~ 9948
- mtr_3:9948 ~ 10000
此时的 lsn 已经增长到了 10000,但是由于没有刷新操作,所以此时
flushed_to_disk_lsn 的值仍为 8704。
随后进行将 log buffer 中的 block 刷新到 redo 日志文件的操作,假设将 mtr_1和 mtr_2 的日志刷新到磁盘,那么 flushed_to_disk_lsn 就应该增长 mtr_1 和 mtr_2写入的日志量,所以 flushed_to_disk_lsn 的值增长到了 9948。
综上所述,当有新的 redo 日志写入到 log buffer 时,首先 lsn 的值会增长,但flushed_to_disk_lsn不变,随后随着不断有log buffer中的日志被刷新到磁盘上,flushed_to_disk_lsn 的值也跟着增长。如果两者的值相同时,说明 log buffer 中的所有 redo 日志都已经刷新到磁盘中了。
Tips:应用程序向磁盘写入文件时其实是先写到操作系统的缓冲区中去,如果某个写入操作要等到操作系统确认已经写到磁盘时才返回,那需要调用一下操作系统提供的 fsync 函数。其实只有当系统执行了 fsync 函数后,flushed_to_disk_lsn 的值才会跟着增长,当仅仅把 log buffer 中的日志写入到操作系统缓冲区却没有显式的刷新到磁盘时,另外的一个称之为 write_lsn 的值跟着增长。
当然系统的 LSN 值远不止我们前面描述的 lsn,还有很多。
7.1.5.2. 查看系统中的各种 LSN 值
我们可以使用 SHOW ENGINE INNODB STATUS 命令查看当前 InnoDB 存储引擎中的各种 LSN 值的情况,比如:
SHOW ENGINE INNODB STATUS\G
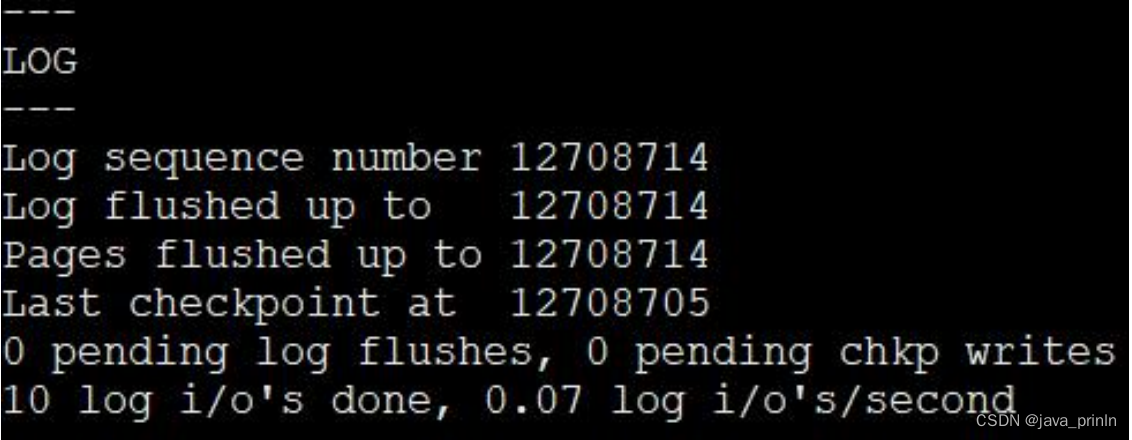
其中:
- Log sequence number:代表系统中的 lsn 值,也就是当前系统已经写入的 redo日志量,包括写入 log buffer 中的日志。
- Log flushed up to:代表 flushed_to_disk_lsn 的值,也就是当前系统已经写入磁盘的 redo 日志量。
- Pages flushed up to:代表 flush 链表中被最早修改的那个页面对应的oldest_modification 属性值。
- Last checkpoint at:当前系统的 checkpoint_lsn 值。
7.1.6. innodb_flush_log_at_trx_commit 的用法
我们前边说为了保证事务的持久性,用户线程在事务提交时需要将该事务执行过程中产生的所有 redo 日志都刷新到磁盘上。会很明显的降低数据库性能。
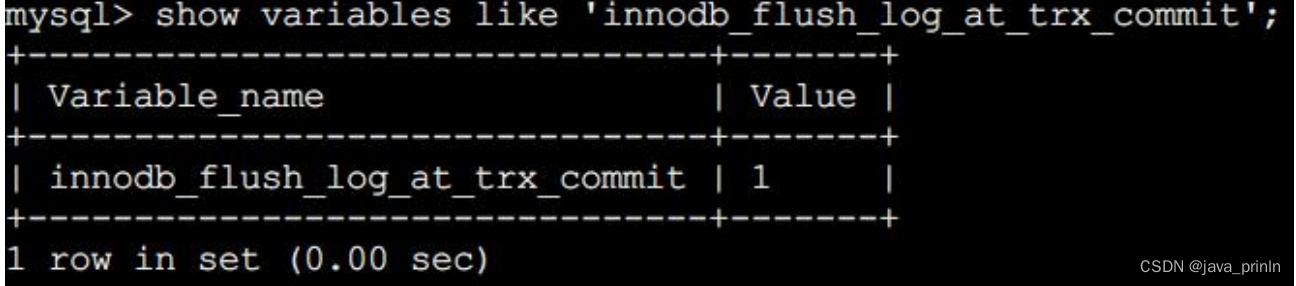
如果对事务的持久性要求不是那么强烈的话,可以选择修改一个称为
innodb_flush_log_at_trx_commit 的系统变量的值,该变量有 3 个可选的值:
0:当该系统变量值为 0 时,表示在事务提交时不立即向磁盘中同步 redo 日志,这个任务是交给后台线程做的。
这样很明显会加快请求处理速度,但是如果事务提交后服务器挂了,后台线程没有及时将 redo 日志刷新到磁盘,那么该事务对页面的修改会丢失。
1:当该系统变量值为 1 时,表示在事务提交时需要将 redo 日志同步到磁盘,可以保证事务的持久性。1 也是 innodb_flush_log_at_trx_commit 的默认值。
2:当该系统变量值为 2 时,表示在事务提交时需要将 redo 日志写到操作系统的缓冲区中,但并不需要保证将日志真正的刷新到磁盘。
这种情况下如果数据库挂了,操作系统没挂的话,事务的持久性还是可以保证的,但是操作系统也挂了的话,那就不能保证持久性了。
7.1.7. 崩溃后的恢复
7.1.7.1. 恢复机制
在服务器不挂的情况下,redo 日志简直就是个大累赘,不仅没用,反而让性能变得更差。但是万一数据库挂了,就可以在重启时根据 redo 日志中的记录就可以将页面恢复到系统崩溃前的状态。
MySQL 可以根据 redo 日志中的各种 LSN 值,来确定恢复的起点和终点。然后将 redo 日志中的数据,以哈希表的形式,将一个页面下的放到哈希表的一个槽中。之后就可以遍历哈希表,因为对同一个页面进行修改的 redo 日志都放在了一个槽里,所以可以一次性将一个页面修复好(避免了很多读取页面的随机 IO)。
并且通过各种机制,避免无谓的页面修复,比如已经刷新的页面,进而提升崩溃恢复的速度。
7.1.7.2. 崩溃后的恢复为什么不用 binlog?
1、这两者使用方式不一样
binlog 会记录表所有更改操作,包括更新删除数据,更改表结构等等,主要用于人工恢复数据,而 redo log 对于我们是不可见的,它是 InnoDB 用于保证crash-safe 能力的,也就是在事务提交后 MySQL 崩溃的话,可以保证事务的持久性,即事务提交后其更改是永久性的。
一句话概括:binlog 是用作人工恢复数据,redo log 是 MySQL 自己使用,用于保证在数据库崩溃时的事务持久性。
2、redo log 是 InnoDB 引擎特有的,binlog 是 MySQL 的 Server 层实现的, 所有引擎都可以使用。
3、redo log 是物理日志,记录的是“在某个数据页上做了什么修改”,恢复
的速度更快;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2这的 c 字段加 1 ” ;
4、redo log 是“循环写”的日志文件,redo log 只会记录未刷盘的日志,已
经刷入磁盘的数据都会从 redo log 这个有限大小的日志文件里删除。binlog 是追加日志,保存的是全量的日志。
5、最重要的是,当数据库 crash 后,想要恢复未刷盘但已经写入 redo log 和binlog 的数据到内存时,binlog 是无法恢复的。虽然 binlog 拥有全量的日志,但没有一个标志让 innoDB 判断哪些数据已经入表(写入磁盘),哪些数据还没有。
比如,binlog 记录了两条日志:
给 ID=2 这一行的 c 字段加 1
给 ID=2 这一行的 c 字段加 1
在记录 1 入表后,记录 2 未入表时,数据库 crash。重启后,只通过 binlog数据库无法判断这两条记录哪条已经写入磁盘,哪条没有写入磁盘,不管是两条都恢复至内存,还是都不恢复,对 ID=2 这行数据来说,都不对。
但 redo log 不一样,只要刷入磁盘的数据,都会从 redo log 中抹掉,数据库重启后,直接把 redo log 中的数据都恢复至内存就可以了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!