GRU,LSTM,encoder-decoder架构,seq2seq的相关概念
门控记忆单元(GRU)
GRU模型有专门的机制来确定应该何时更新隐状态,以及应该何时重置隐状态。这些机制是可学习的。门控循环单元具有以下两个显著特征:
- 重置门有助于捕获序列中的短期依赖关系;
- 更新门有助于捕获序列中的长期依赖关系。
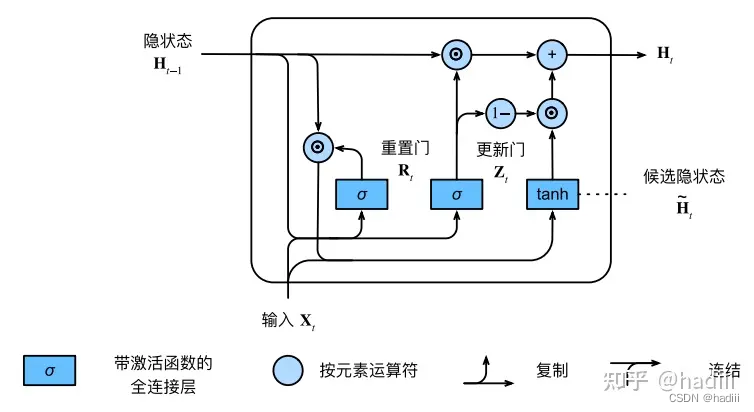
计算门控循环单元模型中的隐状态
GRU中的四个计算公式(符号⊙是Hadamard积,按元素乘积):
R
t
=
σ
(
X
t
W
x
r
+
H
t
?
1
W
h
r
+
b
r
)
R_t = σ(X_tW_{xr} + H_{t?1}W_{hr} + b_r)
Rt?=σ(Xt?Wxr?+Ht?1?Whr?+br?)
Z
t
=
σ
(
X
t
W
x
z
+
H
t
?
1
W
h
z
+
b
z
)
Z_t = σ(X_tW_{xz} + H_{t?1}W_{hz} + b_z)
Zt?=σ(Xt?Wxz?+Ht?1?Whz?+bz?)
H
t
~
=
t
a
n
h
(
X
t
W
x
h
+
(
R
t
⊙
H
t
?
1
)
W
h
h
+
b
h
)
\tilde{H_t} = tanh(X_tW_{xh} + (R_t ⊙ H_{t?1}) W_{hh} + b_h)
Ht?~?=tanh(Xt?Wxh?+(Rt?⊙Ht?1?)Whh?+bh?)
H
t
=
Z
t
⊙
H
t
?
1
+
(
1
?
Z
t
)
⊙
H
t
~
H_t = Z_t ⊙ H_{t?1} + (1 ? Z_t) ⊙ \tilde{H_t}
Ht?=Zt?⊙Ht?1?+(1?Zt?)⊙Ht?~?
长短期记忆网络(LSTM)
LSTM是一种特殊的RNN,主要由遗忘门、输入门和输出门三部分构成。
- 遗忘门负责决定哪些信息从细胞状态中丢弃,其根据当前输入和上一步的隐藏状态生成一个0到1之间的值,通过乘以细胞状态实现遗忘功能。
- 输入门则决定哪些新信息应添加到细胞状态中,它由一个sigmoid层和一个tanh层组成,sigmoid层决定哪些值需要更新,tanh层创建新的候选值向量。
- 输出门负责决定细胞状态的哪部分用于计算下一个隐藏状态,它首先通过sigmoid层决定细胞状态的哪些部分需要输出,然后将细胞状态通过tanh函数处理并与sigmoid门的输出相乘,产生最终的输出。

在长短期记忆模型中计算隐状态
LSTM的相关计算公式:
I
t
=
σ
(
X
t
W
x
i
+
H
t
?
1
W
h
i
+
b
i
)
I_t = σ(X_tW_{xi} + H_{t?1}W_{hi} + b_i)
It?=σ(Xt?Wxi?+Ht?1?Whi?+bi?)
F
t
=
σ
(
X
t
W
x
f
+
H
t
?
1
W
h
f
+
b
f
)
F_t = σ(X_tW_{xf} + H_{t?1}W_{hf} + b_f)
Ft?=σ(Xt?Wxf?+Ht?1?Whf?+bf?)
O
t
=
σ
(
X
t
W
x
o
+
H
t
?
1
W
h
o
+
b
o
)
O_t = σ(X_tW_{xo} + H_{t?1}W_{ho} + b_o)
Ot?=σ(Xt?Wxo?+Ht?1?Who?+bo?)
C
~
t
=
t
a
n
h
(
X
t
W
x
c
+
H
t
?
1
W
h
c
+
b
c
)
\tilde{C}_t = tanh(X_tW_{xc} + H_{t?1}W_{hc} + b_c)
C~t?=tanh(Xt?Wxc?+Ht?1?Whc?+bc?)
C
t
=
F
t
⊙
C
t
?
1
+
I
t
⊙
C
~
t
C_t = F_t ⊙ C_{t?1} + I_t ⊙ \tilde{C}_t
Ct?=Ft?⊙Ct?1?+It?⊙C~t?
H
t
=
O
t
⊙
t
a
n
h
(
C
t
)
H_t=O_t \odot tanh(C_t)
Ht?=Ot?⊙tanh(Ct?)
encoder-decoder架构
数据集加载:我们可以通过截断(truncation)和填充(padding)方式实现一次只处理一个小批量的文本序列。假设同一个小批量中的每个序列都应该具有相同的长度num_steps,那么如果文本序列的词元数目少于num_steps时,我们将继续在其末尾添加特定的“”词元,直到其长度达到num_steps;反之,我们将截断文本序列时,只取其前num_steps个词元,并且丢弃剩余的词元。这样,每个文本序列将具有相同的长度,以便以相同形状的小批量进行加载。
机器翻译是序列转换模型的一个核心问题,其输入和输出都是长度可变的序列。为了处理这种类型的输入和输出,我们可以设计一个包含两个主要组件的架构:
- 编码器(Encoder):编码器接受一个长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。编码器的主要任务是理解和编码输入序列的信息。
- 解码器(Decoder):解码器将固定形状的编码状态映射到长度可变的序列。解码器的主要任务是根据编码器的输出生成一个新的序列。
这种架构被称为编码器-解码器架构。在机器翻译中,编码器可能会接受一种语言的句子,然后解码器会生成另一种语言的句子。这种架构也被广泛应用于其他序列生成任务,如语音识别和文本摘要等。

seq2seq
循环神经网络编码器-解码器模型中的层
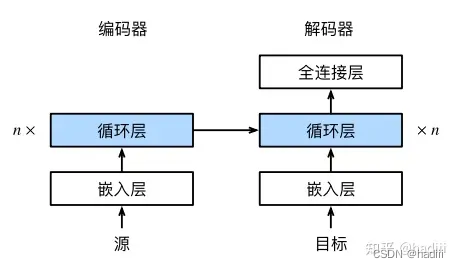
- 嵌入层:嵌入层的主要作用是将离散的文本数据(如单词、字符或子词)转换为连续的向量表示。这些向量表示可以捕捉词汇之间的语义关系,从而使模型能够更好地理解和处理文本数据。在这里,嵌?层的权重是?个矩阵,其行数等于输?词表的大小(vocab_size),其列数等于特征向量的维度(embed_size)。对于任意输?词元的索引i,嵌?层获取权重矩阵的第i行以返回其特征向量。
- 编码器实现:RNN的循环层所做的变换为 h t = f ( x t , h t ? 1 ) h_t = f(x_t, h_{t?1}) ht?=f(xt?,ht?1?),然后编码通过一个函数q将所有隐状态转换为上下文变量 c = q ( h 1 , . . . , h T ) c = q(h_1, . . . , h_T ) c=q(h1?,...,hT?),例如取 q ( h 1 , . . . , h T ) = h T q(h_1, . . . , h_T ) = h_T q(h1?,...,hT?)=hT?,上下文变量仅仅是输?序列在最后时间步的隐状态。
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列学习的循环神经?络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super().__init__(**kwargs)
# 嵌?层
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 在循环神经?络模型中,第?个轴对应于时间步
X = X.permute(1, 0, 2)
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
- 解码器实现: s t ′ = g ( y t ′ ? 1 , c , s t ′ ? 1 ) s_{t′} = g(y_{t ′?1}, c, s_{t ′?1}) st′?=g(yt′?1?,c,st′?1?),函数g表示解码器隐藏层的变换,它接收三个输入:上一个时间步的输出 y t ′ ? 1 y_{t'-1} yt′?1?,上下文变量 c c c(通常是编码器的最终隐藏状态,包含输入序列的信息),以及上一个时间步的隐藏状态 s t ′ ? 1 s_{t'-1} st′?1?。通过这个函数,解码器可以在每个时间步生成新的隐藏状态 s t ′ s_t' st′?,并根据这个隐藏状态来预测当前时间步的输出。获得解码器的隐状态之后,可以使用输出层和softmax操作来计算在时间步 t ′ t′ t′时输出` y t ′ y_{t ′} yt′?的条件概率分布 P ( y t ′ ∣ y 1 , . . . , y t ′ ? 1 , c ) P(y_{t ′} | y_1, . . . , y_{t ′?1}, c) P(yt′?∣y1?,...,yt′?1?,c)。
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播context,使其具有与X相同的num_steps
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
-
损失函数:在每个时间步,解码器会预测输出词元的概率分布,类似于语言模型的操作。为了优化这个过程,可以使用softmax来获得概率分布,并通过计算交叉熵损失函数来进行优化。为了遮蔽不相关的预测,可以对softmax交叉熵损失函数进行扩展。最初,所有预测词元的掩码都被设置为1。一旦给定了有效长度,与填充词元对应的掩码将被设置为0。最后,将所有词元的损失乘以掩码,以过滤掉损失中填充词元产生的不相关预测。
-
数据集加载:我们可以通过截断填充方式实现一次只处理一个小批量的文本序列。但是,我们应该将填充词元的预测排除在损失函数的计算之外。 可以使用sequence_mask函数通过零值化屏蔽不相关的项,以便后?任何不相关预测的计 算都是与零的乘积,结果都等于零。例如,如果两个序列的有效长度(不包括填充词元)分别为1和2,则第 ?个序列的第?项和第?个序列的前两项之后的剩余项将被清除为零。
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32, device=X.device)[None, :] < valid_len[:, None]
print(torch.arange((maxlen))[None, :])
print(valid_len[:, None])
print(mask)
X[~mask] = value
return X
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(sequence_mask(X, torch.tensor([1, 2])))
输出结果:
tensor([[0, 1, 2]])
tensor([[1],
[2]])
tensor([[ True, False, False],
[ True, True, False]])
tensor([[1, 0, 0],
[4, 5, 0]])
-
Decoder的输入,训练和测试时是不一样的。
-
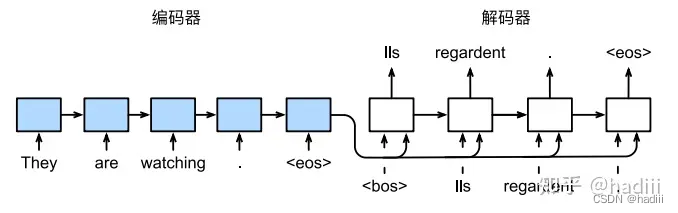
训练:采用强制教学方法(teacher forcing)。在这种方法中,序列开始词元(“”)在初始时间步被输入到解码器中,我们使用真实的目标文本作为输入,即将标准答案作为解码器的输入。在每个时间步,解码器会根据当前正确的输出词和上一步的隐状态来预测下一个输出词。这样做的好处是,在训练过程中,模型可以更容易地学习到正确的输出序列,减轻“一步错,步步错”的误差爆炸问题,加快模型的收敛速度。
-
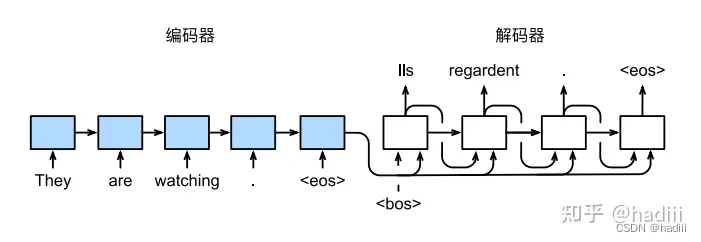
预测:每个解码器当前时间步的输入都是来自前一个时间步的预测词元。与训练过程类似,序列开始词元(“”)在初始时间步被输入到解码器中。预测过程会一直进行,直到输出序列的预测遇到序列结束词元(“”),此时预测过程结束。
-
-
评估:BLEU是?种常用的评估?法,它通过测量预测序列和标签序列之间的n元语法的匹配度来评估预测。
-
贪心搜索:在每个时间步,贪心搜索选择具有最?条件概率的词元。贪心搜索的计算量为 O ( ∣ Y ∣ T ′ ) O(|Y| T ^′ ) O(∣Y∣T′)。

-
穷举搜素:穷举地列举所有可能的输出序列及其条件概率,然后计算输出条件概率最?的?个。穷举搜索的计算量为 O ( ∣ Y ∣ T ′ ) O(|Y|^{T'}) O(∣Y∣T′)。
-
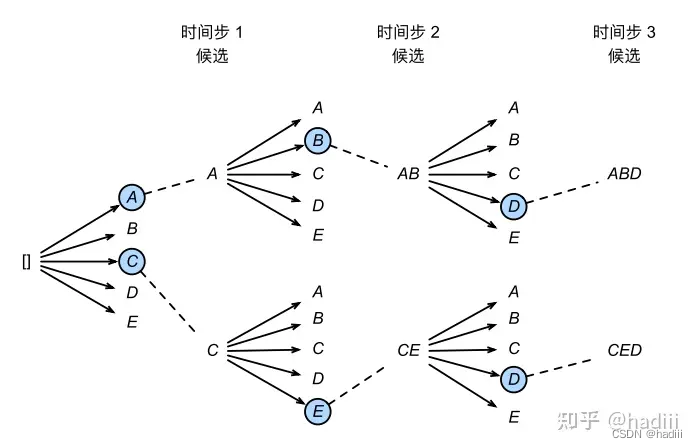
束搜素:束搜索是贪心搜索的一个改进版本。它有一个超参数,名为束宽k。在时间步1,我们选择具有最高条件概率的k个词元。这k个词元将分别是k个候选输出序列的第一个词元。在随后的每个时间步,基于上一个时间步的k个候选输出序列,我们将继续从k |Y|个可能的选择中挑出具有最高条件概率的k个候选输出序列。 束搜素的计算量为 O ( k ∣ Y ∣ T ′ ) O(k |Y| T ′ ) O(k∣Y∣T′)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!