docker swarm 常用命令简介以及使用案例
docker swarm
Docker Swarm 是Docker官?的跨节点的容器编排?具。?户只需要在单?的管理节点上操作,即可管理集群下的所有节点和容器
解决的问题
- 解决docker server的集群化管理和部署
- Swarm通过对Docker宿主机上添加的标签信息来将宿主机资源进?细粒度分区,通过分区来帮助?户将容器部署到?标宿主机上,同样通过分区?式还能提供更多的资源调度策略扩展。
单机模式
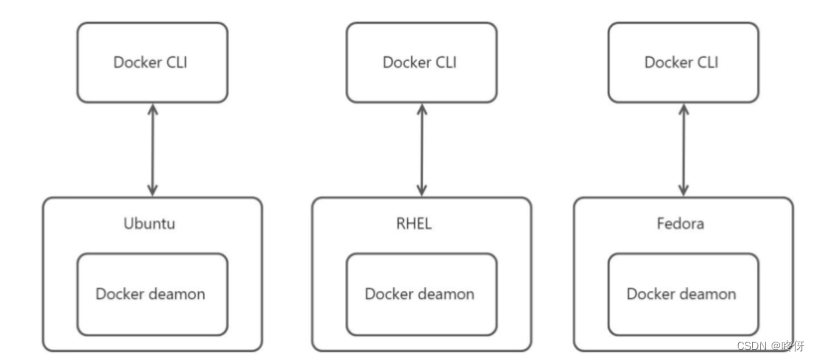
swarm模式
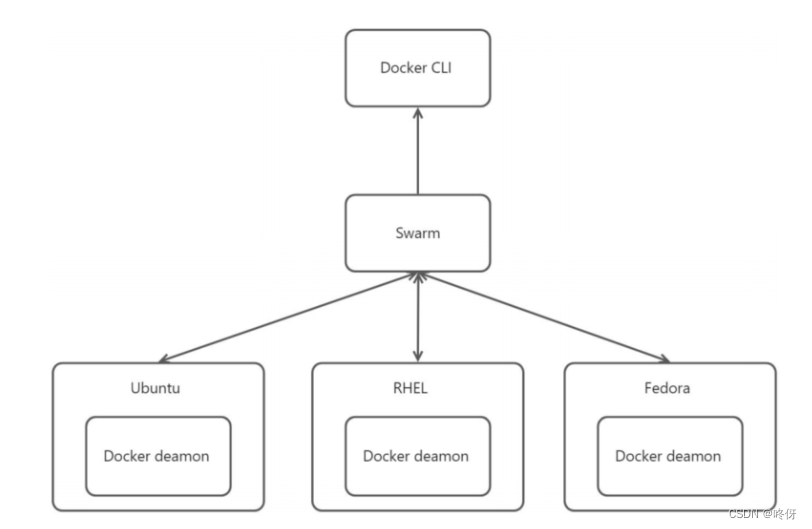
能做什么
- 管理节点?可?,原??持管理节点?可?,采?raft共识算法来?撑管理节点?可?
- 应?程序?可?,?持服务伸缩,滚动更新和应?回滚等部署策略
相关概念
-
docker的两种模式,单引擎模式和swarm集群模式
-
单引擎模式,之docker server没有加?任何集群,且?身也没有加?初始化为swarm 节点,简单的说就我我们平时所操作的孤?的docker server。
-
swarm模式,当docker server 加?到任意swarm集群,或者通过docker swarm init初始化swarm集群时,docker server会?动切换到swarm 集群模式。
-
-
swarm集群中节点分类,分为:manager(管理节点)、node(?作节点)
- manager:是Swarm Daemon?作的节点,包含了调度器、路由、服务发现等功能,负责接收客户端的集群管理请求以及调度Node进?具体?作。manager 本身也是?个node节点
- Node:接受manager调度,对容器进?创建、扩容和销毁等具体操作。
-
raft共识算法,是实现分布式共识的?种算法,主要?来管理?志复制的?致性。(实现manager节点存储相同一致性状态)
当Docker引擎在swarm模式下运?时,manager节点实现Raft?致性算法来管理全局集群状态。Docker swarm模式之所以使??致性算法,是为了确保集群中负责管理和调度任务的所有manager节点都存储相同的?致状态。
在整个集群中具有相同的?致状态意味着,如果出现故障,任何管理器节点都可以拾取任务并将服务恢复到稳定状态。例如,如果负责在集群中调度任务的领导管理器意外死亡,则任何其他管理器都可以选择调度任务并重新平衡任务以匹配所需状态。
使??致性算法在分布式系统中复制?志的系统需要特别??。它们通过要求?多数节点在值上达成?致,确保集群状态在出现故障时保持?致。
Raft最多可承受(N-1)/2次故障,需要(N/2)+1名成员的多数或法定?数才能就向集群提议的值达成?致。这意味着,在运?Raft的5个管理器集群中,如果3个节点不可?,系统将?法处理更多的请求来安排其他任务。现有任务保持运?,但如果管理器集不正常,调度程序?法重新平衡任务以应对故障。
-
Swarm管理节点?可?
- Swarm管理节点内置有对HA的?持,即使有?个或多个节点发送故障,剩余管理节点也会继续保证Swarm运转
- Swarm实现了?种主从?式的多管理节点的HA,即使有多个管理节点也只有?个节点出于活动状态,处于活动状态的节点被称为主节点(leader),?主节点也是唯??个会对Swarm发送控制命令的节点,如果?个备?管理节点接收到了Swarm命令,则它会将其转发给主节点
集群管理
创建集群
- 不包含在任何Swarm中的Docker节点,该Docker节点被称为运?于单引擎(Single-Engine)模式,?旦加?Swarm集群,则切换为Swarm模式
- docker swarm init 会通知Docker来初始化?个新的Swarm,并且将?身设置为第?个管理节点。同时也会使该节点开启Swarm模式
- –advertise-addr IP:2377 指定其他节点?来连接到当前管理节点的IP和端?,这?指令是可选的,当节点有多个IP时,可以指定其中?个
- –listen-addr 指定?于承载Swarm流量的IP和端?,其设置通常与–advertise-addr相匹配,但是当节点上有多个IP的时候,可?于指定具体某个IP
- –autolock 启?管理器?动锁定(需要解锁密钥才能启动已停?的管理器)
- –force-new-cluster 强制从当前状态创建新群集
docker swarm init
talenty@k8smaster:~$ docker swarm init
Swarm initialized: current node (h799byvplbyoo7ic7wgtl2x0t) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-4cn3m0nzkdi3flts2hojqcww4ez52xgx6saaygq38oz8actthz-5qe4s1sigc486wyk3diqvk8my 192.168.22.130:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
将节点加入集群
docker swarm join --token SWMTKN-1-4cn3m0nzkdi3flts2hojqcww4ez52xgx6saaygq38oz8actthz-5qe4s1sigc486wyk3diqvk8my 192.168.22.130:2377
#或者
# ?成work节点 join-token
docker swarm join-token worker
# ?成manager节点 join-token
docker swarm join-token manager
# 此命令为 join-token 命令执?结果,在相应的节点执?该结果即可加?到集群
docker swarm join --token SWMTKN-1-36o8i823751vozwd75mpzgsy28h4ti93zbn4o9wht8kywj35ir-6zh4id2t0ck4on4oyw95xs3cs 192.168.22.130:2377
查看集群状态
docker info
将节点从集群中移除
# 将节点从集群中移除 (只能移除worker节点)
docker swarm leave
# 将节点从集群中强制移除(包括manager节点)
docker swarm leave -f
更新集群
# 更新集群的部分参数
docker swarm update --autolock=false
锁定/解锁集群
- 重启?个旧的管理节点或者进?备份恢复可能对集群造成影响,?个旧的管理节点重新接?Swarm会?动解密并获得Raft数据库中?时间序列的访问权,这会带来安全隐患。进?备份恢复可能会抹掉最新的Swarm配置
- 为了规避上述问题,Docker提供?动锁机制来锁定Swarm,这会强制要求重启的管理节点在提供个集群解锁码之后才有权重新接?集群(也可以防?原来的主节点宕机后快速的重新接?集群,和当前主节点?起成为双主,双主也是?种脑裂问题)
# 设置为?动锁定集群
docker swarm update --autolock=true
# 当集群设置为 --autolock后,可以通过该命令查询解锁集群的秘钥
# 如果该节点必须为集群有效的管理节点
docker swarm unlock-key
# 重启管理节点,集群将被?动锁定
service docker restart
# 重启后的管理节点必须提供解锁码后才能重新接?集群
docker swarm unlock
节点管理
docker node -h
# 降级节点
demote Demote one or more nodes from manager in the swarm
# 查看节点详情
inspect Display detailed information on one or more nodes
# 查看所有节点
ls List nodes in the swarm
# 升级节点
promote Promote one or more nodes to manager in the swarm
# 查看节点上运?的任务,默认当前节点
ps List tasks running on one or more nodes, defaults to current node
# 删除节点
rm Remove one or more nodes from the swarm
# 更新节点
update Update a node
查看集群节点列表
docker node ls 1
升级或降级节点
# 降级?个或多个节点
docker node demote <NODE>
# 通过修改单个节点的role属性,来降级节点
docker node update --role worker <NODE>
# 升级?个或多个节点
docker node promote <NODE>
# 通过修改单个节点的role属性,来升级节点
docker node update --role manager <NODE>
更改节点状态
# 更改节点状态
docker node update --availability active|pause|drain <NODE>
# active: 正常
# pause:挂起
# drain:排除
- 正常节点,可正常部署应?
- 挂起节点,已经部署的应?不会发?变化,新应?将不会部署到该节点
- 排除节点,已经部署在该节点的应?会被调度到其他节点
删除节点
# 只能删除已关闭服务的?作节点
docker node rm <node>
# 只能强制删除?作节点
docker node rm -f <node>
管理节点的删除只能先将管理节点降级为?作节点,再执?删除动作
# 停?docker server
sudo service docker stop
服务管理
常用命令
docker service -h
# 创建?个服务
create Create a new service
# 查看服务详细信息
inspect Display detailed information on one or more services
# 查看服务?志
logs Fetch the logs of a service or task
# 列出所有服务
ls List services
# 列出?个或多个服务的任务列表
ps List the tasks of one or more services
# 删除?个或多个服务
rm Remove one or more services
# 回滚
rollback Revert changes to a service's configuration
# 弹性伸缩?个或多个服务
scale Scale one or multiple replicated services
# 更新服务
update Update a service
在集群上部署应用
随便准备一个gin服务代码打包的镜像
部署
docker service create --name myhello2 --publish published=8081,target=80 --replicas 2 webtestserver:v1
[root@localhost compose]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
pm43flv31rox myhello2 replicated 3/3 webtestserver:v1 *:8081->8088/tcp
查看服务下的任务
docker service ps myhello2
[root@localhost compose]# docker service ps myhello2
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
i9zpdeuuspft myhello2.1 webtestserver:v1 localhost.localdomain Running Running 4 hours ago
px1qtbnsi68u myhello2.2 webtestserver:v1 localhost.localdomain Running Running 4 hours ago
wz77u57rteo9 myhello2.3 webtestserver:v1 localhost.localdomain Running Running 4 hours ago
查看节点下的任务
docker node ps <NODE_ID>
[root@localhost compose]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
feo9ifozbs916w0usp9imsr03 * localhost.localdomain Ready Active Leader 24.0.7
[root@localhost compose]# docker node ps feo9ifozbs916w0usp9imsr03
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
i9zpdeuuspft myhello2.1 webtestserver:v1 localhost.localdomain Running Running 4 hours ago
px1qtbnsi68u myhello2.2 webtestserver:v1 localhost.localdomain Running Running 4 hours ago
wz77u57rteo9 myhello2.3 webtestserver:v1 localhost.localdomain Running Running 4 hours ago
访问集群中任意节点(包括没有运?任务的节点)对应的端?号均能访问到应?程序,swarm为集群实现了负载均衡
查看service详细信息
docker service inspect myhello2
查看service日志
docker service logs myhello2
伸缩服务
docker service scale myhello2=5
修改节点状态,查看任务部署情况
docker node update --availability active|pause|drain <NODE_ID>
部署一个个带更新策略和回滚策略的应?
docker service create \
--name myhello3 \
--publish published=8081,target=8088 \
--replicas 20 \
--update-delay 5s \
--update-parallelism 2 \
--update-failure-action continue \
--rollback-parallelism 2 \
--rollback-monitor 10s \
--rollback-max-failure-ratio 0.2 \
webtestserver:v1
#--update-delay 5s :每个容器依次更新,间隔5s
# --update-parallelism 2 : 每次允许两个服务?起更新
#--update-failure-action continue : 更新失败后的动作是继续
# --rollback-parallelism 2 : 回滚时允许两个?起
# --rollback-monitor 10s :回滚监控时间10s
# --rollback-max-failure-ratio 0.2 : 回滚失败率20%
检查部署后的应?设置项是否都有被成功设置
# 查看并打印友好的详细信息
docker service inspect --pretty myhello3
更新未设置成功的项
docker service update --update-delay 5s --rollback-monitor 10s myhello3
更新服务
打包一个新版本
docker service update --image webtestserver:v2 myhello3
回滚服务
docker service update --rollback myhello3
结合docker-copose.yml部署
部署命令
# 部署或更新 stack
deploy Deploy a new stack or update an existing stack
# 查看 stack 列表
ls List stacks
# 查看 stack 的任务列表
ps List the tasks in the stack
# 删除 stack
rm Remove one or more stacks
# 查看stack 中的服务列表
services List the services in the stack
docker-compose.yml
version: "3.7"
services:
myhello2:
image: webtestserver:v1
ports:
- "8081:8088"
# 依赖服务redis
depends_on:
- redis
#部署参数
deploy:
mode: replicated
replicas: 20
endpoint_mode: vip
rollback_config:
parallelism: 2
delay: 10s
monitor: 10s
max_failure_ratio: 0.2
update_config:
parallelism: 2
delay: 5s
failure_action: continue
redis:
image: redis:alpine
deploy:
mode: replicated
replicas: 6
endpoint_mode: dnsrr
labels:
description: "This redis service label"
resources:
limits:
cpus: '0.50'
memory: 50M
reservations:
cpus: '0.25'
memory: 20M
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
部署stack(部署一堆容器)
docker stack deploy -c docker-compose.yml mystack
查看服务详情
# 查看并打印友好的详细信息
docker service inspect --pretty mystack_myhello2
docker service inspect --pretty mystack_redis
配置说明
配置说明
endpoint_mode:访问集群服务的?式。
endpoint_mode: vip
# Docker 集群服务?个对外的虚拟 ip。所有的请求都会通过这个虚拟 ip 到达集群服务内部的
机器。
endpoint_mode: dnsrr
# DNS 轮询(DNSRR)。所有的请求会?动轮询获取到集群 ip 列表中的?个 ip 地址。
labels:在服务上设置标签。可以?容器上的 labels(跟 deploy 同级的配置) 覆盖 deploy 下的 labels。
mode:指定服务提供的模式。
replicated:复制服务,复制指定服务到集群的机器上。
global:全局服务,服务将部署?集群的每个节点。
replicas:mode 为 replicated 时,需要使?此参数配置具体运?的节点数量。
resources:配置服务器资源使?的限制,例如上例?,配置 redis 集群运?需要的 cpu 的百分? 和 内存的占?。避免
占?资源过?出现异常。
restart_policy:配置如何在退出容器时重新启动容器。
condition:可选 none,on-failure 或者 any(默认值:any)。
delay:设置多久之后重启(默认值:0)。
max_attempts:尝试重新启动容器的次数,超出次数,则不再尝试(默认值:?直重试)。
window:设置容器重启超时时间(默认值:0)。
rollback_config:配置在更新失败的情况下应如何回滚服务。
parallelism:?次要回滚的容器数。如果设置为0,则所有容器将同时回滚。
delay:每个容器组回滚之间等待的时间(默认为0s)。
failure_action:如果回滚失败,该怎么办。其中?个 continue 或者 pause(默认pause)。
monitor:每个容器更新后,持续观察是否失败了的时间 (ns|us|ms|s|m|h)(默认为0s)。
max_failure_ratio:在回滚期间可以容忍的故障率(默认为0)。
order:回滚期间的操作顺序。其中?个 stop-first(串?回滚),或者 start-first(并?回滚)(默认 stop-first )。
update_config:配置应如何更新服务,对于配置滚动更新很有?。
parallelism:?次更新的容器数。
delay:在更新?组容器之间等待的时间。
failure_action:如果更新失败,该怎么办。其中?个 continue,rollback 或者pause (默认:pause)。
monitor:每个容器更新后,持续观察是否失败了的时间 (ns|us|ms|s|m|h)(默认为0s)。
max_failure_ratio:在更新过程中可以容忍的故障率。
order:回滚期间的操作顺序。其中?个 stop-first(串?回滚),或者 start-first(并?回滚)(默认stop-
first)。
注:仅?持 V3.4 及更?版本
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!