java面试题-mysql索引相关问题
远离八股文,面试大白话,通俗且易懂
看完后试着用自己的话复述出来。有问题请指出,有需要帮助理解的或者遇到的真实面试题不知道怎么总结的也请评论中写出来,大家一起解决。
这一块本想着晚一点再整理,因为我怕我自己也讲不明白,但是最近确实很多人说自己面试遇到了,很难讲清楚,所以还是整理了一下,感觉能很顺畅的读懂后决定发出来给大家看一下。
这一章决定讲的详细一点。所以大家最好仔细读一下
1.索引介绍

首先,从navicat创建索引的界面中?可以看到,索引的组成就是
索引名称、对应的字段、索引类型、索引方法、注释
众所周知,索引会使得查询速度变快,所以引出第一个问题
索引为什么会这么快?
答:首先,mysql在查询一张表的时候,如果这张表没有索引,那么查询语句需要在磁盘上将该表的数据一条一条的扫描,然后每一列都需要进行判断后选取符合条件的结果集进行返回。
但是加了索引之后,就相当于给mysql表添加了一个目录一样,如果此时你的查询条件中刚好有索引字段,那么mysql在查询的时候就会先去查询这个索引目录,然后在符合条件的结果集中再去对其他条件进行筛选。这样就会使得扫描的数据大幅度减少,从而提高效率。
同时呢,索引还具有有序性,简言之就是像新华字典一样,相同类型的数据存储在一起,这样就会使得排序、分组等等聚合操作变得更加快。
2.索引类型
针对mysql索引类型,我这边只谈一些常用的,因为工作这么久一些索引类型虽然有所耳闻但是基本没有使用过,所以在平时的工作或者面试中完全足够应付。
?1.按照字段特性划分
(主键索引、唯一索引、全文索引、普通索引)
1.主键索引:这个大家最熟悉,就是mysql表的主键,一张表只有一个,但是不能为空,不能重复
2.唯一索引:针对某一字段创建,保证数据的唯一性,但是可以为空
3.全文索引:这个大家知道就行,全文索引主要是用来进行文章等分词检索的,比如这个字段中存了一篇长文,你要查询是否包含某个单词,就可以使用这个索引。他会根据配置将这个整篇文章分成比如两个字或者三个字的或者其他字数的单词跟你的关键字进行匹配。但是因为现在ES索引数据库做的比较好,所以这个用处不大。
4.普通索引:就是我们常用的索引,可以为空,可以重复
2.按照物理存储划分
(聚簇索引、非聚簇索引)
这个也是经常被问到,因为涉及到存储方式B+树,后面描述,这里用大白话描述一下。
1.聚簇索引:其实也就是主键索引,一张表中只有一个,因为我们知道创建索引就是在磁盘中开辟空间存储索引信息。聚簇索引是将索引和数据放在一起了,就相当于我们找到了这个索引,就找到了这个索引对应的数据行。所以,数据库中主键查询一般都很快。
2.非聚簇索引:我们创建的普通索引都属于非聚簇索引,一张表中可以创建多个,通过名字也能看出。就是索引的位置和数据的位置是分开存储的,我们通过查询索引的位置,确定索引后还需要根据索引再去另一片空间上去查找索引对应的数据。
(通俗来讲:就是我们查字典的时候,首先翻目录,结果我们在目录中很快的找到了一个字,突然发现这个字的后就是对应的解释,这就叫做聚簇索引。而如果我们查字典,在目录中找到一个字,但是后面什么都没有只有对应的页码,我们还需要根据页码再去找对应的解释,这个叫做非聚簇索引)
3.按照字段个数划分
(单列索引、组合索引)
1.单列索引:如果这个索引对应的列只有一个,那就是单列索引
2.组合索引:显而易见,一个索引名称对应多个字段。使用场景就是比如你一个查询业务中,如果两个条件或是三个条件每次都是搭配使用(固定搭配)这样就可以建立一个组合索引,而不需要建立三个单独的,可以一定程度上减少磁盘存储空间(一个索引和三个索引占用的空间还是不同的)
需要注意的是:组合索引必须坚持最左原则
比如:你的索引是name+age+sex;如果你的查询条件中没有name,那么索引就会失效。很重要!!!!!
3.索引方法

可以看到主要就是B+TREE索引和HASH索引
但是项目中我猜测大家基本见过的都是BTREE索引,下面看下具体原因
1.Hash索引。首先hash我们很容易联想到java中的hashmap,根据这一特点我们可以总结出来hash索引的一个特点:
hash索引也是根据hashcode进行存储,数据是无序的,所以你就没有办法进行范围搜索。同时排序也成了一个大的难题。这就导致hash索引使用场景并不多。但是既然存在就肯定有用处,hash的特性也就造成了hash索引对于等值查询的效率非常高,如果你的查询条件中是=、in、!=的时候,这个场景才是hash索引的价值所在。
2.B+tree
这个描述大家看一下是否能看懂,我能理解但是可能不能很好的表达。建议多查一查B+TREE原理
首先需要了解二叉树,二叉树的查询很方便,但是对于数据量大的情况下,你的二叉树也相应的会变大,所以只采用了二叉树的理念。
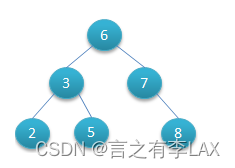
上图就是一个二叉树,他的规律就是每个节点连线的左侧肯定比自己小:比如2<3,3<5,3<6,6<7..
右侧肯定比左侧大:8>7、5>3? ...这样就比较方便进行二分查找或者范围查找,如果条件得当直接省略一半的查询时间。
?
但是二叉树只在节点上存一个关键字。所以效率相对并不高。
于是B+TREE就引入了每个节点可以存储多个数据。也就是刚开始就一个节点,不断的往里存数据,如果达到一定数量就开始分裂,同时遵循二叉树原则,是有序的。图中的圆圈都代表索引节点,他们每一个都对应着叶子节点。所有的叶子节点是根据顺序相连接的形成一个链表,这样就方便进行范围查询。
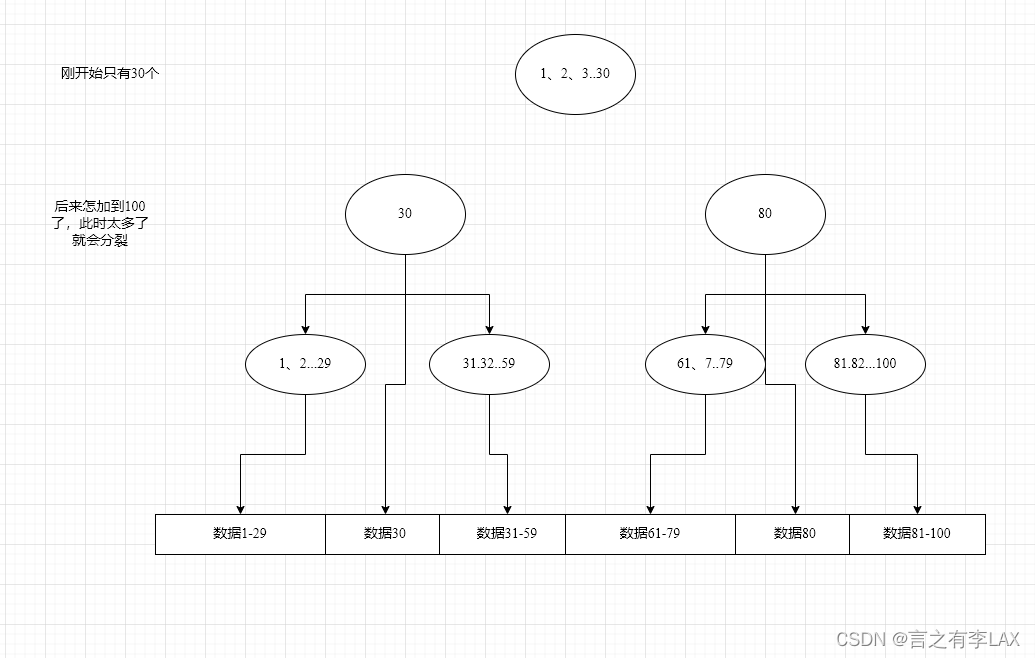
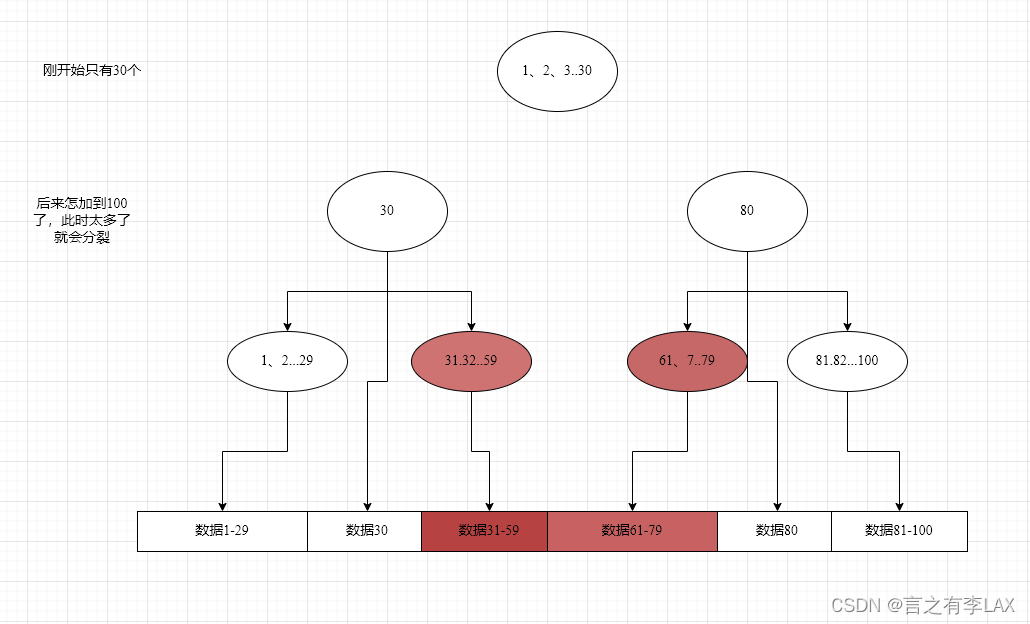
比如:我要查询40-70的数据,则直接通过下图的两个节点就可以直接确认。
4.索引失效的场景
- 使用or?关键字?即使左侧是索引??但是右侧不是索引则会失效
- where?中以%?开头的
- 索引字段变成表达式的时候??id+1?=?2??应该是id?=?3
- 组合索引违背最左原则,当查询条件中没有第一个组合索引的字段(name)会导致索引失效
以上:根据自己的话做下总结,能讲出这些来足够应付大部分mysql索引面试了,但是如果更为详细的DB面试可能还不够,还需在深耕。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!