ShardingSphere数据分片之分表操作

1、概述
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
ShardingShpere的两个核心模块:
- ShardingSphere-JDBC:ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。
- ShardingSphere-Proxy:ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。
在开发中实现分库分表的操作,我们一般使用的ShardingSphere-JDBC这个模块。
具体详情请参考官网:https://shardingsphere.apache.org/document/current/cn/overview/
说实话,看这个官网需要一定的编码功底,懂的都懂。😄
ShardingSphere的分库分表操作的逻辑图:
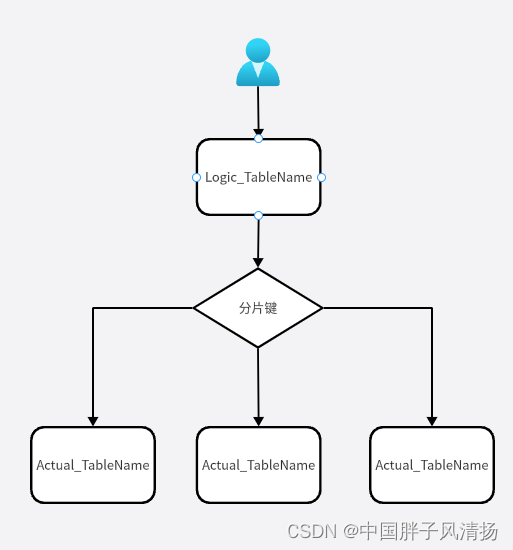
开发者配置了分库分表策略后,我们只需要操作逻辑表名就可以了。
2、数据分片带来的优缺点
数据分片主要是用来解决海量的数据访问的问题,将数据库采用垂直拆分或者水平拆分的方式将海量、复杂的数据分布到不同的数据库、数据表中,以此来实现专库专用、提高访问性能。
优点:
- 提高可扩展性:通过将数据拆分成多个小型数据库,每个数据库仅处理一部分数据,可以在数据增长时动态地添加新的分片,从而提高整个系统的可扩展性。
- 提升性能:分片后的每个小型数据库只处理部分数据,减轻了单个节点的压力,从而提升了整个系统的性能。
缺点:
- 复杂性增加:数据分片意味着需要更多的数据库来存储和管理数据,这增加了系统的复杂性。同时,对于每个查询,可能需要跨多个数据库进行查找,增加了查询的复杂性。
- 并发控制:在分布式系统中,并发控制是一个重要的问题。如果多个节点同时更新同一片数据,就可能导致数据不一致的问题。因此,需要采用并发控制技术来保证数据的正确性。
- 数据迁移和恢复:当新增或删除分片时,需要进行数据迁移和恢复。这个过程可能会导致数据的不一致或丢失。因此,需要设计合理的迁移和恢复策略来保证数据的正确性。
我们所使用ShardingSphere组件,通过配置Yaml文件来降低我们的编码复杂度。并发控制何数据迁移与恢复都是需要其他的方式来解决。
3、ShardingSphere分表操作
ShardingSphere的分库分表操作都是基于ShardingSphere-JDBC这个模块来实现。在当前开发中一般都需要和Springboot进行整合,而且只要是流行的框架、组件,SpringBoot一般都会有一个集成的依赖。
3.1、依赖
当前JDK已经到了21,当然我这里使用的还是JDK17,因为JDK21对于SpringBoot 3.1 以下的版本都不友好,会出现一个错误,所以今年刚出的JDK21可以作为爱好先了解,毕竟刚出来很多东西都还需要完善。
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.7.14</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.4.1</version>
</dependency>
3.2、操作方式一:Yaml文件配置
在引入了ShardingSphere-JDBC模块后,可以通过YAML文件配置的方式轻松的配置分表操作。
spring:
shardingsphere:
props:
sql-show: true # 是否展示ShardingSphere的SQL日志
datasource: # 配置数据源
ds0:
username: root
password: 123456
url: jdbc:mysql://127.0.0.1:3306/mysql_test?serverTimezone=Asia/Shanghai
type: com.zaxxer.hikari.HikariDataSource # 这个参数是必须要有的,否则会报错。
driver-class-name: com.mysql.cj.jdbc.Driver
names: ds0 # 所有数据源的名称,用逗号隔开
rules: # ShardingSphere规则
sharding:
sharding-algorithms: # 分片算法配置
table-inline: # 分片算法名称,自定义的名称
type: INLINE # 分片算法类型
props: # 分片算法属性配置
algorithm-expression: test_$->{id % 2} # 分片规则指定语句
tables: # 分片表配置
logic_table_name: # 自定义的逻辑表名称
actual-data-nodes: ds0.test_0, ds0.test_1 # 真实的表名称,数据源.表名称,多个表之间用逗号隔开,也支持表达式:ds0.test_$->{0..1}
table-strategy: # 表分片策略
standard: # 标准分片策略
sharding-column: id # 分片的列名
sharding-algorithm-name: table-inline # 分片算法
mode:
type: Memory # 运行模式类型。可选配置:内存模式 Memory、单机模式 Standalone、集群模式 Cluster
repository:
type: JDBC
在YAML文件中通过rules.sharding.sharding-algorithms属性来配置数据分片的分片方式,比如说test_$->{id % 2},这个就是按照奇偶的方式对数据进行划分数据。
在rules.sharding.sharding-algorithms.type参数主要用于指定分片算法的类型。以下是一些常见的 type 选项:
| 参数名称 | 参数描述 |
|---|---|
| inline | 行表达式分片算法。该算法允许你使用行表达式来定义分片规则,适用于简单的分片场景。 |
| hint | Hint 分片算法。该算法允许你使用 Hint 来指定分片规则,适用于一些特殊的分片场景。 |
| mod_sharding | 取模分片算法。根据指定的分片数量进行取模运算来进行分片,例如 user_id % 8 |
| range_sharding | 范围分片算法。允许你定义一个范围来进行分片,适用于范围查询等场景。 |
| hash_sharding | 哈希分片算法。根据指定的哈希算法进行分片,适用于一些需要一致性哈希的场景。 |
rules.sharding.tables.<logic_table_name>.table-strategy参数用来配置表分片的策略,可配置的属性如下:
1、standard:标准分片策略。
| 参数名称 | 参数描述 |
|---|---|
| sharding-column | 分片列名称 |
| precise-algorithm-class-name | 精确分片算法类名称,用于 = 和 IN 查询。 |
| range-algorithm-class-name | 范围分片算法类名称,用于 BETWEEN 查询。 |
2、complex:复合分片策略。
| 参数名称 | 参数描述 |
|---|---|
| sharding-columns | 分片列名称列表,多个列以逗号分隔。 |
| algorithm-class-name | 复合分片算法类名称。 |
3、inline:行表达式分片策略。
| 参数名称 | 参数描述 |
|---|---|
| sharding-column | 分片列名称。 |
| algorithm-expression | 分片算法行表达式,例如:${column} % 2。 |
4、hint:Hint 分片策略。
| 参数名称 | 参数描述 |
|---|---|
| algorithm-class-name | Hint分片算法类名称。 |
3.3、操作方式二:自定义分片算法
使用YAML文件的配置只能用于简单的分表配置,像test_0,test_1这种简单的,而像某些表名不同的复杂分表操作就不方便使用YAML的配置方式了,此时就需要使用自定义分片策略。
3.3.1、实现StandardShardingAlgorithm接口
自定义分表策略需要实现StandardShardingAlgorithm接口。通过doSharding方法来返回要操作的真实表名。
public class TestShardingAlgorithm implements StandardShardingAlgorithm<Integer> {
private static Object[] TABLE_NAME_LIST = null;
/**
* 实现精确分片
* @param collection yaml中定义的真实的表名列表
* @param preciseShardingValue 分片的信息
* 1、getColumnName(): 获取分片策略中的sharding-column参数的值
* 2、getValue(): sharding-column参数所对应类的值
* @return 真正需要执行的表名
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Integer> preciseShardingValue) {
if(TABLE_NAME_LIST == null){
TABLE_NAME_LIST = collection.toArray();
}
int index = preciseShardingValue.getValue() % TABLE_NAME_LIST.length;
return (String) TABLE_NAME_LIST[index];
}
// 实现范围分片
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Integer> rangeShardingValue) {
return collection;
}
@Override
public void init() {
// 进行初始化的配置
}
// 分片策略的 key
@Override
public String getType() {
return "TestShardingAlgorithm";
}
}
在单体系统中,doSharding和getType两个方法是必须要编写的,ShardingSphere会根据这两个方法来调用分表策略。
我们也可以使用这种方式来实现动态分表策略,将需要分表的表名存放在一张表中,每次的操作都会进行数据库的访问来确定需要操作的表。存储媒介不光是数据库,还可以是Nacos、Zookeeper等。
3.3.2、配置Yaml文件
spring:
shardingsphere:
props:
sql-show: true
datasource:
ds0:
username: root
password: 123456
url: jdbc:mysql://127.0.0.1:3306/mysql_test?serverTimezone=Asia/Shanghai
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
names: ds0
rules:
sharding:
sharding-algorithms:
table-inline:
type: TestShardingAlgorithm
props:
algorithm-class-name: com.tt.shardingpheredemo.config.TestShardingAlgorithm
tables:
t_user:
actual-data-nodes: ds0.test_0, ds0.test_1
# 分表策略
table-strategy:
standard:
sharding-column: id
sharding-algorithm-name: table-inline
mode:
type: Memory
repository:
type: JDBC
main:
banner-mode: off
自定义分片策略的引入需要修改rules.sharding.sharding-algorithms参数中的type和props.algorithm-class-name两个参数。
type参数的值一定要是自定义策略类中的getType()返回值。
3.3.3、配置分片类载入文件
当我们完成上述的操作后,按照逻辑来说是没问题了的,但是,世事有例外😏,启动项目的时候直接报错:
No implementation class load from SPI `org.apache.shardingsphere.sharding.spi.ShardingAlgorithm` with type `TestShardingAlgorithm`.
如果type这个参数不是和getType()方法的值一致,也会报这个错误。
报这个错误的原因是TestShardingAlgorithm这个类没有被加载进程序,ShardingSphere的底层基于Java SPI机制。
我们不妨来看看StandardShardingAlgorithm其他的实现类是如何实现的。
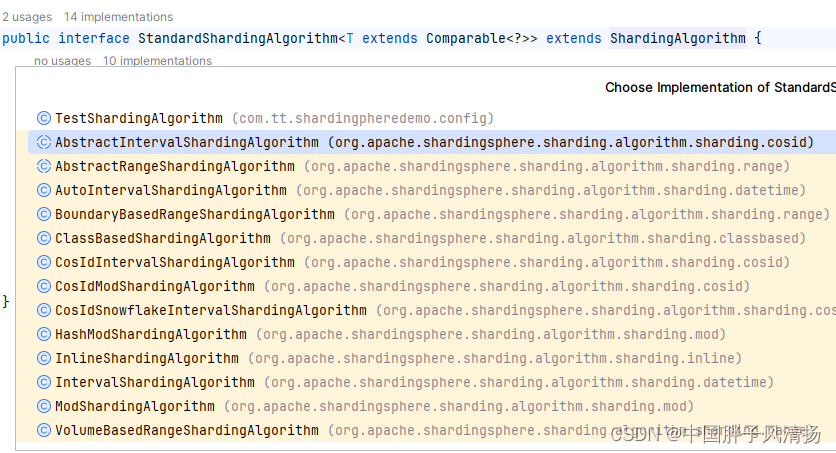
StandardShardingAlgorithm的实现类还是不少的,其中就有上面说的几种分片策略。
在ShardingSphere的源码中,我们看到这几种分片策略都不是通过SpringBoot的注入方式来加载入项目的,而是通过SPI机制来加载入项目,在源码中有一个org.apache.shardingsphere.sharding.spi.ShardingAlgorithm文件,这个文件存放着ShardingSphere所提供的分片策略方式。
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.mod.ModShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.mod.HashModShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.range.VolumeBasedRangeShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.range.BoundaryBasedRangeShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.datetime.AutoIntervalShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.datetime.IntervalShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.classbased.ClassBasedShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.complex.ComplexInlineShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.hint.HintInlineShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.cosid.CosIdModShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.cosid.CosIdIntervalShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.cosid.CosIdSnowflakeIntervalShardingAlgorithm
所以我们想要使用自定义的分片策略,那么就要使用源码中的方式将自定义的分片策略类加载入系统,使用Spring Boot的@Component方式是没有用的。
我们需要在项目的resources目录下创建一个同名的properties文件,来存放自定义的分片策略类的全限定名。
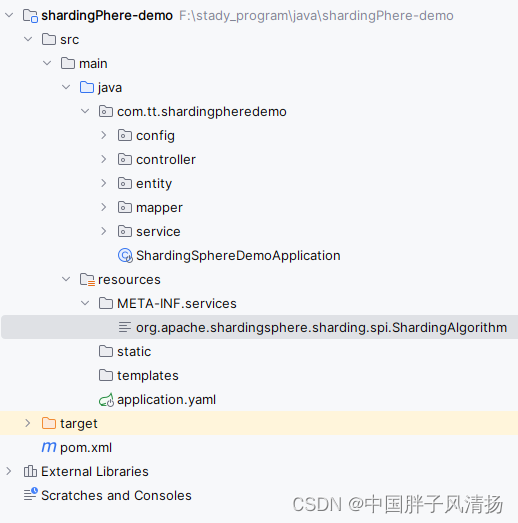
org.apache.shardingsphere.sharding.spi.ShardingAlgorithm文件一定要在META_INF.services目录下,因为源码中的文件就在这个目录下。
3.4、测试
3.4.1、实体类配置
因为系统中集成了Mybatis-plus这个组件,所以在编码上也会轻松很多,Dao层、Service层都和日常开发一样的,唯一不同的就是Entity上。
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName(value = "logic_table_name")
public class Test{
@TableId(type = IdType.AUTO)
private int id;
private String testName;
private int abc;
}
实体类的主要不同就在于@TableName的value值。
value值不再指向的是数据库中的真实表名,而是指向ShardingSphere配置中的逻辑表名。
3.4.2、数据库
两张表:test_1和test_1。
CREATE TABLE `test_0` (
`id` int NOT NULL AUTO_INCREMENT,
`test_name` varchar(255) NOT NULL,
`abc` int NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE TABLE `test_1` (
`id` int NOT NULL AUTO_INCREMENT,
`test_name` varchar(255) NOT NULL,
`abc` int NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
3.4.3、测试结果
本次测试采用奇偶分片策略,分片键为id。
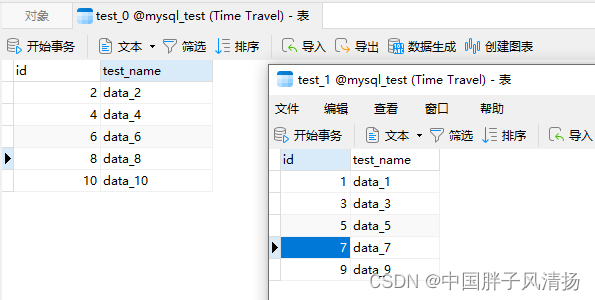
test_0表中存放了id为偶数的数据,test_1表中存放了id为奇数的数据。
4、总结
ShardingSphere虽然支持市面上大部分的分库分表方式,也是市面上当前最火的分库分表组件之一,但是:
- ShardingSphere的配置相对复杂,需要用户具备一定的数据库和中间件知识。配置过程中需要考虑分片键的选择、分片算法的设计、数据的迁移等因素,这些都需要用户进行深入的思考和规划。
- 学习成本高:由于ShardingSphere是一个相对复杂的系统,用户需要花费一定的时间和精力来学习它的原理、配置和使用方法。这对于一些新手来说可能是一个挑战。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!