阿里面试:说说Rocketmq推模式、拉模式?
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题:
说说Rocketmq的推模式、拉模式?
这个题目,是非常常见的面试题,回答的时候, 有两个层面
- 第一个层面:应用开发层
- 第二个层面:底层源码层
关于Rocketmq 的核心面试题,尼恩前面也梳理过几篇文章:
阿里面试:如何保证RocketMQ消息有序?如何解决RocketMQ消息积压?
这里,又新增一个核心面试的答案,“说说Rocketmq的推模式、拉模式?”。
这些文章,在底层都是相同的。帮助大家从Rocketmq源码层去解答,那就更加让面试官 “不能自已、口水直流、震惊不已”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V158版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】获取
文章目录
经典的推模式/拉模式
首先,明确一下业务场景
这里谈论的推拉模式,指的是 Consumer 和 Broker 之间,不是 producer与broker之间。
经典的推模式
经典的推模式,指的是消息从 Broker 推向 Consumer。
Consumer 被动的接收消息,由 Broker 来主导消息的发送。作为代理人,Broker 接受完消息之后,可以立马推送给 Consumer。
Consumer等着就行,消息会有broker主动推过来。所以 Consumer 的处理策略很简单。
推模式的缺点: Consumer可能就“消化不良/OOM”。
当 Broker 推送消息的速率大于Consumer消费速率时,Consumer可能就“消化不良”,出现内存积压,内存溢出,OOM,因为根本消费不过来啊。
所以,经典的推模式,适用于消息量不大、Consumer消费能力强的场景。
经典的拉模式
经典的拉模式,指的是 Consumer 主动向 Broker 请求拉取消息。
上面讲到,经典的推模式,适用于消息量不大、Consumer消费能力强的场景。如果Consumer消费能力弱, 那么就改变方向好了, 由推改完拉。
拉的话,主动权就在Consumer身上了, 能消化多少,吃多少。
假设当前Consumer 消化不过来、消费不过来了,它可以根据一定的策略,暂停拉取甚至停止拉取,或者间隔拉取都行。
凡事有利必有弊。
拉模式的缺点:消息延迟+消息积压。 如果Consumer 隔个 2天采取拉取一批,消息就很有可能延迟,甚至出现严重的消息延迟。而且Broker 服务端大概率会消息积压。
推拉模式,如何选型?
选择推模式的消息队列中间件,主要有ActiveMQ
选择推模式的消息队列中间件,主要有RocketMQ 和 Kafka
虽然RocketMQ 和 Kafka都选择了拉模式。也就是允许消息延迟 + 允许消息积压。
所以,选择RocketMQ 和 Kafka,就需要做好消息积压的监控。
关于消息积压,参考答案请参见尼恩《技术自由圈》前面的一篇文章
阿里面试:如何保证RocketMQ消息有序?如何解决RocketMQ消息积压?
关于积压监控,请参考尼恩的 《Rocketmq 四部曲视频》,如果能够回答到上面的层次,已经非常牛掰了。
Rocketmq 的推模式和拉模式
Rocketmq 的客户端,也定义了两个模式: 推模式和拉模式
但是实际上,RocketMQ 中的 PushConsumer 推模式,仅仅是披着拉模式的方法,本质还是拉模式。
RocketMQ 中的 PushConsumer 推模式
接下来,我们首先看看RocketMQ 中的 PushConsumer 推模式。
这里,建议大家看看,尼恩的前面一篇文章:
惊呆:RocketMQ顺序消息,是“4把锁”实现的(顺序消费)
介绍了 RocketMQ 拉取消息的核心流程,具体如下图所示。
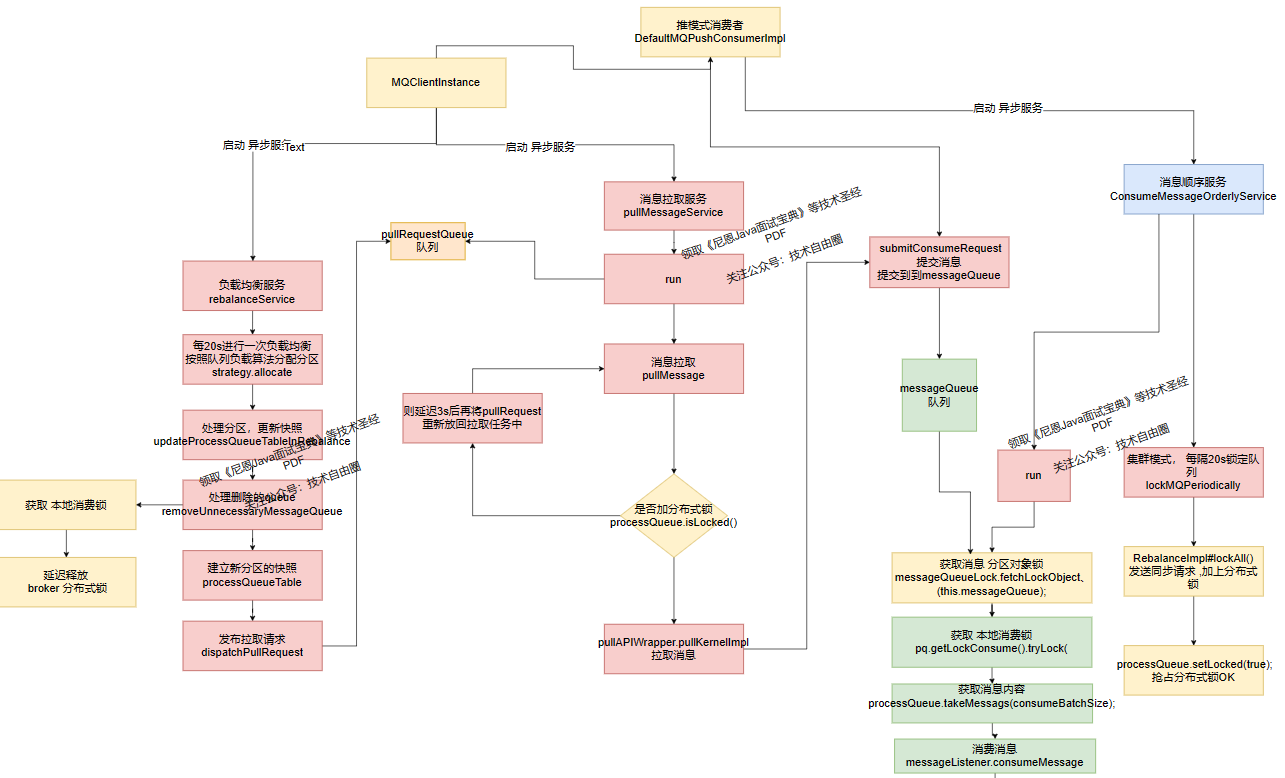
一个消费者至少需要涉及队列自动负载、消息拉取、消息消费、位点提交、消费重试等几个部分。
MQClientInstance 客户端实例,会开启多个异步并行服务:
-
负载均衡服务 rebalanceService :再平衡服务.
专门进行 queue分区的 再平衡,再分配,然后发布拉取消息的请求 pullRequest 实例。
-
消息拉取服务 pullMessageService:专门负责拉取消息。
从请求队列 pullRequestQueue 队列 获取一个一个的 pullRequest,
通过内部实现类DefaultMQPushConsumerImpl 拉取 消息。
注意,拉取的消息,放在另一个队列 messageQueue 缓存,拉取之前,会进行流控检查,如果这个队列满了(>1000个消息或者 >100M内存) 则延迟50ms再拉取, 当然,下一次执行拉取之前,同样也会进行流控检查
-
消息消费线程:ConsumeMessageOrderlyService 有序消息消费, 或者 并行消息。 从messageQueue 拉取消息,进行消费。
上面设计3类线程,在3类线程之间,通过两个队列进行 同步:
- 拉取消息的请求队列 pullRequestQueue
- 缓存消息的队列 messageQueue
Rocketmq 的推模式,本质是一种拉模式, 只是为了让客户端不会 累死, 在拉取之前进行流控。
具体请参见 尼恩 《Rocketmq 四部曲视频》配套的 注释版源码:
// 接下来就是消费者的拉取流量控制,阈值为 1000个消息, 或者 100M
// 消费者消费的太慢了,broker推送的太快了,进行 Flow control
if (cachedMessageCount > this.defaultMQPushConsumer.getPullThresholdForQueue()) {
// 将pullRequest放入队列,只不过是经过后台的定时线程池延50 ms 迟放入,进行 Flow control
// 流量控制, 减缓拉取消息的速度
// * Flow control threshold on queue level, each message queue will cache at most 1000 messages by default,
// * Consider the {@code pullBatchSize}, the instantaneous value may exceed the limit
// */
// private int pullThresholdForQueue = 1000;
this.executePullRequestLater(pullRequest, PULL_TIME_DELAY_MILLS_WHEN_FLOW_CONTROL);
if ((queueFlowControlTimes++ % 1000) == 0) {
log.warn(
"the cached message count exceeds the threshold {}, so do flow control, minOffset={}, maxOffset={}, count={}, size={} MiB, pullRequest={}, flowControlTimes={}",
this.defaultMQPushConsumer.getPullThresholdForQueue(), processQueue.getMsgTreeMap().firstKey(), processQueue.getMsgTreeMap().lastKey(), cachedMessageCount, cachedMessageSizeInMiB, pullRequest, queueFlowControlTimes);
}
return;
}
客户端没有消息怎么办呢?
上一节讲到, RocketMQ三类线程,相互配合: 在背后偷偷的帮我们去 Broker拉消息。
第一类线程 RebalanceService ,根据 topic 的队列数量和消费者个数做负载均衡,对于分配到queue 产生的 pullRequest拉取请求,并讲请求 队列 pullRequestQueue 中。
第二类线程 PullMessageService ,不断的pullRequestQueue队列 中获取 pullRequest,然后从 broker 拉取消息。
PullMessageService 把拉取请求,重新放进pullRequestQueue 队列, 大致的代码如下:
//broker 没有 新消息
case NO_NEW_MSG:
pullRequest.setNextOffset(pullResult.getNextBeginOffset());
DefaultMQPushConsumerImpl.this.correctTagsOffset(pullRequest);
// 把拉取请求,重新放进队列
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
break;
//broker 没有 匹配消息
case NO_MATCHED_MSG:
pullRequest.setNextOffset(pullResult.getNextBeginOffset());
DefaultMQPushConsumerImpl.this.correctTagsOffset(pullRequest);
// 把拉取请求,重新放进队列
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
那么,如果broker暂时没有消息,怎么办呢?
Broker 处理拉取消息命令的 处理器,叫做 PullMessageProcessor。
PullMessageProcessor 里面的 processRequest 方法是用来处理pullRequest 拉消息请求.
如果broker有消息, processRequest 方法就直接返回,
如果broker没有消息, processRequest 方法怎么办呢?
我们来看一下代码。
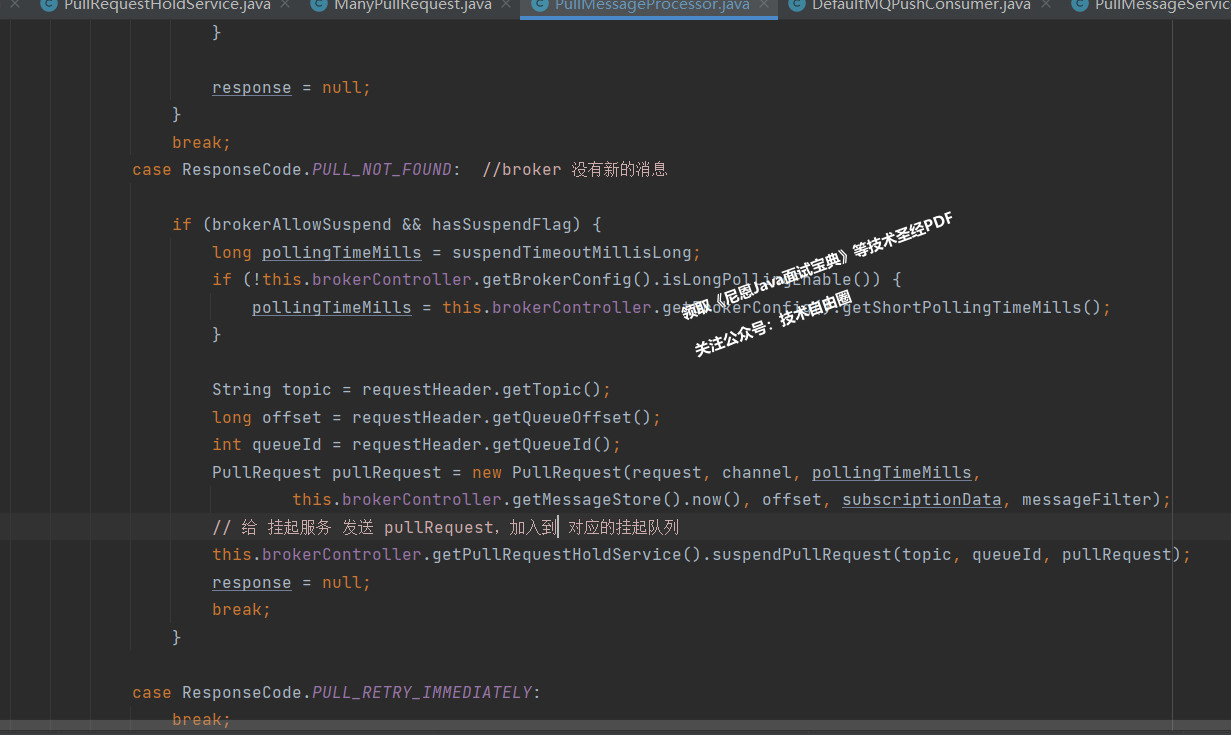
我们再来看下 suspendPullRequest 方法做了什么。
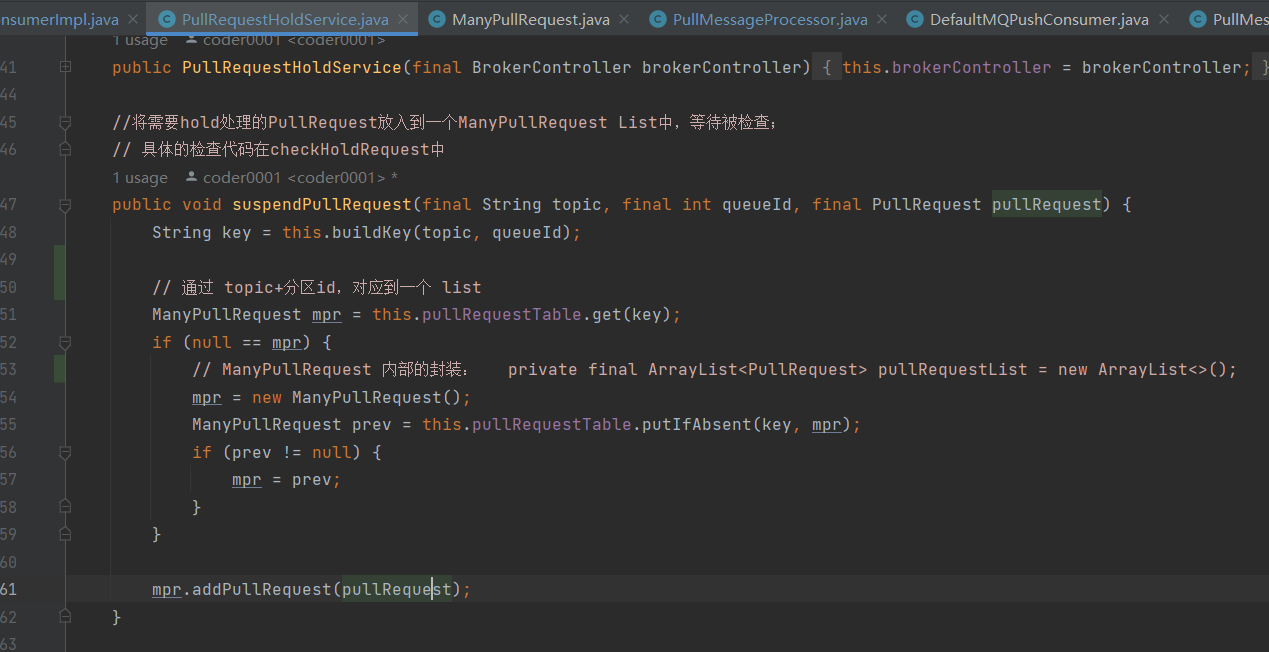
这里有个broker 异步线程 PullRequestHoldService
这个线程会每 5 秒从 pullRequestTable 取PullRequest请求,然后进行检查,看看是否有新的消息
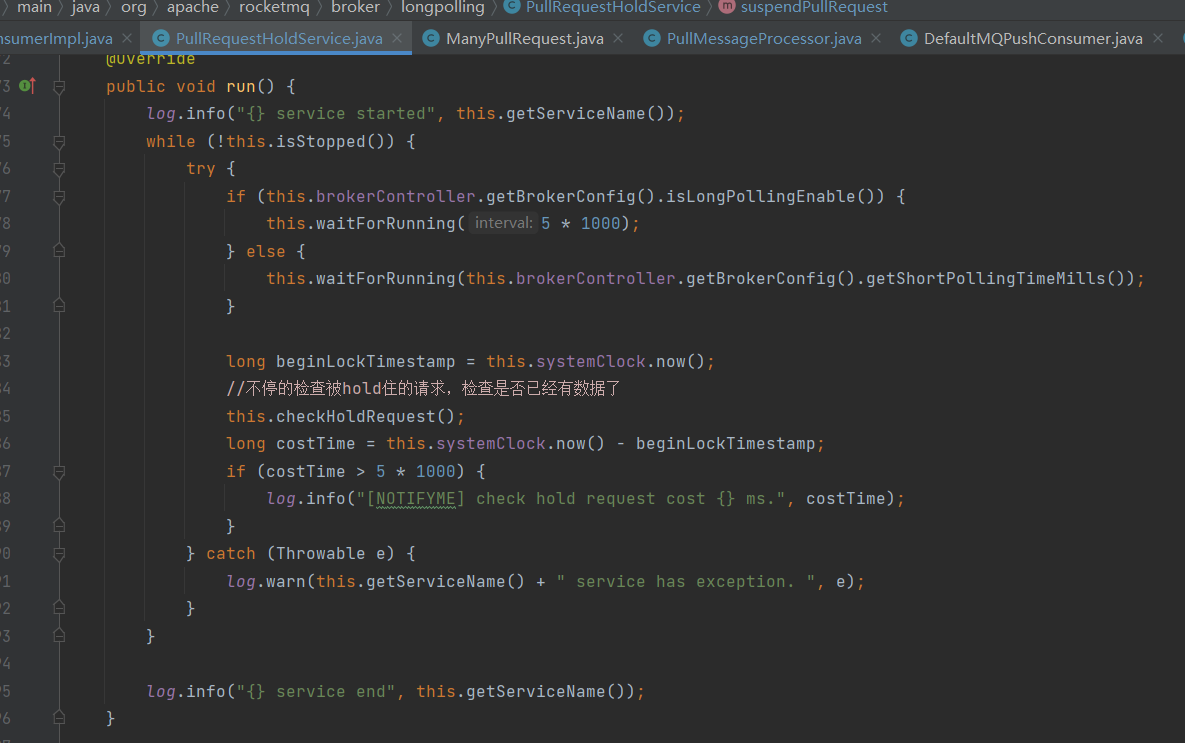
检查方法是:计算 待拉取消息请求的偏移量是否小于当前消费队列最大偏移量,如果条件成立则说明有新消息了,
一旦有消息,PullRequestHoldService 则会调用 notifyMessageArriving ,最终调用 PullMessageProcessor 的 executeRequestWhenWakeup() 方法重新尝试处理这个消息的请求,也就是再来一次,整个长轮询的时间默认 30 秒。
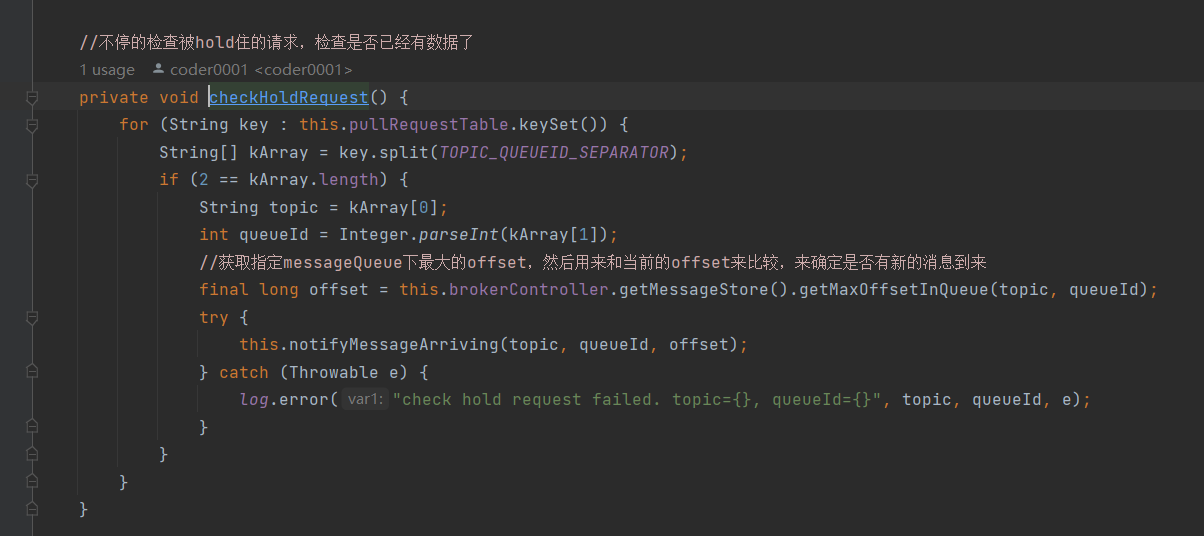
简单的说就是 5 秒会检查一次消息时候到了,如果到了则调用 processRequest 再处理一次。
这里是一个定期检查的流程。除此之外,如果commitLog 有消息,也会执行唤醒的工作,做到准实时。
brocker端的 ReputMessageService 线程,不断地为 commitLog 追加数据并分发请求,构建出 ConsumeQueue 和 IndexFile 两种类型的数据,并且也会有唤醒请求的操作,来弥补每 5s 一次这么慢的延迟
PUSH 模式的应用开发
下面是 RocketMQ 推模式的一个官方示例:
public static void main(String[] args) throws InterruptedException, MQClientException {
Tracer tracer = initTracer();
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("CID_JODIE_1");
consumer.getDefaultMQPushConsumerImpl().registerConsumeMessageHook(new ConsumeMessageOpenTracingHookImpl(tracer));
consumer.subscribe("TopicTest", "*");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
consumer.setConsumeTimestamp("20181109221800");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
消费者会定义一个消息监听器 MessageListenerConcurrently,并且把这个监听器注册到 DefaultMQPushConsumer ,
这个监听器,最终会注册到内部 DefaultMQPushConsumerImpl,当内部拉取到消息时,就会使用这个监听器来处理消息。
消费者消息处理过程
下面用并发消费方式下的同步拉取消息为例总结一下消费者消息处理过程:
第一类线程 RebalanceService ,根据 topic 的队列数量和消费者个数做负载均衡,对于分配到queue 产生的 pullRequest拉取请求,并讲请求 队列 pullRequestQueue 中。
第二类线程 PullMessageService ,不断的pullRequestQueue队列 中获取 pullRequest,然后从 broker 拉取消息。具体来说,这里调用了 DefaultMQPushConsumerImpl 类的 pullMessage 方法; pullMessage 方法调用 PullAPIWrapper 的 pullKernelImpl 方法真正去发送 PULL 请求,并传入 PullCallback 的 回调函数;拉取到消息后,调用 PullCallback 的 onSuccess 方法处理结果,会把消息放入到 缓存消息的队列 messageQueue
第三类线程消息消费线程:ConsumeMessageOrderlyService 有序消息消费, 或者 ConsumeMessageConcurrentlyService 并行消息服务。 从messageQueue 拉取消息,进行消费。这里调用了 ConsumeMessageConcurrentlyService 的 submitConsumeRequest 方法,通过里面的 ConsumeRequest 线程来处理拉取到的消息;处理消息时调用了消费端定义的消费逻辑,也就是 MessageListenerConcurrently 的 consumeMessage 方法。
Rocketmq 拉模式/PULL 模式
下面是来自官方的一段 拉模式/PULL 模式拉取消息的代码:
DefaultLitePullConsumer litePullConsumer =
new DefaultLitePullConsumer("lite_pull_consumer_test");
litePullConsumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
litePullConsumer.subscribe("TopicTest", "*");
litePullConsumer.start();
try {
while (running) {
List<MessageExt> messageExts = litePullConsumer.poll();
System.out.printf("%s%n", messageExts);
}
} finally {
litePullConsumer.shutdown();
}
上面代码中写了一个死循环 , 客户端通过 PULL 模式,不断的调用poll方法,不停的去拉取消息。
从这段代码可以看出, 通过拉模式/PULL 模式 的pullRequest 请求,不是Rocketmq 源码去发出,也不用PullMessageService 线程,这个pullRequest 请求是有 客户端应用程序自己去发。
Rocketmq 源码内部,拉模式消费使用的是DefaultMQPullConsumer/DefaultLitePullConsumerImpl,核心逻辑是先拿到需要获取消息的Topic对应的队列,然后依次从队列中拉取可用的消息。拉取了消息后就可以进行处理,处理完了需要更新消息队列的消费位置。
下面有一个更加生产化的案例
@Test
public void testPullConsumer() throws Exception {
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("group1_pull");
consumer.setNamesrvAddr(this.nameServer);
String topic = "topic1";
consumer.start();
//获取Topic对应的消息队列
Set<MessageQueue> messageQueues = consumer.fetchSubscribeMessageQueues(topic);
int maxNums = 10;//每次拉取消息的最大数量
while (true) {
boolean found = false;
for (MessageQueue messageQueue : messageQueues) {
long offset = consumer.fetchConsumeOffset(messageQueue, false);
PullResult pullResult = consumer.pull(messageQueue, "tag8", offset, maxNums);
switch (pullResult.getPullStatus()) {
case FOUND:
found = true;
List<MessageExt> msgs = pullResult.getMsgFoundList();
System.out.println(messageQueue.getQueueId() + "收到了消息,数量----" + msgs.size());
for (MessageExt msg : msgs) {
System.out.println(messageQueue.getQueueId() + "处理消息——" + msg.getMsgId());
}
long nextOffset = pullResult.getNextBeginOffset();
consumer.updateConsumeOffset(messageQueue, nextOffset);
break;
case NO_NEW_MSG:
System.out.println("没有新消息");
break;
case NO_MATCHED_MSG:
System.out.println("没有匹配的消息");
break;
case OFFSET_ILLEGAL:
System.err.println("offset错误");
break;
}
}
if (!found) {//没有一个队列中有新消息,则暂停一会。
TimeUnit.MILLISECONDS.sleep(5000);
}
}
}
下面代码就演示了使用DefaultMQPullConsumer拉取消息进行消费的示例。
核心方法就是调用consumer的pull()拉取消息。
该示例中使用的是同步拉取,即需要等待Broker响应后才能继续往下执行。如果有需要也可以使用提供了PullCallback的重载方法。同步的pull()返回的是PullResult对象,其中的状态码有四种状态,并且分别对四种状态进行了不同的处理。
只有状态为FOUND才表示拉取到了消息,此时可以进行消费。
消费完了需要调用updateConsumeOffset()更新消息队列的消费位置,这样下次通过fetchConsumeOffset()获取消费位置时才能获取到正确的位置。
如果有需要,用户也可以自己管理消息的消费位置。
RocketMQ 中的 PushConsumer 推模式的源码分析
那 PULL 模式中 poll 函数是怎么实现的呢?
跟踪源码可以看到,消息拉取的时候,DefaultLitePullConsumerImpl工作过程基本与DefaultMQPushConsumer过程相似。
DefaultLitePullConsumerImpl允许设置是否需要自动commit offset(默认自动),并且把拉取到的消息缓存在内存中,Conumser需要主动通过poll从内存中获取消息,进行业务处理。
DefaultLitePullConsumerImpl 类中的一个方法,首先根据负载均衡服务分配到的 queue分区,启动 拉取任务
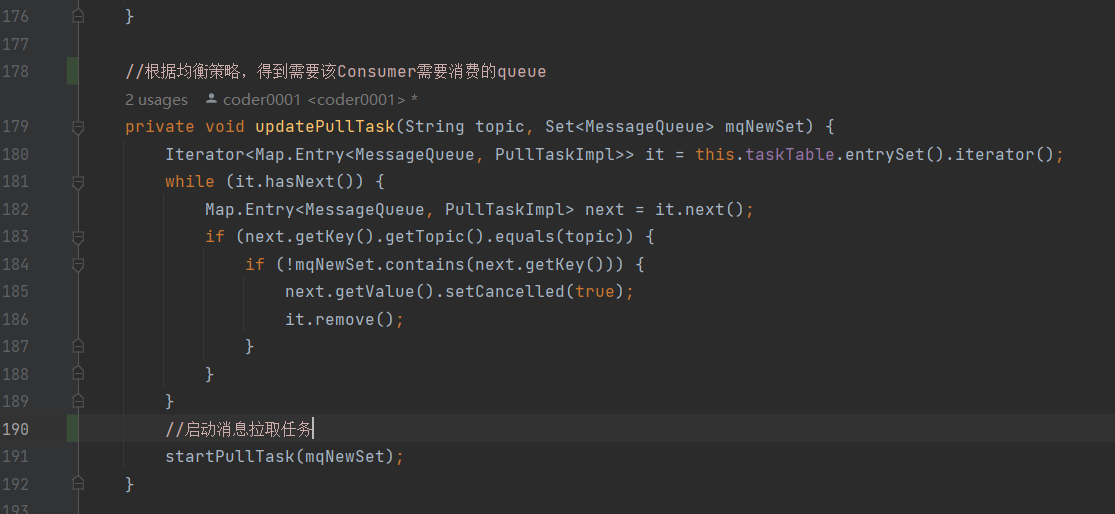
通过定时任务进行消息的拉取

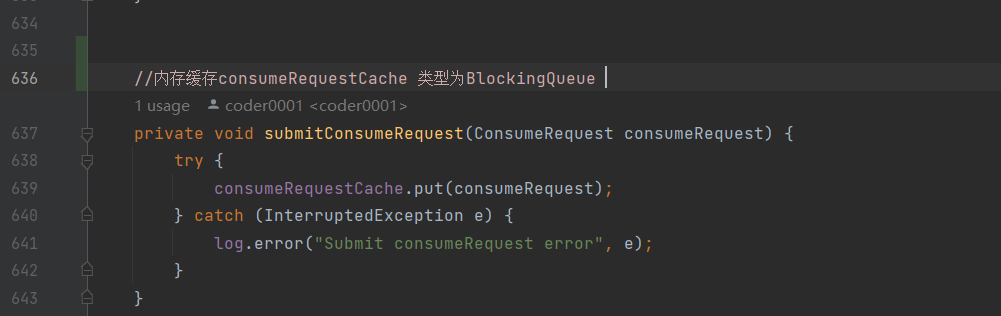
PullTaskImpl拉取到消息后,封装成ConsumeRequest ,提交的 consumeRequestCache 缓存中
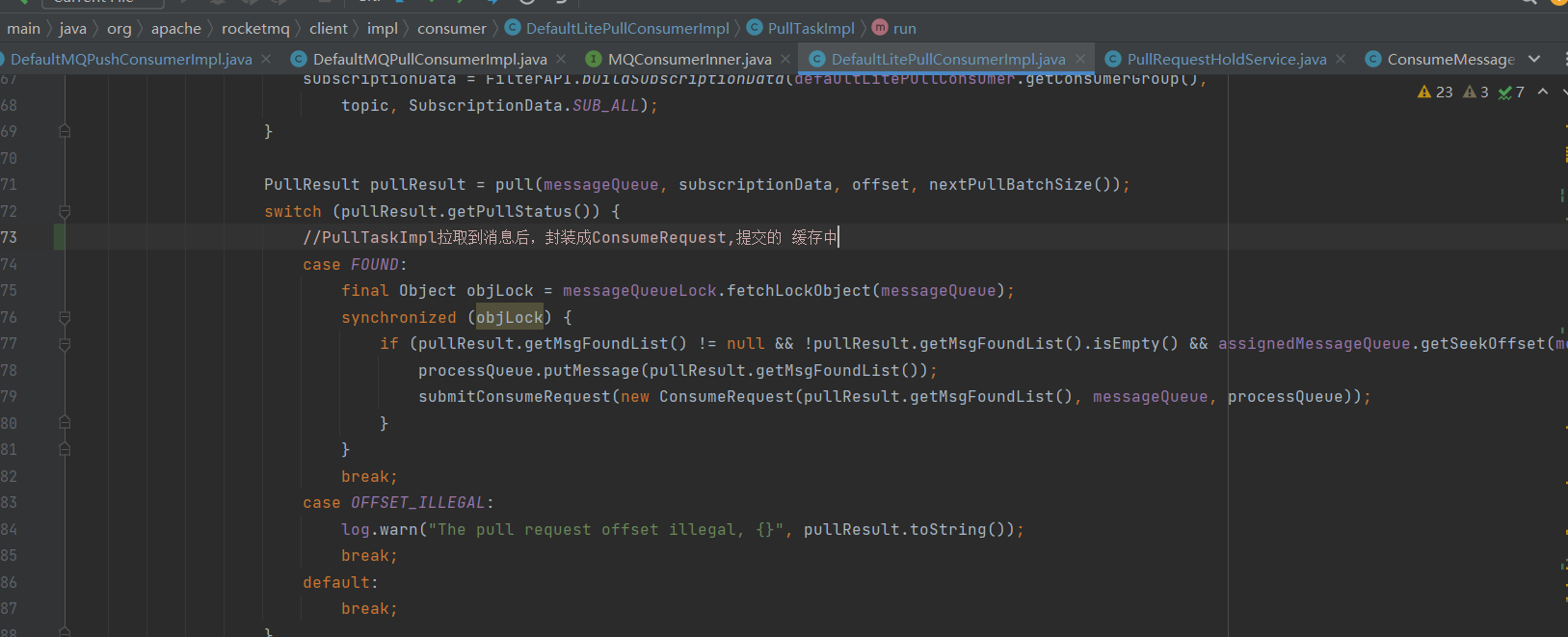
内存缓存consumeRequestCache 类型为BlockingQueue
消费者代码中,通过循环,调用poll方法,不停地从 consumeRequestCache 拉取消息进行处理
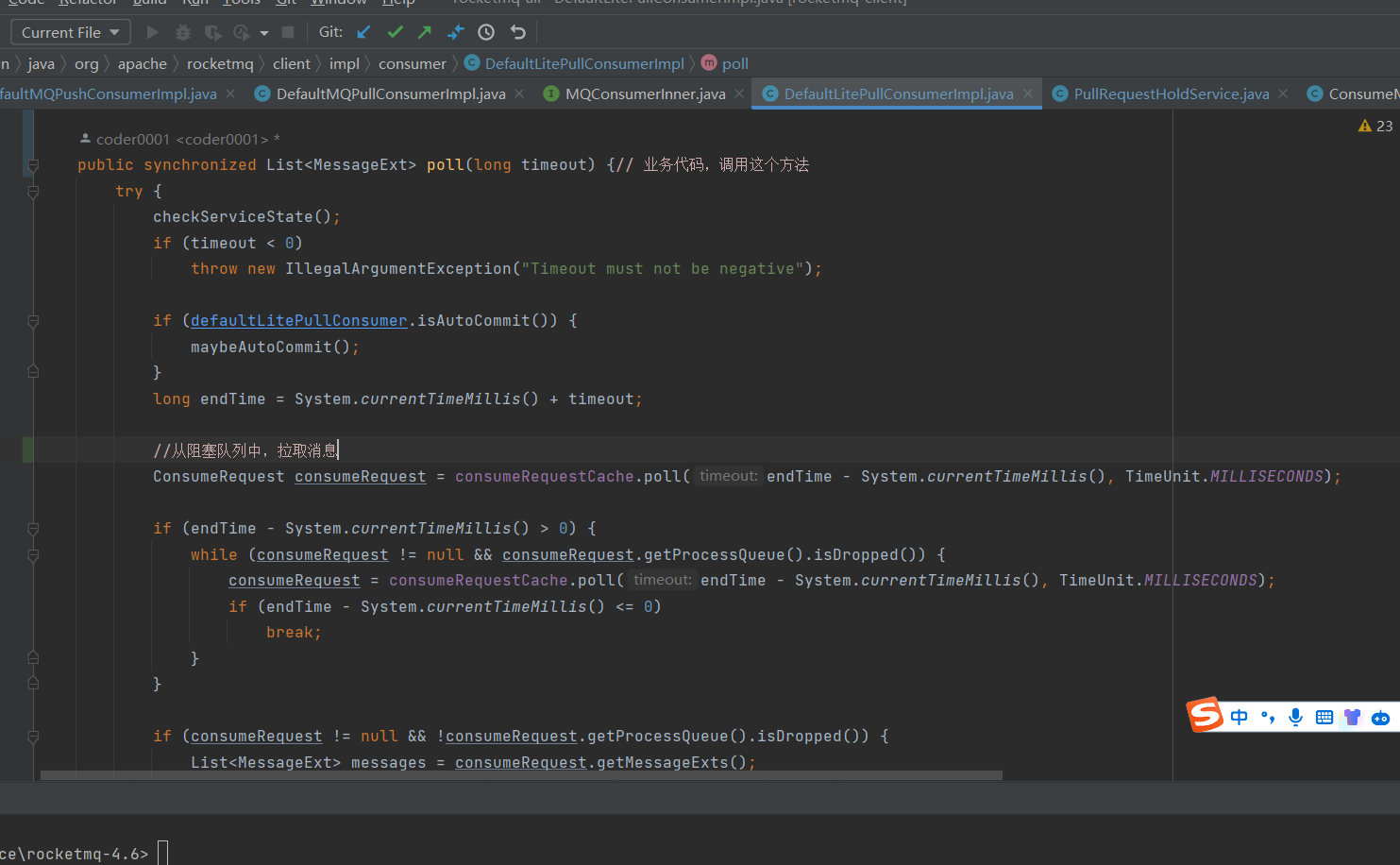
pull模式,消费者消息处理过程:
总结一下,pull模式,消费者消息处理过程:
- 消费者启动过程中,负载均衡线程 RebalanceService 线程发现 ProcessQueueTable 消费快照发生变化时,启动消息拉取线程;
- 消息拉取线程PullTaskImpl 拉取到消息后,把消息放到 consumeRequestCache,然后进行下一次拉取;
- 消费者调用poll方法,不停地从 consumeRequestCache 拉取消息,进行业务处理。
Rocketmq的Push与Pull模式比较
1、Push模式拉取消息,拉取到消息马上推送lisener进行业务处理。
应用程序对消息的拉取过程参与度不高,可控性不足,仅仅提供消息监听器的实现。
2、Pull模式自,自主决定如何拉取消息,从什么位置拉取消息。
应用程序对消息的拉取过程参与度高,由可控性高,可以自主决定何时进行消息拉取,从什么位置offset拉取消息
上面的流程梳理,涉及到Rocketmq源码学习。
Rocketmq源码用了大量的架构模式、设计模式,可以理解为中间件架构的巅峰之作。尼恩的 《RocketMQ 四部曲视频》,从架构师视角揭秘 RocketMQ 的架构哲学,让大家彻底的了解这个高深莫测 RocketMQ 组件的宏观架构,提升大家的架构水平和设计水平。
说在最后:有问题可以找老架构取经
Rocketmq相关的面试题,是非常常见的面试题。
以上的内容,如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。很多小伙伴刷完后, 吊打面试官, 大厂横着走。
在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来改简历、做帮扶。
尼恩指导了大量的小伙伴上岸,前段时间,刚指导一个40岁+被裁小伙伴,拿到了一个年薪100W的offer。
尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!