GoogLeNet(V1)
目录
一、GooLeNet介绍
???????GoogLeNet是由Google团队于2014年提出的深度卷积神经网络架构,也被称为Inception v1。它在当时引入了一些创新的设计理念,成为了深度学习领域的里程碑之一。GoogLeNet的设计目标是在保持网络深度的同时,减少参数数量,提高计算效率。
???????虽然NiN目前没有大规模使用,但是GoogLeNet目前还在大规模使用,它也是第一个超过100层的神经网络,它名字中的“L”大写是为了致敬LeNet。NiN的思想严重影响了GoogLeNet的设计。
1、模型设计的motivation
???????之前我们可能存在一些疑问:卷积核要选多大?通道数要选多大?池化层应该使用最大池化还是平均池化?选择很多但是不知道用哪个比较好。

2、Inception块
???????GoogLeNet引入了"Inception"模块,该模块通过并行使用多个不同大小的卷积核和池化操作,来提取不同尺度的特征。这种并行操作帮助网络同时捕捉到局部和全局的特征,从而提高了网络的表达能力。此外,为了减少参数数量,GoogLeNet还使用了1x1的卷积核进行降维和升维操作,以减少计算成本。

???????其实是将输入Input给copy了4份,通过4条不同的路径对图像进行特征提取(加入必要的padding保证输出跟输入等高等宽),最后将输出的4个特征图在通道维度进行concat(拼接)操作。根据上图可以知道Inception不改变输入的高和宽,只改变通道数。
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)。这很可能得名于电影《盗梦空间》(英文名:Inception),因为电影中的一句话“我们需要走得更深”(“We need to go deeper”)。
???????跟单??或?
?卷积层比,Inception块有更少的参数个数和计算复杂度。
| Parameters(参数量) | FLOPS(计算量) | |
| Inception | 0.16 M | 128 M |
| 3×3 Conv | 0.44 M | 346 M |
| 5×5 Conv | 1.22 M | 963 M |
3、GoogLeNet架构
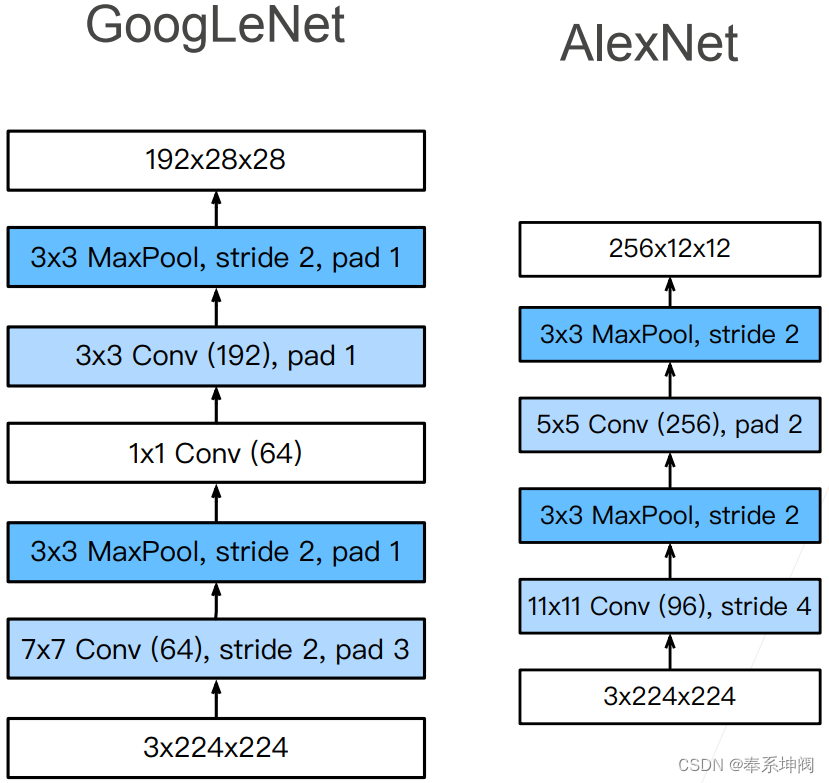
???????在网络结构方面,GoogLeNet采用了多个Inception模块的堆叠。每个Inception模块由多个并行的卷积层和池化层组成,它们的输出被拼接在一起形成下一层的输入。通过堆叠多个Inception模块,网络可以逐渐提取更加抽象和高级的特征。GoogLeNet主要分成了5个Stage,所谓的Stage一般这么算:图像的高宽减半是一个Stage。

(1)Stage1 and Stage2
? ? ? ?Stage1和Stage2没有使用Inception Block。
- channel变化:3 -> 64 -> 192
- (h, w)变化:3次strides=2,每次图片尺寸减半,因此图片大小缩小8倍:
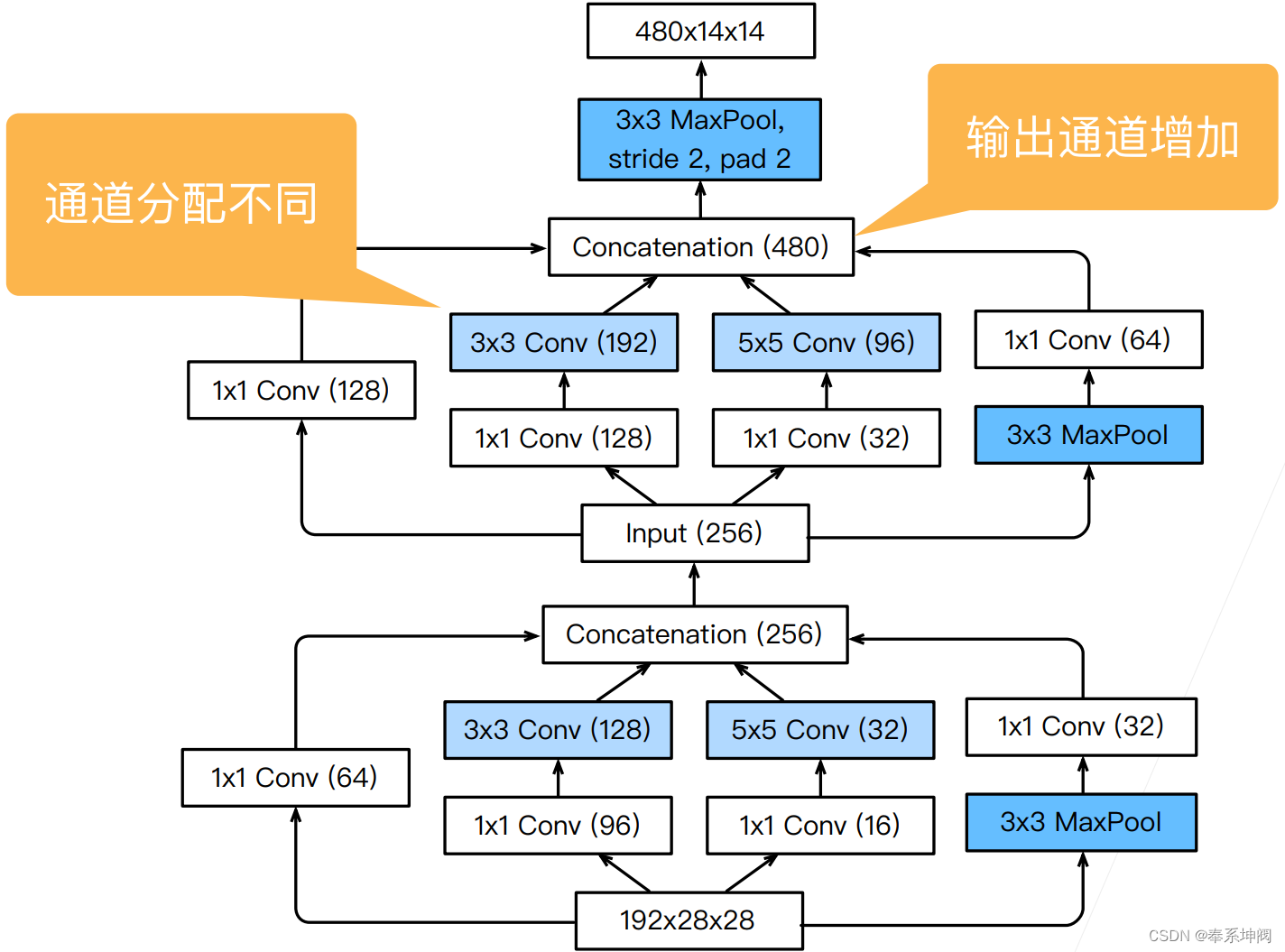
(2)Stage3
???????Stage3使用了2个Inception Block。
- channel变化:192 -> 256 ->480
- (h, w)变化:Inception Block不改变图片尺寸。在两个Inception Block后面有一个MaxPool,其stride=2,因此图片大小缩小2倍?
(3)Stage4 and Stage5
???????Stage4和Stage5使用了7个Inception Block。这里最后和NiNNet不一样:NiNNet经过最后一个NiN块时输出通道个数直接等于类别数,后面不需要全连接层;而GoogLeNet经过最后一个Inception块后通道数很多,在后面加一个全连接层(FC),使通道个数经过全连接层后等于类别数。
- channel变化:480 -> 512 -> 832 -> 1024
- (h, w)变化:Inception Block不改变图片尺寸。Stage4后面有一个MaxPool,其stride=2,此时(h, w)会从14变为7,在Stage5后面有一个全局平均池化(GlobalAvgPool),此时会(h, w)会直接变成1。

4、Inception后续变种
- Inception-BN (V2): 使用了batch normalization。
- Inception-V3: 修改了Inception块:替换?
?为多个?
?卷积层、替换?
?和?
?卷积层、替换?
?和?
?卷积层、更深。
- Inception-V4: 使用残差连接。
5、总结

二、代码实现
1、Inception块
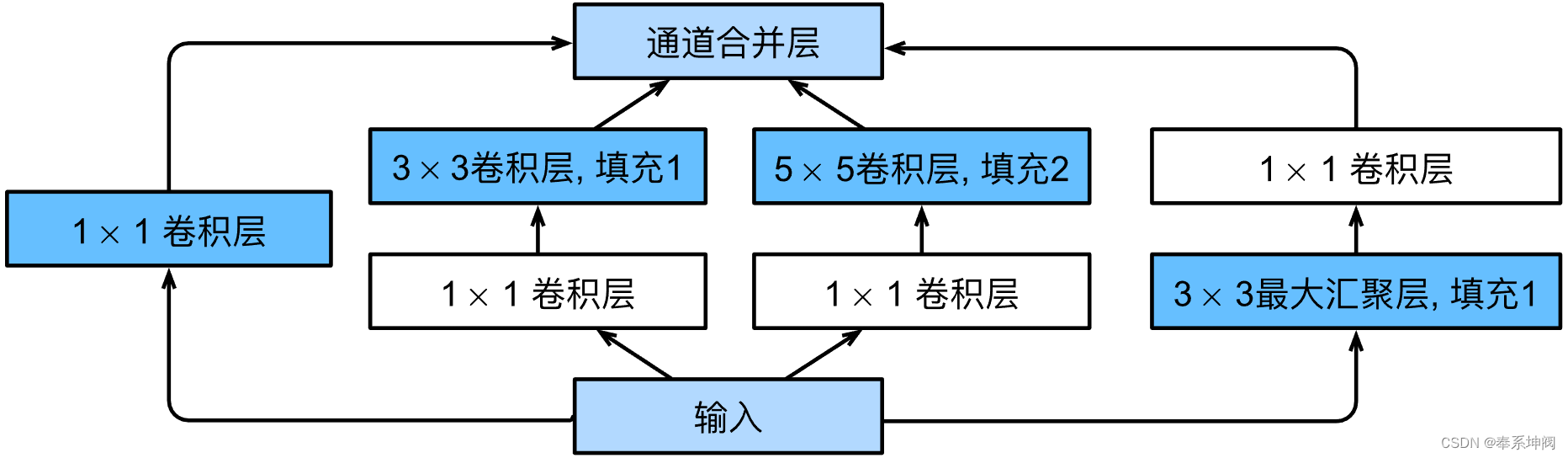
???????如下图所示,Inception块由四条并行路径组成。前三条路径使用窗口大小为 、
?和
?的卷积层,从不同空间大小中提取信息。中间的两条路径在输入上执行
?卷积,以减少通道数,从而降低模型的复杂性。第四条路径使用
?最大池化层,然后使用
?卷积层来改变通道数。
???????这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1) # 通道维度dimension为1 (batch, channel, height, width) -> (0, 1, 2, 3)2、GoogLeNet模型
(1)Stage1
???????现在,我们逐一实现GoogLeNet的每个Stage。Stage1使用64个通道、?卷积层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))(2)Stage2
? ? ? ?Stage2使用两个卷积层:第一个卷积层是64个通道、?卷积层;第二个卷积层使用将通道数量增加三倍的
?卷积层。这对应于Inception块中的第二条路径。
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))(3)Stage3
???????Stage3串联两个的Inception块。
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))(4)Stage4
???????Stage4串联了五个Inception块。
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))(5)Stage5
???????Stage5串联了两个Inception块。需要注意的是,Stage5的后面紧跟输出层,该模块同NiN一样使用全局平均池化层,将每个通道的高和宽变成1。最后我们将输出变成二维数组,再接上一个输出个数为标签类别数的全连接层。
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)), # 全局平均池化层
nn.Flatten()) # 将channel+height+width三个维度展平
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))???????GoogLeNet模型的计算复杂,而且不如VGG那样便于修改通道数。为了使Fashion-MNIST上的训练短小精悍,我们将输入的高和宽从224降到96,这简化了计算。下面演示各个模块输出的形状变化。
X = torch.rand(size=(1, 1, 96, 96))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)Sequential output shape: torch.Size([1, 64, 24, 24])
Sequential output shape: torch.Size([1, 192, 12, 12])
Sequential output shape: torch.Size([1, 480, 6, 6])
Sequential output shape: torch.Size([1, 832, 3, 3])
Sequential output shape: torch.Size([1, 1024])
Linear output shape: torch.Size([1, 10])3、训练模型
???????我们使用Fashion-MNIST数据集来训练我们的模型。在训练之前,我们将图片转换为 ?分辨率。
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())loss 0.262, train acc 0.900, test acc 0.886
3265.5 examples/sec on cuda:0
4、总结
- Inception块相当于一个有4条路径的子网络。它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使用
?卷积层减少每像素级别上的通道维数从而降低模型复杂度。
- GoogLeNet将多个设计精细的Inception块与其他层(卷积层、全连接层)串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
- GoogLeNet和它的后继者们一度是ImageNet上最有效的模型之一:它以较低的计算复杂度提供了类似的测试精度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!