SD之lora训练
目录
为什么要训练自己的模型
训练自己的模型可以在现有模型的基础上,让AI懂得如何更精确生成/生成特定的风格、概念、角色、姿势、对象。
比如,你下载了一个人物的大模型checkpoint,但是你想生成特点的人物,比如迪丽热巴,AI大模型是不知道迪丽热巴长什么样子的,这个使用lora就派上用场了。
要注意的是,对于一些基础东西,比如长头发、短头发、黑色头发、棕色头发,这些AI 都是知道的,lora并不是做这个的。
SD模型微调方法
主要有 4 种方式:Dreambooth, LoRA(Low-Rank Adaptation of Large Language Models), Textual Inversion, Hypernetworks。它们的区别大致如下:
- Textual Inversion?(也称为 Embedding),它实际上并没有修改原始的 Diffusion 模型, 而是通过深度学习找到了和你想要的形象一致的角色形象特征参数,通过这个小模型保存下来。这意味着,如果原模型里面这方面的训练缺失的,其实你很难通过嵌入让它“学会”,它并不能教会 Diffusion 模型渲染其没有见过的图像内容。
- Dreambooth?是对整个神经网络所有层权重进行调整,会将输入的图像训练进 Stable Diffusion 模型,它的本质是先复制了源模型,在源模型的基础上做了微调(fine tunning)并独立形成了一个新模型,在它的基本上可以做任何事情。缺点是,训练它需要大量 VRAM, 目前经过调优后可以在 16GB 显存下完成训练。
- LoRA?也是使用少量图片,但是它是训练单独的特定网络层的权重,是向原有的模型中插入新的网络层,这样就避免了去修改原有的模型参数,从而避免将整个模型进行拷贝的情况,同时其也优化了插入层的参数量,最终实现了一种很轻量化的模型调校方法, LoRA 生成的模型较小,训练速度快, 推理时需要 LoRA 模型+基础模型,LoRA 模型会替换基础模型的特定网络层,所以它的效果会依赖基础模型。
- Hypernetworks?的训练原理与 LoRA 差不多,目前其并没有官方的文档说明,与 LoRA 不同的是,Hypernetwork 是一个单独的神经网络模型,该模型用于输出可以插入到原始 Diffusion 模型的中间层。 因此通过训练,我们将得到一个新的神经网络模型,该模型能够向原始 Diffusion 模型中插入合适的中间层及对应的参数,从而使输出图像与输入指令之间产生关联关系。
总儿言之,就训练时间与实用度而言,目前训练LoRA性价比更高,也是当前主流的训练方法。
准备素材
1 确定要训练的LoRA类型
首先需要确定训练什么类型的Lora,类型可以有风格,概念,角色,姿势,对象等。本文以人物风格为例,讲解如何训练人物风格的LoRA模型。
2 图片收集
对于训练人物风格的LoRA,图片收集的标准大致为:
- 数量几十张即可
- 分辨率适中,勿收集极小图像
- 数据集需要统一的主题和风格的内容,图片不宜有复杂背景以及其他无关人物
- 图像人物尽量多角度,多表情,多姿势
- 凸显面部的图像数量比例稍微大点,全身照的图片数量比例稍微小点
(补充)图片收集的渠道:
一般情况下,首先会想到去Google的图片中进行搜索,但有时候搜索到的图片分辨率较小,且质量也不是很高。这里Post其他博主推荐的一些图片的网站,仅供参考:
优质训练集定义如下
- 至少15张图片,每张图片的训练步数不少于100
- 照片人像要求多角度,特别是脸部特写(尽量高分辨率),多角度,多表情,不同灯光效果,不同姿势等
- 图片构图尽量简单,避免复杂的其他因素干扰
- 可以单张脸部特写+单张服装按比例组成的一组照片
- 减少重复或高度相似的图片,避免造成过拟合
- 建议多个角度、表情,以脸为主,全身的图几张就好,这样训练效果最好
3 图片预处理
这里主要介绍对于图像分辨率方面的预处理。有些人也说,不用裁剪了,让AI自己去适配。
收集的图片在分辨率方面尽量大一些,但也不要太大。如果收集到的图片过小,可以使用超分辨率重建的方式将图片的方式扩大;然后将所有图片都裁剪成512x512像素大小(虽然SD2.x支持了768x768的输入,但考虑到显存限制,这里选择裁剪到512x512)。
对于超分辨率重建,可以使用SD WebUI中Extra页面中进行分辨率放大。详情请参考:https://ivonblog.com/posts/stable-diffusion-webui-manuals/zh-cn/features/upscalers/
对于裁剪到固定尺寸,现提供如下的裁剪方法:
- birme站点批量裁剪后批量下载,优势是可以自定义选取
- 使用SD WebUI自动裁切,或是手动裁切。详情请参考:https://ivonblog.com/posts/stable-diffusion-webui-manuals/zh-cn/training/prepare-training-dataset/
4 图片标注
这里图片标注是对每张训练图片加以文字的描述,并保存为与图片同名的txt格式文本。
我们将使用神经网络来为我们完成艰苦的工作,而不是自己费力地为每个图片进行标注。这里用到的是一个名为BLIP的图像标注模型。模型的标注并不完美,但后面经过人工的微调也足以满足我们的目的。
标注工具可以使用SD WebUI中自带的图像标注功能。详细使用请参考:https://ivonblog.com/posts/stable-diffusion-webui-manuals/zh-cn/training/prepare-training-dataset/中的预先给图片上提示词章节。
也可以使用一个工具:BooruDatasetTagManager
图片标注完成之后,会在图像文件夹里生成与图片同名的txt文件。点击打开txt文件,将觉得无关,多余的特征都给删除掉。
强调:
每个txt中记得加上关键标记,如我这里是训练迪丽热巴,那我都加上关键词dlrb,后面使用这个来触发lora
至此,训练数据集准备完成。
安装Koyha_ss
目前网上有很多训练LoRA的项目
1.koyha_ss_GUI:https://github.com/bmaltais/kohya_ss
2.LoRA_Easy_Training_Scripts:https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
3.秋叶大佬的:https://github.com/Akegarasu/lora-scripts? /??https://gitcode.com/mirrors/akegarasu/lora-scripts/blob/main/README.md
他们底层都是用的:https://github.com/kohya-ss/sd-scripts
本文介绍的是koyha_SS_Gui,windows的安装
这个安装简单,照着git步骤来就可以了,目前代码中默认torch是支持cuda118的,这个需要注意自己的显卡了。
1.git clone https://github.com/bmaltais/kohya_ss.git
2.cd kohya_ss
3..\setup.bat
#选择1,进行安装安装过程可能报错,哈哈,一步步来解决。
运行:
gui.ps1 --listen 127.0.0.1 --server_port 7861 --inbrowser --share训练lora
1.准备参数和环境
需要配置以下三个目录:
- image:存放训练集
- log:存放日志文件
- model:存放训练过的模型
首先在image文件夹中新建一个名为100_{{name}}的文件夹,100用来表示单张图片训练100次。然后将之前标注好的训练数据都放入名为100的文件夹中。
由于之前准备的训练数据集是真人风格的,故这里可以选择真人风格的基座大模型:chilloutmix_NiPrunedFp32Fix.safetensors
详细的配置如下:


随后配置训练参数:

系统提供了很多可以调节的参数,比如batchsize,learning rate, optimizer等等。大家可以根据自己实际情况进行配置。
2.启动训练
当路径以及训练参数都配置好之后,点击入下图所示的启动按钮即可启动训练。训练的日志可在终端中查看。

使用模型
1 拷贝训练过的lora模型
当训练并测试完LoRA之后,就可以与基座大模型结合在一起进行特定风格的使用了。在使用之前需要先把训练过的LoRA模型拷贝到SD WebUI对应的保存LoRA模型的文件夹中,对应的路径为stable-diffusion-webui/models/Lora。
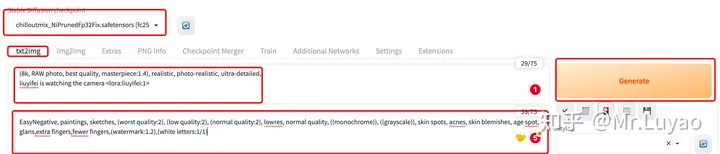
2 启动SD WebUI进行图像生成
1. 启动SD WebUI界面,首先选择基座大模型,由于本示例是写实风,故这里选择写实风的基座大模型:chilloutmix_NiPrunedFp32Fix.safetensors
2. 输入正向prompt,并在最后输入 <lora:训练的模型名称:权重> 来调用训练过的LoRA模型。这里记得加入dlrb,关键词
3. 输入反向prompt
4. 设定超参
5. Generate
即可使用训练过的LoRA模型进行特定任务的图像生成。
复制:全流程讲解如何使用Kohya_ss自定义训练LoRA - 知乎?,加入自己的理解和排版
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!