【没有哪个港口是永远的停留~论文解读】FlowNet 2.0
2.2 FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
paper:https://arxiv.org/pdf/1612.01925
摘要:
- FlowNet证明了光流估计可以作为一个学习问题。
- 准确率方面:FlowNet无法与变分方法竞争。
- 在本文中,我们提出了光流的端到端学习的概念,并使其非常有效。质量和速度的大幅提高
- 原理:
首先,我们关注训练数据,并表明在训练期间呈现数据的时间表非常重要。
其次,我们开发了一种堆叠结构,该结构包括利用中间光流对第二图像进行翘曲。
第三,我们通过引入专门研究小运动的子网络来阐述小位移。
-
速度精度:FlowNet 2.0仅略慢于原始FlowNet,但将估计误差降低了50%以上。
- 它的性能与最先进的方法不相上下,同时以交互式帧速率运行。
- 此外,我们提出了更快的变体,允许以高达140fps的速度进行光流计算,其精度与原始FlowNe相匹配
2.2.1 Introduction
- FlowNet 使用简单的卷积CNN架构从数据中直接学习光流概念的想法与所有已建立的方法完全脱节。
- 但是,FlowNet 解决了估计流场中位移小和噪声伪影的问题。
- FlowNet 2.0达到了最先进的水平。
2.2.2 相关工作
- 其他的网络:3D卷积网络、无监督学习目标、精心设计的旋转不变架构或基于变分方法的从粗到细思想的金字塔方法为特征。这些方法都没有显著优于原始FlowNet
- Siamese network architectures 精度好,但是速度慢
- 为每像素预测任务训练的卷积网络通常会产生噪声或模糊的结果。因此采用后处理操作比较好
- 后处理操作:例如,光流估计可以用变分方法进行细化。在某些情况下,这种细化可以通过神经网络来近似:Chen和Pock[10]将反应扩散模型公式化为CNN,并将其应用于图像去噪、去块和超分辨率。最近,已经表明,通过将几个卷积网络堆叠在一起,可以获得类似的细化。这导致了人类姿态估计[18,9]和语义实例分割[23]的改进结果。在本文中,我们将堆叠多个网络的思想应用于光流估计。
- image warping 的概念在所有当代变分光流方法中都很常见,可以追溯到Lucas和Kanade[17]的工作。在Brox等人[6]中,它被证明对应于与延拓方法相结合的数值不动点迭代方案。
- ?curriculum learning 课程学习:在一系列逐渐增加的任务上训练机器学习模型的策略被称为课程学习[5]。这个想法至少可以追溯到Elman[12],他表明任务的演变和网络架构在语言处理场景中都是有益的。
2.2.3 数据集计划
- 观点:高质量的培训数据对于监督培训的成功至关重要。
- 实验:我们研究了根据所提供的训练数据估计的光流质量的差异。
- 实验结论:不仅数据类型很重要,而且数据在训练过程中的呈现顺序也很重要。
?

?
1)解释:FlowNetS 在不同的数据集上(Chairs Things3D mixed...)用不同的调度(S-short\S-long\S-fine)训练的结果。
2) ?解释:数字表示Sintel train clean上的端点错误。
3) ?解释:mixed表示Chairs和Things3D的相等混合。
4)? 结论:首先在Chairs上进行培训,然后在Things3D上进行微调,可以获得最佳结果
5)? 结论:FlowNetC的性能优于FlowNetS。
6)? 现象【Chairs→Things3D 优于 mixed】推测:更简单的Chairs数据集有助于网络学习颜色匹配的一般概念,而不会过早地为3D运动和逼真的照明开发可能令人困惑的先验。
7)? 结论:在使用深度网络学习通用概念时,训练数据调度对于避免捷径的重要性。
2.2.4 Stacking Networks 堆叠网络
观点:所有最先进的光流方法都依赖于迭代方法。
实验:深度网络也能从迭代细化中受益吗?为了回答这个问题,我们尝试堆叠多个FlowNetS和FlowNetC架构。
?

?
- 图2:完整架构的示意图:为了计算大位移光流,我们结合了多个FlowNets。
- 大括号表示输入的串联。
- 为了优化处理小位移,我们在FlowNetS架构中引入了开始时的较小步长和上卷积之间的卷积。
- 最后,我们应用一个小型融合网络来提供最终估计。
?
网络1(FlowNetC) input:? images I1 、images I2
网络1(FlowNetC) output: ?flow 估计 wi (其中 i 表示索引 )
?
?flow wi、双线性插值将 images I2? warp:
这样,堆栈中的下一个网络可以专注于 images I1 和? images ~I2,i 之间的剩余增量。
网络2(FlowNetS) input: 误差 ei ;见图2。
表2显示了堆叠两个网络的效果、扭曲的效果以及端到端训练的效果。
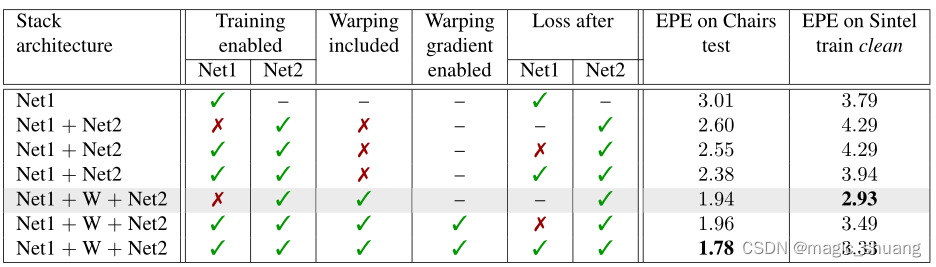
1)堆叠两个FlowNetS网络(Net1和Net2)时的选项评估。
2)第 1 行:Net1使用 Chairs→Things3D 时间表。
3)第 2 行:Net2随机初始化,调度Slong
4)第 3 行:Net1和Net2一起初始化,
5)第 4 行:只有Net2在带有Slong的椅子上训练
我们做出了以下观察:
(1)仅堆叠网络而不warp 可以提高Chairs的结果,但会降低Sintel的性能,即堆叠网络过于拟合。
(2) 包括 warp 在内,堆叠总是能提高效果。
(3) 当训练堆叠的网络端到端时,在Net1之后添加中间损耗是有利的。
(4) 当保持第一网络固定并且在warp 操作之后仅训练第二网络时,获得最佳结果。
显然,由于堆叠网络是单个网络的两倍大,因此过度拟合是一个问题。warp 后的流细化的积极效果可以抵消这个问题,但当堆叠网络一个接一个地训练时,可以获得两者的最佳效果,因为这避免了过拟合,同时具有流细化的好处。
图4显示了单个FlowNetS的不同网络大小的网络精度和运行时间。当以更快的网络为目标时,因子3/8在速度和准确性之间产生了良好的权衡。

堆叠多个不同的网络
注释:
- s:FlowNetS小网络? S:FlowNetS大网络
- ss: 两个小网络 SS:两个大网络
- CSS:FlowNetC+FlowNetS+FlowNetS
- 每个新网络首先按照Slong规则在Chairs上train,然后按照Sfine在Things3D上train(Chairs→Things3D时间表)。
- 推理:Nvidia GTX 1080。
?

?
2.2.5 小位移
数据集:创建了一个椅子数据集ChairsSDHom,位移非常小,位移直方图更像UCF101。
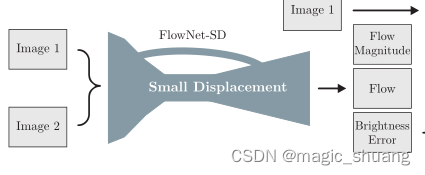
网络结构:在亚像素运动的情况下,噪声仍然是一个问题,我们推测FlowNet架构通常可能不适合这种运动。因此,我们稍微修改了最初的FlowNetS架构,并删除了第一层中的跨步2。我们通过用多个3×3内核2交换开头的7×7和5×5内核,使网络的开头更深入。由于噪声往往是小位移的问题,我们在上卷积之间添加卷积,以获得更平滑的估计,如[19]所示。我们用FlowNet2 SD表示得到的体系结构;见图
?
2.2.6 实验
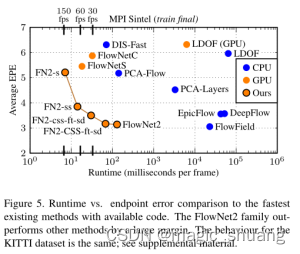
我们在采用2.40GHz Intel Xeon E5和Nvidia GTX 1080的系统上评估了所有方法3。在适用的情况下,使用特定于数据集的参数,以获得最佳性能。表4给出了端点错误和运行时间
1) X-耗时 Y-端点错误
2)DIS-Fast、LDOF
3)?? PCA-Flow、EpicFlow、DeepFlow、FlowFied
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!