【python】进阶--->并发编程之线程(二)
一、线程的生命周期
新建 : 创建线程经过初始化,进入就绪状态
就绪 : 等待操作系统调度,调度后进入运行状态运行
阻塞 : 暂停运行,解除阻塞后进入就绪等待重新调度
消亡 : 线程执行完毕或者异常终止
可能有3种情况从运行到阻塞 :
- 同步 : 线程中获取同步锁,但是资源已经被其他线程锁定,进入locked状态,直到该资源可以获取
- 睡眠 : 线程运行sleep或者join方法后,进入sleep状态.区别在于sleep是阻塞自己等待一定的时间,join是阻塞其他线程等待调用join的线程执行完毕.
- 等待 : 线程中执行wait方法,等待其他线程通知notify.
线程共享全局变量
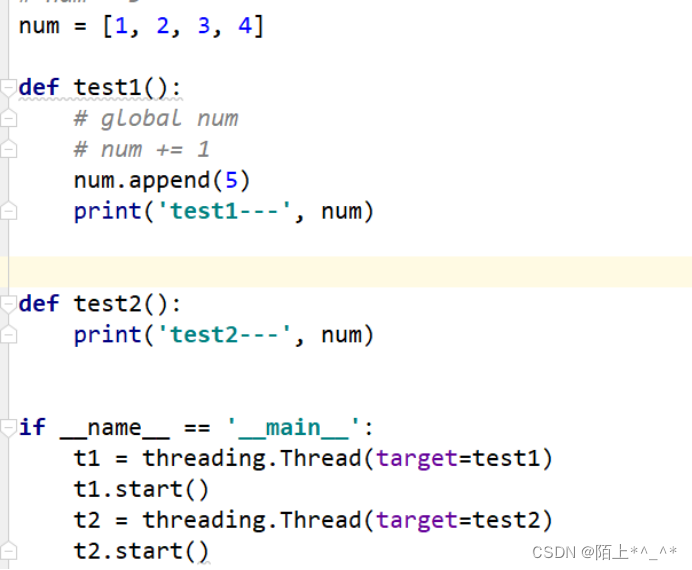
import threading, time
num = 5
# num = [1, 2, 3, 4]
def test1():
global num
# num += 1
# num.append(5)
for i in range(10):
time.sleep(1)
num += 1
print('test1---', num)
def test2():
global num
for i in range(10):
time.sleep(1)
num += 1
print('test2---', num)
if __name__ == '__main__':
t1 = threading.Thread(target=test1)
t1.start()
t2 = threading.Thread(target=test2)
t2.start()
在一个进程内所有的线程共享全局变量,很方便多个线程键共享数据
缺点就是,线程对全局变量随机修改可能在成多线程之间全局变量的混乱.
线程的数量
import threading
import time
def test1():
for i in range(3):
print('test1---%s' % i)
time.sleep(1)
def test2():
for i in range(3):
print('test2---%s' % i)
time.sleep(1)
if __name__ == '__main__':
print('开始')
# len(threading.enumerate())
print('t1创建之前,线程的数量:', len(threading.enumerate()))
t1 = threading.Thread(target=test1)
print('t1创建之后,t2创建前,线程的数量:', len(threading.enumerate()))
t2 = threading.Thread(target=test2)
print('t2创建后,线程的数量:', len(threading.enumerate()))
# 调用start方法的时候,才会真正创建一条线程
t1.start()
print('t1启动之后,t2启动前,线程的数量:', len(threading.enumerate()))
t2.start()
print('t2启动后,线程的数量:', len(threading.enumerate()))
线程的执行顺序
import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(3):
time.sleep(1)
print('这是线程%s在进行第%s循环' % (self.name, i))
if __name__ == '__main__':
for i in range(5):
t = MyThread()
t.start()
# 多条线程执行的顺序是不确定的,当执行到sleep语句时
# 线程将被阻塞,sleep结束之后,线程进入就绪状态,等待调度
# 线程调度是操作系统自行选择的.
# 所以只能保证每个线程都完整的执行了,但是启动顺序和函数执行的顺序是不能确定的
主线程和子线程
import time, threading
def test1():
for i in range(10):
time.sleep(1)
print('test1----')
def test2():
for i in range(5):
time.sleep(1)
print('test2----')
if __name__ == '__main__':
print('主线程开始运行')
t = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t.setDaemon(True) # 设置为守护线程
t.start()
t.join()
t2.start()
print('主线程结束')
二、同步和互斥
同时运行的多个任务可能:
?都需要访问/使用同一种资源
?多个任务之间有依赖关系,某个任务的运行依赖于另一个任务
互斥 : 散布在不同任务之间的若干个程序片段,当某个任务运行一个程序片段是,其他任务就不能运行他们之中的任何一个,只能等待该任务运行完这个程序片段之后才可以运行.比如说:一个公共资源同一时刻只能被一个进程或线程使用,多个进程或线程不能同时使用公共资源.
同步 : 散布在不同任务之间的若干个程序片段,他们的运行必须严格按照规定的某种先后顺序来运行,这种先后顺序必须依赖于要完成特定的任务.
三、互斥锁
当多个线程几乎同时修改某一个共享数据时,需要进行同步控制.
线程同步能够保证线程安全访问资源,最简单的机制就是引入互斥锁.为资源引入一个状态:锁定/非锁定
某个线程要更改数据时,先将数据进行锁定,此时资源的状态为”锁定”,其他线程不能更改.
等待该线程执行完,将资源的状态修改为”非锁定”,其他的线程才能去再次锁定该线程.
threading模块中的Lock()
创建锁
mutex = threading.Lock()
锁定
mutex.acquire()
释放
mutex.release()
如果这个锁之前是没有上锁的,那么acquire就不会阻塞.如果在调用acquire对这个锁上锁之前已经被其他线程上锁了,那么就会阻塞,直到锁被释放为止.
死锁
死锁 : 两个或者两个以上的进程在执行的过程中,因为抢夺资源而造成一种互相等待的现象.如果没有外力作用,将无法进行下去.
避免死锁 : 银行家算法,添加超时时间
import threading, time
num = 0
def test1():
global num
for i in range(100):
mutex.acquire()
num += 1
mutex.release()
print('---test1---', num)
def test2():
global num
for i in range(100):
mutex.acquire()
num += 1
mutex.release()
print('---test2---', num)
if __name__ == '__main__':
mutex = threading.Lock()
mutex1 = threading.Lock()
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
print('主线程:', num)
四、银行家算法
银行家算法 : 操作系统看做银行家,操作系统管理的资源相当于银行家的资金,进程向操作系统请求分配资源相当于用户向银行贷款.银行规定 :
1.当顾客对资金的最大需求量不超过银行现有的资金时才接纳顾客.
2.顾客可以贷款,但是贷款总数不能超过最大需求量.
3.当银行现有的资金不能满足顾客现需的贷款数额时,对顾客的贷款可推迟支付,但是总能让在顾客的有限时间里得到贷款.
4.当顾客得到所需的全部资金后,一定要在有限的时间里归还所有资金.
五、多线程案例
生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题.
生产者和消费者彼此之间不直接通信,而是通过阻塞队列来进行通信,所有生产者生产完数据不用等待消费者处理直接放到阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列获取.这样就解决了因为生产生产速度慢或者消费者消费处理能力造成的资源浪费.
import threading, time, random, multiprocessing
class Producer(threading.Thread):
def __init__(self, name, queue):
threading.Thread.__init__(self, name=name)
# super().父类方法()
# 父类名.父类方法(self)
self.data = queue
def run(self):
for i in range(5):
print('%s正在生产%s' % (self.getName(), i))
self.data.put(i)
time.sleep(random.random())
print('%s生产结束' % self.getName())
class Consumer(threading.Thread):
def __init__(self, name, queue):
threading.Thread.__init__(self, name=name)
self.data = queue
def run(self):
for i in range(5):
value = self.data.get()
print('%s正在消费%s' % (self.name, value))
time.sleep(random.random())
print('%s消费结束' % self.name)
if __name__ == '__main__':
queue = multiprocessing.Queue()
p = Producer('生产者', queue)
c = Consumer('消费者', queue)
p.start()
c.start()
print('线程结束')
关于Python线程的所有介绍今天就到这里啦,后续我会为大家介绍协程的相关知识哦~
关注我,带你领略Python的风采~😍😍😍
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!