HW4 Speaker classification-SIMPLE (TRANSFORMER)
2023-12-22 19:01:00





Task description
Classify the speakers of given features.
Main goal: Learn how to use transformer.
Baselines:
Easy: Run sample code and know how to use transformer.
Medium: Know how to adjust parameters of transformer.
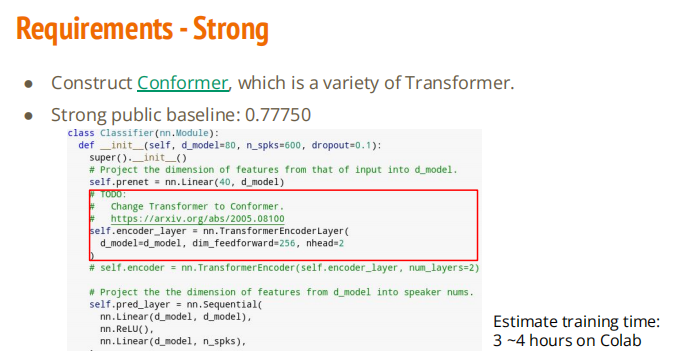
Strong: Construct conformer which is a variety of transformer.
Boss: Implement Self-Attention Pooling & Additive Margin Softmax to further boost the performance.
Other links
Kaggle: [link](https://www.kaggle.com/competitions/ml2022spring-hw4)
Slide: link
Data: link
import torch
import torch.nn as nn
import torch.nn.functional as F
class Classifier(nn.Module):
def __init__(self, d_model=224, n_spks=600, dropout=0.2):
super().__init__()
# Project the dimension of features from that of input into d_model.
self.prenet = nn.Linear(40, d_model)
# TODO:
# Change Transformer to Conformer.
# https://arxiv.org/abs/2005.08100
self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, dim_feedforward=d_model*2, nhead=2, dropout=dropout)
self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=3)
# Project the the dimension of features from d_model into speaker nums.
self.pred_layer = nn.Sequential(
nn.BatchNorm1d(d_model),
#nn.Linear(d_model, d_model),
#nn.ReLU(),
nn.Linear(d_model, n_spks),
)
def forward(self, mels):
"""
args:
mels: (batch size, length, 40)
return:
out: (batch size, n_spks)
"""
# out: (batch size, length, d_model)
out = self.prenet(mels)
# out: (length, batch size, d_model)
out = out.permute(1, 0, 2)
# The encoder layer expect features in the shape of (length, batch size, d_model).
out = self.encoder(out)
# out: (batch size, length, d_model)
out = out.transpose(0, 1)
# mean pooling
stats = out.mean(dim=1)
# out: (batch, n_spks)
out = self.pred_layer(stats)
return out
import torch
import torch.nn as nn
import torch.nn.functional as F
!pip install conformer
from conformer import ConformerBlock
class Classifier(nn.Module):
def __init__(self, d_model=224, n_spks=600, dropout=0.25):
super().__init__()
# Project the dimension of features from that of input into d_model.
self.prenet = nn.Linear(40, d_model)
# TODO:
# Change Transformer to Conformer.
# https://arxiv.org/abs/2005.08100
#self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, dim_feedforward=d_model*2, nhead=2, dropout=dropout)
#self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=3)
self.encoder = ConformerBlock(
dim = d_model,
dim_head = 4,
heads = 4,
ff_mult = 4,
conv_expansion_factor = 2,
conv_kernel_size = 20,
attn_dropout = dropout,
ff_dropout = dropout,
conv_dropout = dropout,
)
# Project the the dimension of features from d_model into speaker nums.
self.pred_layer = nn.Sequential(
nn.BatchNorm1d(d_model),
#nn.Linear(d_model, d_model),
#nn.ReLU(),
nn.Linear(d_model, n_spks),
)
def forward(self, mels):
"""
args:
mels: (batch size, length, 40)
return:
out: (batch size, n_spks)
"""
# out: (batch size, length, d_model)
out = self.prenet(mels)
# out: (length, batch size, d_model)
out = out.permute(1, 0, 2)
# The encoder layer expect features in the shape of (length, batch size, d_model).
out = self.encoder(out)
# out: (batch size, length, d_model)
out = out.transpose(0, 1)
# mean pooling
stats = out.mean(dim=1)
# out: (batch, n_spks)
out = self.pred_layer(stats)
return out
文章来源:https://blog.csdn.net/weixin_39107270/article/details/135153120
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!