Python 架构模式:附录 A 到 E
附录 A:摘要图和表
原文:Appendix A: Summary Diagram and Table
译者:飞龙
这是我们在书的最后看到的架构:
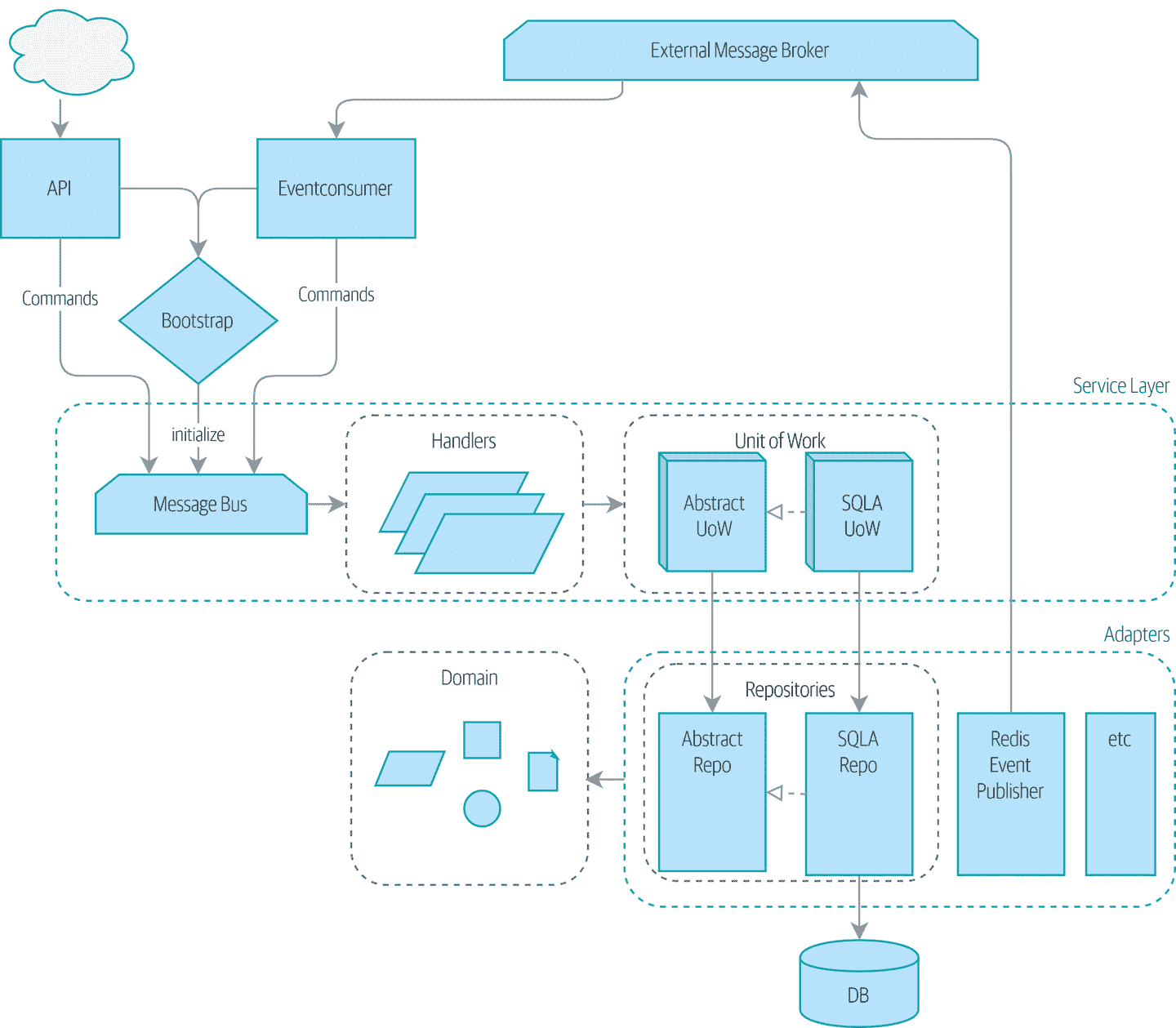
表 A-1 总结了每个模式及其功能。
表 A-1. 我们的架构组件及其功能
| 层 | 组件 | 描述 |
|---|---|---|
| 领域 | 定义业务逻辑。 | |
| 实体 | 一个领域对象,其属性可能会改变,但随着时间的推移具有可识别的身份。 | |
| 值对象 | 一个不可变的领域对象,其属性完全定义它。它可以与其他相同的对象互换。 | |
| 聚合 | 一组相关对象,我们将其视为数据更改的一个单元。定义和强制一致性边界。 | |
| 事件 | 代表发生的事情。 | |
| 命令 | 代表系统应执行的作业。 | |
| 服务层 | 定义系统应执行的作业并协调不同的组件。 | |
| 处理程序 | 接收命令或事件并执行需要发生的操作。 | |
| 工作单元 | 围绕数据完整性的抽象。每个工作单元代表一个原子更新。使存储库可用。跟踪检索到的聚合上的新事件。 | |
| 消息总线(内部) | 通过将命令和事件路由到适当的处理程序来处理命令和事件。 | |
| 适配器(次要) | 接口的具体实现,从我们的系统到外部世界(I/O)。 | |
| 存储库 | 围绕持久存储的抽象。每个聚合都有自己的存储库。 | |
| 事件发布者 | 将事件推送到外部消息总线上。 | |
| 入口点(主要适配器) | 将外部输入转换为对服务层的调用。 | |
| Web | 接收 Web 请求并将其转换为命令,将其传递到内部消息总线。 | |
| 事件消费者 | 从外部消息总线读取事件并将其转换为命令,将其传递到内部消息总线。 | |
| N/A | 外部消息总线(消息代理) |
附录 B:模板项目结构
原文:Appendix B: A Template Project Structure
译者:飞龙
在第四章周围,我们从只在一个文件夹中拥有所有内容转移到了更有结构的树形结构,并且我们认为可能会对梳理各个部分感兴趣。
提示
本附录的代码位于 GitHub 上的 appendix_project_structure 分支中(https://oreil.ly/1rDRC):
git clone https://github.com/cosmicpython/code.git
cd code
git checkout appendix_project_structure
基本的文件夹结构如下:
项目树
.
├── Dockerfile (1)
├── Makefile (2)
├── README.md
├── docker-compose.yml (1)
├── license.txt
├── mypy.ini
├── requirements.txt
├── src (3)
│ ├── allocation
│ │ ├── __init__.py
│ │ ├── adapters
│ │ │ ├── __init__.py
│ │ │ ├── orm.py
│ │ │ └── repository.py
│ │ ├── config.py
│ │ ├── domain
│ │ │ ├── __init__.py
│ │ │ └── model.py
│ │ ├── entrypoints
│ │ │ ├── __init__.py
│ │ │ └── flask_app.py
│ │ └── service_layer
│ │ ├── __init__.py
│ │ └── services.py
│ └── setup.py (3)
└── tests (4)
├── conftest.py (4)
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
├── pytest.ini (4)
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.py
①
我们的docker-compose.yml和我们的Dockerfile是运行我们的应用程序的容器的主要配置部分,它们也可以运行测试(用于 CI)。一个更复杂的项目可能会有几个 Dockerfile,尽管我们发现最小化镜像数量通常是一个好主意。1
②
Makefile提供了开发人员(或 CI 服务器)在其正常工作流程中可能想要运行的所有典型命令的入口点:make build,make test等。2 这是可选的。您可以直接使用docker-compose和pytest,但是如果没有其他选择,将所有“常用命令”列在某个地方是很好的,而且与文档不同,Makefile 是代码,因此不太容易过时。
③
我们应用程序的所有源代码,包括领域模型、Flask 应用程序和基础设施代码,都位于src内的 Python 包中,3我们使用pip install -e和setup.py文件进行安装。这使得导入变得容易。目前,此模块内的结构完全是平面的,但对于更复杂的项目,您可以期望增加一个包含domain_model/、infrastructure/、*services/和api/*的文件夹层次结构。
④
测试位于它们自己的文件夹中。子文件夹区分不同的测试类型,并允许您分别运行它们。我们可以在主测试文件夹中保留共享的固定装置(conftest.py),并在需要时嵌套更具体的固定装置。这也是保留pytest.ini的地方。
提示
pytest 文档在测试布局和可导入性方面非常好。
让我们更详细地看一下这些文件和概念。
环境变量、12 因素和配置,内部和外部容器
我们在这里要解决的基本问题是,我们需要不同的配置设置,用于以下情况:
-
直接从您自己的开发机器运行代码或测试,可能是从 Docker 容器的映射端口进行通信
-
在容器本身上运行,使用“真实”端口和主机名
-
不同的容器环境(开发、暂存、生产等)
通过12 因素宣言建议的环境变量配置将解决这个问题,但具体来说,我们如何在我们的代码和容器中实现它呢?
Config.py
每当我们的应用程序代码需要访问某些配置时,它将从一个名为config.py的文件中获取。以下是我们应用程序中的一些示例:
示例配置函数(src/allocation/config.py)
import os
def get_postgres_uri(): #(1)
host = os.environ.get("DB_HOST", "localhost") #(2)
port = 54321 if host == "localhost" else 5432
password = os.environ.get("DB_PASSWORD", "abc123")
user, db_name = "allocation", "allocation"
return f"postgresql://{user}:{password}@{host}:{port}/{db_name}"
def get_api_url():
host = os.environ.get("API_HOST", "localhost")
port = 5005 if host == "localhost" else 80
return f"http://{host}:{port}"
①
我们使用函数来获取当前的配置,而不是在导入时可用的常量,因为这样可以让客户端代码修改os.environ。
②
config.py还定义了一些默认设置,设计用于在从开发人员的本地机器运行代码时工作。?
一个名为environ-config的优雅 Python 包值得一看,如果您厌倦了手动编写基于环境的配置函数。
提示
不要让这个配置模块成为一个充满了与配置只有模糊关系的东西的倾倒场所,然后在各个地方都导入它。保持事物不可变,并且只通过环境变量进行修改。如果您决定使用引导脚本,您可以将其作为导入配置的唯一位置(除了测试)。
Docker-Compose 和容器配置
我们使用一个轻量级的 Docker 容器编排工具叫做docker-compose。它的主要配置是通过一个 YAML 文件(叹气):?
docker-compose配置文件(docker-compose.yml)
version: "3"
services:
app: #(1)
build:
context: .
dockerfile: Dockerfile
depends_on:
- postgres
environment: #(3)
- DB_HOST=postgres (4)
- DB_PASSWORD=abc123
- API_HOST=app
- PYTHONDONTWRITEBYTECODE=1 #(5)
volumes: #(6)
- ./src:/src
- ./tests:/tests
ports:
- "5005:80" (7)
postgres:
image: postgres:9.6 #(2)
environment:
- POSTGRES_USER=allocation
- POSTGRES_PASSWORD=abc123
ports:
- "54321:5432"
①
在docker-compose文件中,我们定义了我们应用程序所需的不同services(容器)。通常一个主要的镜像包含了我们所有的代码,我们可以使用它来运行我们的 API,我们的测试,或者任何其他需要访问领域模型的服务。
②
您可能会有其他基础设施服务,包括数据库。在生产环境中,您可能不会使用容器;您可能会使用云提供商,但是docker-compose为我们提供了一种在开发或 CI 中生成类似服务的方式。
③
environment部分允许您为容器设置环境变量,主机名和端口,从 Docker 集群内部看到。如果您有足够多的容器,这些信息开始在这些部分中重复,您可以改用environment_file。我们通常称为container.env。
④
在集群内,docker-compose设置了网络,使得容器可以通过其服务名称命名的主机名相互访问。
⑤
专业提示:如果您将卷挂载到本地开发机器和容器之间共享源文件夹,PYTHONDONTWRITEBYTECODE环境变量告诉 Python 不要写入*.pyc*文件,这将使您免受在本地文件系统上到处都是数百万个根文件的困扰,删除起来很烦人,并且会导致奇怪的 Python 编译器错误。
将我们的源代码和测试代码作为volumes挂载意味着我们不需要在每次代码更改时重新构建我们的容器。
ports部分允许我们将容器内部的端口暴露到外部世界?——这些对应于我们在config.py中设置的默认端口。
注意
在 Docker 内部,其他容器可以通过其服务名称命名的主机名访问。在 Docker 外部,它们可以在localhost上访问,在ports部分定义的端口上。
将您的源代码安装为包
我们所有的应用程序代码(除了测试,实际上)都存放在src文件夹内:
src 文件夹
├── src
│ ├── allocation (1)
│ │ ├── config.py
│ │ └── ...
│ └── setup.py (2)
①
子文件夹定义了顶级模块名称。您可以有多个。
②
setup.py是您需要使其可通过 pip 安装的文件,下面会展示。
src/setup.py中的三行可安装的 pip 模块
from setuptools import setup
setup(
name='allocation',
version='0.1',
packages=['allocation'],
)
这就是您需要的全部。packages=指定要安装为顶级模块的子文件夹的名称。name条目只是装饰性的,但是是必需的。对于一个永远不会真正进入 PyPI 的包,它会很好。?
Dockerfile
Dockerfile 将会是非常特定于项目的,但是这里有一些您期望看到的关键阶段:
我们的 Dockerfile(Dockerfile)
FROM python:3.9-slim-buster
(1)
# RUN apt install gcc libpq (no longer needed bc we use psycopg2-binary)
(2)
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
(3)
RUN mkdir -p /src
COPY src/ /src/
RUN pip install -e /src
COPY tests/ /tests/
(4)
WORKDIR /src
ENV FLASK_APP=allocation/entrypoints/flask_app.py FLASK_DEBUG=1 PYTHONUNBUFFERED=1
CMD flask run --host=0.0.0.0 --port=80
①
安装系统级依赖
②
安装我们的 Python 依赖项(您可能希望将开发和生产依赖项分开;为简单起见,我们没有这样做)
③
复制和安装我们的源代码
④
可选配置默认启动命令(您可能经常需要从命令行覆盖这个)
提示
需要注意的一件事是,我们按照它们可能发生变化的频率安装东西的顺序。这使我们能够最大程度地重用 Docker 构建缓存。我无法告诉你这个教训背后有多少痛苦和挫折。有关此问题以及更多 Python Dockerfile 改进提示,请查看“可生产使用的 Docker 打包”。
测试
我们的测试与其他所有内容一起保存,如下所示:
测试文件夹树
└── tests
├── conftest.py
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
├── pytest.ini
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.py
这里没有特别聪明的地方,只是一些不同测试类型的分离,您可能希望单独运行,以及一些用于常见固定装置、配置等的文件。
在测试文件夹中没有src文件夹或setup.py,因为我们通常不需要使测试可通过 pip 安装,但如果您在导入路径方面遇到困难,您可能会发现它有所帮助。
总结
这些是我们的基本构建模块:
-
src文件夹中的源代码,可以使用setup.py进行 pip 安装
-
一些 Docker 配置,用于尽可能模拟生产环境的本地集群
-
通过环境变量进行配置,集中在一个名为config.py的 Python 文件中,其中默认值允许事情在容器外运行
-
一个用于有用的命令行命令的 Makefile
我们怀疑没有人会得到完全与我们相同的解决方案,但我们希望你在这里找到一些灵感。
1 有时将图像分离用于生产和测试是一个好主意,但我们倾向于发现进一步尝试为不同类型的应用程序代码(例如,Web API 与发布/订阅客户端)分离不值得麻烦;在复杂性和更长的重建/CI 时间方面的成本太高。你的情况可能有所不同。
2 一个纯 Python 的 Makefile 替代方案是Invoke,值得一试,如果你的团队每个人都懂 Python(或者至少比 Bash 更懂)。
3 Hynek Schlawack 的“测试和打包”提供了有关src文件夹的更多信息。
? 这为我们提供了一个“只要可能就能工作”的本地开发设置。你可能更喜欢在缺少环境变量时严格失败,特别是如果任何默认值在生产中可能不安全。
? Harry 对 YAML 有点厌倦。它无处不在,但他永远记不住语法或应该如何缩进。
? 在 CI 服务器上,您可能无法可靠地暴露任意端口,但这只是本地开发的便利。您可以找到使这些端口映射可选的方法(例如,使用docker-compose.override.yml)。
? 有关更多setup.py提示,请参阅 Hynek 的这篇关于打包的文章。
附录 C:更换基础设施:使用 CSV 做所有事情
原文:Appendix C: Swapping Out the Infrastructure: Do Everything with CSVs
译者:飞龙
本附录旨在简要说明 Repository、UnitOfWork 和 Service Layer 模式的好处。它旨在从第六章中延伸出来。
就在我们完成构建 Flask API 并准备发布时,业务部门来找我们,道歉地说他们还没有准备好使用我们的 API,并询问我们是否可以构建一个仅从几个 CSV 中读取批次和订单并输出第三个 CSV 的东西。
通常这是一种可能会让团队咒骂、唾弃并为他们的回忆做笔记的事情。但我们不会!哦不,我们已经确保我们的基础设施问题与我们的领域模型和服务层很好地解耦。切换到 CSV 将只是简单地编写一些新的Repository和UnitOfWork类,然后我们就能重用领域层和服务层的所有逻辑。
这是一个 E2E 测试,向您展示 CSV 的流入和流出:
第一个 CSV 测试(tests/e2e/test_csv.py)
def test_cli_app_reads_csvs_with_batches_and_orders_and_outputs_allocations(
make_csv
):
sku1, sku2 = random_ref('s1'), random_ref('s2')
batch1, batch2, batch3 = random_ref('b1'), random_ref('b2'), random_ref('b3')
order_ref = random_ref('o')
make_csv('batches.csv', [
['ref', 'sku', 'qty', 'eta'],
[batch1, sku1, 100, ''],
[batch2, sku2, 100, '2011-01-01'],
[batch3, sku2, 100, '2011-01-02'],
])
orders_csv = make_csv('orders.csv', [
['orderid', 'sku', 'qty'],
[order_ref, sku1, 3],
[order_ref, sku2, 12],
])
run_cli_script(orders_csv.parent)
expected_output_csv = orders_csv.parent / 'allocations.csv'
with open(expected_output_csv) as f:
rows = list(csv.reader(f))
assert rows == [
['orderid', 'sku', 'qty', 'batchref'],
[order_ref, sku1, '3', batch1],
[order_ref, sku2, '12', batch2],
]
毫无思考地实现并不考虑存储库和所有那些花哨东西,你可能会从这样的东西开始:
我们的 CSV 读取器/写入器的第一个版本(src/bin/allocate-from-csv)
#!/usr/bin/env python
import csv
import sys
from datetime import datetime
from pathlib import Path
from allocation import model
def load_batches(batches_path):
batches = []
with batches_path.open() as inf:
reader = csv.DictReader(inf)
for row in reader:
if row['eta']:
eta = datetime.strptime(row['eta'], '%Y-%m-%d').date()
else:
eta = None
batches.append(model.Batch(
ref=row['ref'],
sku=row['sku'],
qty=int(row['qty']),
eta=eta
))
return batches
def main(folder):
batches_path = Path(folder) / 'batches.csv'
orders_path = Path(folder) / 'orders.csv'
allocations_path = Path(folder) / 'allocations.csv'
batches = load_batches(batches_path)
with orders_path.open() as inf, allocations_path.open('w') as outf:
reader = csv.DictReader(inf)
writer = csv.writer(outf)
writer.writerow(['orderid', 'sku', 'batchref'])
for row in reader:
orderid, sku = row['orderid'], row['sku']
qty = int(row['qty'])
line = model.OrderLine(orderid, sku, qty)
batchref = model.allocate(line, batches)
writer.writerow([line.orderid, line.sku, batchref])
if __name__ == '__main__':
main(sys.argv[1])
看起来还不错!而且我们正在重用我们的领域模型对象和领域服务。
但这不会起作用。现有的分配也需要成为我们永久 CSV 存储的一部分。我们可以编写第二个测试来迫使我们改进事情:
另一个,带有现有分配(tests/e2e/test_csv.py)
def test_cli_app_also_reads_existing_allocations_and_can_append_to_them(
make_csv
):
sku = random_ref('s')
batch1, batch2 = random_ref('b1'), random_ref('b2')
old_order, new_order = random_ref('o1'), random_ref('o2')
make_csv('batches.csv', [
['ref', 'sku', 'qty', 'eta'],
[batch1, sku, 10, '2011-01-01'],
[batch2, sku, 10, '2011-01-02'],
])
make_csv('allocations.csv', [
['orderid', 'sku', 'qty', 'batchref'],
[old_order, sku, 10, batch1],
])
orders_csv = make_csv('orders.csv', [
['orderid', 'sku', 'qty'],
[new_order, sku, 7],
])
run_cli_script(orders_csv.parent)
expected_output_csv = orders_csv.parent / 'allocations.csv'
with open(expected_output_csv) as f:
rows = list(csv.reader(f))
assert rows == [
['orderid', 'sku', 'qty', 'batchref'],
[old_order, sku, '10', batch1],
[new_order, sku, '7', batch2],
]
我们可以继续对load_batches函数进行修改并添加额外的行,以及一种跟踪和保存新分配的方式,但我们已经有了一个可以做到这一点的模型!它叫做我们的 Repository 和 UnitOfWork 模式。
我们需要做的(“我们需要做的”)只是重新实现相同的抽象,但是以 CSV 作为基础,而不是数据库。正如您将看到的,这确实相对简单。
为 CSV 实现 Repository 和 UnitOfWork
一个基于 CSV 的存储库可能看起来像这样。它将磁盘上读取 CSV 的所有逻辑抽象出来,包括它必须读取两个不同的 CSV(一个用于批次,一个用于分配),并且它给我们提供了熟悉的.list() API,这提供了一个领域对象的内存集合的幻觉:
使用 CSV 作为存储机制的存储库(src/allocation/service_layer/csv_uow.py)
class CsvRepository(repository.AbstractRepository):
def __init__(self, folder):
self._batches_path = Path(folder) / 'batches.csv'
self._allocations_path = Path(folder) / 'allocations.csv'
self._batches = {} # type: Dict[str, model.Batch]
self._load()
def get(self, reference):
return self._batches.get(reference)
def add(self, batch):
self._batches[batch.reference] = batch
def _load(self):
with self._batches_path.open() as f:
reader = csv.DictReader(f)
for row in reader:
ref, sku = row['ref'], row['sku']
qty = int(row['qty'])
if row['eta']:
eta = datetime.strptime(row['eta'], '%Y-%m-%d').date()
else:
eta = None
self._batches[ref] = model.Batch(
ref=ref, sku=sku, qty=qty, eta=eta
)
if self._allocations_path.exists() is False:
return
with self._allocations_path.open() as f:
reader = csv.DictReader(f)
for row in reader:
batchref, orderid, sku = row['batchref'], row['orderid'], row['sku']
qty = int(row['qty'])
line = model.OrderLine(orderid, sku, qty)
batch = self._batches[batchref]
batch._allocations.add(line)
def list(self):
return list(self._batches.values())
这是一个用于 CSV 的 UoW 会是什么样子的示例:
用于 CSV 的 UoW:commit = csv.writer(src/allocation/service_layer/csv_uow.py)
class CsvUnitOfWork(unit_of_work.AbstractUnitOfWork):
def __init__(self, folder):
self.batches = CsvRepository(folder)
def commit(self):
with self.batches._allocations_path.open('w') as f:
writer = csv.writer(f)
writer.writerow(['orderid', 'sku', 'qty', 'batchref'])
for batch in self.batches.list():
for line in batch._allocations:
writer.writerow(
[line.orderid, line.sku, line.qty, batch.reference]
)
def rollback(self):
pass
一旦我们做到了,我们用于读取和写入批次和分配到 CSV 的 CLI 应用程序将被简化为它应该有的东西——一些用于读取订单行的代码,以及一些调用我们现有服务层的代码:
用九行代码实现 CSV 的分配(src/bin/allocate-from-csv)
def main(folder):
orders_path = Path(folder) / 'orders.csv'
uow = csv_uow.CsvUnitOfWork(folder)
with orders_path.open() as f:
reader = csv.DictReader(f)
for row in reader:
orderid, sku = row['orderid'], row['sku']
qty = int(row['qty'])
services.allocate(orderid, sku, qty, uow)
哒哒!现在你们是不是印象深刻了?
Much love,
Bob and Harry
附录 D:使用 Django 的存储库和工作单元模式
原文:Appendix D: Repository and Unit of Work Patterns with Django
译者:飞龙
假设你想使用 Django 而不是 SQLAlchemy 和 Flask。事情可能会是什么样子?首先要选择安装的位置。我们将其放在与我们的主要分配代码相邻的一个单独的包中:
├── src
│ ├── allocation
│ │ ├── __init__.py
│ │ ├── adapters
│ │ │ ├── __init__.py
...
│ ├── djangoproject
│ │ ├── alloc
│ │ │ ├── __init__.py
│ │ │ ├── apps.py
│ │ │ ├── migrations
│ │ │ │ ├── 0001_initial.py
│ │ │ │ └── __init__.py
│ │ │ ├── models.py
│ │ │ └── views.py
│ │ ├── django_project
│ │ │ ├── __init__.py
│ │ │ ├── settings.py
│ │ │ ├── urls.py
│ │ │ └── wsgi.py
│ │ └── manage.py
│ └── setup.py
└── tests
├── conftest.py
├── e2e
│ └── test_api.py
├── integration
│ ├── test_repository.py
...
提示
这个附录的代码在 GitHub 的 appendix_django 分支中GitHub:
git clone https://github.com/cosmicpython/code.git
cd code
git checkout appendix_django
使用 Django 的存储库模式
我们使用了一个名为pytest-django的插件来帮助管理测试数据库。
重写第一个存储库测试是一个最小的改变 - 只是用 Django ORM/QuerySet 语言重写了一些原始 SQL:
第一个存储库测试适应(tests/integration/test_repository.py)
from djangoproject.alloc import models as django_models
@pytest.mark.django_db
def test_repository_can_save_a_batch():
batch = model.Batch("batch1", "RUSTY-SOAPDISH", 100, eta=date(2011, 12, 25))
repo = repository.DjangoRepository()
repo.add(batch)
[saved_batch] = django_models.Batch.objects.all()
assert saved_batch.reference == batch.reference
assert saved_batch.sku == batch.sku
assert saved_batch.qty == batch._purchased_quantity
assert saved_batch.eta == batch.eta
第二个测试涉及的内容更多,因为它有分配,但它仍然由熟悉的 Django 代码组成:
第二个存储库测试更复杂(tests/integration/test_repository.py)
@pytest.mark.django_db
def test_repository_can_retrieve_a_batch_with_allocations():
sku = "PONY-STATUE"
d_line = django_models.OrderLine.objects.create(orderid="order1", sku=sku, qty=12)
d_b1 = django_models.Batch.objects.create(
reference="batch1", sku=sku, qty=100, eta=None
)
d_b2 = django_models.Batch.objects.create(
reference="batch2", sku=sku, qty=100, eta=None
)
django_models.Allocation.objects.create(line=d_line, batch=d_batch1)
repo = repository.DjangoRepository()
retrieved = repo.get("batch1")
expected = model.Batch("batch1", sku, 100, eta=None)
assert retrieved == expected # Batch.__eq__ only compares reference
assert retrieved.sku == expected.sku
assert retrieved._purchased_quantity == expected._purchased_quantity
assert retrieved._allocations == {
model.OrderLine("order1", sku, 12),
}
这是实际存储库的最终外观:
一个 Django 存储库(src/allocation/adapters/repository.py)
class DjangoRepository(AbstractRepository):
def add(self, batch):
super().add(batch)
self.update(batch)
def update(self, batch):
django_models.Batch.update_from_domain(batch)
def _get(self, reference):
return django_models.Batch.objects.filter(
reference=reference
).first().to_domain()
def list(self):
return [b.to_domain() for b in django_models.Batch.objects.all()]
你可以看到,实现依赖于 Django 模型具有一些自定义方法,用于转换到我们的领域模型和从领域模型转换。1
Django ORM 类上的自定义方法,用于转换到/从我们的领域模型
这些自定义方法看起来像这样:
Django ORM 与领域模型转换的自定义方法(src/djangoproject/alloc/models.py)
from django.db import models
from allocation.domain import model as domain_model
class Batch(models.Model):
reference = models.CharField(max_length=255)
sku = models.CharField(max_length=255)
qty = models.IntegerField()
eta = models.DateField(blank=True, null=True)
@staticmethod
def update_from_domain(batch: domain_model.Batch):
try:
b = Batch.objects.get(reference=batch.reference) #(1)
except Batch.DoesNotExist:
b = Batch(reference=batch.reference) #(1)
b.sku = batch.sku
b.qty = batch._purchased_quantity
b.eta = batch.eta #(2)
b.save()
b.allocation_set.set(
Allocation.from_domain(l, b) #(3)
for l in batch._allocations
)
def to_domain(self) -> domain_model.Batch:
b = domain_model.Batch(
ref=self.reference, sku=self.sku, qty=self.qty, eta=self.eta
)
b._allocations = set(
a.line.to_domain()
for a in self.allocation_set.all()
)
return b
class OrderLine(models.Model):
#...
①
对于值对象,objects.get_or_create 可以工作,但对于实体,你可能需要一个显式的 try-get/except 来处理 upsert。2
②
我们在这里展示了最复杂的例子。如果你决定这样做,请注意会有样板代码!幸运的是,它并不是非常复杂的样板代码。
③
关系也需要一些谨慎的自定义处理。
注意
就像在第二章中一样,我们使用了依赖反转。ORM(Django)依赖于模型,而不是相反。
使用 Django 的工作单元模式
测试并没有太大改变:
适应的 UoW 测试(tests/integration/test_uow.py)
def insert_batch(ref, sku, qty, eta): #(1)
django_models.Batch.objects.create(reference=ref, sku=sku, qty=qty, eta=eta)
def get_allocated_batch_ref(orderid, sku): #(1)
return django_models.Allocation.objects.get(
line__orderid=orderid, line__sku=sku
).batch.reference
@pytest.mark.django_db(transaction=True)
def test_uow_can_retrieve_a_batch_and_allocate_to_it():
insert_batch("batch1", "HIPSTER-WORKBENCH", 100, None)
uow = unit_of_work.DjangoUnitOfWork()
with uow:
batch = uow.batches.get(reference="batch1")
line = model.OrderLine("o1", "HIPSTER-WORKBENCH", 10)
batch.allocate(line)
uow.commit()
batchref = get_allocated_batch_ref("o1", "HIPSTER-WORKBENCH")
assert batchref == "batch1"
@pytest.mark.django_db(transaction=True) #(2)
def test_rolls_back_uncommitted_work_by_default():
...
@pytest.mark.django_db(transaction=True) #(2)
def test_rolls_back_on_error():
...
①
因为在这些测试中有一些小的辅助函数,所以实际的测试主体基本上与 SQLAlchemy 时一样。
②
pytest-django mark.django_db(transaction=True) 是必须的,用于测试我们的自定义事务/回滚行为。
实现相当简单,尽管我尝试了几次才找到 Django 事务魔法的调用:
适用于 Django 的 UoW(src/allocation/service_layer/unit_of_work.py)
class DjangoUnitOfWork(AbstractUnitOfWork):
def __enter__(self):
self.batches = repository.DjangoRepository()
transaction.set_autocommit(False) #(1)
return super().__enter__()
def __exit__(self, *args):
super().__exit__(*args)
transaction.set_autocommit(True)
def commit(self):
for batch in self.batches.seen: #(3)
self.batches.update(batch) #(3)
transaction.commit() #(2)
def rollback(self):
transaction.rollback() #(2)
①
set_autocommit(False) 是告诉 Django 停止自动立即提交每个 ORM 操作,并开始一个事务的最佳方法。
②
然后我们使用显式回滚和提交。
③
一个困难:因为与 SQLAlchemy 不同,我们不是在领域模型实例本身上进行检测,commit() 命令需要显式地通过每个存储库触及的所有对象,并手动将它们更新回 ORM。
API:Django 视图是适配器
Django 的views.py文件最终几乎与旧的flask_app.py相同,因为我们的架构意味着它是围绕我们的服务层(顺便说一句,服务层没有改变)的一个非常薄的包装器:
Flask app → Django views (src/djangoproject/alloc/views.py)
os.environ['DJANGO_SETTINGS_MODULE'] = 'djangoproject.django_project.settings'
django.setup()
@csrf_exempt
def add_batch(request):
data = json.loads(request.body)
eta = data['eta']
if eta is not None:
eta = datetime.fromisoformat(eta).date()
services.add_batch(
data['ref'], data['sku'], data['qty'], eta,
unit_of_work.DjangoUnitOfWork(),
)
return HttpResponse('OK', status=201)
@csrf_exempt
def allocate(request):
data = json.loads(request.body)
try:
batchref = services.allocate(
data['orderid'],
data['sku'],
data['qty'],
unit_of_work.DjangoUnitOfWork(),
)
except (model.OutOfStock, services.InvalidSku) as e:
return JsonResponse({'message': str(e)}, status=400)
return JsonResponse({'batchref': batchref}, status=201)
为什么这么难?
好吧,它可以工作,但感觉比 Flask/SQLAlchemy 要费力。为什么呢?
在低级别上的主要原因是因为 Django 的 ORM 工作方式不同。我们没有 SQLAlchemy 经典映射器的等价物,因此我们的ActiveRecord和领域模型不能是同一个对象。相反,我们必须在存储库后面构建一个手动翻译层。这是更多的工作(尽管一旦完成,持续的维护负担不应该太高)。
由于 Django 与数据库紧密耦合,您必须使用诸如pytest-django之类的辅助工具,并从代码的第一行开始仔细考虑测试数据库的使用方式,这是我们在纯领域模型开始时不必考虑的。
但在更高的层面上,Django 之所以如此出色的原因是,它的设计围绕着使构建具有最少样板的 CRUD 应用程序变得容易的最佳点。但我们的整本书的主要内容是关于当您的应用程序不再是一个简单的 CRUD 应用程序时该怎么办。
在那一点上,Django 开始妨碍而不是帮助。像 Django 管理这样的东西,在您开始时非常棒,但如果您的应用程序的整个目的是围绕状态更改的工作流程构建一套复杂的规则和建模,那么它们就会变得非常危险。Django 管理绕过了所有这些。
如果您已经有 Django,该怎么办
那么,如果您想将本书中的一些模式应用于 Django 应用程序,您应该怎么做呢?我们建议如下:
-
存储库和工作单元模式将需要相当多的工作。它们在短期内将为您带来的主要好处是更快的单元测试,因此请评估在您的情况下是否值得这种好处。在长期内,它们将使您的应用程序与 Django 和数据库解耦,因此,如果您预计希望迁移到其中任何一个,存储库和 UoW 是一个好主意。
-
如果您在views.py中看到很多重复,可能会对服务层模式感兴趣。这是一种很好的方式,可以让您将用例与 Web 端点分开思考。
-
您仍然可以在 Django 模型中进行 DDD 和领域建模,尽管它们与数据库紧密耦合;您可能会因迁移而放慢速度,但这不应该是致命的。因此,只要您的应用程序不太复杂,测试速度不太慢,您可能会从fat models方法中获益:尽可能将大部分逻辑下推到模型中,并应用实体、值对象和聚合等模式。但是,请参见以下警告。
话虽如此,Django 社区中的一些人发现,fat models方法本身也会遇到可扩展性问题,特别是在管理应用程序之间的相互依赖方面。在这些情况下,将业务逻辑或领域层提取出来,放置在视图和表单以及models.py之间,可以尽可能地保持其最小化。
途中的步骤
假设您正在开发一个 Django 项目,您不确定是否会变得足够复杂,以至于需要我们推荐的模式,但您仍然希望采取一些步骤,以使您的生活在中期更轻松,并且如果以后要迁移到我们的一些模式中,也更轻松。考虑以下内容:
-
我们听到的一个建议是从第一天开始在每个 Django 应用程序中放置一个logic.py。这为您提供了一个放置业务逻辑的地方,并使您的表单、视图和模型免于业务逻辑。这可以成为迈向完全解耦的领域模型和/或服务层的垫脚石。
-
业务逻辑层可能开始使用 Django 模型对象,只有在以后才会完全脱离框架,并在纯 Python 数据结构上工作。
-
对于读取方面,您可以通过将读取放入一个地方来获得 CQRS 的一些好处,避免在各个地方散布 ORM 调用。
-
在为读取和领域逻辑分离模块时,值得脱离 Django 应用程序层次结构。业务问题将贯穿其中。
注意
我们想要向 David Seddon 和 Ashia Zawaduk 致敬,因为他们讨论了附录中的一些想法。他们尽力阻止我们在我们没有足够个人经验的话题上说出任何愚蠢的话,但他们可能失败了。
有关处理现有应用程序的更多想法和实际经验,请参阅附录。
DRY-Python 项目的人们构建了一个名为 mappers 的工具,看起来可能有助于最小化这种事情的样板文件。
@mr-bo-jangles建议您可以使用update_or_create,但这超出了我们的 Django-fu。
附录 E:验证
译者:飞龙
每当我们教授和讨论这些技术时,一个反复出现的问题是“我应该在哪里进行验证?这属于我的业务逻辑在领域模型中,还是属于基础设施问题?”
与任何架构问题一样,答案是:这取决于情况!
最重要的考虑因素是我们希望保持我们的代码良好分离,以便系统的每个部分都很简单。我们不希望用无关的细节来混淆我们的代码。
验证到底是什么?
当人们使用验证这个词时,他们通常指的是一种过程,通过这种过程测试操作的输入,以确保它们符合某些标准。符合标准的输入被认为是有效的,而不符合标准的输入被认为是无效的。
如果输入无效,则操作无法继续,但应该以某种错误退出。换句话说,验证是关于创建前提条件。我们发现将我们的前提条件分为三个子类型:语法、语义和语用是有用的。
验证语法
在语言学中,语言的语法是指控制语法句子结构的规则集。例如,在英语中,“Allocate three units of TASTELESS-LAMP to order twenty-seven”是语法正确的,而短语“hat hat hat hat hat hat wibble”则不是。我们可以将语法正确的句子描述为格式良好。
这如何映射到我们的应用程序?以下是一些语法规则的示例:
-
一个
Allocate命令必须有一个订单 ID、一个 SKU 和一个数量。 -
数量是一个正整数。
-
SKU 是一个字符串。
这些是关于传入数据的形状和结构的规则。一个没有 SKU 或订单 ID 的Allocate命令不是一个有效的消息。这相当于短语“Allocate three to.”
我们倾向于在系统的边缘验证这些规则。我们的经验法则是,消息处理程序应始终只接收格式良好且包含所有必需信息的消息。
一种选择是将验证逻辑放在消息类型本身上:
消息类上的验证(src/allocation/commands.py)
from schema import And, Schema, Use
@dataclass
class Allocate(Command):
_schema = Schema({ #(1)
'orderid': int,
sku: str,
qty: And(Use(int), lambda n: n > 0)
}, ignore_extra_keys=True)
orderid: str
sku: str
qty: int
@classmethod
def from_json(cls, data): #(2)
data = json.loads(data)
return cls(**_schema.validate(data))
①
schema库让我们以一种好的声明方式描述消息的结构和验证。
②
from_json方法将字符串读取为 JSON,并将其转换为我们的消息类型。
不过这可能会变得重复,因为我们需要两次指定我们的字段,所以我们可能希望引入一个辅助库,可以统一验证和声明我们的消息类型:
带有模式的命令工厂(src/allocation/commands.py)
def command(name, **fields): #(1)
schema = Schema(And(Use(json.loads), fields), ignore_extra_keys=True)
cls = make_dataclass(name, fields.keys()) #(2)
cls.from_json = lambda s: cls(**schema.validate(s)) #(3)
return cls
def greater_than_zero(x):
return x > 0
quantity = And(Use(int), greater_than_zero) #(4)
Allocate = command( #(5)
orderid=int,
sku=str,
qty=quantity
)
AddStock = command(
sku=str,
qty=quantity
①
command函数接受一个消息名称,以及消息有效负载字段的 kwargs,其中 kwarg 的名称是字段的名称,值是解析器。
②
我们使用数据类模块的make_dataclass函数动态创建我们的消息类型。
③
我们将from_json方法打补丁到我们的动态数据类上。
④
我们可以创建可重用的解析器来解析数量、SKU 等,以保持代码的 DRY。
⑤
声明消息类型变成了一行代码。
这是以失去数据类上的类型为代价的,所以要考虑这种权衡。
Postel’s Law 和宽容读者模式
Postel’s law,或者鲁棒性原则,告诉我们,“在接受时要宽容,在发出时要保守。”我们认为这在与其他系统集成的情境中特别适用。这里的想法是,当我们向其他系统发送消息时,我们应该严格要求,但在接收他人消息时尽可能宽容。
例如,我们的系统可以验证 SKU 的格式。我们一直在使用像UNFORGIVING-CUSHION和MISBEGOTTEN-POUFFE这样的虚构 SKU。这遵循一个简单的模式:由破折号分隔的两个单词,其中第二个单词是产品类型,第一个单词是形容词。
开发人员喜欢验证消息中的这种内容,并拒绝任何看起来像无效 SKU 的内容。当某个无政府主义者发布名为COMFY-CHAISE-LONGUE的产品或供应商出现问题导致CHEAP-CARPET-2的发货时,这将在后续过程中造成可怕的问题。
实际上,作为分配系统,SKU 的格式与我们无关。我们只需要一个标识符,所以我们可以简单地将其描述为一个字符串。这意味着采购系统可以随时更改格式,而我们不会在意。
同样的原则适用于订单号、客户电话号码等。在大多数情况下,我们可以忽略字符串的内部结构。
同样,开发人员喜欢使用 JSON Schema 等工具验证传入消息,或构建验证传入消息并在系统之间共享的库。这同样无法通过健壮性测试。
例如,假设采购系统向“ChangeBatchQuantity”消息添加了记录更改原因和负责更改的用户电子邮件的新字段。
由于这些字段对分配服务并不重要,我们应该简单地忽略它们。我们可以通过传递关键字参数ignore_extra_keys=True来在schema库中实现这一点。
这种模式,即我们仅提取我们关心的字段并对它们进行最小的验证,就是宽容读者模式。
提示
尽量少进行验证。只读取您需要的字段,不要过度指定它们的内容。这将有助于您的系统在其他系统随着时间的变化而保持健壮。抵制在系统之间共享消息定义的诱惑:相反,使定义您所依赖的数据变得容易。有关更多信息,请参阅 Martin Fowler 的文章Tolerant Reader pattern。
在边缘验证
我们曾经说过,我们希望避免在我们的代码中充斥着无关的细节。特别是,我们不希望在我们的领域模型内部进行防御性编码。相反,我们希望确保在我们的领域模型或用例处理程序看到它们之前,已知请求是有效的。这有助于我们的代码在长期内保持干净和可维护。我们有时将其称为在系统边缘进行验证。
除了保持您的代码干净并且没有无休止的检查和断言之外,要记住,系统中漫游的无效数据就像是一颗定时炸弹;它越深入,造成的破坏就越大,而您可以用来应对它的工具就越少。
在第八章中,我们说消息总线是一个很好的放置横切关注点的地方,验证就是一个完美的例子。以下是我们如何改变我们的总线来执行验证的方式:
验证
class MessageBus:
def handle_message(self, name: str, body: str):
try:
message_type = next(mt for mt in EVENT_HANDLERS if mt.__name__ == name)
message = message_type.from_json(body)
self.handle([message])
except StopIteration:
raise KeyError(f"Unknown message name {name}")
except ValidationError as e:
logging.error(
f'invalid message of type {name}\n'
f'{body}\n'
f'{e}'
)
raise e
以下是我们如何从我们的 Flask API 端点使用该方法:
API 在处理 Redis 消息时出现验证错误(src/allocation/flask_app.py)
@app.route("/change_quantity", methods=['POST'])
def change_batch_quantity():
try:
bus.handle_message('ChangeBatchQuantity', request.body)
except ValidationError as e:
return bad_request(e)
except exceptions.InvalidSku as e:
return jsonify({'message': str(e)}), 400
def bad_request(e: ValidationError):
return e.code, 400
以下是我们如何将其插入到我们的异步消息处理器中:
处理 Redis 消息时出现验证错误(src/allocation/redis_pubsub.py)
def handle_change_batch_quantity(m, bus: messagebus.MessageBus):
try:
bus.handle_message('ChangeBatchQuantity', m)
except ValidationError:
print('Skipping invalid message')
except exceptions.InvalidSku as e:
print(f'Unable to change stock for missing sku {e}')
请注意,我们的入口点仅关注如何从外部世界获取消息以及如何报告成功或失败。我们的消息总线负责验证我们的请求并将其路由到正确的处理程序,而我们的处理程序则专注于用例的逻辑。
提示
当您收到无效的消息时,通常除了记录错误并继续之外,你几乎无能为力。在 MADE,我们使用指标来计算系统接收的消息数量,以及其中有多少成功处理、跳过或无效。如果我们看到坏消息数量的激增,我们的监控工具会向我们发出警报。
验证语义
虽然语法涉及消息的结构,语义是对消息中含义的研究。句子“Undo no dogs from ellipsis four”在语法上是有效的,并且与句子“Allocate one teapot to order five”具有相同的结构,但它是毫无意义的。
我们可以将这个 JSON 块解读为一个“分配”命令,但无法成功执行它,因为它是无意义的:
一个毫无意义的消息
{
"orderid": "superman",
"sku": "zygote",
"qty": -1
}
我们倾向于在消息处理程序层验证语义关注点,采用一种基于合同的编程:
前提条件(src/allocation/ensure.py)
"""
This module contains preconditions that we apply to our handlers.
"""
class MessageUnprocessable(Exception): #(1)
def __init__(self, message):
self.message = message
class ProductNotFound(MessageUnprocessable): #(2)
""""
This exception is raised when we try to perform an action on a product
that doesn't exist in our database.
""""
def __init__(self, message):
super().__init__(message)
self.sku = message.sku
def product_exists(event, uow): #(3)
product = uow.products.get(event.sku)
if product is None:
raise ProductNotFound(event)
①
我们使用一个通用的错误基类,表示消息无效。
②
为此问题使用特定的错误类型使得更容易报告和处理错误。例如,将ProductNotFound映射到 Flask 中的 404 很容易。
③
product_exists是一个前提条件。如果条件为False,我们会引发一个错误。
这样可以使我们的服务层的主要逻辑保持清晰和声明式:
在服务中确保调用(src/allocation/services.py)
# services.py
from allocation import ensure
def allocate(event, uow):
line = mode.OrderLine(event.orderid, event.sku, event.qty)
with uow:
ensure.product_exists(uow, event)
product = uow.products.get(line.sku)
product.allocate(line)
uow.commit()
我们可以扩展这个技术,以确保我们幂等地应用消息。例如,我们希望确保我们不会多次插入一批库存。
如果我们被要求创建一个已经存在的批次,我们将记录一个警告并继续下一个消息:
为可忽略的事件引发 SkipMessage 异常(src/allocation/services.py)
class SkipMessage (Exception):
""""
This exception is raised when a message can't be processed, but there's no
incorrect behavior. For example, we might receive the same message multiple
times, or we might receive a message that is now out of date.
""""
def __init__(self, reason):
self.reason = reason
def batch_is_new(self, event, uow):
batch = uow.batches.get(event.batchid)
if batch is not None:
raise SkipMessage(f"Batch with id {event.batchid} already exists")
引入SkipMessage异常让我们以一种通用的方式处理这些情况在我们的消息总线中:
公交车现在知道如何跳过(src/allocation/messagebus.py)
class MessageBus:
def handle_message(self, message):
try:
...
except SkipMessage as e:
logging.warn(f"Skipping message {message.id} because {e.reason}")
这里需要注意一些陷阱。首先,我们需要确保我们使用的是与用例的主要逻辑相同的 UoW。否则,我们会让自己遭受恼人的并发错误。
其次,我们应该尽量避免将所有业务逻辑都放入这些前提条件检查中。作为一个经验法则,如果一个规则可以在我们的领域模型内进行测试,那么它应该在领域模型中进行测试。
验证语用学
语用学是研究我们如何在语境中理解语言的学科。在解析消息并理解其含义之后,我们仍然需要在上下文中处理它。例如,如果你在拉取请求上收到一条评论说“我认为这非常勇敢”,这可能意味着评论者钦佩你的勇气,除非他们是英国人,在这种情况下,他们试图告诉你你正在做的事情是非常冒险的,只有愚蠢的人才会尝试。上下文是一切。
提示
一旦在系统边缘验证了命令的语法和语义,领域就是其余验证的地方。验证语用学通常是业务规则的核心部分。
在软件术语中,操作的语用学通常由领域模型管理。当我们收到像“allocate three million units of SCARCE-CLOCK to order 76543”这样的消息时,消息在语法上有效且语义上有效,但我们无法遵守,因为我们没有库存可用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!