Prometheus 监控笔记(1):你真的会玩监控吗?
认识Prometheus
Prometheus 是一种开源的系统和服务监控工具,最初由 SoundCloud 开发,后来成为继 Kubernetes 之后云原生生态系统中的一部分。在 Kubernetes 容器管理系统中,通常会搭配 Prometheus 进行监控,同时也支持多种 Exporter 采集数据,还支持 Pushgateway 进行数据上报, Prometheus 性能足够支撑上万台规模的集群,大部分中小企业单台 Prometheus 完全满足需求,如果有高可用的需求,可以直接通过 联邦机制 或者 远程读写 实现。

数据模型: Prometheus 使用一种基于键值对的时间序列数据模型。监控数据被表示为一系列标签的时间序列,其中包含指标的名称和关联的键值对标签。比如下面的数据表示为某一个时刻:
<metric name>{<label name>=<label value>, ...}
<指标名称>{指标标签=指标标签值, ...}
# 示例 某台网络交换机某一个时间戳接口流量
ifHCInOctets{auth="public_v2", brand="Huawei", hostname="switch", ifAlias="demo", ifName="GigabitEthernet0/0/6", ifOperStatus="1", instance="172.17.32.133", job="huawei_sw", model="S5720S-52P-LI-AC", module="huawei_common,huawei_agg"} 171077793119
数据采集: Prometheus 通过 HTTP 协议定期拉取( pull )目标系统的指标数据。这种模型与传统的推送( push )模型不同,允许 Prometheus 更灵活地控制数据的采集频率和方式。
查询语言: Prometheus 提供 PromQL( Prometheus Query Language )用于实时查询和分析时间序列数据。 PromQL 支持聚合、筛选和操作时间序列数据,使用户能够生成丰富的监控仪表板和警报规则。
多维度数据: Prometheus 通过标签为时间序列数据引入多维度的概念,使得数据的查询和分析更加灵活。这也有助于更好地理解系统的性能和行为。
告警与警报: Prometheus 允许用户定义基于查询表达式的警报规则,并能够将警报发送到不同的接收端,如电子邮件、企业微信、Slack、Webhook等。
持久化存储: Prometheus 自带一种本地的时间序列数据库,用于存储采集到的数据。这种本地存储方案对于快速的数据查询和分析非常有利。
可视化: Prometheus 通常与 Grafana 等可视化工具结合使用,以创建各种监控仪表板,直观地展示系统的性能和状态。
云原生生态系统: Prometheus 已成为云原生生态系统的标准监控工具,与 Kubernetes 等容器编排系统集成良好。
社区支持: 由于其强大的功能和广泛的社区支持, Prometheus 在开源监控领域具有很高的影响力,并被许多组织和项目广泛采用。
总体而言, Prometheus 是一款灵活、强大且易于部署的监控系统,适用于监控各种规模和类型的系统和服务,由于生态庞大,很多开源项目和组件都拥抱 Prometheus ,并且出现了一批拥抱 Prometheus 生态开源的第三方监控项目:比如国内比较好用的夜莺等等。
微信公众号:网络小斐
Prometheus解决什么问题
到现在为止 Prometheus 提供的工具或与其他生态系统组件集成可以提供完整的监控管道:
- 检测(跟踪和暴露指标)
- 指标收集
- 指标存储
- 查询指标,用于报警、仪表板等
Prometheus 具有足够的通用性,可以监控各个级别的实例:你自己的应用程序、第三方服务、中间件、主机或网络设备等等。此外 Prometheus 特别适用于监控动态云环境和 Kubernetes 云原生环境。
Prometheus 没有解决的问题,主要是可观测性三大支柱的日志和链路,Prometheus主要关注指标监控。
- 日志和追踪(Prometheus 只处理指标,也称为时间序列)
- 基于机器学习或 AI 的异常检测
- 水平扩展、集群化的存储
这些功能显然也是非常有价值的,但是 Prometheus 本身并没有尝试去解决,而是留给了第三方解决方案。比如:日志和链路追踪业界有专门的相关产品解决方案;而存储, Prometheus 开放了远程存储读写的接口,把接口开放出来留给第三方去解决,比如: Thanos 、 VictoriaMetrics 等等。
和其他监控相比有那些优势呢?
整体来说与其他监控解决方案相比, Prometheus 提供了许多重要功能:
- 多维数据模型,允许对指标进行跟踪
- 强大的查询语言(
PromQL) - 时间序列处理和报警的整合
- 与服务发现集成来确定应监控的内容
- 操作简单
- 执行高效
单节点部署操作简单
Prometheus 的整个概念很简单并且操作也非常简单。 Prometheus 用 Go 编写,直接使用独立的二进制文件即可部署,而无需依赖外部运行时(例如 JVM )、解释器(例如 Python 或 Ruby )或共享系统库。
每个 Prometheus 服务器都独立于任何其他 Prometheus 服务器收集数据并评估报警规则,并且仅在本地存储数据,而没有严格的集群或副本。(集群和副本可用其他时序数据库解决)。
要创建用于报警的高可用性配置,你仍然可以运行两个配置相同的 Prometheus 服务器,以计算相同的报警( Alertmanager 将对通知进行去重操作):

Prometheus 大规模部署或集群部署还是有些复杂的,后续篇幅做具体探讨。
性能高效
Prometheus 需要能够同时从许多系统和服务中收集详细的指标数据,为此,特别对以下组件进行了高度优化:
- 抓取和解析传入的指标
- 写入和读取时序数据库
- 评估基于
TSDB数据的PromQL表达式
根据社区的使用经验显示,一台大型 Prometheus 服务器每秒可以摄取多达 100万 个时间序列样本,并使用 1-2 字节来将每个样本存储在磁盘上。
演示部署
这里将简单部署一个开源的 Prometheus 演示服务(后续篇幅有完整的全套组件部署),作为后续演示如何使用 PromQL 查询语句的环境。
https://github.com/juliusv/prometheus_demo_service
构建
首先准备 golang 环境:
# 通过一键脚本安装Go
sudo apt install jq
# root下执行脚本 下载1.20.x的版本
wget https://gitee.com/robotneo/script/raw/master/install-go.sh && chmod +x install-go.sh && ./install-go.sh
# 执行go命令验证
go version
然后 clone 代码构建:
# 首先clone代码
git clone https://github.com/juliusv/prometheus_demo_service.git
cd prometheus_demo_service
# 构建
env GOOS=linux GOARCH=amd64 go build -o prometheus_demo_service
nohup ./prometheus_demo_service -listen-address=:10000 > output.log 2>&1 &
nohup ./prometheus_demo_service -listen-address=:10001 > output.log 2>&1 &
nohup ./prometheus_demo_service -listen-address=:10002 > output.log 2>&1 &
构建完成后启动 3 个服务,分别监听 10000、10001、10002 端口:
ps -aux |grep demo
root 12258 2.7 0.1 1139952 16904 pts/0 Sl 14:22 0:00 ./prometheus_demo_service -listen-address=:10000
root 12271 2.6 0.0 1065580 14624 pts/0 Sl 14:22 0:00 ./prometheus_demo_service -listen-address=:10001
root 12281 2.5 0.0 1065580 14532 pts/0 Sl 14:22 0:00 ./prometheus_demo_service -listen-address=:10002
上面 3 个服务都在 /metrics 端点暴露了一些指标数据,我们可以把这 3 个服务配置到 Prometheus 抓取任务中,这样后续就可以使用这几个服务来进行 PromQL 查询说明了。
Prometheus 启动
# prometheus启动
mkdir -pv /opt/prometheus/{data,conf,rules,targets}
# 编辑
sudo vim /opt/prometheus/conf/prometheus.yml
global:
scrape_interval: 5s # 抓取频率
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 配置demo抓取任务
- job_name: demo
scrape_interval: 15s
scrape_timeout: 10s
static_configs:
- targets:
- demo-service-0:10000
- demo-service-1:10001
- demo-service-2:10002
wget https://gitee.com/robotneo/script/raw/master/compose-prom-demo.yml
# 修改宿主机IP docker compose中需要添加
sudo vim compose-prom-demo.yml
extra_hosts:
- "demo-service-0:172.17.40.5" # 这里域名和IP映射需要修改成自己的宿主机IP
- "demo-service-1:172.17.40.5"
- "demo-service-2:172.17.40.5"
# 启动 -p 代表docker compose的项目名称为prom
sudo docker compose -f compose.yml -p prom up -d
# 停止
sudo docker compose -p prom down -v
# 查看
sudo docker compose -p prom ps -a
这里我们将3个服务配置到名为 demo 的抓取任务中,为了看上去更加清晰,这里我们使用 demo-service-<index> 来代替服务地址,直接在 Prometheus 所在宿主机的 /etc/hosts 文件中添加上对应服务的 IP 映射:
cat /etc/hosts
......
172.17.40.5 demo-service-0
172.17.40.5 demo-service-1
172.17.40.5 demo-service-2
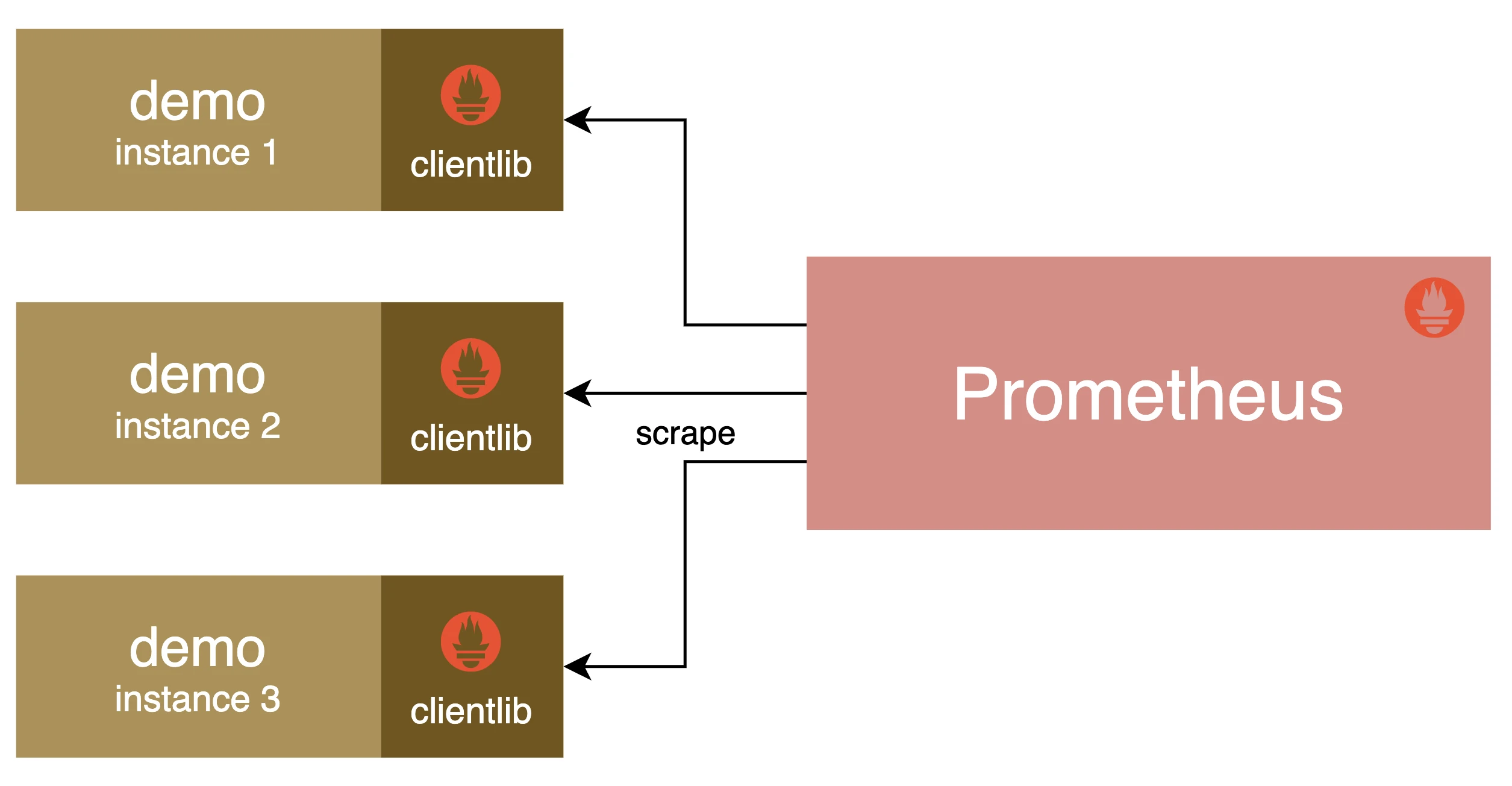
配置完成后直接重新启动 Prometheus 服务即可, Docker Compose 部署的直接再次启动一次。
启动后可以在 /targets 页面查看是否在正确抓取监控指标:
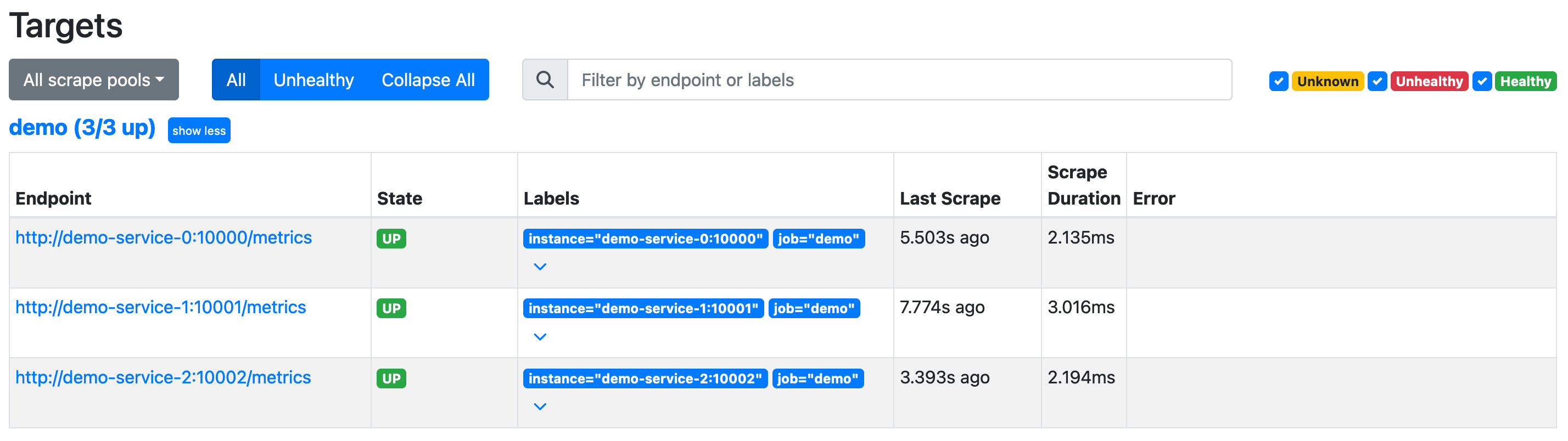
该演示服务 模拟 了一些用于我们测试的监控指标,包括:
- 暴露请求计数和响应时间(以
path、method和响应状态码为标签key)的HTTP API服务 - 一个定期的批处理任务,它暴露了最后一次成功运行的时间戳和处理的字节数
- 有关
CPU数量及其使用情况的综合指标 - 有关内存使用情况的综合指标
- 有关磁盘总大小及其使用情况的综合指标
- 其他指标…
配置解析
Prometheus 通过抓取监控目标上的 HTTP 端点来收集指标,而且 Prometheus 本身也暴露 metrics 指标接口,所以自然它也可以抓取并监控其自身的运行状况,下面我们就用收集自身的数据为例进行配置说明。
将以下 Prometheus 配置保存为 prometheus.yml 文件:
global:
scrape_interval: 5s # 抓取频率
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
上面配置了 Prometheus 每 5s 从自身抓取指标。 global 区域用于配置一些全局配置和默认值, scrape_configs 部分是用来告诉 Prometheus 要抓取哪些目标的。
在我们这里使用 static_configs 属性手动列举了抓取的目标(以 <host>:<port> 格式),不过一般生产环境配置使用一个或多个服务发现来发现目标,完整的配置可以参考官方文档,后续篇幅也会单独针对 服务发现 开一篇。
5秒钟的抓取间隔是非常激进的,但对于这里的演示目的来说还是非常有用的,因为我们希望可以快速获得数据。在实际情况下,间隔通常在10到60秒之间。
查看监控目标
当启动 Prometheus 后,我们可以检查下它是否正确的抓取了配置的目标,可以在浏览器中访问 http://<host-ip>:9090/targets 来查看所有的抓取目标列表:
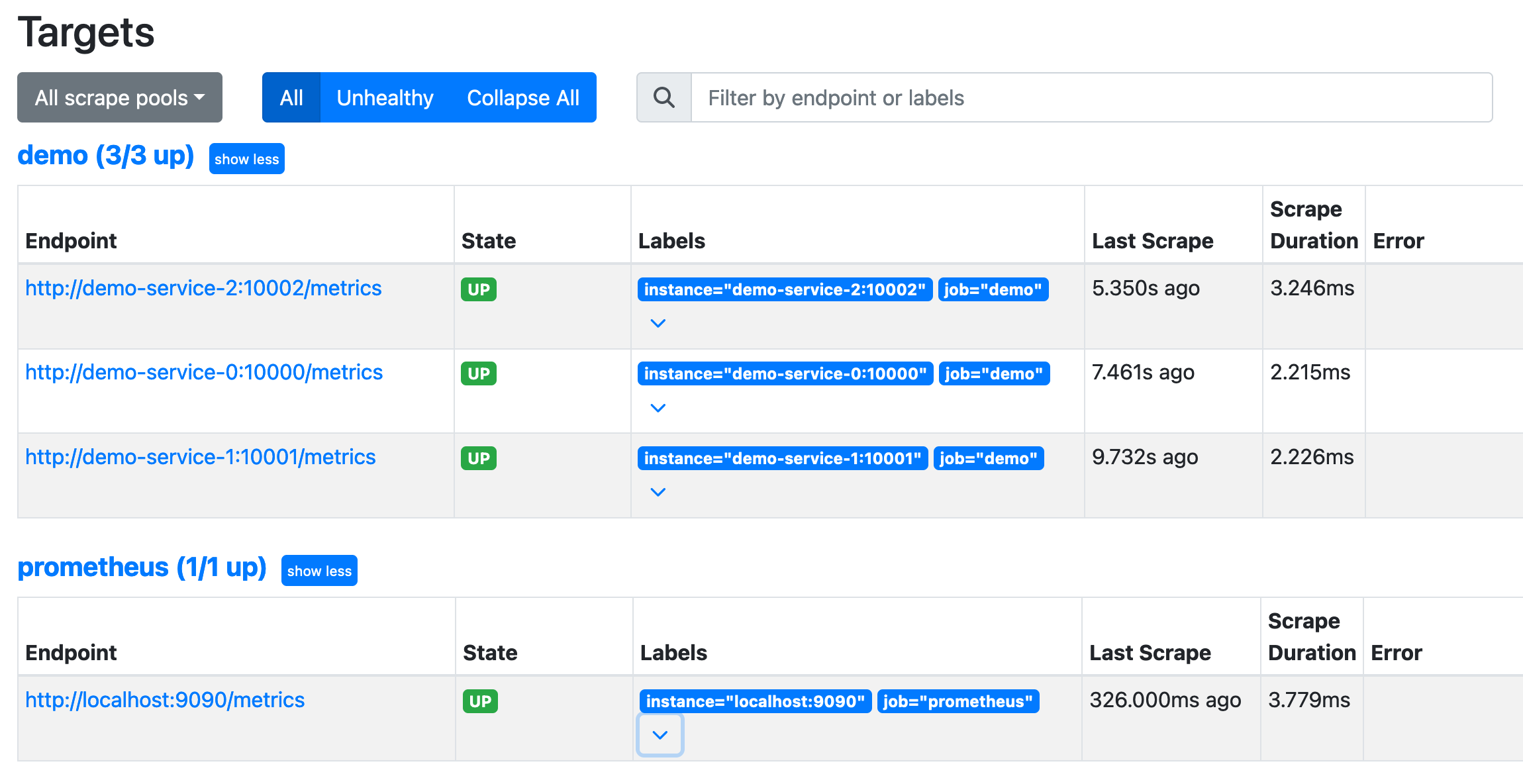
如果我们配置的抓取本身的 prometheus 这个任务显示的绿色的 UP 状态,证明 Prometheus 已经正常抓取自身的监控指标了。
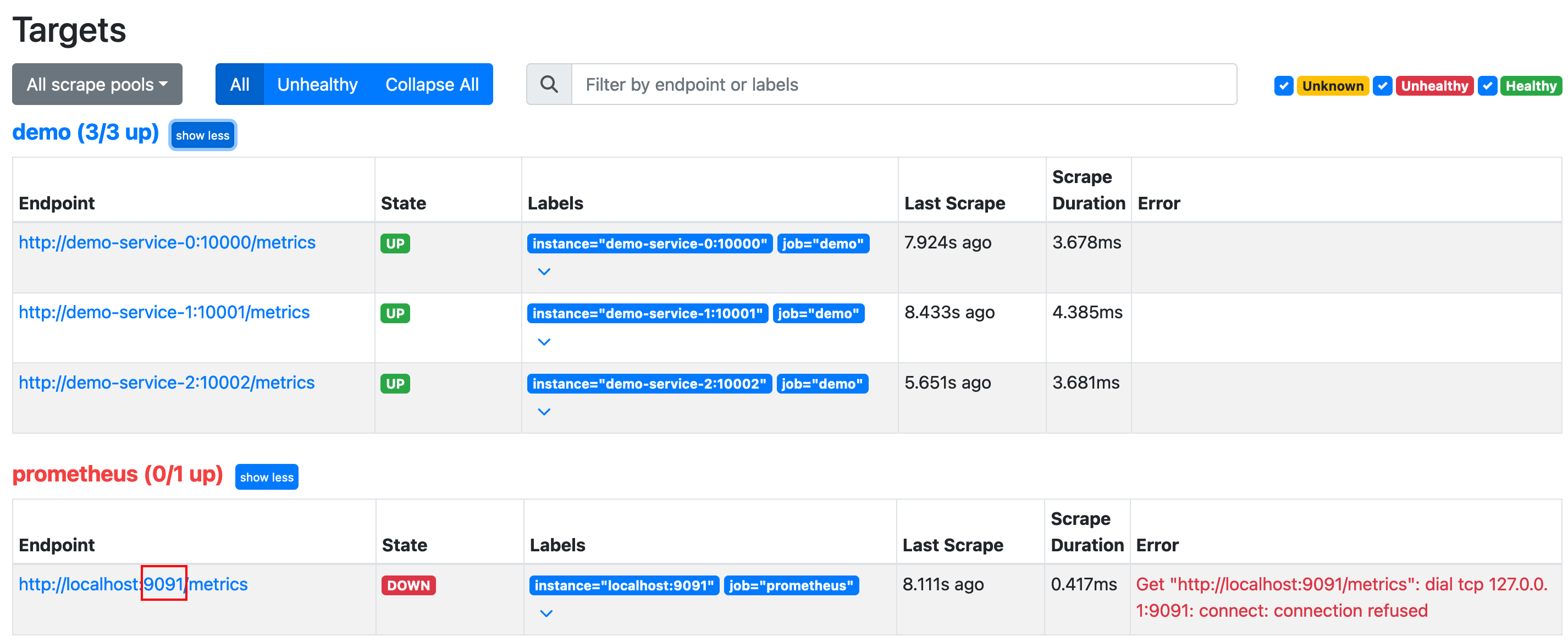
如果在抓取过程中出现任何问题(DNS解析失败、连接超时等等错误),抓取目标都会显示为 DOWN ,同时还有一条错误消息,提供有关抓取失败的相关信息,可以帮助我们快速发现错误配置或不健康的目标。
例如,如果你将 Prometheus 配置在错误的端口上进行抓取( 9091 而不是 9090 ), targets 目标页面将显示 connection refused 错误。
表达式查询
Prometheus 内置了用于 PromQL 查询的表达式查询界面,浏览器中导航至 http://<host-ip>:9090/graph 并选择 Table 视图即可:

Table 选项卡显示了表达式的每个输出序列的最新值,而 Graph 选项卡是绘制随时间变化的值,当然绘制图形对于服务端和浏览器来说是比较耗性能的,所以一般情况都是先在 Table 下尝试查询可能比较耗时的表达式,然后将表达式的查询时间范围缩小,再切换到 Graph 下面进行图形绘制是一个更好的做法。
我们这里使用的最新版本的 2.48.1 版本,每次查询都有查询提示,只需要输入关键字前面字母,就会提示匹配到的字母开头指标名称。

这里的提示功能不只是有指标名称,还有查询语句中使用到的查询函数,也包括这个函数的用法提示等信息,可以说查询功能非常实用。关于指标名称,还可以点击 Open Metrics Explorer 打开预览和搜索拥有的指标。


查询指标Table和Graph
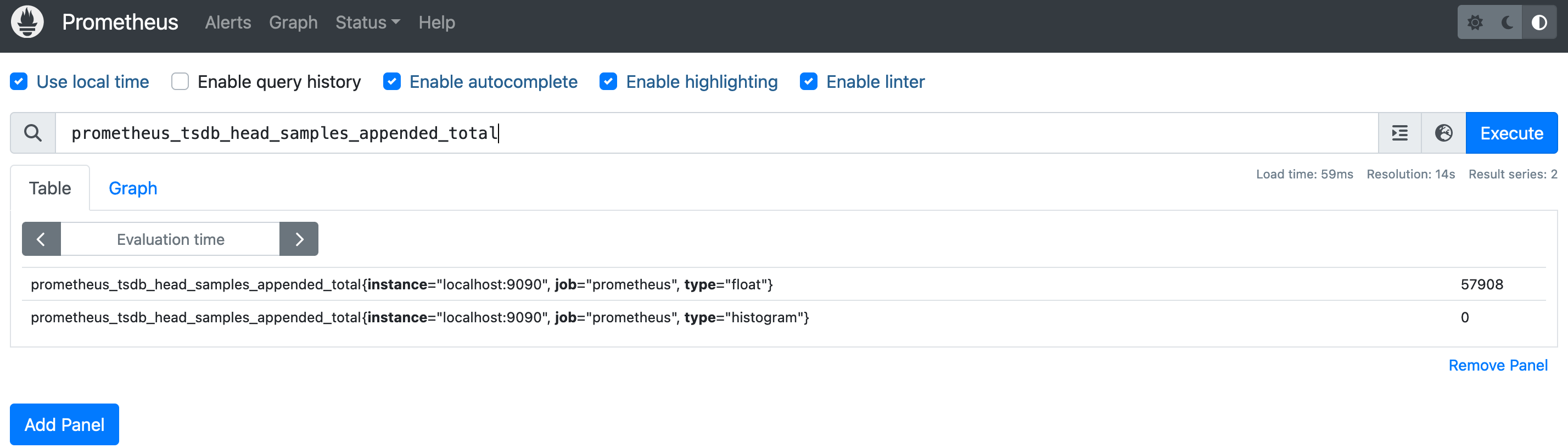
比如我们这里可以查询下面的指标,表示自进程开始以来被摄入 Prometheus 本地存储中的样本总数:
prometheus_tsdb_head_samples_appended_total

然后可以使用下面的表达式了查询 1 分钟内平均每秒摄取的样本数:
rate(prometheus_tsdb_head_samples_appended_total[1m])
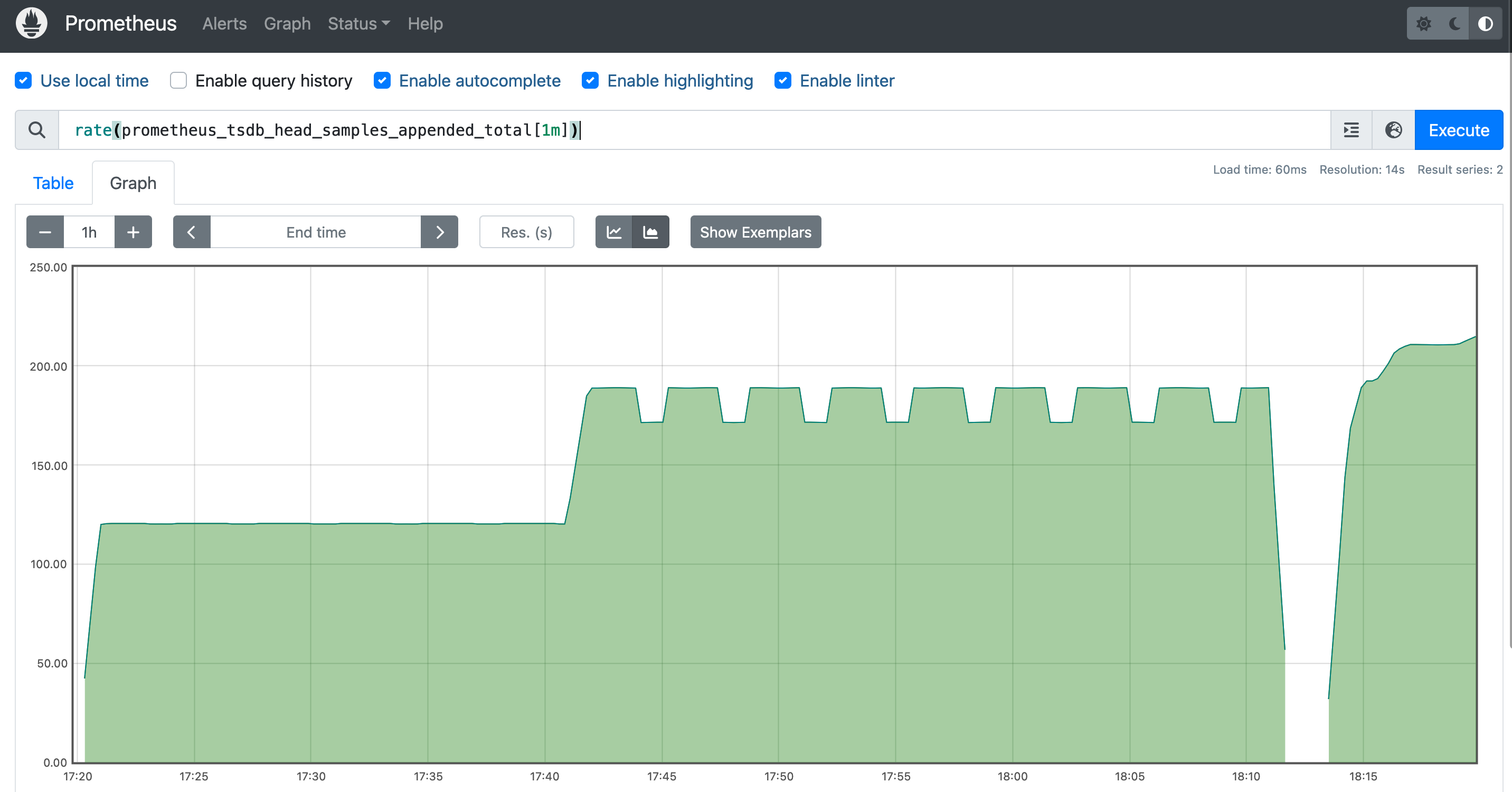
我们可以在 Table 和 Graph 视图下面切换查看表达式查询的结果。
以上就是本篇幅的完整内容,比较啰嗦,但是比较全面,适合新手入门,这篇就到此为止,这次只是一个初步的对 Prometheus 的了解和认识,下一篇将介绍下架构和具体 Prometheus 的主要特性。
参考来源:
https://prometheus.io/docs/introduction/overview/
https://github.com/cnych/qikqiak.com
https://doc.cncf.vip/prometheus-handbook/
希望通过今天的小小探险,你已经对 Prometheus 的监控魔法略有了解啦!就像一位掌握了魔法的巫师, Prometheus 能够在IT领域为你解开许多神秘的问题,让你的系统稳定健康!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!