【基础】【Python网络爬虫】【2.请求与响应】常用请求报头和常用响应方法
Python网络爬虫基础
爬虫基础
请求与相应
在进行爬虫数据采集的过程中,往往是通过一个链接地址向服务器模拟发送请求,从而得到此地址在服务器中的数据。这个地址会遵循互联网数据传输协议:
协议
- 协议,意思是共同计议,协商,经过谈判、协商而定制的共同承认、共同遵守的文件。
- 协议,网络协议的简称,网络协议是通信计算机双方必须共同遵从的一组约定。如怎么样建立连接、怎么样互相识别等。只有遵守这个约定,计算机之间才能相互通信交流。
爬虫业务场景中最常见就是 http 协议
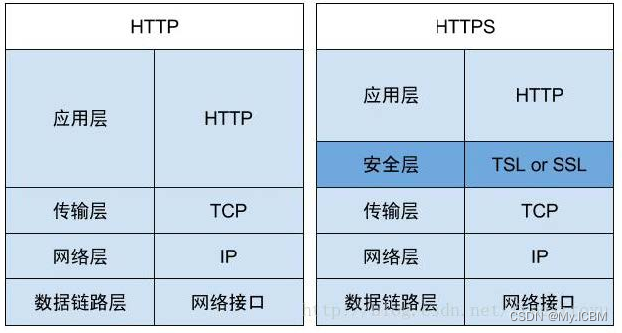
HTTP/HTTPS 协议
- HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法。
- HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
HTTP/HTTPS的优缺点

HTTP 的缺点
- 通信使用明文(不加密),内容可能会被窃听
- 不验证通信方的身份,因此有可能遭遇伪装
- 无法证明报文的完整性,所以有可能已遭篡改
HTTPS的优点
为了解决 HTTP 协议的以上缺点,在上世纪90年代中期,由网景(NetScape)公司设计了 SSL 协议。SSL 是“Secure Sockets Layer”的缩写,中文叫做“安全套接层”。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
请求与响应概述
HTTP通信由两部分组成: 客户端请求消息 与 服务器响应消息
浏览器发送HTTP请求的过程:
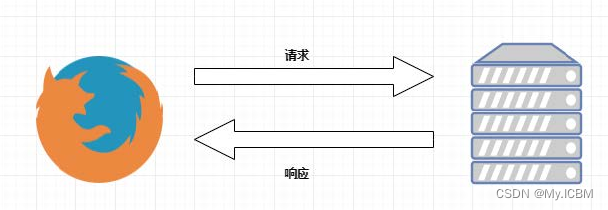
- 当我们在浏览器输入URL https://www.baidu.com 的时候,浏览器发送一个Request请求去获取 https://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
- 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
- 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
请求
请求目标(url)
URL又叫作统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种方法。类似于Windows的文件路径。
一个网址的组成:
1. http://:这个是协议,也就是HTTP超文本传输协议,也就是网页在网上传输的协议。
2. mail:这个是服务器名,代表着是一个邮箱服务器,所以是mail。
3. 163.com:这个是域名,是用来定位网站的独一无二的名字。
4. mail.163.com:这个是网站名,由服务器名+域名组成。
5. /:这个是根目录,也就是说,通过网站名找到服务器,然后在服务器存放网页的根目录。
6. index.html:这个是根目录下的网页。
7. http://mail.163.com/index.html:这个叫做URL,统一资源定位符,全球性地址,用于定位网上
的资源。

请求体(response)
就像打电话一样,HTTP到底和服务器说了什么,才能让服务器返回正确的消息的,其实客户端的请求告诉了服务器这些内容:请求行、请求头部、空行、请求数据
此请求体对象是http协议中的请求体格式,我们平常一般看不到这样的格式内容。此格式在数据包中会有另外的一种数据格式显示。
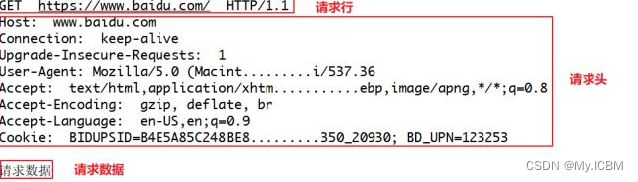
常用的请求报头
请求头描述了客户端向服务器发送请求时所使用的编码,以及发送内容的长度,告诉服务器自己有没有登陆,采用的什么浏览器访问的等等。
Accept :浏览器告诉服务器自己接受什么数据类型,文字,图片等。Accept-Charset :浏览器申明自己接收的字符集。Accept-Encoding :浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法 (gzip, deflate, br)。Accept-Language :浏览器申明自己接收的语言。Authorization :授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中。Content-Length :表示请求消息正文的长度。origin (常用):声明请求资源的起始位置Connection :处理完这次请求后,是断开连接还是继续保持连接。Cookie (常用):发送给WEB服务器的Cookie内容,经常用来判断是否登陆了。Host (常用):客户端指定自己想访问的WEB服务器的域名/IP 地址和端口号。If-Modified-Since :客户机通过这个头告诉服务器,资源的缓存时间。只有当所请求的内容在指定的时间后又经过修改才返回它,否则返回304“Not Modified”应答。Pragma :指定“no-cache”值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝。Referer (常用):告诉服务器该页面从哪个页面链接的。From :请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它。User-Agent (常用):浏览器表明自己的身份 (是哪种浏览器)Upgrade-insecure-requests :申明浏览器支持从 http 请求自动升级为 https 请求,并且在以后发送请求的时候都使用 https。UA-Pixels,UA-Color,UA-OS,UA-CPU :由某些版本的IE浏览器所发送的非标准的请求头,表示屏幕大小、颜色深度、操作系统和CPU类型。`
查看请求体(requests 模块)
在我们用requests模块请求数据的时候携带上诉请求报头的字段信息,将我们的爬虫代码进行伪装。同样的伪装之后我们也可以通过代码查看请求体的字段信息,有如下几种常见的属性:
# 查看请求体中的url地址
response.request.url
# 查看请求体中的请求头信息
response.request.headers
# 查看请求体中的请求方法
response.request.method
响应
- 响应体就是响应的消息体,如果是纯数据就是返回纯数据,如果请求的是HTML页面,那么返回的就是HTML代码,如果是JS就是JS代码,如此之类。
HTTP响应体
- HTTP响应报文也由三部分组成:响应行、响应头、响应体
- HTTP响应报文格式就如下图所示:

响应行
- 响应行一般由协议版本、状态码及其描述组成 比如 HTTP/1.1 200 OK
- 其中协议版本HTTP/1.1或者HTTP/1.0,200就是它的状态码,OK则为它的描述。
响应头
- 响应头用于描述服务器的基本信息,以及数据的描述,服务器通过这些数据的描述信息,可以通知客户端如何处理等一会儿它回送的数据。
- 设置HTTP响应头往往和状态码结合起来。例如,有好几个表示“文档位置已经改变”的状态代码都伴随着一个Location头,而401(Unauthorized)状态代码则必须伴随一个WWW-Authenticate头。然而,即使在没有设置特殊含义的状态代码时,指定应答头也是很有用的。应答头可以用来完成:设置Cookie,指定修改日期,指示浏览器按照指定的间隔刷新页面,声明文档的长度以便利用持久HTTP连接等许多其他任务。
常见的响应头字段含义
Allow :服务器支持哪些请求方法(如GET、POST等)。Content-Encoding :文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Content-Length :表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。Content- Type :表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置 Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。Date :当前的GMT时间,例如,Date:Mon,31Dec200104:25:57GMT。Date描述的时间表示世界标准时,换算成本地时间,需要知道用户所在的时区。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。Expires :告诉浏览器把回送的资源缓存多长时间,-1或0则是不缓存。Last-Modified :文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。Location :这个头配合302状态码使用,用于重定向接收者到一个新 url 地址。表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。Refresh :告诉浏览器隔多久刷新一次,以秒计。Server :服务器通过这个头告诉浏览器服务器的类型。Server响应头包含处理请求的原始服务器的软件信息。此域能包含多个产品标识和注释,产品标识一般按照重要性排序。Servlet一般不设置这个值,而是由Web服务器自己设置。Set-Cookie :设置和页面关联的Cookie。Servlet不应使用response.setHeader(“Set-Cookie”, …),而是应使用HttpServletResponse提供的专用方法addCookie。Transfer-Encoding :告诉浏览器数据的传送格式。WWW-Authenticate :客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。setContentType :设置Content-Type头。大多数Servlet都要用到这个方法。setContentLength :设置Content-Length头。对于支持持久HTTP连接的浏览器来说,这个函数是很有用的。addCookie :设置一个Cookie(Servlet API中没有setCookie方法,因为应答往往包含多个Set-Cookie头)。
响应内容
- 响应内容指的就是根据链接地址请求所返回的数据,常见的包括html、css、js、图片、视频、音频等响应的数据。
常见的响应方法
# 获取响应体文本数据
response.text
# 获取响应体二进制数据
response.content
# 获取响应体json数据
response.json()
# 获取响应体响应头信息
response.headers
# 设置响应体的编码
response.encoding
# 自动识别响应体的编码
response.apparent_encoding
# 获取响应体的cookies信息,获取到的是cookiejar对象
response.cookies
# 获取响应体的url地址
response.url
# 获取响应体的状态码
response.status_code
响应状态码
响应状态码可以很方便的查看我们的响应状态,我们可以检测响应状态码:
200 :请求正常,服务器正常的返回数据。301 :永久重定向。比如在访问www.jingdong.com 的时候会重定向到www.jd.com。302 :临时重定向。比如在访问一个需要登录的页面的时候,而此时没有登录,那么就会重定向到登录页面。400 :请求的url 在服务器上找不到。换句话说就是请求url 错误。403 :服务器拒绝访问,权限不够。500 :服务器内部错误。可能是服务器出现bug 了。
import requests
response = requests.get('http://www.pcbaby.com.cn/')
print(response.status_code)
"""
100 - 200 标识服务器已经成功接受到了请求
200 - 299 表示请求成功 200 206 207
300 - 399 重定向(你请求的地址已经移动到了另外一个位置) 302
400 - 499 客户端请求的地址在服务器找不到数据<地址错了> 404 405
500 - 599 服务器错误, 是服务器问题 501 504
"""
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!